") 基于DNN模型的ADS深度學(xué)習(xí)算法選型探討
基于DNN模型的ADS深度學(xué)習(xí)算法選型探討
對(duì)于自動(dòng)駕駛ADS行業(yè)而言,其核心演進(jìn)趨勢(shì)可以定義為群體智能的社會(huì)計(jì)算,簡(jiǎn)單表述為,用NPU大算力和去中心化計(jì)算來(lái)虛擬化駕駛環(huán)境,通過(guò)數(shù)字化智能體即自動(dòng)駕駛車(chē)輛AV的多模感知交互決策,以及車(chē)車(chē)協(xié)同,車(chē)路協(xié)同,車(chē)云協(xié)同,通過(guò)跨模數(shù)據(jù)融合、高清地圖重建、云端遠(yuǎn)程智駕等可信計(jì)算來(lái)構(gòu)建元宇宙中ADS的社會(huì)計(jì)算能力。
ADS算法的典型系統(tǒng)分層架構(gòu)一般包括傳感層,感知層,定位層,決策層(預(yù)測(cè)+規(guī)劃)和控制層。每個(gè)層面會(huì)采用傳統(tǒng)算法模型或者是與深度學(xué)習(xí)DNN模型相結(jié)合,從而在ADS全程駕駛中提供人類(lèi)可以認(rèn)可的高可靠和高安全性,以及在這個(gè)基礎(chǔ)上提供最佳能耗比、最佳用車(chē)體驗(yàn)、和用戶社交娛樂(lè)等基本功能。
01基于DNN模型的感知算法
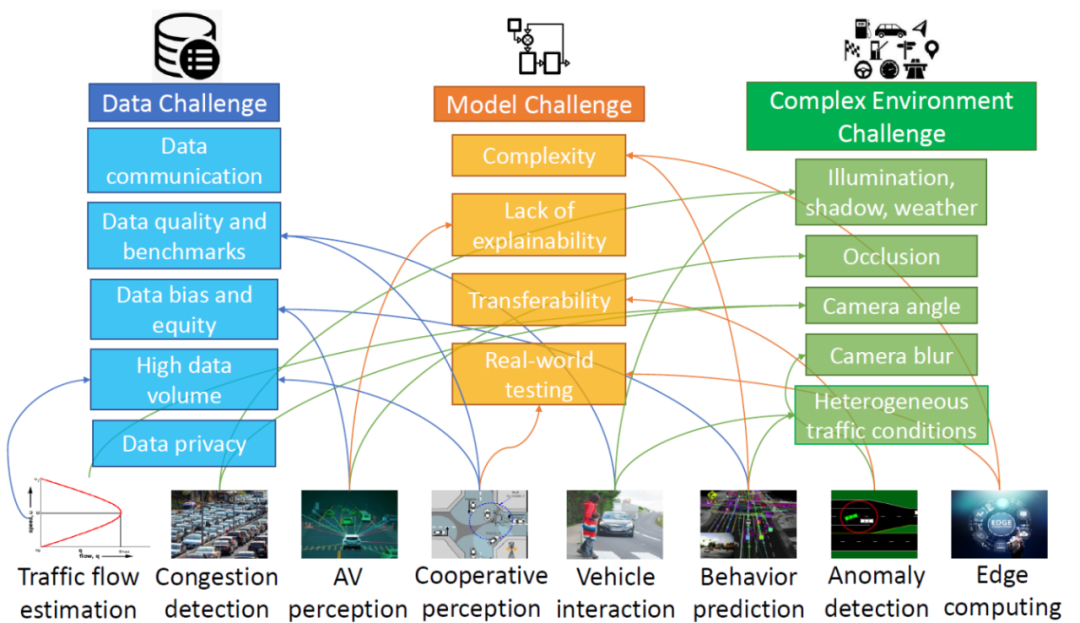
ADS部署的傳感器在極端惡劣場(chǎng)景(雨雪霧、低照度、高度遮擋、傳感器部分失效、主動(dòng)或被動(dòng)場(chǎng)景攻擊等)的影響程度是不一樣的。所以傳感器組合應(yīng)用可以來(lái)解決單傳感器的感知能力不足問(wèn)題,常用的多模傳感器包括Camera(Front-View or Multiview orSurround-View; Mono or Stereo;LD or HD),毫米波Radar(3Dor4D)和激光雷達(dá)LIDAR(LDorHD)。ADS的一個(gè)主要挑戰(zhàn)是多模融合感知,即如何在感知層能夠有效融合這些多模態(tài)傳感器的輸出,配合高清HD地圖或其它方式定位信息,對(duì)應(yīng)用場(chǎng)景中的交通標(biāo)識(shí),動(dòng)態(tài)目標(biāo)屬性(位置、速度、方向、高度、行為),紅綠燈狀態(tài),車(chē)道線,可駕駛區(qū)域,進(jìn)行特征提取共享和多任務(wù)的2D/3D目標(biāo)檢測(cè)、語(yǔ)義分割、在線地圖構(gòu)建、Occupancy特征和語(yǔ)義提取(Volume/Flow/Surface)等等。基于DNN模型的感知算法,在實(shí)際工程部署中的一個(gè)挑戰(zhàn),還需要解決圖 1所示的三個(gè)方向關(guān)鍵難題:數(shù)據(jù)挑戰(zhàn)、模型挑戰(zhàn)、和復(fù)雜場(chǎng)景挑戰(zhàn)。
 ?
?
圖 1DL算法在智能交通ITS和自動(dòng)駕駛領(lǐng)域ADS的部署挑戰(zhàn)(Azfar 2022) 目前大多數(shù)AI視覺(jué)感知任務(wù),包括目標(biāo)檢測(cè)跟蹤分類(lèi)識(shí)別,場(chǎng)景語(yǔ)義分割和目標(biāo)結(jié)構(gòu)化,其算法流程都可以簡(jiǎn)單總結(jié)為特征抽取,特征增強(qiáng)和特征融合,然后在特征空間進(jìn)行(采樣)重建,最后進(jìn)行多任務(wù)的各類(lèi)檢測(cè)識(shí)別與語(yǔ)義理解。以目標(biāo)檢測(cè)任務(wù)為例,一個(gè)主要的發(fā)展趨勢(shì),是從CNN (Compute-bound)向 Transformer (memory-bound)演進(jìn)。CNN目標(biāo)檢測(cè)方法包括常用的Two-Stage Candidate-based常規(guī)檢測(cè)方法(Faster-RCNN)和One-Stage Regression-based 快速檢測(cè)方法(YOLO, SSD, RetinaNet, CentreNet)。
Transformer目標(biāo)檢測(cè)方法包括DETR, Vision Transformer, Swin Transformer, DTR3D, BEVFormer, BEVFusion等等。兩者之間的主要差別是目標(biāo)感知場(chǎng)的尺寸,前者是局部視野,側(cè)重目標(biāo)紋理,后者是全局視野,從全局特征中進(jìn)行學(xué)習(xí),側(cè)重目標(biāo)形狀。可以看出針對(duì)各類(lèi)模型包括混合模型和通過(guò)NAS架構(gòu)搜索生成的模型,學(xué)術(shù)界和工業(yè)界在持續(xù)推陳出新,高速迭代,依舊呈現(xiàn)出多元多樣化態(tài)勢(shì),但如何有效進(jìn)行模型選型,以及模型小型化和工程化加速,一直是ADS產(chǎn)業(yè)算法能否成功落地的核心難題。
02基于DNN模型的決策算法
基于DNN模型的決策算法,是一種在數(shù)據(jù)充分的條件下,通過(guò)少量的人力投入就可以提供非常有力的設(shè)計(jì)表達(dá)。尤其是針對(duì)社交關(guān)系建模與推理來(lái)解決ADS中預(yù)測(cè)與規(guī)劃問(wèn)題,通過(guò)監(jiān)督和自監(jiān)督學(xué)習(xí)的方式,單獨(dú)或者聯(lián)合建模的方式,以及模仿學(xué)習(xí)IL和強(qiáng)化學(xué)習(xí)RL的學(xué)習(xí)流程。交互建模的輸入來(lái)自車(chē)輛狀態(tài),包括定位信息,速度,加速度,角速度,車(chē)輛朝向等。端到端的DL-based方法通常直接通過(guò)卷積處理原始傳感數(shù)據(jù)(RGB圖像和點(diǎn)云),計(jì)算簡(jiǎn)潔但會(huì)損失弱的或者隱含的交互推理的內(nèi)容表達(dá)。如圖 2所示,深度學(xué)習(xí)模型中的不同構(gòu)建模塊,是可以對(duì)多智能體的交互推理進(jìn)行有效建模和表達(dá)的,其中
(a)全連接FC層:又稱(chēng)多層感知器MLP,其中所有輸入通過(guò)連接可以與輸出交互并對(duì)輸出做出貢獻(xiàn)。 (b)卷積CONV層:卷積層采用局部感知場(chǎng),所以每層的連接會(huì)比較稀疏,通常假定合適用來(lái)捕獲空間關(guān)系,最初的底層卷積層一般提取類(lèi)似邊緣紋理類(lèi)的信息,越接近頂層也偏語(yǔ)義特征。 (c)遞歸Recurrent層 :通常用來(lái)處理時(shí)間維度的數(shù)據(jù)序列,多用來(lái)捕獲時(shí)間關(guān)系。 (d)圖Graph層:典型的圖包括節(jié)點(diǎn)、邊(用來(lái)描述節(jié)點(diǎn)間關(guān)系)、和上下文全局屬性,通常用來(lái)捕獲圖結(jié)構(gòu)表征中顯性關(guān)系推理,與FC層和RNN層一個(gè)不同之處是輸入的先后次序不會(huì)影響結(jié)構(gòu),圖結(jié)構(gòu)還可以處理不同數(shù)目的個(gè)體,比較適合多個(gè)體的ADS環(huán)境。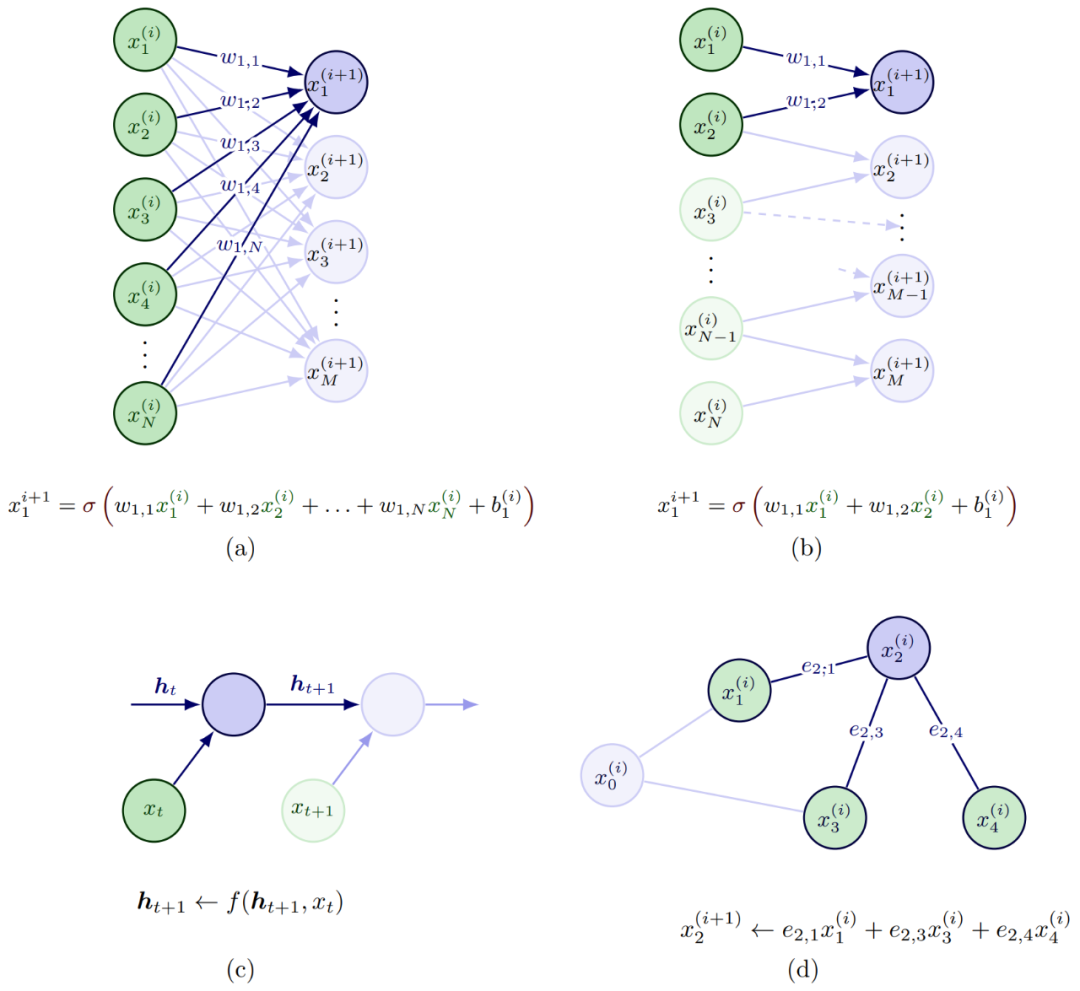 ?
?
圖 2DNN模塊對(duì)多智能體交互的建模案例(Wang 2022) 對(duì)于ADS中社交特征表征,常用的有空間時(shí)間狀態(tài)特征矢量,空間占用方格和圖區(qū)域動(dòng)態(tài)插入等方式。空時(shí)狀態(tài)特征矢量比較難以定義,尤其是個(gè)體數(shù)量變化和有效時(shí)間步長(zhǎng)的不同,另外一個(gè)限制是依賴(lài)于個(gè)體插入的次序。所以一個(gè)常用的設(shè)計(jì)思路是采用占用方格地圖Occupancy Grid Map (OGM)來(lái)解決上述的兩個(gè)問(wèn)題。OGM是以本體ego agent為中心來(lái)構(gòu)建空間方格圖,可以處理ROI區(qū)域不同數(shù)目的智能體。OGM通常采用原始狀態(tài)(定位,速度,加速度)或者采用FC層來(lái)進(jìn)行狀態(tài)編碼,如果FC層隱層包括個(gè)體的歷史軌跡信息,可以同時(shí)捕獲空間時(shí)間信息。
OGM的分辨率對(duì)計(jì)算性能影響比較大。 相對(duì)而言,圖網(wǎng)絡(luò)GNN可以通過(guò)動(dòng)態(tài)插入?yún)^(qū)域DIA抽取來(lái)更好地構(gòu)建空間時(shí)間交互圖關(guān)系,圖的類(lèi)型可以基于個(gè)體(車(chē)輛,行人,機(jī)動(dòng)車(chē)等),也可以基于區(qū)域area,后者主要聚焦對(duì)車(chē)輛意圖(車(chē)道保持,換道并道,左拐右拐)的表征,這里DIA指的是可駕駛場(chǎng)景中空閑空隔。如圖 3所示,DIA的優(yōu)勢(shì)在于對(duì)環(huán)境中靜態(tài)元素(道路拓?fù)洌?lèi)似stop道路標(biāo)志牌等)和動(dòng)態(tài)元素(行駛車(chē)輛)非常靈活,可以認(rèn)為是動(dòng)態(tài)環(huán)境的統(tǒng)一表征或者也可以叫做環(huán)境的虛擬化。所有時(shí)間地平線的DIAs可以用來(lái)構(gòu)建空間時(shí)間語(yǔ)義圖。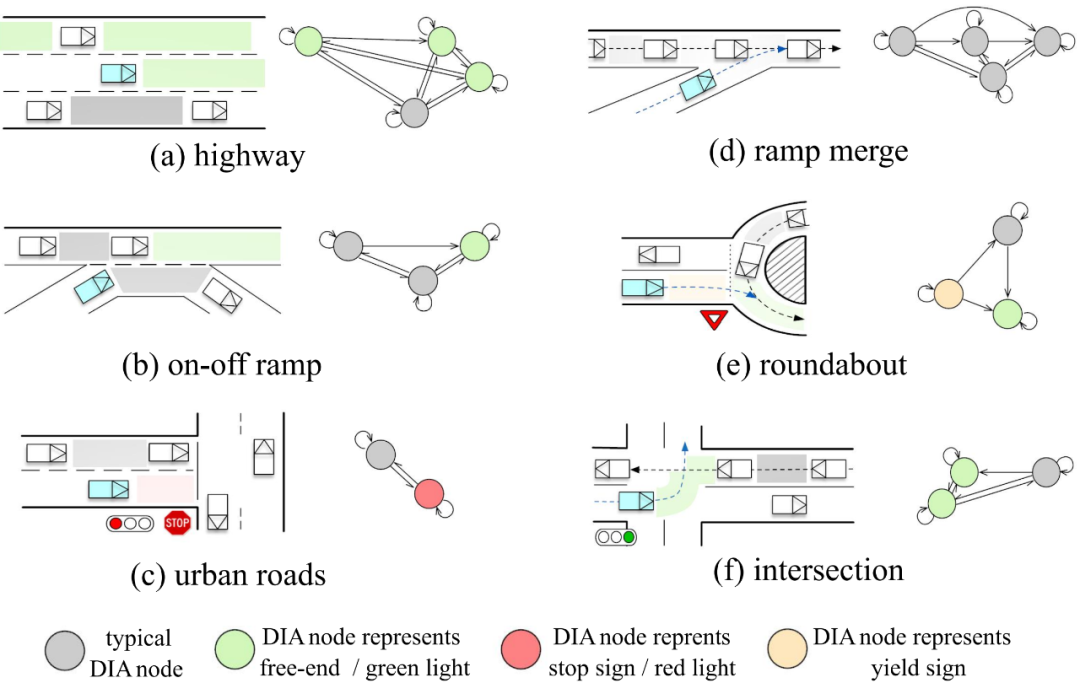 ?
?
圖 3動(dòng)態(tài)插入?yún)^(qū)域抽取和場(chǎng)景語(yǔ)義圖構(gòu)建案例(Wang 2022) 如圖 2所示,群體智能的社會(huì)計(jì)算,其中的社交關(guān)系,可以采用不同的深度學(xué)習(xí)層來(lái)進(jìn)行交互建模和編碼:
FC層交互編碼:采用將不同個(gè)體的特征進(jìn)行拉平,拼接成一個(gè)向量。多用來(lái)對(duì)單體single agent進(jìn)行運(yùn)動(dòng)和意圖建模,很少用于multiple agent。
CONV層交互編碼:將空間時(shí)間特征(狀態(tài)特征張量)或占用方格地圖做為CNN輸入來(lái)進(jìn)行交互編碼。
Recurrent層交互編碼:多采用LSTM來(lái)進(jìn)行時(shí)間維度推理,編碼產(chǎn)生的embedding張量可以捕獲時(shí)間空間的交互信息。
Graph層交互編碼:對(duì)多智能體之間的關(guān)系采用節(jié)點(diǎn)之間的無(wú)向或者有向邊來(lái)表征,可以用消息傳遞機(jī)制來(lái)進(jìn)行交互學(xué)習(xí),每個(gè)節(jié)點(diǎn)通過(guò)聚集鄰近節(jié)點(diǎn)的特征來(lái)更新自身的屬性特征。
在實(shí)際設(shè)計(jì)中,多將Recurrent層和Graph層相結(jié)合,可以很好地處理時(shí)間信息。而注意力attention機(jī)制編碼可以更好地量化一個(gè)特征如何影響其它特征。人類(lèi)司機(jī)會(huì)在交互場(chǎng)景中有選擇地選取其它個(gè)體來(lái)進(jìn)行關(guān)注,包括其過(guò)去現(xiàn)在的信息和未來(lái)的預(yù)判。所以注意力機(jī)制編碼可以基于時(shí)間域(短期的和長(zhǎng)期的)和空間域(本地的和偏遠(yuǎn)的),在上述方法中通過(guò)加權(quán)方案分別進(jìn)行應(yīng)用。對(duì)個(gè)體的注意力建模,可以采用基于距離的方法,這意味著其它個(gè)體越近,關(guān)注度也越高。 綜上所述,DL-based方法由于模塊化的設(shè)計(jì)和海量數(shù)據(jù)貢獻(xiàn),性能占優(yōu),但如何能夠提供模型的安全能力和大規(guī)模部署,需要解決幾個(gè)挑戰(zhàn):在保證性能基礎(chǔ)上改善可解釋性;在不同的駕駛個(gè)體,場(chǎng)景和態(tài)勢(shì)下繼續(xù)增強(qiáng)模型的推廣能力;模型選型和工程實(shí)現(xiàn)如何有效加速落地問(wèn)題。
03CNN與Transformer選型對(duì)比探討
Transformer或Transformer + CNN + RNN混合模型選型呈現(xiàn)出了高效的算法性能,對(duì)應(yīng)在工程實(shí)現(xiàn)上也開(kāi)始主導(dǎo)整個(gè)ADS行業(yè)市場(chǎng)。Transformer采用Attention機(jī)制的主干網(wǎng)絡(luò),而CNN在特征提取和變換上由Convolution來(lái)主導(dǎo),深度理解兩種模型的主要收益到底來(lái)自什么樣的算法模塊或者算子,對(duì)ADS主流算法的未來(lái)演進(jìn),可能會(huì)有一種積極的推動(dòng)作用。
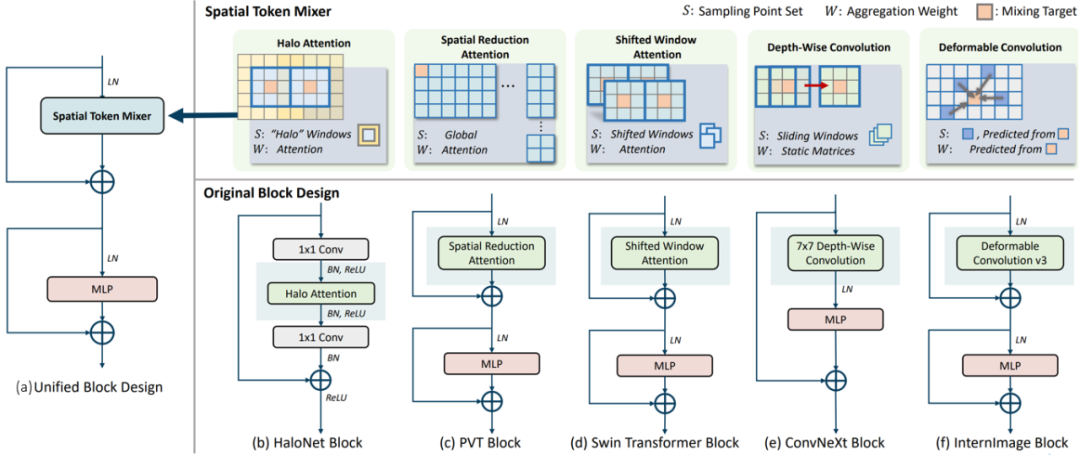
一種看法(Dai 2022)認(rèn)為,這主要的差別來(lái)自特征變換模塊(Attention vs Convolution)對(duì)空間特征聚類(lèi)的處理方式,即所謂的Spatial Token Mixer(STM)問(wèn)題。當(dāng)前常用構(gòu)建DNN網(wǎng)絡(luò)模型包括Attention, Convolution, Hybrid等模塊的多種變形,以分類(lèi)算法為例,先后有HaloNet(Halo Attention), PVT(Spatial Reduction Attention, 2021), Swin Transformer(Shifted Window Attention, 2021), ConvNeXt(7x7 Depth-Wise Convolution, 2022), InternImage (Deformable Convolution v3, 2022)等SOTA模型出世。 ?
?  ?
?
圖 4特征變換模塊的實(shí)現(xiàn)案例(Dai 2022) 如圖 4所示,CNN和Transformer模型中最常用的四種STM算子類(lèi)型包括:Local Attention, Global Attention, Depth-Wise Convolution, Dynamic Convolution。采用固定感知場(chǎng)的Static Convolution只在小容量模型(~5MB參數(shù))中表現(xiàn)不錯(cuò),而Local-Attention STM模型結(jié)合跨窗間信息轉(zhuǎn)移策略可以顯著提升性能。
STM的設(shè)計(jì)也反映了假定空間即歸納偏置中采用的先驗(yàn)知識(shí)和約束條件對(duì)模型學(xué)習(xí)的影響,包括局部特性Locality、平移不變性,旋轉(zhuǎn)不變性和尺寸不變性等模型特性,這可以從有效感知場(chǎng)ERF與下游多任務(wù)學(xué)習(xí)的關(guān)聯(lián)關(guān)系來(lái)體現(xiàn),有趣的是,當(dāng)上調(diào)模型參數(shù)時(shí),擴(kuò)大ERF反而會(huì)導(dǎo)致模型飽和,同樣我們工程實(shí)現(xiàn)中也觀察到,對(duì)特征提取backbone而言用CNN來(lái)替代Transformer Encoder進(jìn)行推理加速,也有類(lèi)似模型飽和問(wèn)題和上下游任務(wù)匹配不齊的問(wèn)題。
至于對(duì)于各類(lèi)目標(biāo)不變性的性能對(duì)比,性能高的模型,對(duì)不同場(chǎng)景變化的魯棒性會(huì)好一些,Static Convolution采用權(quán)值共享和局部感知場(chǎng)有利于提升平移不變性,而靈活的采樣策略可以動(dòng)態(tài)地進(jìn)行特征聚類(lèi),在動(dòng)態(tài)卷積(例如DCNv3)中表現(xiàn)出更好的旋轉(zhuǎn)和尺寸縮放不變性。 Convolution-based STM模型多采用如下架構(gòu):Residual Learning, Dense Connection, Grouping, Spatial Attention,Channel Attention。其中Spatial Attention采用Deformable Convolution和Non-Local算子采用靈活可變的點(diǎn)采樣來(lái)構(gòu)建長(zhǎng)范圍的依賴(lài)語(yǔ)義依賴(lài)關(guān)系。
Vision Transformer的出世也給這類(lèi)設(shè)計(jì)帶來(lái)了新的架構(gòu)設(shè)計(jì)和探索思路。 對(duì)于Attention-based STM模型,比較而言,Transformer采用的全局感知場(chǎng)和動(dòng)態(tài)的空間聚類(lèi),也帶來(lái)了海量的計(jì)算復(fù)雜度,尤其是ADS 應(yīng)用中需要場(chǎng)景覆蓋的計(jì)算區(qū)域越來(lái)越大時(shí),這對(duì)ADS NPU的加速設(shè)計(jì)引入了一個(gè)全新課題。
從算法角度而言,圖 4所示的幾個(gè)算法,也采用了類(lèi)似CNN的Local Attention機(jī)制,例如采用非重疊的局部計(jì)算窗和金字塔結(jié)構(gòu),以及跨窗間信息遷移的機(jī)制,例如Haloing,Shifted Windows等等,當(dāng)前還有一種新的設(shè)計(jì)思路采用CNN和Transformer算子塊的交織實(shí)現(xiàn)方式,也可以稱(chēng)作為聯(lián)合或者混合架構(gòu),可以很好的融合CNN和Transformer的各自?xún)?yōu)勢(shì),適當(dāng)降低總體計(jì)算復(fù)雜度。而NAS網(wǎng)絡(luò)架構(gòu)檢索可以采用更加靈活的算子組合的策略,當(dāng)然這顯然增加了硬件計(jì)算架構(gòu)和數(shù)據(jù)流優(yōu)化的設(shè)計(jì)難度。
審核編輯:劉清
-
RGB
+關(guān)注
關(guān)注
4文章
804瀏覽量
59650 -
ADS仿真
+關(guān)注
關(guān)注
1文章
71瀏覽量
10793 -
dnn
+關(guān)注
關(guān)注
0文章
61瀏覽量
9233 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4507
原文標(biāo)題:ADS深度學(xué)習(xí)算法選型探討
文章出處:【微信號(hào):算力基建,微信公眾號(hào):算力基建】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
機(jī)器學(xué)習(xí)模型市場(chǎng)前景如何
FPGA加速深度學(xué)習(xí)模型的案例
AI大模型與深度學(xué)習(xí)的關(guān)系
深度識(shí)別算法包括哪些內(nèi)容
深度學(xué)習(xí)模型有哪些應(yīng)用場(chǎng)景
深度學(xué)習(xí)模型量化方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論