 邊緣AI的模型壓縮技術
邊緣AI的模型壓縮技術

深度學習在模型及其數據集方面正在以驚人的速度增長。在應用方面,深度學習市場以圖像識別為主,其次是光學字符識別,以及面部和物體識別。根據 Allied 的市場調查,2020 年全球深度學習市場規模為 68.5 億美元,預計到 2030 年將達到 1799.6 億美元,從 2021 年到 2030 年的復合年增長率為 39.2%。
在某個時間點,人們認為大型和復雜的模型表現更好,但現在它幾乎是一個神話。隨著邊緣AI的發展,越來越多的技術將大型復雜模型轉換為可以在邊緣上運行的簡單模型,所有這些技術結合在一起執行模型壓縮。
什么是模型壓縮?
模型壓縮是在具有低計算能力和內存的邊緣設備上部署SOTA(最先進的)深度學習模型的過程,而不會影響模型在準確性,精度,召回性等方面的性能。模型壓縮廣泛地減少了模型中的兩件事,即大小和延遲。大小減小側重于通過減少模型參數使模型更簡單,從而減少執行中的 RAM 要求和內存中的存儲要求。減少延遲是指減少模型進行預測或推斷結果所花費的時間。模型大小和延遲通常是一起的,大多數技術都會減少兩者。
流行的模型壓縮技術
修剪:
修剪是模型壓縮的最流行的技術,它通過刪除冗余和無關緊要的參數來工作。神經網絡中的這些參數可以是連接器、神經元、通道,甚至是層。它很受歡迎,因為它同時減小了模型的大小并改善了延遲。
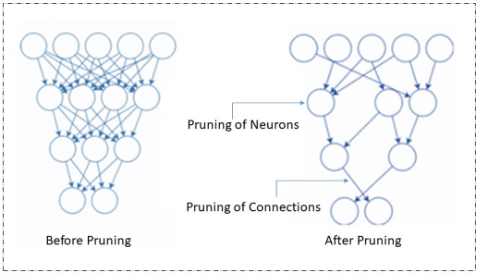
修剪
修剪可以在訓練模型時或在訓練后完成。有不同類型的修剪技術,包括重量/連接修剪,神經元修剪,過濾器修剪和層修剪。
量化:
當我們在修剪中移除神經元,連接,過濾器,層等以減少加權參數的數量時,權重的大小在量化過程中減小。在此過程中,較大集中的值將映射到較小集中的值。與輸入網絡相比,輸出網絡的值范圍較窄,但保留了大部分信息。
知識提煉:
在知識提煉過程中,一個復雜而大型的模型在一個非常大的數據集上被訓練。微調大型模型后,它可以很好地處理看不見的數據。一旦實現,這些知識就會轉移到較小的神經網絡或模型中。同時使用教師網絡(較大模型)和學生網絡(較小模型)。這里存在兩個方面,知識提煉,其中我們不調整教師模型,而在遷移學習中,我們使用確切的模型和權重,在一定程度上改變模型,并針對相關任務進行調整。
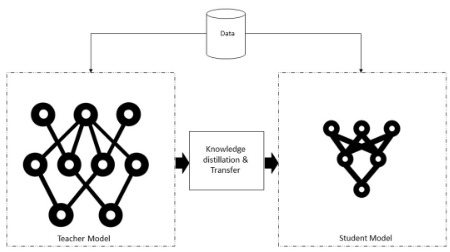
知識蒸餾系統
知識、蒸餾算法和師生架構模型是典型知識蒸餾系統的三個主要部分,如上圖所示。
低矩陣分解:
矩陣構成了大多數深度神經架構的大部分。該技術旨在通過應用矩陣或張量分解并將它們變成更小的矩陣來識別冗余參數。當應用于密集 DNN(深度神經網絡)時,此技術可降低 CNN(卷積神經網絡)層的存儲要求和因式分解,并縮短推理時間。具有二維且具有秩 r 的權重矩陣 A 可以分解為更小的矩陣,如下所示。
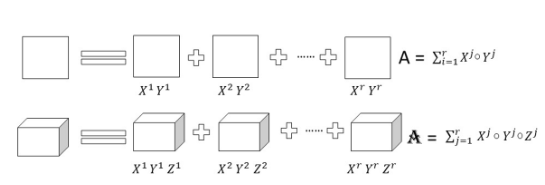
低矩陣因式分解
模型準確性和性能在很大程度上取決于正確的因式分解和秩選擇。低秩因式分解過程中的主要挑戰是更難實現,并且計算密集型。總體而言,與全秩矩陣表示相比,密集層矩陣的因式分解可導致更小的模型和更快的性能。
由于邊緣AI,模型壓縮策略變得非常重要。這些方法相互補充,可以在整個AI管道的各個階段使用。像張量流和Pytorch這樣的流行框架現在包括修剪和量化等技術。最終,該領域使用的技術數量將會增加。
審核編輯:郭婷
-
連接器
+關注
關注
99文章
15352瀏覽量
140181 -
RAM
+關注
關注
8文章
1392瀏覽量
117315 -
深度學習
+關注
關注
73文章
5560瀏覽量
122733
發布評論請先 登錄
Nordic收購 Neuton.AI 關于產品技術的分析
邊緣AI實現的核心環節:硬件選擇和模型部署

邊緣AI的優勢和技術基石

邊緣AI實現的核心環節:硬件選擇和模型部署
Deepseek海思SD3403邊緣計算AI產品系統
意法半導體邊緣AI套件中提供的全部工具
AI賦能邊緣網關:開啟智能時代的新藍海
研華邊緣AI Box MIC-ATL3S部署Deepseek R1模型






 工商網監
工商網監
評論