 使用自適應條形采樣和雙分支Transformer的DA-Net
使用自適應條形采樣和雙分支Transformer的DA-Net
文章目錄
前言
概述
網絡簡介
DBTM:Local Patches Meet Global Context
ASUB block
實驗
討論
前言
這是 MICCAI 2022 上的第三篇閱讀筆記了,之前兩篇也都可以在 GiantPandaCV 公眾號搜索到。如下圖所示,目前的視網膜血管分割方法按照輸入數據劃分有兩類:image-level 和 patches-level,每一種方法都有自己的優勢,如何將兩者結合起來是一個需要去解決的問題,這也是 DA-Net 這篇文章的貢獻之一。此外,這篇文章還提出了一個自適應的條狀 Upsampling Block,我們會在后面展開介紹。
概述
目前的視網膜血管分割方法根據輸入類型大致分為 image-level 和 patches-level 方法,為了從這兩種輸入形式中受益,這篇文章引入了一個雙分支 Transformer 模塊,被叫做 DBTM,它可以同時利用 patches-level 的本地信息和 image-level 的全局上下文信息。視網膜血管跨度長、細且呈條狀分布,傳統的方形卷積核表現不佳,也是為了更好地捕獲這部分的上下文信息,進一步設計了一個自適應條狀 Upsampling Block,被叫做 ASUB,以適應視網膜血管的條狀分布。
網絡簡介
下圖是 DA-Net 的整體結構。共享 encoder 包含五個卷積塊,DBTM 在 encoder 之后,最后是帶 ASUB 的 decoder。首先,原眼底圖像很常規的被分成 N^2 個 patches,N 為 patch 的大小,除此之外,將原眼底圖像也下采樣 N 倍,但是不做裁剪。將它們一起送入共享 encoder,分別得到相應的特征圖 F(i) 和 F′,這里的共享指的是兩個 encoder 分支的權重共享(那么你可以把它簡單理解為用同一個卷積核掃描 N^1+1 個 patches,只不過其中 1 這個 patch 是完整的圖像),兩個分支可以通過合并批次并行操作,這意味著輸入圖像的編碼可以在一次推理中完成,無需增加額外的參數和時間消耗。隨后,這兩個分支的輸出通過 DBTM 進行通信,DBTM 可以向每個補丁廣播長距離的全局信息。U 型網絡中間還有普通的跨層連接,最后,再通過 ASUB 的 decoder后,得到預測的分割結果。
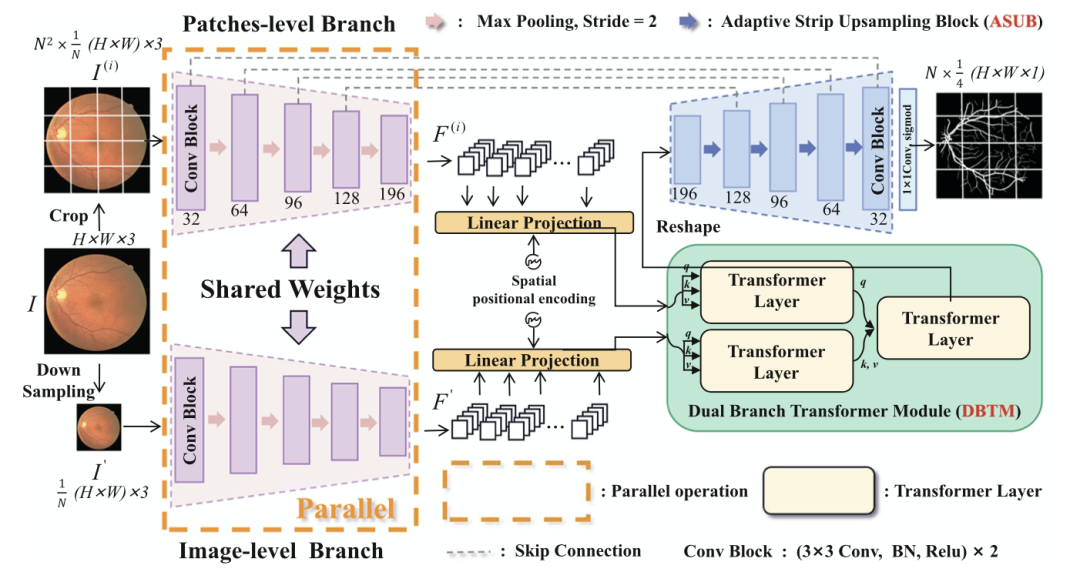 請添加圖片描述
請添加圖片描述
DBTM:Local Patches Meet Global Context
下面兩部分,我們分別對 DBTM 和 AUSB block 展開介紹。
首先,將經過 flatten 和投影的特征圖 F(i) 和 F′ 作為輸入 tokens ,其中加入訓練過的 position embeddings 以保留位置信息。然后,如下圖所示,輸入 tokens 被送入 Transformer Layer。不同的是,設計了一個特殊的 self-then-cross 的 pipeline,將兩個分支的輸入混合起來,稱為雙分支 Transformer 模塊(看網絡簡介中的圖)。第一個 Transformer Layer 作為 Q,第二個 Transformer Layer 作為 K 和 V。具體來說,首先,這兩個分支的輸入標記分別用自注意機制模擬 image-level 和 patches-level 的長距離依賴。然后,交叉注意機制被用于兩個分支的 tokens 之間的通信。在交叉注意機制中,將 patches-level 的標記表示為查詢 Q, image-level 分支的標記表示為下圖中多頭自我注意(MSA)層的鍵 Q 值 V。整體設計是很簡單的,實現了”Local Patches Meet Global Context“。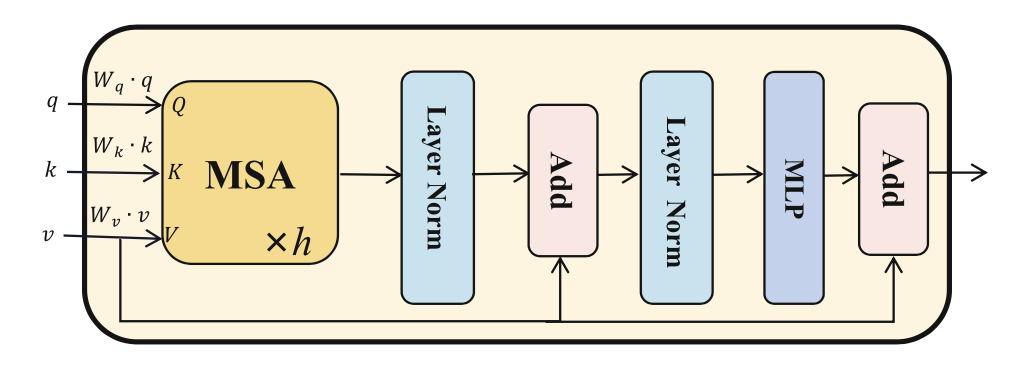
ASUB block
視網膜血管的一些固有特征導致了其分割困難,比如視網膜血管的分支很細,邊界很難區分,而且視網膜血管之間的關系很復雜。在這些情況下,視網膜血管周圍的背景信息對視網膜血管的分割至關重要。如下圖所示,傳統的方形卷積核在正常的上采樣塊中不能很好地捕捉線性特征,并且不可避免地引入了來自鄰近的不相關信息。為了更好地收集視網膜血管周圍的背景信息,提出了 Adaptive Strip Upsampling Block(ASUB),它適合于長而細的視網膜血管分布。
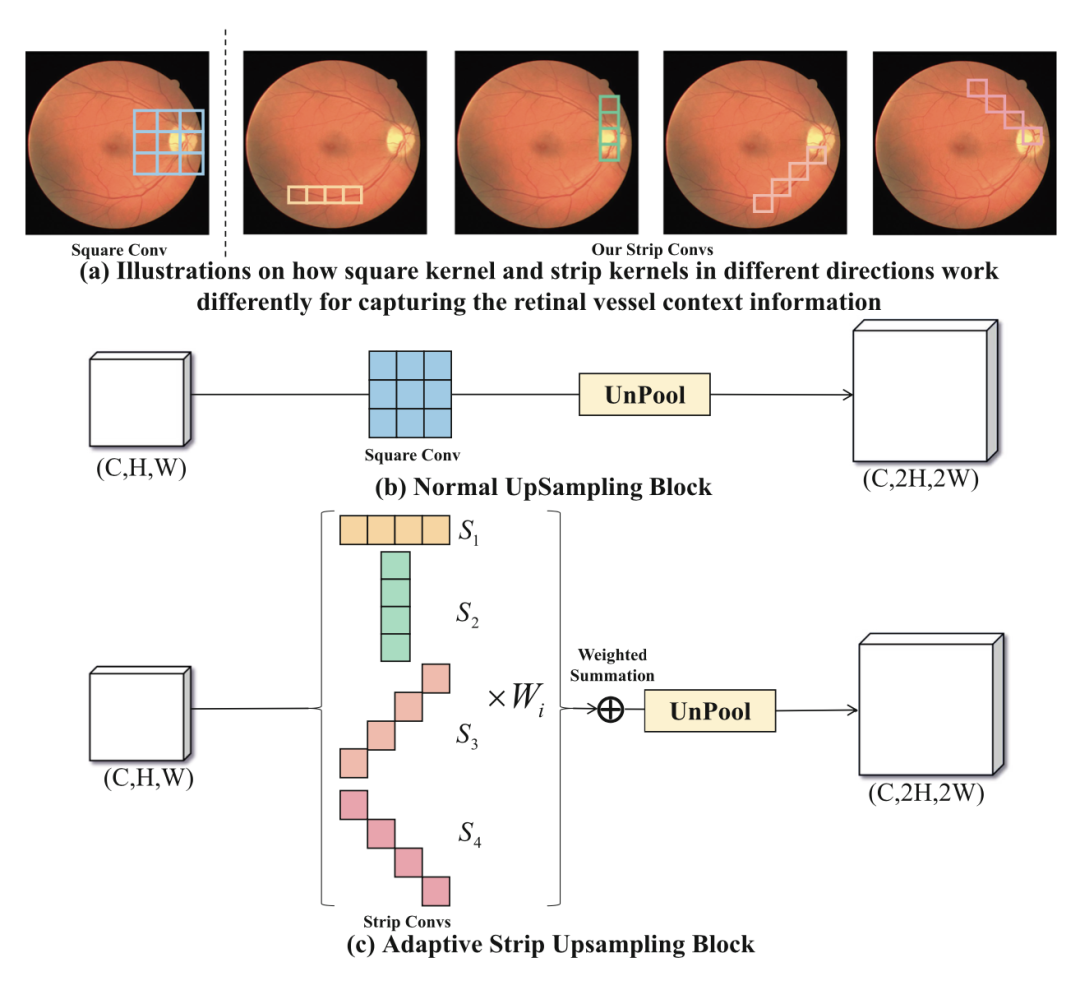 請添加圖片描述
請添加圖片描述
粗略看一下,在 (c) 中,一共有四種類型的條狀卷積核,捕捉水平(S1)、垂直(S2)、左對角線(S3)和右對角線(S4)方向上的信息。接下來,我們仔細分析下 ASUB 的思路,首先,使用一個 1×1 的 Conv 來將特征圖的維度減半,以減少計算成本。然后,利用四個帶狀卷積來捕捉來自不同方向的上下文信息。此外,做全局平均池化(GAP)來獲得通道維度的特征圖。在特征圖的通道維度上獲得特征向量,并使用全連接層來學習每個帶狀卷積的通道方向的注意立向量。之后,應用萬能的 softmax 來產生通道融合權重Wi , i∈{1, 2, 3, 4}。最后,我們用學到的自適應權重對每個帶狀卷積 Fi 的輸出進行加權,得到特征圖,特征圖是 4 個 Fi*Wi 求和。最后用 1×1 的 Conv 恢復維度,得到最終輸出 Foutput。同時,這部分是會增加網絡學習負擔的。
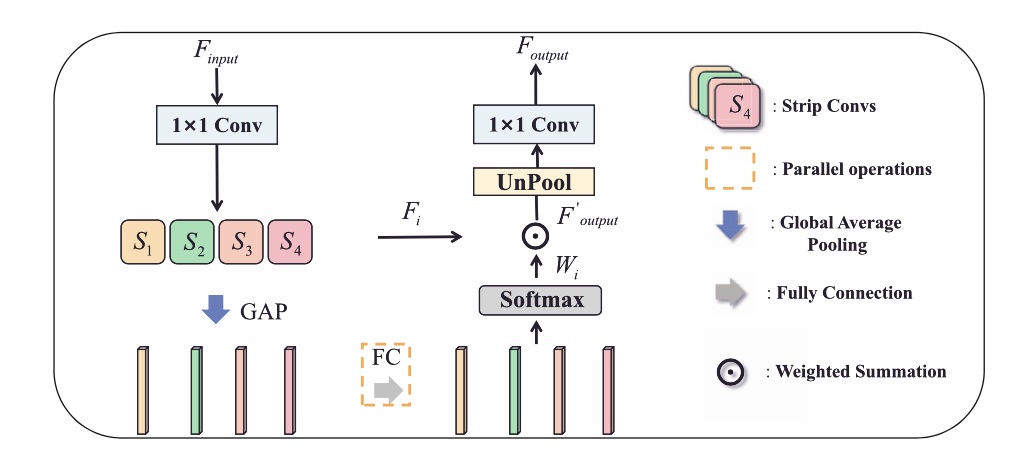 請添加圖片描述
請添加圖片描述
實驗
首先是和其他 SOTA 方法的比較,包括 image-level 和 patches-level 兩種,如下表。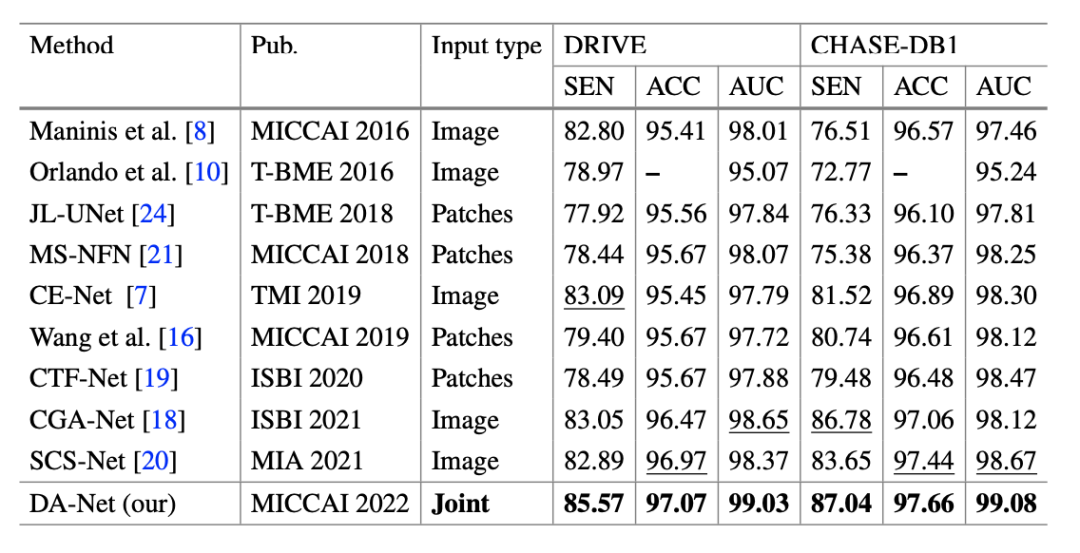
接下來是消融實驗的部分,其中的 Baseline 指 U-Net。注意到,FLOPs 和 參數量的增加是可以接受的。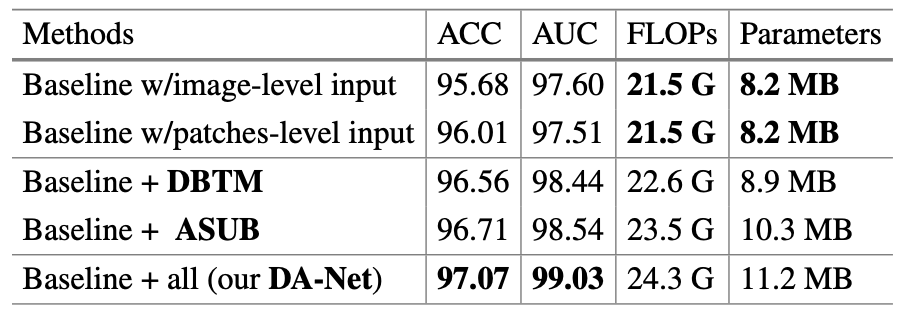
討論
其實 ASUB 設置的條形采樣方向也不一定與一些小血管的方向完全一致,這是可以進一步改進的地方。比如說嘗試可變形卷積(Deformable ConvNetsV2)的方式。
-
數據
+關注
關注
8文章
7249瀏覽量
91313 -
編碼
+關注
關注
6文章
967瀏覽量
55586 -
卷積
+關注
關注
0文章
95瀏覽量
18719 -
Transformer
+關注
關注
0文章
151瀏覽量
6426
原文標題:MICCAI 2022:使用自適應條形采樣和雙分支 Transformer 的 DA-Net
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自適應數字傳感器設計
自適應濾波器的相關資料推薦
自適應的弱選擇壓縮采樣匹配追蹤算法
基于雙評判準則自適應融合的跟蹤算法
視頻壓縮感知自適應改進
什么是自適應控制_自適應控制基本原理
自適應控制的優缺點_自適應控制存在的問題及發展

基于雙孿生網絡的自適應選擇跟蹤系統ASTS






 工商網監
工商網監
評論