") 深度模型Adan優(yōu)化器如何完成ViT的訓(xùn)練
深度模型Adan優(yōu)化器如何完成ViT的訓(xùn)練
自Google提出Vision Transformer(ViT)以來,ViT漸漸成為許多視覺任務(wù)的默認(rèn)backbone。憑借著ViT結(jié)構(gòu),許多視覺任務(wù)的SoTA都得到了進(jìn)一步提升,包括圖像分類、分割、檢測(cè)、識(shí)別等。
然而,訓(xùn)練ViT并非易事。除了需要較復(fù)雜的訓(xùn)練技巧,模型訓(xùn)練的計(jì)算量往往也較之前的CNN大很多。近日,新加坡Sea AI LAB (SAIL) 和北大ZERO Lab的研究團(tuán)隊(duì)共同提出新的深度模型優(yōu)化器Adan,該優(yōu)化器可以僅用一半的計(jì)算量就能完成ViT的訓(xùn)練。
此外,在計(jì)算量一樣的情況下, Adan在多個(gè)場(chǎng)景(涉及CV、NLP、RL)、多種訓(xùn)練方式(有監(jiān)督與自監(jiān)督)和多種網(wǎng)絡(luò)結(jié)構(gòu)/算法(Swin、ViT、ResNet、ConvNext、MAE、LSTM、BERT、Transformer-XL、PPO算法)上,均獲得了性能提升。
代碼、配置文件、訓(xùn)練log均已開源。
深度模型的訓(xùn)練范式與優(yōu)化器
隨著ViT的提出,深度模型的訓(xùn)練方式變得越來越復(fù)雜。常見的訓(xùn)練技巧包括復(fù)雜的數(shù)據(jù)增強(qiáng)(如MixUp、CutMix、AutoRand)、標(biāo)簽的處理(如label smoothing和noise label)、模型參數(shù)的移動(dòng)平均、隨機(jī)網(wǎng)絡(luò)深度、dropout等。伴隨著這些技巧的混合運(yùn)用,模型的泛化性與魯棒性均得到了提升,但是隨之而來的便是模型訓(xùn)練的計(jì)算量變得越來越大。
在ImageNet 1k上,訓(xùn)練epoch數(shù)從ResNet剛提出的90已經(jīng)增長到了訓(xùn)練ViT常用的300。甚至針對(duì)一些自監(jiān)督學(xué)習(xí)的模型,例如MAE、ViT,預(yù)訓(xùn)練的epoch數(shù)已經(jīng)達(dá)到了1.6k。訓(xùn)練epoch增加意味著訓(xùn)練時(shí)間極大的延長,急劇增加了學(xué)術(shù)研究或工業(yè)落地的成本。目前一個(gè)普遍的解決方案是增大訓(xùn)練的batch size并輔助并行訓(xùn)練以減少訓(xùn)練時(shí)間,但是伴隨的問題便是,大的batch size往往意味著performance的下降,并且batch size越大,情況越明顯。
這主要是因?yàn)槟P蛥?shù)的更新次數(shù)隨著batch size的增加在急劇減少。當(dāng)前的優(yōu)化器并不能在復(fù)雜的訓(xùn)練范式下以較少的更新次數(shù)實(shí)現(xiàn)對(duì)模型的快速訓(xùn)練,這進(jìn)一步加劇了模型訓(xùn)練epoch數(shù)的增長。
因此,是否存在一種新的優(yōu)化器能在較少的參數(shù)更新次數(shù)情況下更快更好地訓(xùn)練深度模型?在減少訓(xùn)練epoch數(shù)的同時(shí),也能緩解batch size增加帶來的負(fù)面影響?
被忽略的沖量
要想加速優(yōu)化器的收斂速度,最直接的方法便是引入沖量。近年提出的深度模型優(yōu)化器均沿用著Adam中使用的沖量范式——重球法:
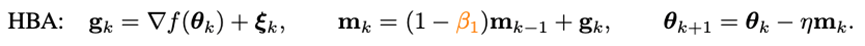
其中g(shù)_k是隨機(jī)噪聲,m_k是moment,eta是學(xué)習(xí)率。Adam將m_k的更新由累積形式換成了移動(dòng)平均的形式,并引入二階moment(n_k)對(duì)學(xué)習(xí)率進(jìn)行放縮,即:
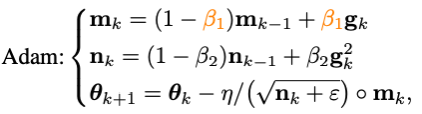
然而隨著Adam訓(xùn)練原始ViT失敗,它的改進(jìn)版本AdamW漸漸地變成了訓(xùn)練ViT甚至ConvNext的首選。但是AdamW并沒有改變Adam中的沖量范式,因此在當(dāng)batch size超過4,096的時(shí)候,AdamW訓(xùn)練出的ViT的性能會(huì)急劇下降。
在傳統(tǒng)凸優(yōu)化領(lǐng)域,有一個(gè)與重球法齊名的沖量技巧——Nesterov沖量算法:
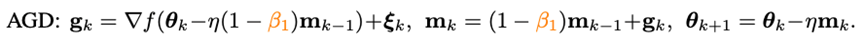
Nesterov沖量算法在光滑且一般凸的問題上,擁有比重球法更快的理論收斂速度,并且理論上也能承受更大的batch size。同重球法不同的是,Nesterov算法不在當(dāng)前點(diǎn)計(jì)算梯度,而是利用沖量找到一個(gè)外推點(diǎn),在該點(diǎn)算完梯度以后再進(jìn)行沖量累積。
外推點(diǎn)能幫助Nesterov算法提前感知當(dāng)前點(diǎn)周圍的幾何信息。這種特性使得Nesterov沖量更加適合復(fù)雜的訓(xùn)練范式和模型結(jié)構(gòu)(如ViT),因?yàn)樗⒉皇菃渭兊匾揽窟^去的沖量去繞開尖銳的局部極小點(diǎn),而是通過提前觀察周圍的梯度,調(diào)整更新的方向。
盡管Nesterov沖量算法擁有一定的優(yōu)勢(shì),但是在深度優(yōu)化器中,卻鮮有被應(yīng)用與探索。其中一個(gè)主要的原因就是Nesterov算法需要在外推點(diǎn)計(jì)算梯度,在當(dāng)前點(diǎn)更新,期間需要多次模型參數(shù)重載以及需要人為地在外推點(diǎn)進(jìn)行back-propagation (BP)。這些不便利性極大地限制了Nesterov沖量算法在深度模型優(yōu)化器中的應(yīng)用。
Adan優(yōu)化器
通過結(jié)合改寫的Nesterov沖量與自適應(yīng)優(yōu)化算法,并引入解耦的權(quán)重衰減,可以得到最終的Adan優(yōu)化器。利用外推點(diǎn),Adan可以提前感知周圍的梯度信息,從而高效地逃離尖銳的局部極小區(qū)域,以增加模型的泛化性。
1) 自適應(yīng)的Nesterov沖量
為了解決Nesterov沖量算法中多次模型參數(shù)重載的問題,研究人員首先對(duì)Nesterov進(jìn)行改寫:
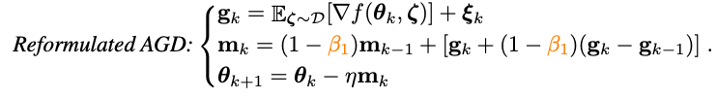
可以證明,改寫的Nesterov沖量算法與原算法等價(jià),兩者的迭代點(diǎn)可以相互轉(zhuǎn)化,且最終的收斂點(diǎn)相同。可以看到,通過引入梯度的差分項(xiàng),已經(jīng)可以避免手動(dòng)的參數(shù)重載和人為地在外推點(diǎn)進(jìn)行BP。
將改寫的Nesterov沖量算法同自適應(yīng)類優(yōu)化器相結(jié)合——將m_k的更新由累積形式替換為移動(dòng)平均形式,并使用二階moment對(duì)學(xué)習(xí)率進(jìn)行放縮:
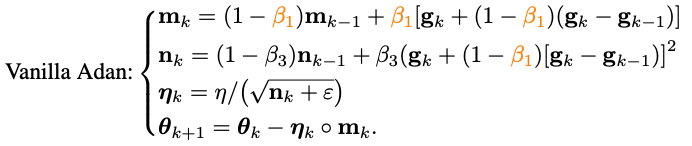
至此已經(jīng)得到了Adan的算法的基礎(chǔ)版本。
2) 梯度差分的沖量
可以發(fā)現(xiàn),m_k的更新將梯度與梯度的差分耦合在一起,但是在實(shí)際場(chǎng)景中,往往需要對(duì)物理意義不同的兩項(xiàng)進(jìn)行單獨(dú)處理,因此研究人員引入梯度差分的沖量v_k:
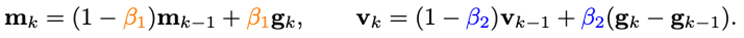
這里對(duì)梯度的沖量和其差分的沖量設(shè)置不同的沖量/平均系數(shù)。梯度差分項(xiàng)可以在相鄰梯度不一致的時(shí)候減緩優(yōu)化器的更新,反之,在梯度方向一致時(shí),加速更新。
3) 解耦的權(quán)重衰減
對(duì)于帶L2權(quán)重正則的目標(biāo)函數(shù),目前較流行的AdamW優(yōu)化器通過對(duì)L2正則與訓(xùn)練loss解耦,在ViT和ConvNext上獲得了較好的性能。但是AdamW所用的解耦方法偏向于啟發(fā)式,目前并不能得到其收斂的理論保證。
基于對(duì)L2正則解耦的思想,也給Adan引入解耦的權(quán)重衰減策略。目前Adan的每次迭代可以看成是在最小化優(yōu)化目標(biāo)F的某種一階近似:
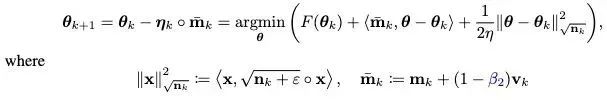
由于F中的L2權(quán)重正則過于簡(jiǎn)單且光滑性很好,以至于不需要對(duì)其進(jìn)行一階近似。因此,可以只對(duì)訓(xùn)練loss進(jìn)行一階近似而忽略L2權(quán)重正則,那么Adan的最后一步迭代將會(huì)變成:
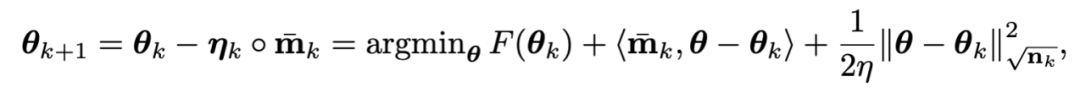
有趣的是,可以發(fā)現(xiàn)AdamW的更新準(zhǔn)則是Adan更新準(zhǔn)則在學(xué)習(xí)率eta接近0時(shí)的一階近似。因此,可從proximal 算子的角度給Adan甚至AdamW給出合理的解釋而不是原來的啟發(fā)式改進(jìn)。
4) Adan優(yōu)化器
將2)和3)兩個(gè)改進(jìn)結(jié)合進(jìn)Adan的基礎(chǔ)版本,可以得到如下的Adan優(yōu)化器。

Adan結(jié)合了自適應(yīng)優(yōu)化器、Nesterov沖量以及解耦的權(quán)重衰減策略的優(yōu)點(diǎn),能承受更大的學(xué)習(xí)率和batch size,以及可以實(shí)現(xiàn)對(duì)模型參數(shù)的動(dòng)態(tài)L2正則。
5) 收斂性分析
這里跳過繁復(fù)的數(shù)學(xué)分析過程,只給出結(jié)論:
定理:在給定或未給定Hessian-smooth條件的兩種情況下,Adan優(yōu)化器的收斂速度在非凸隨機(jī)優(yōu)化問題上均能達(dá)到已知的理論下界,并且該結(jié)論在帶有解耦的權(quán)重衰減策略時(shí)仍然成立。
實(shí)驗(yàn)結(jié)果
一、CV場(chǎng)景
1)有監(jiān)督學(xué)習(xí)——ViT模型
針對(duì)ViT模型,研究人員分別在ViT和Swin結(jié)構(gòu)上,測(cè)試了Adan的性能。

可以看到,例如在ViT-small、ViT-base、Swin-tiny以及Swin-base上,Adan僅僅消耗了一半的計(jì)算資源就獲得了同SoTA優(yōu)化器接近的結(jié)果,并且在同樣的計(jì)算量下,Adan在兩種ViT模型上均展現(xiàn)出較大的優(yōu)勢(shì)。
此外,也在大batch size下測(cè)試了Adan的性能:

可以看到,Adan在各種batch size下都表現(xiàn)得不錯(cuò),且相對(duì)于專為大batch size設(shè)計(jì)的優(yōu)化器(LAMB)也具有一定的優(yōu)勢(shì)。
2)有監(jiān)督學(xué)習(xí)——CNN模型
除了較難訓(xùn)練的ViT模型,研究人員也在尖銳局部極小點(diǎn)相對(duì)較少的CNN模型上也測(cè)試了Adan的性能——包括經(jīng)典的ResNet與較先進(jìn)的ConvNext。結(jié)果如下:
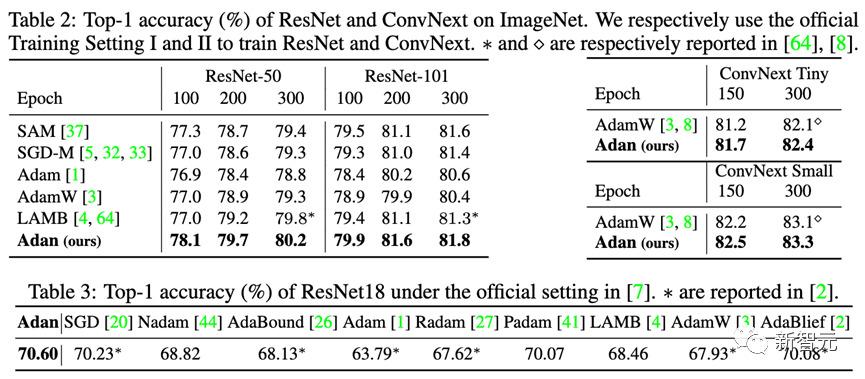
可以觀察到,不管是ResNet還是ConvNext,Adan均能在大約2/3訓(xùn)練epoch以內(nèi)獲得超越SoTA的性能。
3) 無監(jiān)督學(xué)習(xí)
在無監(jiān)督訓(xùn)練框架下,研究人員在最新提出的MAE上測(cè)試了Adan的表現(xiàn)。其結(jié)果如下:

同有監(jiān)督學(xué)習(xí)的結(jié)論一致,Adan僅消耗了一半的計(jì)算量就追平甚至超過了原來的SoTA優(yōu)化器,并且當(dāng)訓(xùn)練epoch越小,Adan的優(yōu)勢(shì)就越明顯。
二、NLP場(chǎng)景
1) 有監(jiān)督學(xué)習(xí)
在NLP的有監(jiān)督學(xué)習(xí)任務(wù)上,分別在經(jīng)典的LSTM以及先進(jìn)的Transformer-XL上觀察Adan的表現(xiàn)。
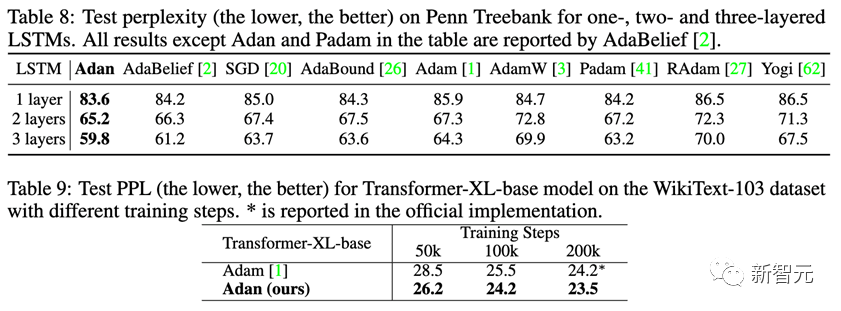
Adan在上述兩種網(wǎng)絡(luò)上,均表現(xiàn)出一致的優(yōu)越性。并且對(duì)于Transformer-XL,Adan在一半的訓(xùn)練步數(shù)內(nèi)就追平了默認(rèn)的Adam優(yōu)化器。
2) 無監(jiān)督學(xué)習(xí)
為了測(cè)試Adan在NLP場(chǎng)景下無監(jiān)督任務(wù)上的模型訓(xùn)練情況。研究人員從頭開始訓(xùn)練BERT:在經(jīng)過1000k的預(yù)訓(xùn)練迭代后,在GLUE數(shù)據(jù)集的7個(gè)子任務(wù)上測(cè)試經(jīng)過Adan訓(xùn)練的模型性能,結(jié)果如下:

Adan在所測(cè)試的7個(gè)詞句分類任務(wù)上均展現(xiàn)出較大的優(yōu)勢(shì)。值得一提的是,經(jīng)過Adan訓(xùn)練的BERT-base模型,在一些子任務(wù)上(例如RTE、CoLA以及SST-2)的結(jié)果甚至超過了Adam訓(xùn)練的BERT-large.
三、RL場(chǎng)景
研究人員將RL常用的PPO算法里的優(yōu)化器替換為了Adan,并在MuJoCo引擎中的4個(gè)游戲上測(cè)試了Adan的性能。在4個(gè)游戲中,用Adan作為網(wǎng)絡(luò)優(yōu)化器的PPO算法,總能獲得較高的reward。
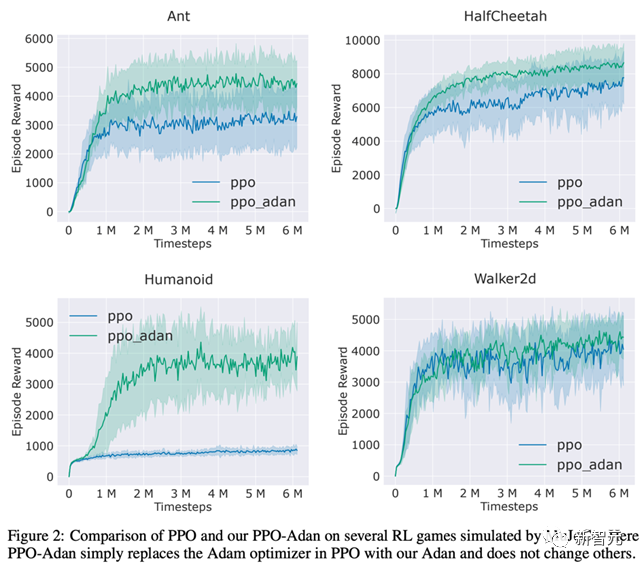
Adan在RL的網(wǎng)絡(luò)訓(xùn)練中,也表現(xiàn)出較大的潛力。
結(jié)論與展望
Adan優(yōu)化器為目前的深度模型優(yōu)化器引入了新的沖量范式。在復(fù)雜的訓(xùn)練范式下以較少的更新次數(shù)實(shí)現(xiàn)對(duì)模型的快速訓(xùn)練。
實(shí)驗(yàn)顯示,Adan僅需1/2-2/3的計(jì)算量就能追平現(xiàn)有的SoTA優(yōu)化器。
Adan在多個(gè)場(chǎng)景(涉及CV、NLP、RL)、多個(gè)訓(xùn)練方式(有監(jiān)督與自監(jiān)督)和多種網(wǎng)絡(luò)結(jié)構(gòu)(ViT、CNN、LSTM、Transformer等)上,均展現(xiàn)出較大的性能優(yōu)勢(shì)。此外,Adan優(yōu)化器的收斂速度在非凸隨機(jī)優(yōu)化上也已經(jīng)達(dá)到了理論下界。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7246瀏覽量
91110 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4371瀏覽量
64280 -
模型
+關(guān)注
關(guān)注
1文章
3499瀏覽量
50056
原文標(biāo)題:訓(xùn)練ViT和MAE減少一半計(jì)算量!Sea和北大提出新優(yōu)化器Adan:深度模型都能用!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何才能高效地進(jìn)行深度學(xué)習(xí)模型訓(xùn)練?
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
Pytorch模型訓(xùn)練實(shí)用PDF教程【中文】
深度融合模型的特點(diǎn)
深度學(xué)習(xí)模型是如何創(chuàng)建的?
探索一種降低ViT模型訓(xùn)練成本的方法

基于預(yù)訓(xùn)練模型和長短期記憶網(wǎng)絡(luò)的深度學(xué)習(xí)模型
什么是預(yù)訓(xùn)練 AI 模型?
什么是預(yù)訓(xùn)練AI模型?
深度學(xué)習(xí)框架區(qū)分訓(xùn)練還是推理嗎
深度學(xué)習(xí)如何訓(xùn)練出好的模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論