") 一文學(xué)會(huì)ByteHouse搭建數(shù)倉(cāng)最佳實(shí)踐
一文學(xué)會(huì)ByteHouse搭建數(shù)倉(cāng)最佳實(shí)踐
隨著數(shù)據(jù)的應(yīng)用場(chǎng)景越來(lái)越豐富,企業(yè)對(duì)數(shù)據(jù)價(jià)值反饋到業(yè)務(wù)中的時(shí)效性要求也越來(lái)越高,很早就有人提出過(guò)一個(gè)概念:數(shù)據(jù)的價(jià)值在于數(shù)據(jù)的在線化。實(shí)時(shí)計(jì)算起源于對(duì)數(shù)據(jù)加工時(shí)效性的嚴(yán)苛需求:數(shù)據(jù)的業(yè)務(wù)價(jià)值隨著時(shí)間的流逝會(huì)迅速降低,因此在數(shù)據(jù)產(chǎn)生后必須盡快對(duì)其進(jìn)行計(jì)算和處理,從而最大效率實(shí)現(xiàn)數(shù)據(jù)價(jià)值轉(zhuǎn)化,對(duì)實(shí)時(shí)數(shù)倉(cāng)的建設(shè)需求自然而然的誕生了。而建設(shè)好實(shí)時(shí)數(shù)倉(cāng)需要解決如下幾個(gè)問(wèn)題:
一、穩(wěn)定性:實(shí)時(shí)數(shù)倉(cāng)對(duì)數(shù)據(jù)的實(shí)時(shí)處理必須是可靠的、穩(wěn)定的;
二、高效數(shù)據(jù)集成:流式數(shù)據(jù)的集成必須方便高效,要求能進(jìn)行高并發(fā)、大數(shù)據(jù)量的寫(xiě)入;
三、極致性能要求:實(shí)時(shí)數(shù)倉(cāng)不能僅限于簡(jiǎn)單查詢(xún),需要支持復(fù)雜計(jì)算能力,且計(jì)算結(jié)果可秒級(jí)返回;
四、靈活查詢(xún):需要具備自助分析的能力,為業(yè)務(wù)分析提供靈活的、自助式的匯總和明細(xì)查詢(xún)服務(wù);
五、彈性擴(kuò)縮:需要具備良好的擴(kuò)展性, 必須架構(gòu)統(tǒng)一具備擴(kuò)展性,可為IT建設(shè)提供靈活性。
針對(duì)以上問(wèn)題,火山引擎不斷在業(yè)務(wù)中摸索,總結(jié)了基于 ByteHouse 建設(shè)實(shí)時(shí)數(shù)倉(cāng)的經(jīng)驗(yàn)。
選擇ByteHouse構(gòu)建實(shí)時(shí)數(shù)倉(cāng)的原因
ByteHouse 是火山引擎在 ClickHouse 的基礎(chǔ)上自研并大規(guī)模實(shí)踐的一款高性能、高可用企業(yè)級(jí)分析性數(shù)據(jù)庫(kù),支持用戶(hù)交互式分析 PB 級(jí)別數(shù)據(jù)。其自研的表引擎,靈活支持各類(lèi)數(shù)據(jù)分析和保證實(shí)時(shí)數(shù)據(jù)高效落盤(pán),實(shí)現(xiàn)了熱數(shù)據(jù)按生命周自動(dòng)冷存,緩解存儲(chǔ)空間壓力;同時(shí)引擎內(nèi)置了圖形化運(yùn)維界面,可輕松對(duì)集群服務(wù)狀態(tài)進(jìn)行運(yùn)維;整體架構(gòu)采用多主對(duì)等架構(gòu)設(shè)計(jì),架構(gòu)安全可靠穩(wěn)定,可確保單點(diǎn)無(wú)故障瓶頸。
ByteHouse 的架構(gòu)簡(jiǎn)潔,采用了全面向量化引擎,并配備全新設(shè)計(jì)的優(yōu)化器,查詢(xún)速度有數(shù)量級(jí)提升(尤其是多表關(guān)聯(lián)查詢(xún))。
用戶(hù)使用 ByteHouse 可以靈活構(gòu)建包括大寬表、星型模型、雪花模型在內(nèi)的各類(lèi)模型。
ByteHouse 可以滿(mǎn)足企業(yè)級(jí)用戶(hù)的多種分析需求,包括 OLAP 多維分析、定制報(bào)表、實(shí)時(shí)數(shù)據(jù)分析和 Ad-hoc 數(shù)據(jù)分析等各種應(yīng)用場(chǎng)景。
ByteHouse 優(yōu)勢(shì)一:實(shí)時(shí)數(shù)據(jù)高吞吐的接入能力
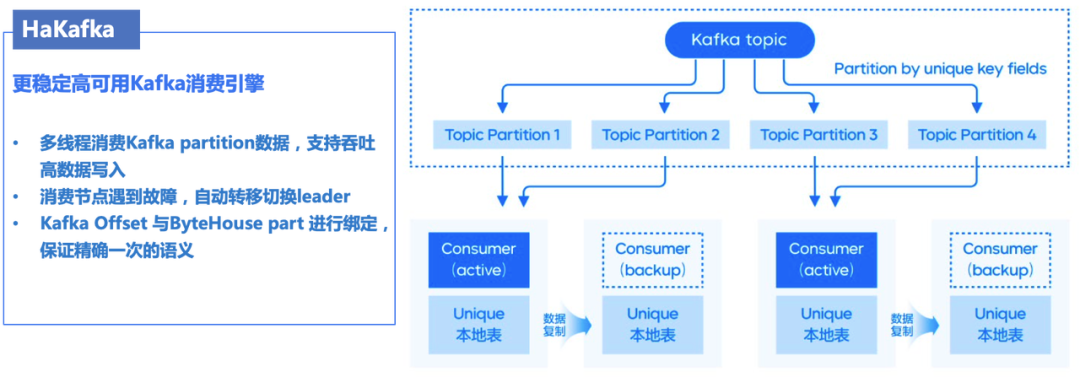
面對(duì)業(yè)務(wù)大數(shù)據(jù)量的產(chǎn)生,需要高效可靠實(shí)時(shí)數(shù)據(jù)的接入能力,為此我們自研了 Kafka 數(shù)據(jù)源接入表引擎 HaKafka ,該表引擎可高效的將 Kafka 的數(shù)據(jù)接入 ByteHouse ,具有有如下特性:
數(shù)據(jù)接入高吞吐性,支持了多線消費(fèi) Kafka topic 對(duì)應(yīng) Partition 的數(shù)據(jù),滿(mǎn)足大數(shù)據(jù)量實(shí)時(shí)數(shù)據(jù)接入的需求。
數(shù)據(jù)接入高可靠性,通過(guò) Zookeeper 來(lái)實(shí)現(xiàn)主備消費(fèi)節(jié)點(diǎn)管理,比如,當(dāng)線上出現(xiàn)某個(gè)節(jié)點(diǎn)出現(xiàn)故障或無(wú)法提供服務(wù)時(shí),可以通過(guò) Zookeeper 心跳感知機(jī)制自動(dòng)切換到另一個(gè)節(jié)點(diǎn)提供服務(wù),以此來(lái)保障業(yè)務(wù)的穩(wěn)定性。
數(shù)據(jù)接入原子性,引擎自行管理 Kafka offset ,將 offset 和 parts 進(jìn)行綁定在一起,來(lái)實(shí)現(xiàn)單批次消費(fèi)寫(xiě)入的原子性,當(dāng)中途消費(fèi)寫(xiě)入失敗,會(huì)自動(dòng)將綁定的 parts 撤銷(xiāo),從而實(shí)現(xiàn)數(shù)據(jù)消費(fèi)的穩(wěn)定性。
具體流程原理如下圖所示
ByteHouse 優(yōu)勢(shì)二:基于主鍵高頻數(shù)據(jù)更新能力
隨著實(shí)時(shí)數(shù)據(jù)分析場(chǎng)景的發(fā)展,對(duì)實(shí)時(shí)數(shù)據(jù)更新的分析需求也越來(lái)越多,比如在如下的業(yè)務(wù)場(chǎng)景就需要實(shí)時(shí)更新數(shù)據(jù)能力:
? 第一類(lèi)是業(yè)務(wù)需要對(duì)它的交易類(lèi)數(shù)據(jù)進(jìn)行實(shí)時(shí)分析,需要把數(shù)據(jù)流同步到 ByteHouse 這類(lèi) OLAP 數(shù)據(jù)庫(kù)中。大家知道,業(yè)務(wù)數(shù)據(jù)諸如訂單數(shù)據(jù)天生是存在更新的,所以需要 OLAP 數(shù)據(jù)庫(kù)去支持實(shí)時(shí)更新。
? 第二個(gè)場(chǎng)景和第一類(lèi)比較類(lèi)似,業(yè)務(wù)希望把TP數(shù)據(jù)庫(kù)的表實(shí)時(shí)同步到 ByteHouse,然后借助 ByteHouse 強(qiáng)大的分析能力進(jìn)行實(shí)時(shí)分析,這就需要支持實(shí)時(shí)的更新和刪除。
? 最后一類(lèi)場(chǎng)景的數(shù)據(jù)雖然不存在更新,但需要去重。大家知道在開(kāi)發(fā)實(shí)時(shí)數(shù)據(jù)的時(shí)候,很難保證數(shù)據(jù)流里沒(méi)有重復(fù)數(shù)據(jù),因此通常需要存儲(chǔ)系統(tǒng)支持?jǐn)?shù)據(jù)的冪等寫(xiě)入。
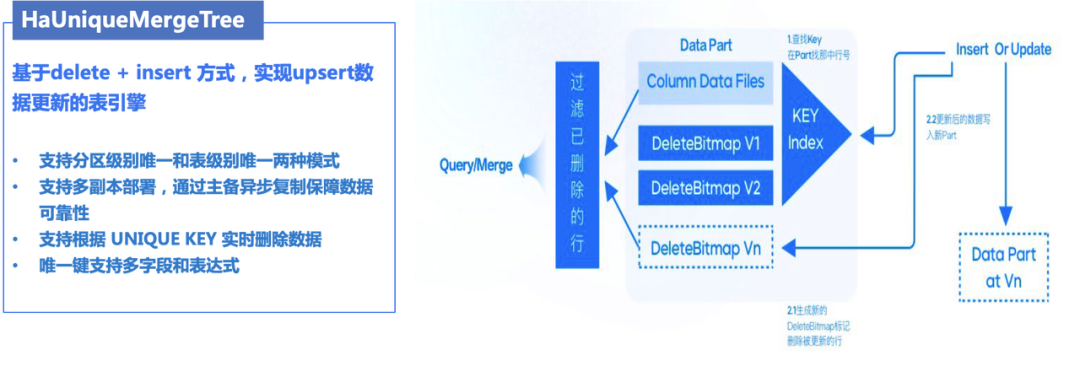
基于以上業(yè)務(wù)場(chǎng)景的需求,我們自研了基于主鍵更新數(shù)據(jù)的表引擎 HaUniqueMergeTree,該表引擎即滿(mǎn)足高效查詢(xún)性能要求,又支持基于主鍵更新數(shù)據(jù)的表引擎,有如下特性:
通過(guò)定義 Unique Key 唯一鍵,來(lái)提供數(shù)據(jù)實(shí)時(shí)更新的語(yǔ)義,唯一鍵的選擇支持多字段和表達(dá)式的模式;
支持分區(qū)級(jí)別數(shù)據(jù)唯一和表級(jí)別數(shù)據(jù)唯一兩種模式;
支持多副本高可靠部署,實(shí)測(cè)數(shù)據(jù)去重寫(xiě)入吞吐達(dá)每秒10萬(wàn)行以上(10w+/s),很好的解決了社區(qū)版 ReplacingMergreTree 不能高效更新數(shù)據(jù)的痛點(diǎn)。
具體流程原理如下圖所示
具體的原理細(xì)節(jié)可查閱之前發(fā)布的文章 干貨 | ClickHouse增強(qiáng)計(jì)劃之“Upsert”
ByteHouse 優(yōu)勢(shì)三:多表 Join 查詢(xún)能力
在構(gòu)建實(shí)時(shí)數(shù)據(jù)分析的場(chǎng)景中,我們常在數(shù)據(jù)加工的過(guò)程中,將多張表通過(guò)一些關(guān)聯(lián)字段打平成一張寬表,通過(guò)一張表對(duì)外提供分析能力,即大寬表模型。其實(shí)大寬表依然有它的局限性,一是,生成每一張大寬表都需要數(shù)據(jù)開(kāi)發(fā)人員不小的工作量,而且生成過(guò)程也需要一定的時(shí)間;二是,生成寬表會(huì)產(chǎn)生大量的數(shù)據(jù)冗余。針對(duì)寬表模型的局限性,我們從0到1自研實(shí)現(xiàn)了查詢(xún)優(yōu)化器,非常好的支持復(fù)雜查詢(xún)的需求,有如下特性:
兼容兩種 SQL 語(yǔ)法,支持 ANSI SQL 和原生 CLICKHOUSE SQL ;
支持基于RBO優(yōu)化能力,即支持:列裁剪、分區(qū)裁剪、表達(dá)式簡(jiǎn)化、子查詢(xún)解關(guān)聯(lián)、謂詞下推、冗余算子消除、Outer-JOIN 轉(zhuǎn) INNER-JOIN、算子下推存儲(chǔ)、分布式算子拆分等常見(jiàn)的啟發(fā)式優(yōu)化能力;
支持基于 CBO 優(yōu)化能力,基于 Cascade 搜索框架,實(shí)現(xiàn)了高效的 Join 枚舉算法,以及基于 Histogram 的代價(jià)估算,對(duì) 10 表全連接級(jí)別規(guī)模的 Join Reorder 問(wèn)題,能夠全量枚舉并尋求最優(yōu)解,同時(shí)針對(duì)大于10表規(guī)模的 Join Reorder 支持啟發(fā)式枚舉并尋求最優(yōu)解。CBO 支持基于規(guī)則擴(kuò)展搜索空間,除了常見(jiàn)的 Join Reorder 問(wèn)題以外,還支持 Outer-Join/Join Reorder,Magic Set Placement 等相關(guān)優(yōu)化能力;
分布式計(jì)劃優(yōu)化,面向分布式 MPP 數(shù)據(jù)庫(kù),生成分布式查詢(xún)計(jì)劃,并且和 CBO 結(jié)合在一起。相對(duì)業(yè)界主流實(shí)現(xiàn):分為兩個(gè)階段,首先尋求最優(yōu)的單機(jī)版計(jì)劃,然后將其分布式化。我們的方案則是將這兩個(gè)階段融合在一起,在整個(gè) CBO 尋求最優(yōu)解的過(guò)程中,會(huì)結(jié)合分布式計(jì)劃的訴求,從代價(jià)的角度選擇最優(yōu)的分布式計(jì)劃。對(duì)于 Join/Aggregate 的還支持 Partition 屬性展開(kāi)。
高階優(yōu)化能力,實(shí)現(xiàn)了 Dynamic Filter pushdown、單表物化視圖改寫(xiě)、基于代價(jià)的 CTE (公共表達(dá)式共享)。
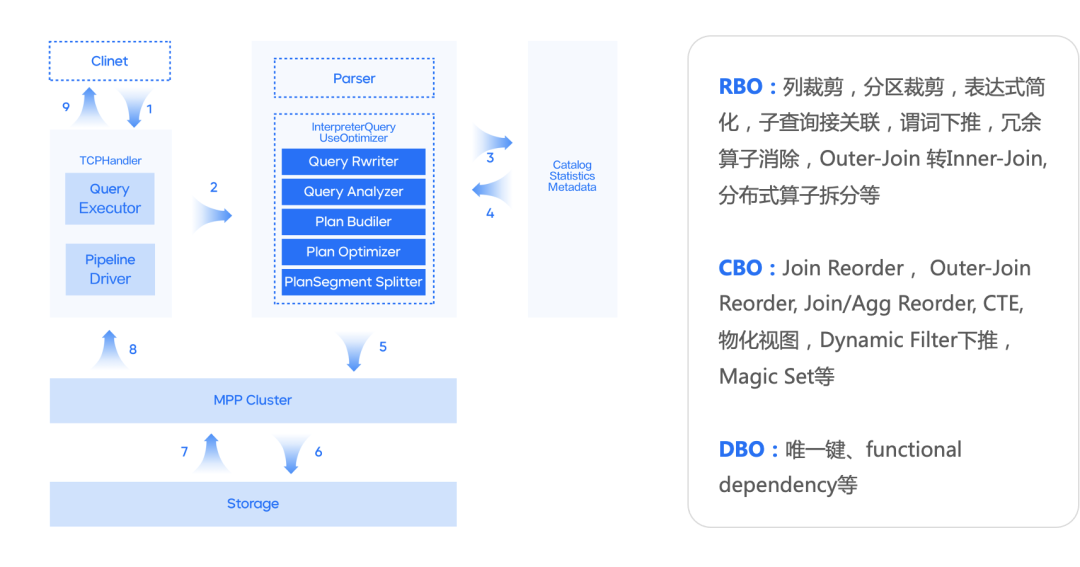
具體的原理細(xì)節(jié)可查閱之前發(fā)布的文章 干貨 | ClickHouse增強(qiáng)計(jì)劃之“查詢(xún)優(yōu)化器”
實(shí)時(shí)數(shù)倉(cāng)建設(shè)方案
借助Flink 出色流批一體的能力,ByteHouse極致的查詢(xún)性能,為用戶(hù)構(gòu)建實(shí)時(shí)數(shù)倉(cāng),滿(mǎn)足業(yè)務(wù)實(shí)時(shí)分析需求。
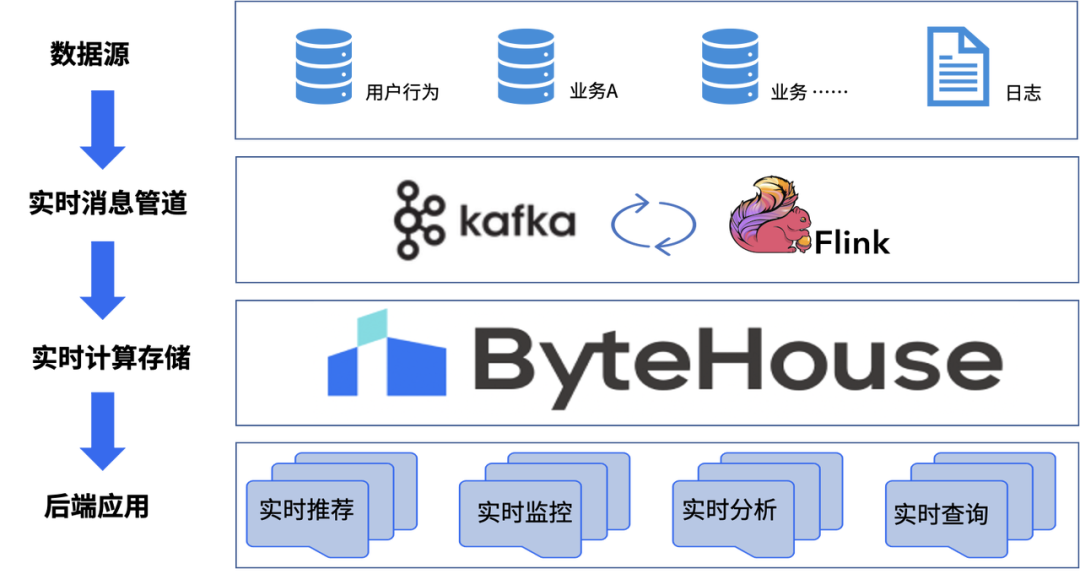
Flink 作為流式數(shù)據(jù)處理引擎,使用Flink SQL為整個(gè)實(shí)時(shí)數(shù)倉(cāng)數(shù)據(jù)提供數(shù)據(jù)轉(zhuǎn)化與清洗;
Kafka作為流式數(shù)據(jù)臨時(shí)存儲(chǔ)層,同時(shí)為Flink SQL 數(shù)據(jù)轉(zhuǎn)化與清洗提供緩沖作用,提高數(shù)據(jù)穩(wěn)定性;
ByteHouse 作為流式數(shù)據(jù)持久化存儲(chǔ)層,使用 ByteHouse HaKafka 、HaUniqueMergeTree 表引擎可將 Kafka 臨時(shí)數(shù)據(jù)高效穩(wěn)定接入儲(chǔ)存到 ByteHouse ,為后端應(yīng)用提供極速統(tǒng)一的數(shù)據(jù)集市查詢(xún)服務(wù)。具體的數(shù)據(jù)鏈路如下圖所示
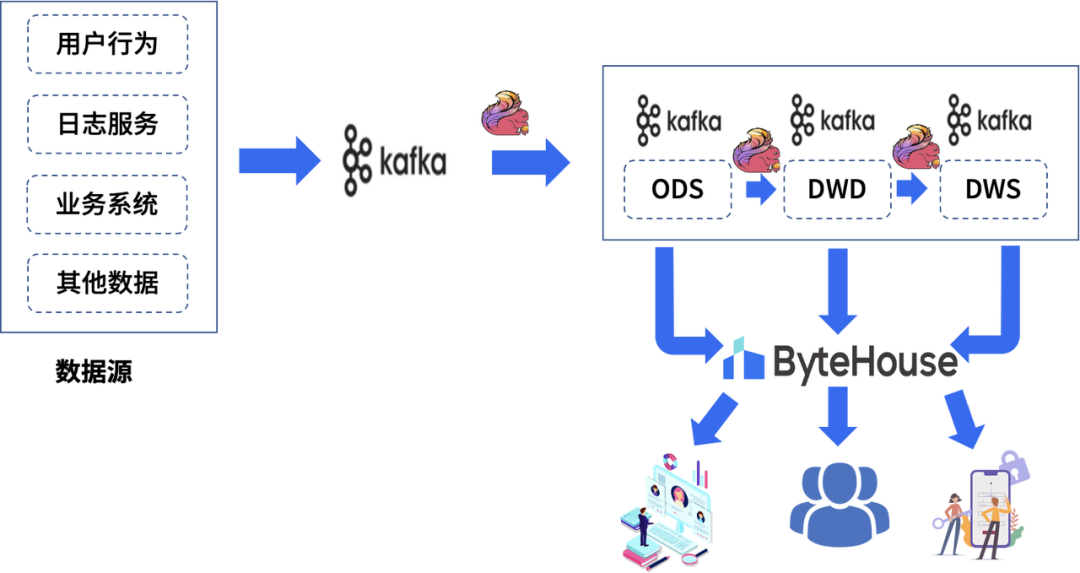
實(shí)時(shí)數(shù)倉(cāng)各邏輯層功能職責(zé)如下:
ODS 層(Operational Data Store)
把生產(chǎn)系統(tǒng)的數(shù)據(jù)導(dǎo)入消息隊(duì)列,原則上不做任何清洗操作,字段信息跟數(shù)據(jù)源保持一致。目的是為了對(duì)數(shù)據(jù)源做收斂管理,數(shù)據(jù)排查上也好做溯源回查。
DWD 層(Data Warehouse Detail)
DWD 層采用維度建模理論,針對(duì)業(yè)務(wù)內(nèi)容梳理業(yè)務(wù)實(shí)體的維表信息和事實(shí)表信息,設(shè)計(jì) DWD 明細(xì)寬表模型,根據(jù)設(shè)計(jì)好的邏輯模型對(duì) ODS 層的數(shù)據(jù)進(jìn)行數(shù)據(jù)清洗,重定義和整合,整合主要包含多流 join 和維度擴(kuò)充兩部分內(nèi)容, 建設(shè)能表達(dá)該業(yè)務(wù)主題下具體業(yè)務(wù)過(guò)程的多維明細(xì)寬表流。每一份 DWD 表從業(yè)務(wù)梳理->模型設(shè)計(jì)->數(shù)據(jù)流圖->任務(wù)開(kāi)發(fā)鏈接->數(shù)據(jù)校驗(yàn)結(jié)果->數(shù)據(jù)落地信息->常用使用場(chǎng)景歸納。
DWS 層(Data Warehouse Summary)
該層級(jí)主要在 DWD 層明細(xì)數(shù)據(jù)的基礎(chǔ)上針對(duì)業(yè)務(wù)實(shí)體跨業(yè)務(wù)主題域建設(shè)匯總指標(biāo),根據(jù)統(tǒng)計(jì)場(chǎng)景,設(shè)計(jì)匯總指標(biāo)模型。
APP 層(Application)
作為對(duì)接具體應(yīng)用的數(shù)倉(cāng)層級(jí),由 ByteHouse 提供統(tǒng)一的數(shù)據(jù)服務(wù),是基于 DWD 和 DWS 層對(duì)外提供一些定制化實(shí)時(shí)流。
ByteHouse 已經(jīng)在火山引擎上全面對(duì)外服務(wù),并且提供各種版本以滿(mǎn)足不同類(lèi)型用戶(hù)的需求。
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7246瀏覽量
91141 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3904瀏覽量
65818 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1470瀏覽量
34826
原文標(biāo)題:一文學(xué)會(huì) ByteHouse 搭建數(shù)倉(cāng)最佳實(shí)踐
文章出處:【微信號(hào):芋道源碼,微信公眾號(hào):芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
天馬榮獲新財(cái)富雜志“2024 ESG最佳實(shí)踐獎(jiǎng)”
曙光存儲(chǔ)入選2025年中國(guó)先進(jìn)存力最佳應(yīng)用實(shí)踐
SOLIDWORKS 2025教育版:緊密的產(chǎn)學(xué)研合作,搭建理論與實(shí)踐的橋梁
兆芯最佳實(shí)踐應(yīng)用場(chǎng)景解決方案發(fā)布
4G模組之UDP應(yīng)用的最佳實(shí)踐!

MES系統(tǒng)的最佳實(shí)踐案例
邊緣計(jì)算架構(gòu)設(shè)計(jì)最佳實(shí)踐
云計(jì)算平臺(tái)的最佳實(shí)踐
TMCS110x 布局挑戰(zhàn)和最佳實(shí)踐

衰減 AMC3301 系列輻射發(fā)射 EMI 的最佳實(shí)踐
毫米波雷達(dá)器件的放置和角度最佳實(shí)踐應(yīng)用
電機(jī)驅(qū)動(dòng)器電路板布局的最佳實(shí)踐
電科金倉(cāng):數(shù)智未來(lái),國(guó)產(chǎn)數(shù)據(jù)庫(kù)大有可為

MSP430 FRAM技術(shù)–使用方法和最佳實(shí)踐





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論