 NanoGPT,最簡單最快的庫來了!
NanoGPT,最簡單最快的庫來了!
訓練/微調中型GPT,最簡單最快的庫來了!
其名為:NanoGPT。
從名字就能看出是個“納米武器”,據作者介紹,該庫代碼簡單易讀,2個僅300行代碼的文件。
現已基于OpenWebText重現 GPT-2 (124M),在單個8XA100 40GB節點上,訓練時間為38小時。
值得一提的是,該庫發布者是前特斯拉AI總監,李飛飛高徒,Andrej Karpathy。此次發布的NanoGPT,正是他2年前MinGPT的升級版。

目前,此項目在GitHub所獲star已超6k,HackerNews上points也破千。

毫無意外地,評論區一片“喜大普奔”。
有網友表示,這才是咱獨立開發者喜聞樂見的AI工具。
還有人對其一直開放傳授分享知識的做法,表示感謝。
那么,這個最簡單最快的NanoGPT怎么用?
下面展開講講。
NanoGPT的打開方式
發布文件里面包含一個約300行的GPT模型定義(文件名:model.py),可以選擇從OpenAI加載GPT-2權重。
還有一個訓練模型PyTorch樣板(文件名:train.py),同樣也是300多行。
作者補充道,代碼并不難,很容易就能滿足大家需求——無論是從頭開始訓練新模型,還是基于預訓練進行微調(目前可用的最大模型為1.3B參數的GPT-2)。
△一個訓練實例展示
上手前,需要提前準備好依賴項:
-
pytorch <3
-
numpy <3
-
pip install datasets for huggingface datasets <3 (如果你需要下載和預處理OpenWebText)
-
pip install tiktoken for OpenAI’s fast BPE code <3
-
pip install wandb for optional logging <3
-
pip install tqdm
先下載并標記OpenWebText數據集。
$cddata/openwebtext
$pythonprepare.py
這將創建一個train.bin和val.bin文件,將 GPT2 BPE token id放入一個序列中。
然后準備訓練,目前腳本默認是嘗試重現GPT-2,124M參數版本,但作者更鼓勵大家閱讀代碼查看文件頂部的設置及路徑。
$pythontrain.py
如需使用 PyTorch 分布式數據并行 (DDP) 進行訓練,請使用 torchrun 運行腳本。
比如,要在4個GPU節點上運行,代碼如下:
$torchrun--standalone--nproc_per_node=4train.py
要從模型節點中采樣,就需將一些檢查點寫入輸入目錄中。
$pythonsample.py
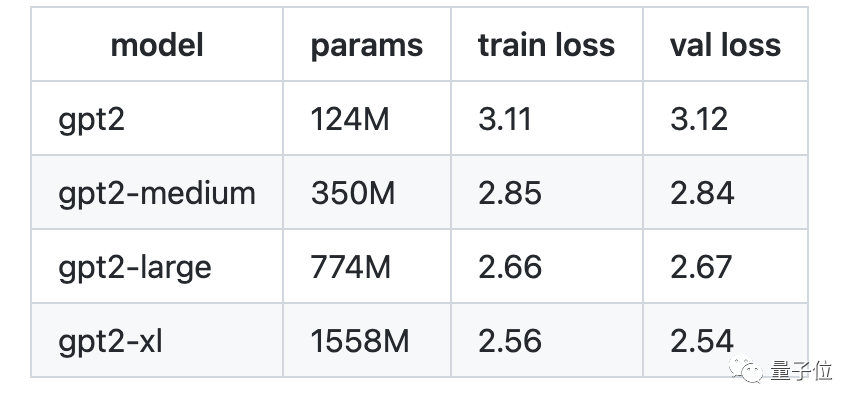
據作者目前自己的測試,他在1 個 A100 40GB GPU 上訓練一晚,損失約為 3.74。如果是在4個GPU上訓練損失約為3.60。
如果在8個A100 40GB節點上進行約50萬次迭代,時長約為1天,atim的訓練降至約3.1,init隨機概率是10.82,已將結果帶到了baseline范圍。
觀察不同參數下訓練/驗證loss值如下:
至于如何基于新文本微調GPT,作者也簡介了方法。
先訪問data/shakespeare,查看prepare.py。
下載小型shakespeare數據集并將其呈現為train.bin和val.bin文件(方法前文已介紹),幾秒即可搞定。
運行一個微調示例,如下:
$pythontrain.pyconfig/finetune_shakespeare.py
該操作將加載配置參數,覆蓋config/finetune_shakespeare.py文件。
作者指出,一般情況下,基本操作就是從GPT-2檢查點初始化init_from,再正常訓練。
此外,如果手里只有macbook或一些“力量”不足的小破本,作者建議使用shakespeare數據集,然后在一個很小的網絡上運行。
先渲染數據;
$cddata/shakespeare
$pythonprepare.py
再用一個較小的網絡來運行訓練腳本。
比如下面就創建了一個小得多的Transformer(4層,4個head,64嵌入大小),只在CPU運行,在作者自己的蘋果AIR M1本上,每次迭代大約需要400毫秒。
$cd../..
$pythontrain.py--dataset=shakespeare--n_layer=4--n_head=4--n_embd=64--device=cpu--compile=False--eval_iters=1--block_size=64--batch_size=8
關于NanoGPT的后續計劃,Andrej Karpathy也在網上有所分享。
他將試圖讓NanoGPT更快復現其他GPT-2模型,然后將預訓練擴展至更大規模的模型/數據集中,此外,他還計劃改進下微調部分的文檔。
轉戰教育和開源的特斯拉前AI總監
熟悉Karpathy的圈內人肯定知道,他此前是李飛飛高徒,也長期致力于讓更多人接觸了解神經網絡和相關數據集。
2020年8月,他就曾發布NanoGPT前一代,MinGPT,同樣旨在讓GPT做到小巧、簡潔、可解釋,同樣主打300行代碼搞定。
Karpathy另一大身份是前特斯拉AI核心人物。
在馬斯克麾下,他歷任特斯拉高級AI主管、特斯拉自動駕駛AutoPilot負責人、特斯拉超算Dojo負責人、特斯拉擎天柱人形機器人負責人…
2022年7月,Karpathy Andrej離職,在業內引發不小討論。他表示,未來將花更多時間在AI、開源技術教育上,比如他做了一檔AI課程,現還在更新中。
此番發布NanoGPT同時,Karpathy還下場安撫了下催更黨——新視頻正從0開始構建,計劃2周內發布。
最后附上:
NanoGPT項目:https://github.com/karpathy/nanoGPT
Andrej Karpathy課程:https://karpathy.ai/zero-to-hero.html
審核編輯 :李倩
-
模型
+關注
關注
1文章
3464瀏覽量
49838 -
代碼
+關注
關注
30文章
4882瀏覽量
70036 -
GPT
+關注
關注
0文章
368瀏覽量
15874
原文標題:300行代碼搞定!特斯拉前AI總監發布:NanoGPT,最簡單最快的庫來了!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Devart: dbForge Compare Bundle for SQL Server—比較SQL數據庫最簡單、最準確的方法
云數據庫是哪種數據庫類型?
騰訊ima升級知識庫功能,上線小程序實現共享與便捷問答
AMC7834只使用外部4個ADC,怎么配置可以使轉換速率達到最快?
HAL庫在Arduino平臺上的使用
HAL庫和標準庫的區別 HAL庫與CMSIS的關系
簡單認識libmodbus開發庫
在KiCad中使用AD的封裝庫(Pcblib)






 工商網監
工商網監
評論