") ConvNeXt模型更新了!
ConvNeXt模型更新了!

ConvNeXt 模型更新了!
經(jīng)過幾十年的基礎(chǔ)研究,視覺識別領(lǐng)域已經(jīng)迎來了大規(guī)模視覺表征學(xué)習(xí)的新時代。預(yù)訓(xùn)練的大規(guī)模視覺模型已經(jīng)成為特征學(xué)習(xí)(feature learning)和視覺應(yīng)用的基本工具。視覺表征學(xué)習(xí)系統(tǒng)的性能在很大程度上受到三個主要因素的影響:模型的神經(jīng)網(wǎng)絡(luò)架構(gòu)、訓(xùn)練網(wǎng)絡(luò)的方法以及訓(xùn)練數(shù)據(jù)。每個因素的改進(jìn)都有助于模型整體性能的提高。
神經(jīng)網(wǎng)絡(luò)架構(gòu)設(shè)計的創(chuàng)新在表征學(xué)習(xí)領(lǐng)域一直發(fā)揮著重要作用。卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)(ConvNet)對計算機(jī)視覺研究產(chǎn)生了重大影響,使得各種視覺識別任務(wù)中能夠使用通用的特征學(xué)習(xí)方法,無需依賴人工實現(xiàn)的特征工程。近年來,最初為自然語言處理而開發(fā)的 transformer 架構(gòu)因其適用于不同規(guī)模的模型和數(shù)據(jù)集,在其他深度學(xué)習(xí)領(lǐng)域中也開始被廣泛使用。
ConvNeXt 架構(gòu)的出現(xiàn)使傳統(tǒng)的 ConvNet 更加現(xiàn)代化,證明了純卷積模型也可以適應(yīng)模型和數(shù)據(jù)集的規(guī)模變化。然而,要想對神經(jīng)網(wǎng)絡(luò)架構(gòu)的設(shè)計空間進(jìn)行探索,最常見方法仍然是在 ImageNet 上進(jìn)行監(jiān)督學(xué)習(xí)的性能基準(zhǔn)測試。
另一種思路是將視覺表征學(xué)習(xí)的重點從有標(biāo)簽的監(jiān)督學(xué)習(xí)轉(zhuǎn)向自監(jiān)督預(yù)訓(xùn)練。自監(jiān)督算法將掩碼語言建模引入視覺領(lǐng)域,并迅速成為視覺表征學(xué)習(xí)的一種流行方法。然而,自監(jiān)督學(xué)習(xí)通常會使用為監(jiān)督學(xué)習(xí)設(shè)計的架構(gòu),并假定該架構(gòu)是固定的。例如,掩碼自編碼器(MAE)使用了視覺 transformer 架構(gòu)。
有一種方法是將這些架構(gòu)和自監(jiān)督學(xué)習(xí)框架結(jié)合起來,但會面臨一些具體問題。例如,將 ConvNeXt 與 MAE 結(jié)合起來時就會出現(xiàn)如下問題:MAE 有一個特定的編碼 - 解碼器設(shè)計,該設(shè)計針對 transformer 的序列處理能力進(jìn)行了優(yōu)化,這使得計算量大的編碼器專注于那些可見的 patch,從而降低了預(yù)訓(xùn)練成本。但是這種設(shè)計可能與標(biāo)準(zhǔn)的 ConvNet 不兼容,因為后者使用了密集的滑動窗口。此外,如果不考慮架構(gòu)和訓(xùn)練目標(biāo)之間的關(guān)系,那么也就不清楚是否能達(dá)到最佳性能。事實上,已有研究表明用基于掩碼的自監(jiān)督學(xué)習(xí)來訓(xùn)練 ConvNet 是很困難的,而且實驗證據(jù)表明,transformer 和 ConvNet 可能在特征學(xué)習(xí)方面存在分歧,會影響到最終表征的質(zhì)量。
為此,來自 KAIST、Meta、紐約大學(xué)的研究者(包括ConvNeXt一作劉壯、ResNeXt 一作謝賽寧)提出在同一框架下共同設(shè)計網(wǎng)絡(luò)架構(gòu)和掩碼自編碼器,這樣做的目的是使基于掩碼的自監(jiān)督學(xué)習(xí)能夠適用于 ConvNeXt 模型,并獲得可與 transformer 媲美的結(jié)果。

論文地址:https://arxiv.org/pdf/2301.00808v1.pdf
在設(shè)計掩碼自編碼器時,該研究將帶有掩碼的輸入視為一組稀疏 patch,并使用稀疏卷積處理可見的部分。這個想法的靈感來自于在處理大規(guī)模 3D 點云時使用稀疏卷積。具體來說,該研究提出用稀疏卷積實現(xiàn) ConvNeXt,然后在微調(diào)時,權(quán)重不需要特殊處理就能被轉(zhuǎn)換回標(biāo)準(zhǔn)的密集網(wǎng)絡(luò)層。為了進(jìn)一步提高預(yù)訓(xùn)練效率,該研究用單個 ConvNeXt 替換 transformer 解碼器,使整個設(shè)計完全卷積網(wǎng)絡(luò)化。研究者觀察到加入這些變化后:學(xué)習(xí)到的特征是有用的并且改進(jìn)了基線結(jié)果,但微調(diào)后的性能仍然不如基于 transformer 的模型。
然后,該研究對不同訓(xùn)練配置的 ConvNeXt 的特征空間進(jìn)行了分析。當(dāng)直接在掩碼輸入上訓(xùn)練 ConvNeXt 時,研究者發(fā)現(xiàn) MLP 層存在潛在的特征崩潰(feature collapse)問題。為了解決這個問題,該研究提出添加一個全局響應(yīng)歸一化層(Global Response Normalization layer)來增強(qiáng)通道間的特征競爭。當(dāng)使用掩碼自編碼器對模型進(jìn)行預(yù)訓(xùn)練時,這種改進(jìn)最為有效,這表明監(jiān)督學(xué)習(xí)中重復(fù)使用監(jiān)督學(xué)習(xí)中的固定架構(gòu)設(shè)計可能不是最佳方法。
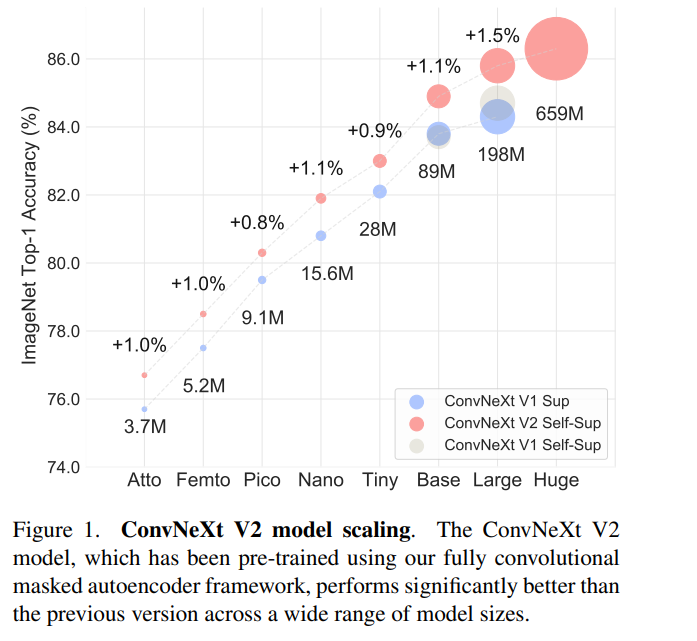
基于以上改進(jìn),該研究提出了 ConvNeXt V2,該模型在與掩碼自編碼器結(jié)合使用時表現(xiàn)出了更好的性能。同時研究者發(fā)現(xiàn) ConvNeXt V2 在各種下游任務(wù)上比純 ConvNet 有明顯的性能提升,包括在 ImageNet 上的分類任務(wù)、COCO 上的目標(biāo)檢測和 ADE20K 上的語義分割。
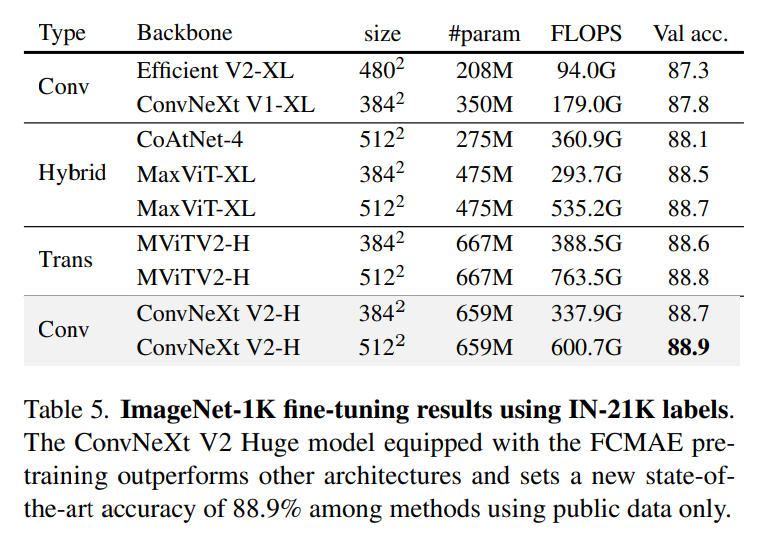
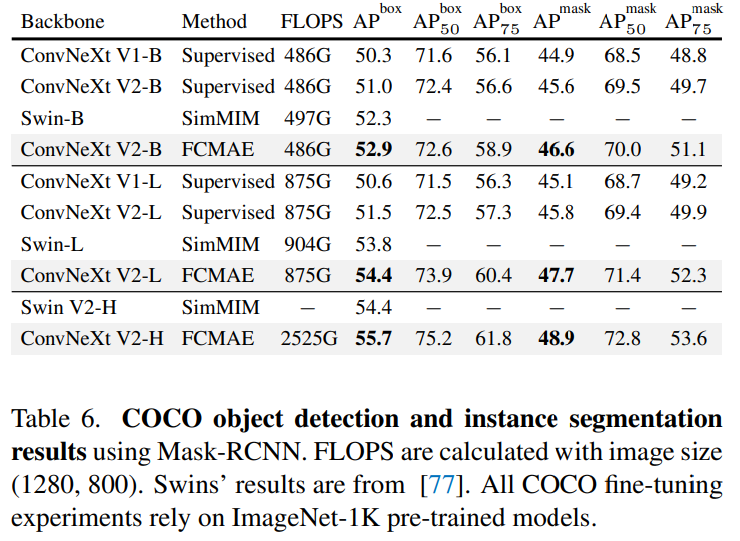
方法介紹
全卷積掩碼自編碼器
該研究提出的方法在概念上很簡單,是以完全卷積的方式運(yùn)行的。學(xué)習(xí)信號通過對原始的視覺輸入隨機(jī)掩碼來生成,同時掩碼的比率需要較高,然后再讓模型根據(jù)剩余的 context 預(yù)測缺失的部分。整體框架如下圖所示。
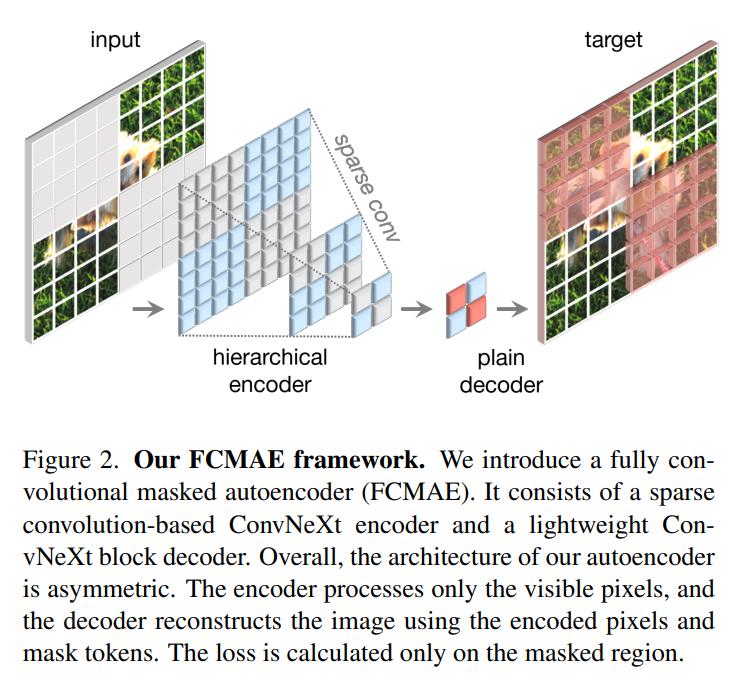
框架由一個基于稀疏卷積的 ConvNeXt 編碼器和一個輕量級的 ConvNeXt 解碼器組成,其中自編碼器的結(jié)構(gòu)是不對稱的。編碼器只處理可見的像素,而解碼器則使用已編碼的像素和掩碼 token 來重建圖像。同時只在被掩碼的區(qū)域計算損失。
全局響應(yīng)歸一化
大腦中有許多促進(jìn)神經(jīng)元多樣性的機(jī)制。例如,側(cè)向抑制可以幫助增強(qiáng)激活神經(jīng)元的反應(yīng),增加單個神經(jīng)元對刺激的對比度和選擇性,同時還可以增加整個神經(jīng)元群的反應(yīng)多樣性。在深度學(xué)習(xí)中,這種形式的側(cè)向抑制可以通過響應(yīng)歸一化(response normalization)來實現(xiàn)。該研究引入了一個新的響應(yīng)歸一化層,稱為全局響應(yīng)歸一化 (GRN),旨在增加通道間的對比度和選擇性。GRN 單元包括三個步驟:1) 全局特征聚合,2) 特征歸一化,3) 特征校準(zhǔn)。如下圖所示,可以將 GRN 層合并到原始 ConvNeXt 塊中。
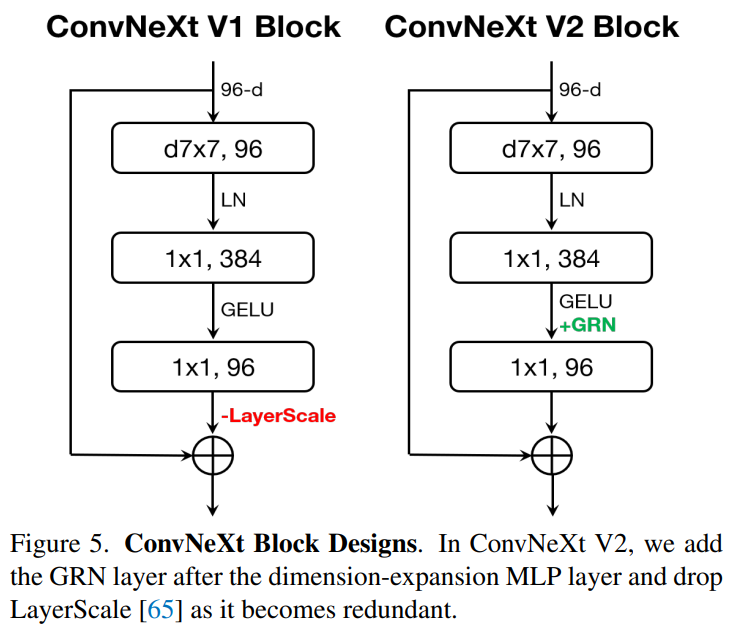
研究者根據(jù)實驗發(fā)現(xiàn),當(dāng)應(yīng)用 GRN 時,LayerScale 不是必要的并且可以被刪除。利用這種新的塊設(shè)計,該研究創(chuàng)建了具有不同效率和容量的多種模型,并將其稱為 ConvNeXt V2 模型族,模型范圍從輕量級(Atto)到計算密集型(Huge)。
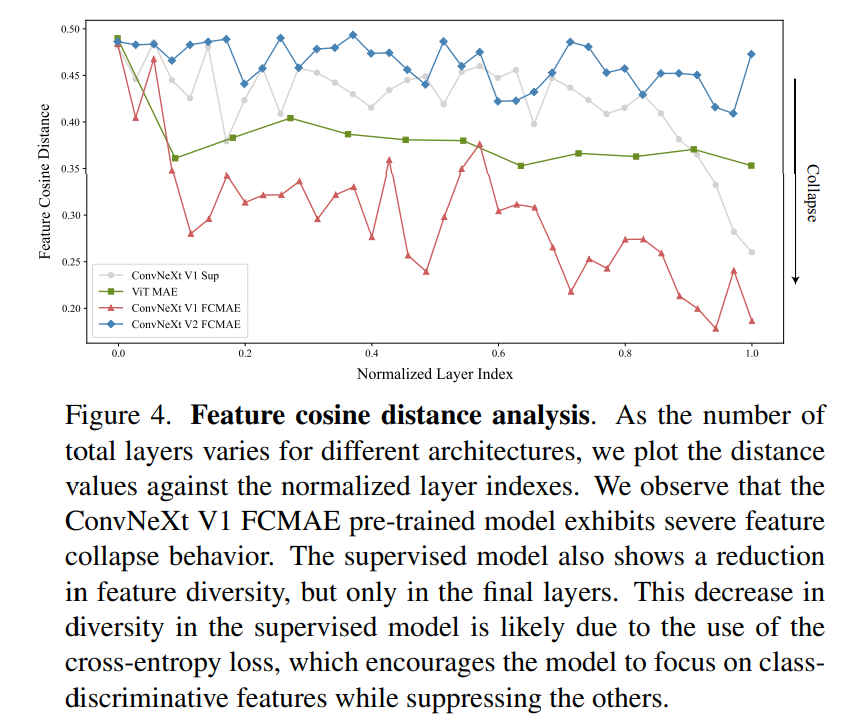
為了評估 GRN 的作用,該研究使用 FCMAE 框架對 ConvNeXt V2 進(jìn)行預(yù)訓(xùn)練。從下圖 3 中的可視化展示和圖 4 中的余弦距離分析,可以觀察到 ConvNeXt V2 有效地緩解了特征崩潰問題。余弦距離值一直很高,表明在網(wǎng)絡(luò)層傳遞的過程中可以保持特征的多樣性。這類似于使用 MAE 預(yù)訓(xùn)練的 ViT 模型。這表明在類似的掩碼圖像預(yù)訓(xùn)練框架下,ConvNeXt V2 的學(xué)習(xí)行為類似于 ViT。

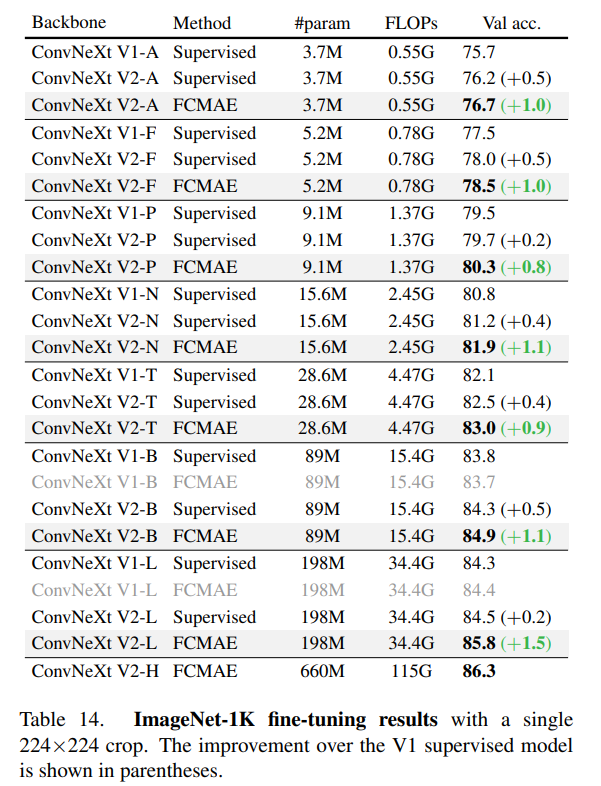
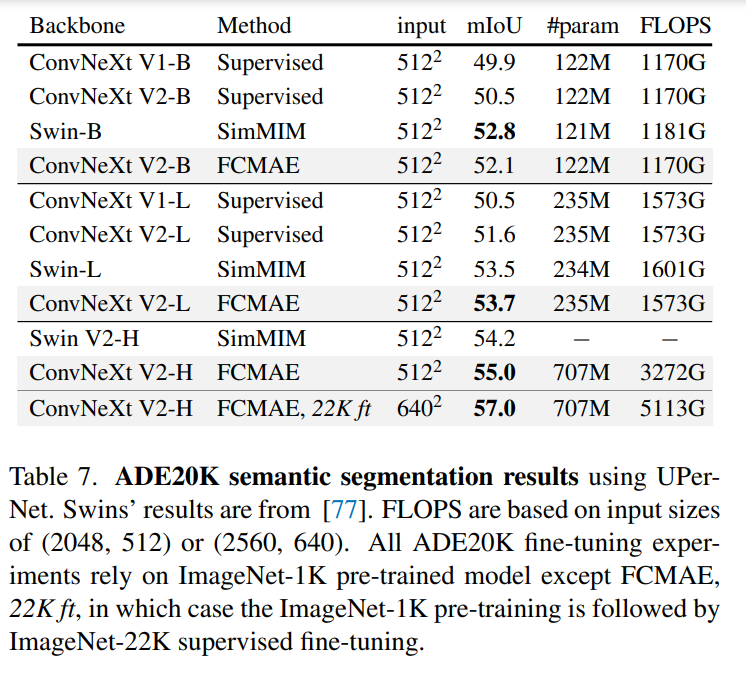
該研究進(jìn)一步評估了微調(diào)性能,結(jié)果如下表所示。
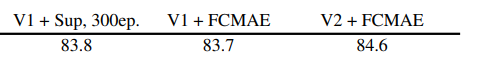
當(dāng)配備 GRN 時,F(xiàn)CMAE 預(yù)訓(xùn)練模型可以顯著優(yōu)于使用 300 個 epoch 訓(xùn)練得到的監(jiān)督模型。GRN 通過增強(qiáng)特征多樣性來提高表征質(zhì)量,這對于基于掩碼的預(yù)訓(xùn)練是至關(guān)重要的,并且在 ConvNeXt V1 模型中是不存在的。值得注意的是,這種改進(jìn)是在不增加額外參數(shù)開銷,且不增加 FLOPS 的情況下實現(xiàn)的。
最后,該研究還檢查了 GRN 在預(yù)訓(xùn)練和微調(diào)中的重要性。如下表 2 (f) 所示,無論是從微調(diào)中刪除 GRN,還是在微調(diào)時添加新初始化的 GRN,性能都會顯著下降,這表明在預(yù)訓(xùn)練和微調(diào)中 GRN 很重要。

審核編輯 :李倩
-
解碼器
+關(guān)注
關(guān)注
9文章
1176瀏覽量
42007 -
編碼器
+關(guān)注
關(guān)注
45文章
3808瀏覽量
138118 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6525
原文標(biāo)題:ConvNeXt V2來了,僅用最簡單的卷積架構(gòu),性能不輸Transformer
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
谷歌Gemini 2.5模型系列更新
深蘭科技醫(yī)療大模型榮獲MedBench評測第一
KaihongOS操作系統(tǒng)FA模型與Stage模型介紹
英偉達(dá)GTC2025亮點 NVIDIA推出Cosmos世界基礎(chǔ)模型和物理AI數(shù)據(jù)工具的重大更新
騰訊AI助手“騰訊元寶”重大更新:支持深度思考功能
騰訊元寶AI產(chǎn)品更新,正式接入DeepSeek R1模型
有了DeepSeek等AI大模型,人人都能當(dāng)醫(yī)生嗎?
簡述NVIDIA Isaac的重要更新

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
小米汽車接入VLM視覺語言大模型,OTA更新帶來多項升級
【「大模型啟示錄」閱讀體驗】對大模型更深入的認(rèn)知
車載大模型分析揭示:存儲帶寬對性能影響遠(yuǎn)超算力
PerfXCloud 重大更新 端側(cè)多模態(tài)模型 MiniCPM-Llama3-V 2.5 閃亮上架






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論