 NVIDIA 與飛槳團隊合作開發基于 ResNet50 的模型示例
NVIDIA 與飛槳團隊合作開發基于 ResNet50 的模型示例
你還在頭疼于經典模型的復現嗎?不知何處可以得到全面可參照的 Benchmark?
為了讓飛槳開發者可以快速復現頂尖的精度和超高的性能,NVIDIA 與飛槳團隊合作開發了基于 ResNet50 的模型示例,并將持續開發更多的基于 NLP 和 CV 等領域的經典模型,后續陸續發布的模型有 BERT、PP-OCR、PP-YOLO 等,歡迎持續關注。
深度學習模型是什么?
深度學習包括訓練和推理兩個環節。訓練是指通過大數據訓練出一個復雜的神經網絡模型,即用大量標記過的數據來“訓練”相應的系統,使之可以適應特定的功能。推理是指利用訓練好的模型,使用新數據推理出各種結論。深度學習模型是在訓練工作過程中生成,并將其保存,用于推理當中。
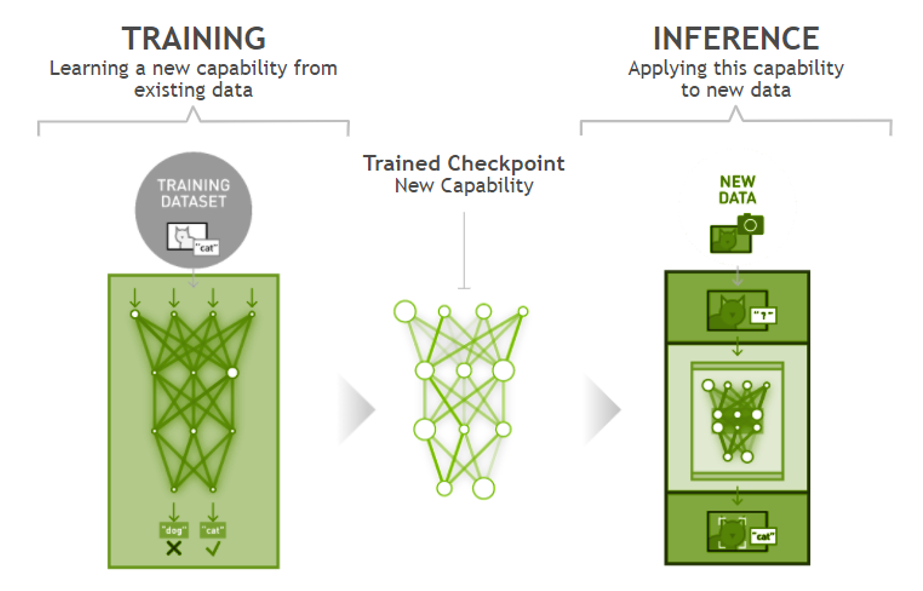
深度學習訓練推理示意圖
NVIDIA Deep Learning Examples
全新上線飛槳 ResNet50
NVIDIA Deep Learning Examples 倉庫上線了基于飛槳實現的 ResNet50 模型的性能優化結果,該示例全面適配各類 NVIDIA GPU 和各種硬件拓撲(單機單卡,單機多卡),極致優化性能。值得一提的是,Deep Learning Examples 中飛槳 ResNet50 模型訓練速度已超過對應的 PyTorch 版 ResNet50。
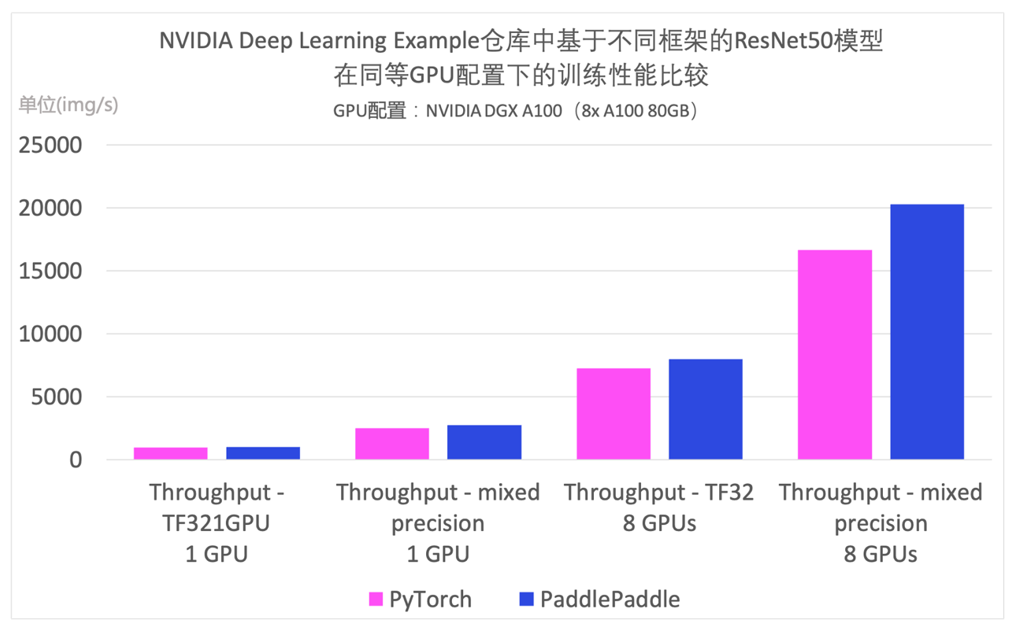
NVIDIA Deep Learning Examples 倉庫中基于飛槳與 PyTorch 的 ResNet50 模型在同等 GPU 配置下的訓練性能比較,GPU 配置為 NVIDIA DGX A100(8x A100 80GB)。
*數據來源:[1][2]
NVIDIA Deep Learning Examples 倉庫中飛槳 ResNet50 有哪些優勢?
優勢一:通過使用 DALI 等工具,加速 GPU 數據預處理性能
NVIDIA Data Loading Library( DALI )專注于使用 GPU 加速深度學習應用中的數據加載和預處理。深度學習數據預處理涉及到復雜的、多個階段的處理過程,如 ResNet50 模型訓練過程中,在 CPU 上處理圖片的加載、解碼、裁剪、翻轉、縮放和其他數據增強等操作會成為瓶頸,限制訓練和推理的性能和可擴展性。DALI 將這些操作轉移到 GPU 上,最大限度地提高輸入流水線的吞吐量,并且其中數據預取,并行執行和批處理的操作對用戶是透明的。
優勢二:通過使用 AMP,ASP 等工具,提高推理性能
飛槳內置支持 AMP(自動混合精度)及 ASP(自動稀疏化)模塊,AMP 模塊可在模型訓練過程中,自動為算子選擇合適的計算精度(FP32/FP16),充分利用 Tensor Cores 的性能,在不影響模型精度的前提下,大幅加速模型訓練。
ASP 模塊實現了一個工作流將深度學習模型從稠密修剪為 2:4 的稀疏模式,經過重訓練之后,可恢復到與稠密模型相當的精度。稀疏模型可以充分利用 A100 Tensor Core GPU 的加速特性,被修剪的權重矩陣參數存儲量減半,并且可以獲得理論上 2 倍的計算加速,從而大幅提高推理性能。
優勢三:通過集成 TensorRT,優化推理模型
飛槳推理集成了 TensorRT,稱為 Paddle-TRT。它可以把部分模型子圖交給 TensorRT 加速,而其他部分仍然用飛槳執行,從而達到最佳的推理性能。
優勢四:豐富的 Benchmark
NVIDIA Deep Learning Examples 倉庫中
有哪些 Benchmark?
NVIDIA Deep Learning Examples 倉庫中的 Benchmark 主要包含訓練精度結果、訓練性能結果、推理性能結果、Paddle-TRT 性能結果幾個方面。
1、訓練精度結果
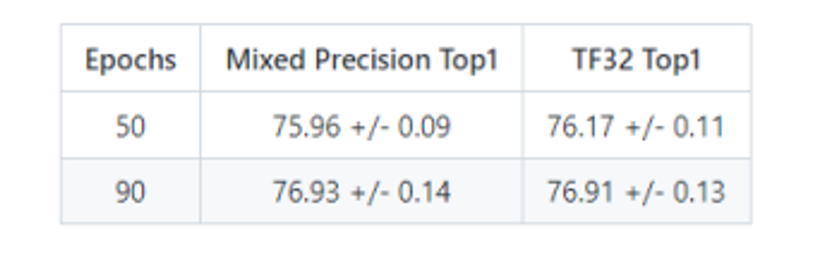
訓練精度: NVIDIA DGX A100 (8x A100 80GB)
*數據來源:[1]

集成 ASP 的提高精度: NVIDIA DGX A100 (8x A100 80GB)
*數據來源:[1]
2、訓練性能結果

訓練性能: NVIDIA DGX A100 (8x A100 80GB)
*數據來源:[1]

集成 ASP 的訓練性能: NVIDIA DGX A100 (8x A100 80GB)
*數據來源:[1]
3、推理性能結果
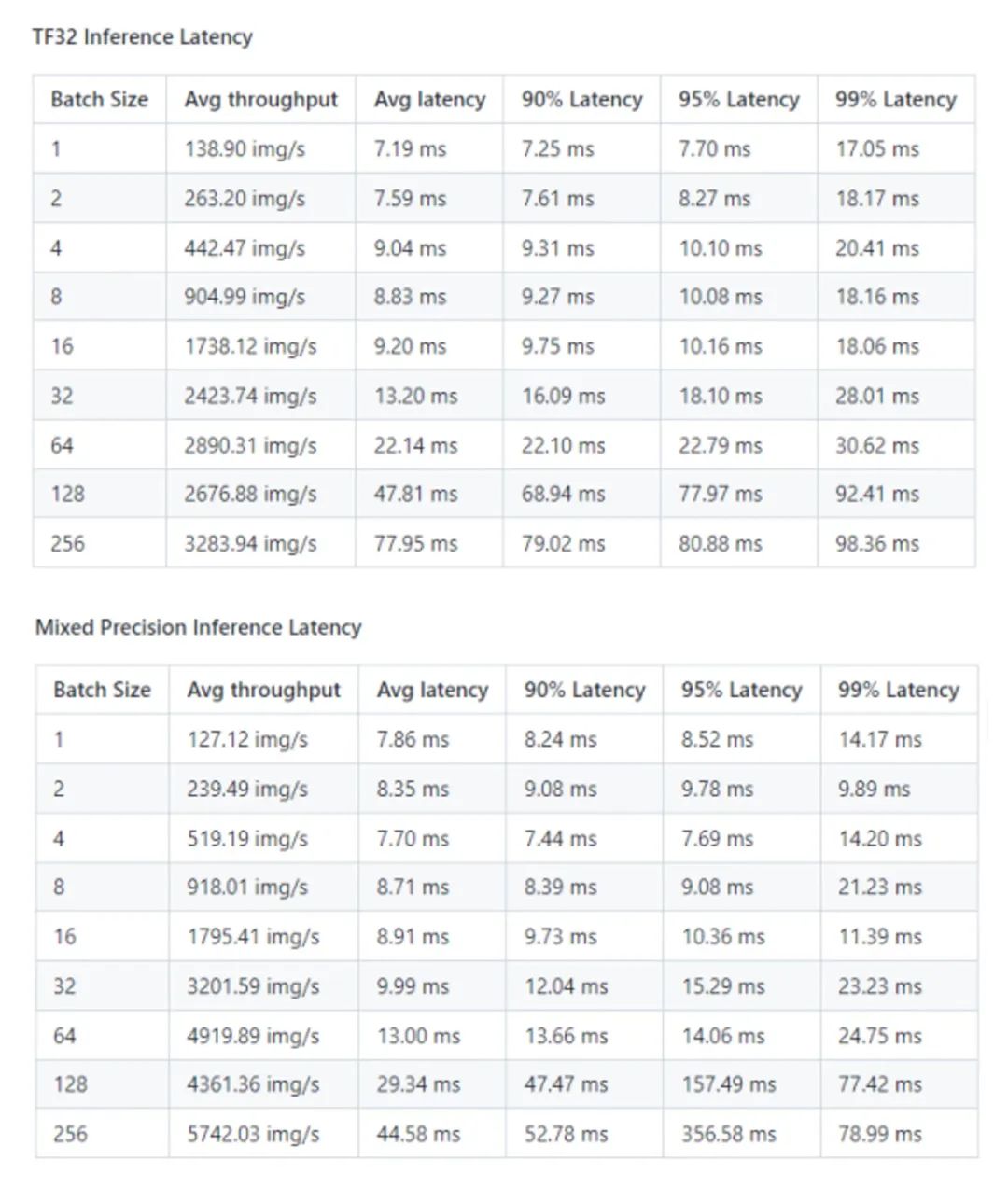
推理性能: NVIDIA DGX A100 (1x A100 80GB)
*數據來源:[1]
4、Paddle-TRT 性能結果
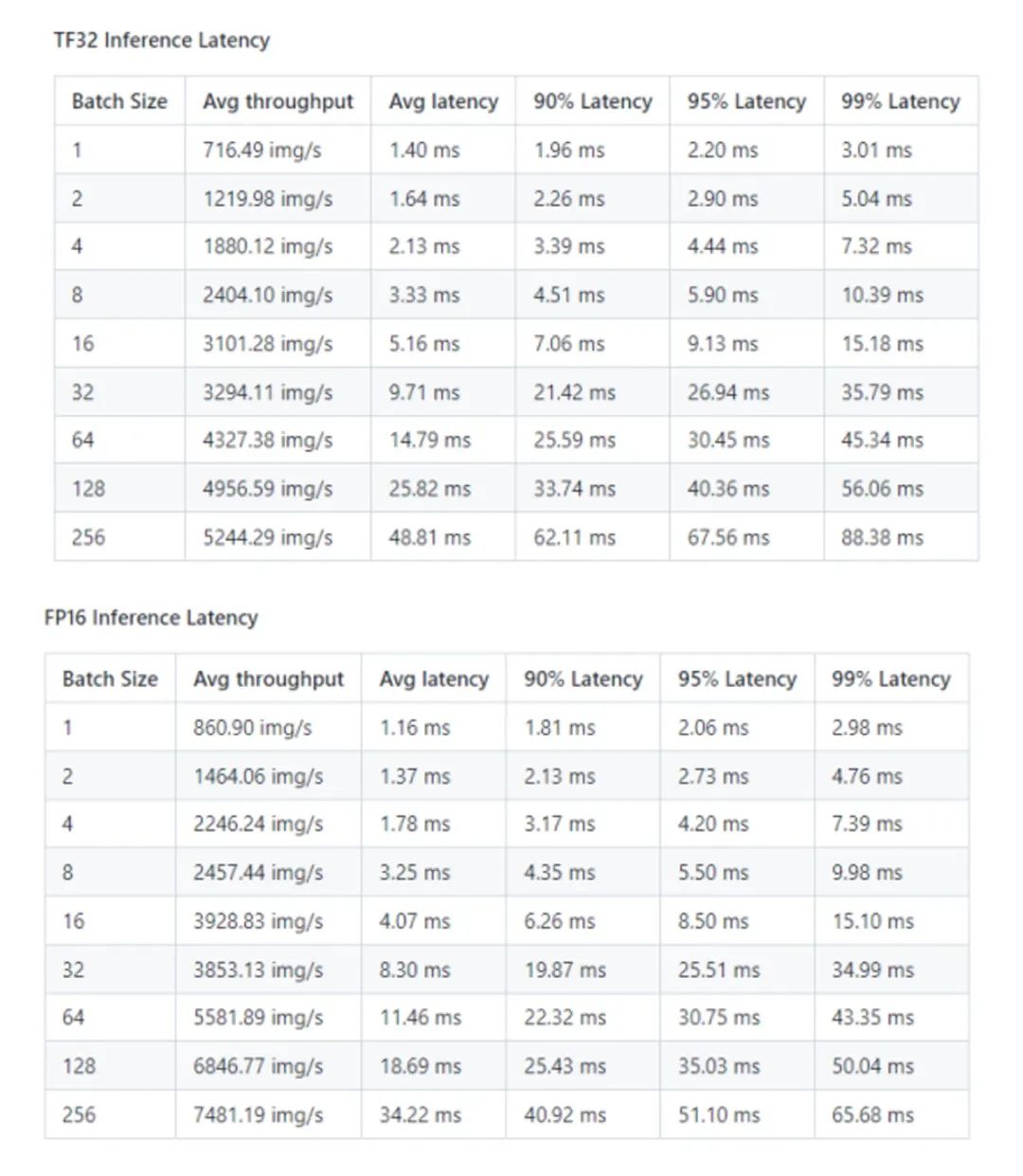
Paddle-TRT 性能結果: NVIDIA DGX A100 (1x A100 80GB)
*數據來源:[1]
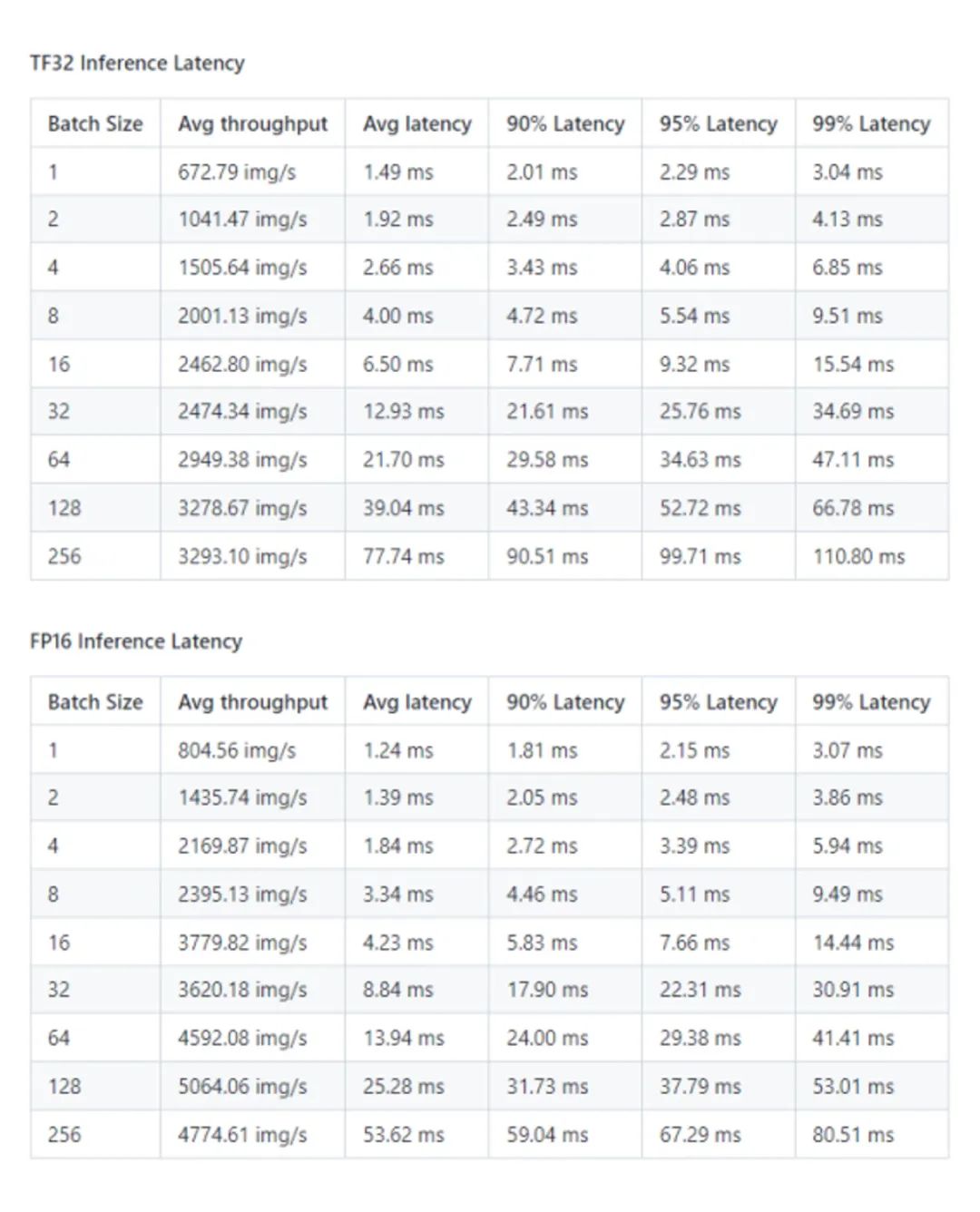
Paddle-TRT 性能結果: NVIDIA A30 (1x A30 24GB)
*數據來源:[1]
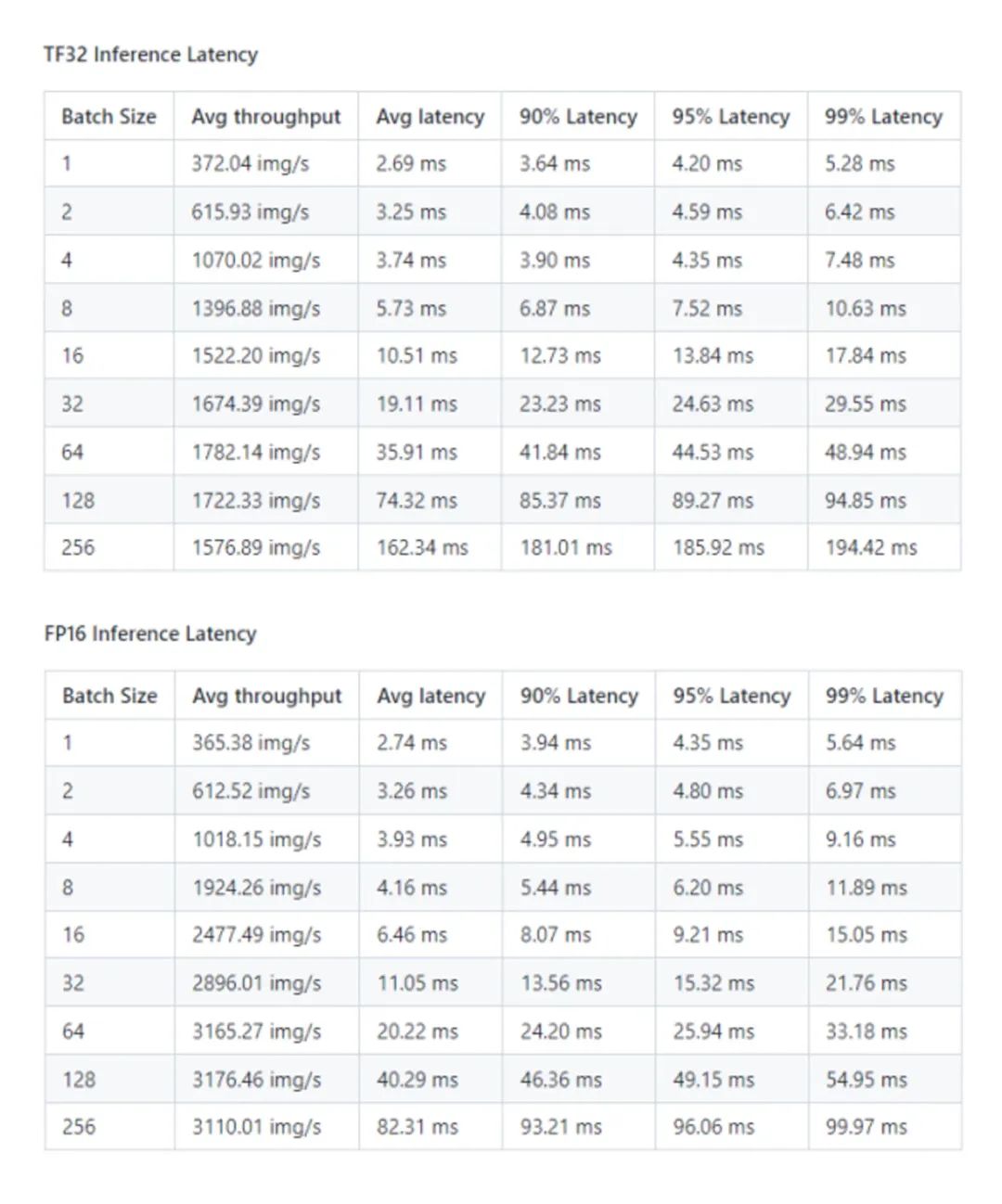
Paddle-TRT 性能結果: NVIDIA A10 (1x A10 24GB)
*數據來源:[1]
如何下載 NVIDIA Deep Learning Examples 中的飛槳 ResNet50?
登錄 GitHub NVIDIA Deep Learning Examples 倉庫, 找到 PaddlePaddle/Classification/RN50/1.5,下載模型源代碼即可。
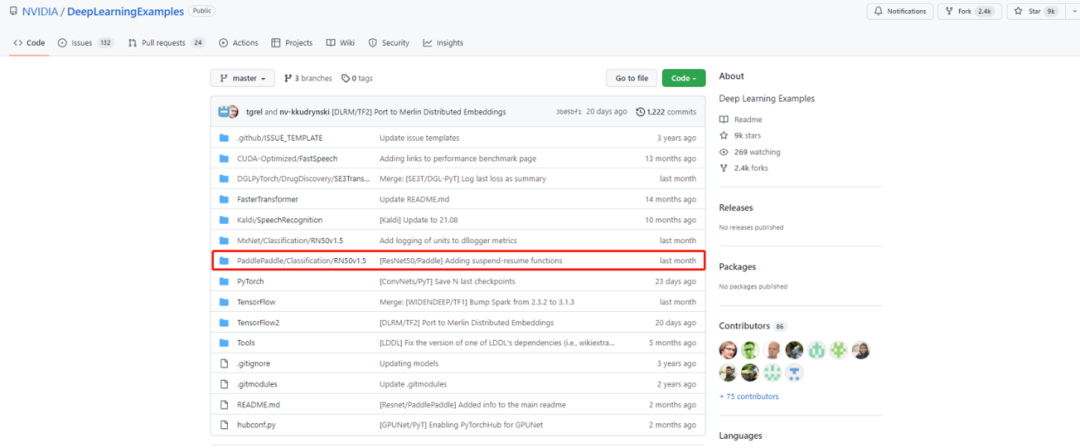
NVIDIA Deep Learning Examples 飛槳 ResNet50 下載頁面
飛槳容器如何安裝?
容器包含了深度學習框架在運行時所需的所有部件(包括驅動,工具包等),它具有輕量化與可復制性、打包和執行環境合二為一以及簡化應用程序部署等優勢,因此,被認為是在同一環境中實現“構建、測試、部署”的最佳平臺。容器允許我們創建標準化可復制的輕量級開發環境,擺脫來自 Hypervisor 所帶來運行開銷。應用程序可以基于 Container Runtime 運行在“任意”系統中。
NVIDIA 與百度飛槳聯合開發了 NGC 飛槳容器,將最新版本的飛槳與最新的 NVIDIA 的軟件棧進行了無縫的集成與性能優化,最大程度的釋放飛槳框架在 NVIDIA 最新硬件上的計算能力。這樣,用戶不僅可以快速開啟 AI 應用,專注于創新和應用本身,還能夠在 AI 訓練和推理任務上獲得飛槳+NVIDIA 帶來的飛速體驗。
NGC 飛槳容器已經集成入飛槳官網主頁。你可以選擇 “飛槳版本”+“Linux”+“Docker”+“CUDA 11.7”找到對應的 Container 下載指令。
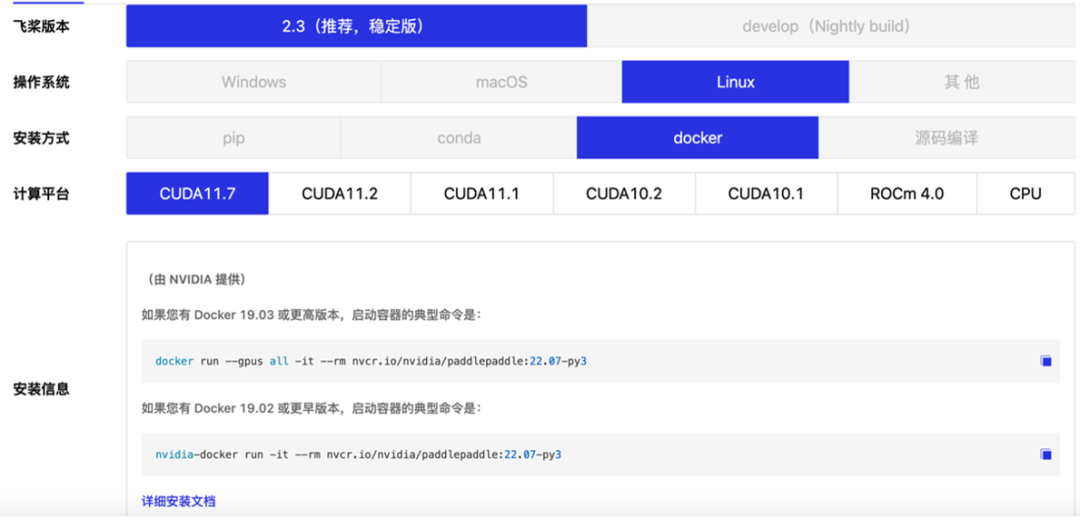
并參考《NGC 飛槳容器安裝指南》下載安裝:https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
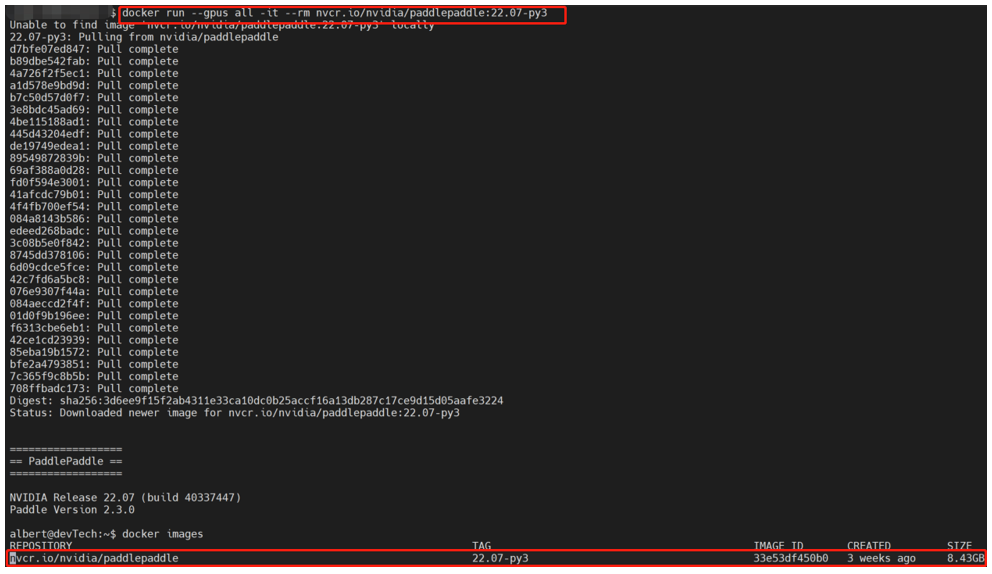
運行結果如下:
-
NVIDIA
+關注
關注
14文章
5258瀏覽量
105844 -
模型
+關注
關注
1文章
3499瀏覽量
50058 -
大數據
+關注
關注
64文章
8952瀏覽量
139566 -
飛槳
+關注
關注
0文章
35瀏覽量
2439
原文標題:NVIDIA Deep Learning Examples飛槳ResNet50模型上線訓練速度超PyTorch ResNet50
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
全志科技攜飛凌嵌入式T527核心板亮相OpenHarmony開發者大會

大模型時代的深度學習框架

基于RV1126開發板的resnet50訓練部署教程

燧原科技正式納入飛槳例行版本發布體系
百度飛槳框架3.0正式版發布

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺

如何在C#中部署飛槳PP-OCRv4模型

使用OpenVINO C# API輕松部署飛槳PP-OCRv4模型
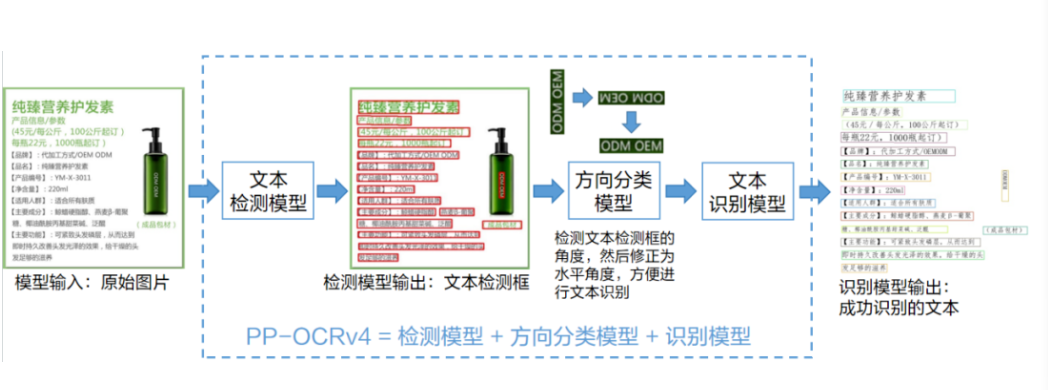
在Ubuntu 24.04 LTS上安裝飛槳PaddleX
基于改進ResNet50網絡的自動駕駛場景天氣識別算法

NVIDIA擬與印度合作開發AI芯片
TI (德州儀器) 團隊到訪飛凌嵌入式總部,深化交流與合作






 工商網監
工商網監
評論