") 基于事件相機(jī)的超分辨率圖像恢復(fù)
基于事件相機(jī)的超分辨率圖像恢復(fù)
摘要 由于事件相機(jī)具有極高的時間分辨率,其在機(jī)器人和計算機(jī)視覺方面具有很大的潛力。然而,它的異步成像機(jī)制往往會加重測量對噪聲的敏感性,給提高圖像空間分辨率帶來物理負(fù)擔(dān)。
為了恢復(fù)高質(zhì)量的強(qiáng)度圖像,算法需要同時解決事件相機(jī)的去噪和超分辨率問題。由于事件描述了圖像亮度的變化,利用基于事件增強(qiáng)的圖像退化模型,可以從存在噪聲的、模糊和低分辨率的強(qiáng)度觀測中恢復(fù)清晰的高分辨率潛在圖像。利用稀疏學(xué)習(xí)框架,可以同時考慮事件和低分辨率強(qiáng)度圖像。
在此基礎(chǔ)上,我們提出了一種可解釋網(wǎng)絡(luò),即基于事件增強(qiáng)的稀疏學(xué)習(xí)網(wǎng)絡(luò)(eSL-Net),用于從事件相機(jī)中恢復(fù)高質(zhì)量圖像。在使用合成數(shù)據(jù)集進(jìn)行訓(xùn)練后,所提出的eSL-Net可以極大地提高7-12 dB的性能。此外,不需要額外的訓(xùn)練過程,所提出的eSL-Net可以很容易地擴(kuò)展到幀率與事件相同的連續(xù)幀生成任務(wù)中。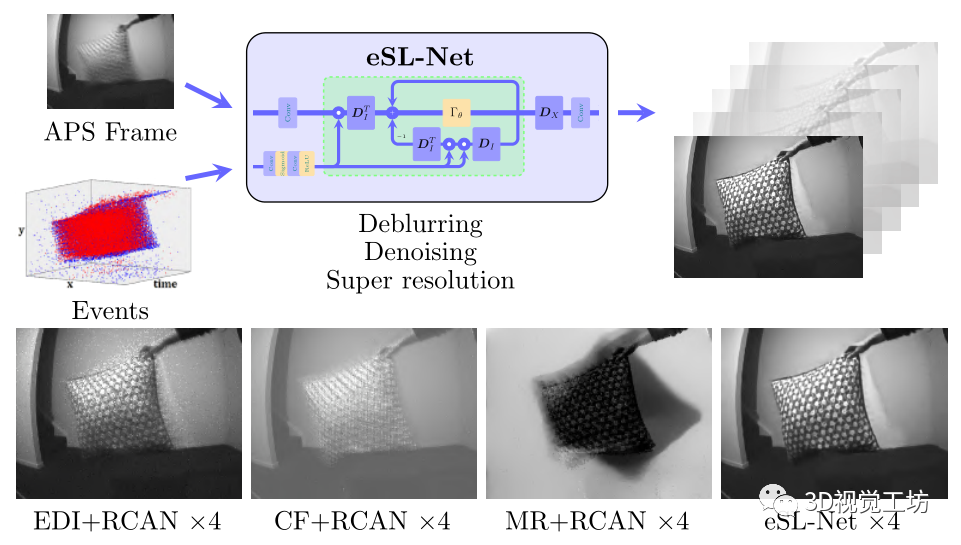
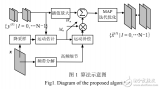
圖1 eSL-Net的算法流程示意圖以及模型效果
目前需要解決的問題
利用事件相機(jī)恢復(fù)高質(zhì)量圖像應(yīng)同時解決以下問題:
1)運(yùn)動模糊:主動像素傳感器(APS)幀率相對較低 (≥5 ms延遲),其在記錄高速場景時,運(yùn)動模糊是不可避免的。
2)圖像噪聲:熱效應(yīng)或不穩(wěn)定的光環(huán)境會產(chǎn)生大量的噪聲事件,再加上APS自身的噪聲,強(qiáng)度圖像的重建將陷入混合噪聲的問題。
3)低空間分辨率:目前消費(fèi)級事件相機(jī)通常具有非常低的空間分辨率,這是為了平衡事件數(shù)據(jù)的空間分辨率和延遲。
本文的貢獻(xiàn)
1)作者結(jié)合基于事件增強(qiáng)的圖像退化模型以及稀疏學(xué)習(xí)框架,提出了一種可解釋網(wǎng)絡(luò)——基于事件增強(qiáng)的稀疏學(xué)習(xí)網(wǎng)絡(luò)eSL-Net,用于從事件相機(jī)中恢復(fù)高質(zhì)量圖像。
2)作者提出了一種簡單的方法來擴(kuò)展eSL-Net,以實(shí)現(xiàn)高幀率和高質(zhì)量的視頻恢復(fù)。
3)作者為事件相機(jī)建立了一個合成數(shù)據(jù)集,其中事件數(shù)據(jù)、LR模糊圖像和HR清晰圖像。
算法原理


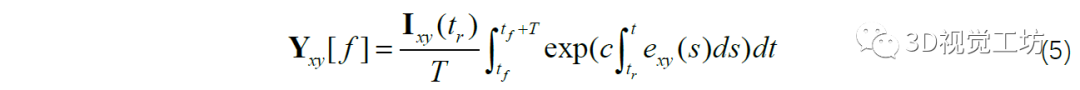
最后將公式運(yùn)用在整個圖像的所有像素上,就可以得到一個關(guān)于[tr,t]時間間隔內(nèi)的事件流、t時刻的觀測強(qiáng)度圖像以及tr時刻潛在清晰強(qiáng)度圖像三者之間的簡單模型:
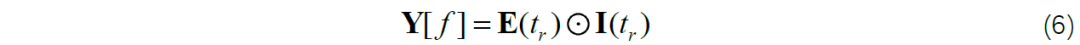
在實(shí)際應(yīng)用中,傳感器的非理想性以及相機(jī)與目標(biāo)場景之間的相對運(yùn)動會極大地降低觀測到的強(qiáng)度圖像Y[f]的質(zhì)量,使其具有噪聲和運(yùn)動模糊。此外,盡管事件相機(jī)具有極高的時間分辨率,但由于硬件設(shè)計的限制,其空間像素分辨率相對較低。考慮到這些因素,公式需要加入一些不定因素,改寫為:



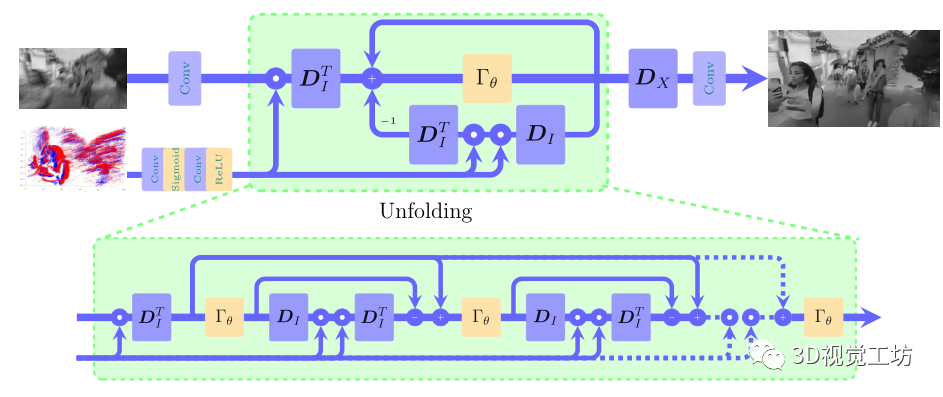
圖2 eSL-Net的模型細(xì)節(jié)
受到基于深度學(xué)習(xí)的稀疏編碼方法的啟發(fā),作者將稀疏編碼過程集成到CNN架構(gòu)中,提出了一種基于事件增強(qiáng)的稀疏學(xué)習(xí)網(wǎng)絡(luò)eSL-Net,在統(tǒng)一的框架下解決噪聲、運(yùn)動模糊和低空間分辨率的問題。
如圖2所示,eSL-Net的基本思想是將基于事件的強(qiáng)度圖像重建方法的更新步驟映射到由多個固定階段組成的深度網(wǎng)絡(luò)架構(gòu),每個階段對應(yīng)于公式(9)的一次迭代,因此eSL-Net是一個可解釋的深度網(wǎng)絡(luò)。
當(dāng)公式(9)中的系數(shù)為非負(fù)時,ISTA不受影響,則很容易發(fā)現(xiàn)逐元素軟閾值函數(shù)與ReLU激活函數(shù)的相等性。然后公式中的加減運(yùn)算也可以看成是神經(jīng)網(wǎng)絡(luò)的卷積運(yùn)算。由公式(5)可知,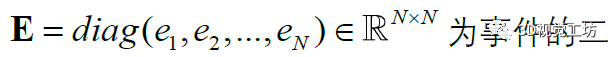
為事件的二重積分。在離散情況下,連續(xù)積分轉(zhuǎn)化為離散求和,更一般地,用加權(quán)求和卷積來代替積分。這樣,通過兩個具有合適參數(shù)的卷積層,可以將輸入的事件流轉(zhuǎn)換為近似的E。此外,卷積對事件流有一定的去噪效果。最后,迭代模塊輸出的最優(yōu)稀疏編碼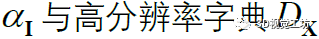
與高分辨率字典Dx計算得到最終的清晰圖像。在eSL-Net中,使用卷積層和shuffle層來實(shí)現(xiàn)高分辨率字典Dx,因?yàn)閟huffle算子對不同通道的像素進(jìn)行排列,可以看作是一個線性算子。
實(shí)驗(yàn)結(jié)果
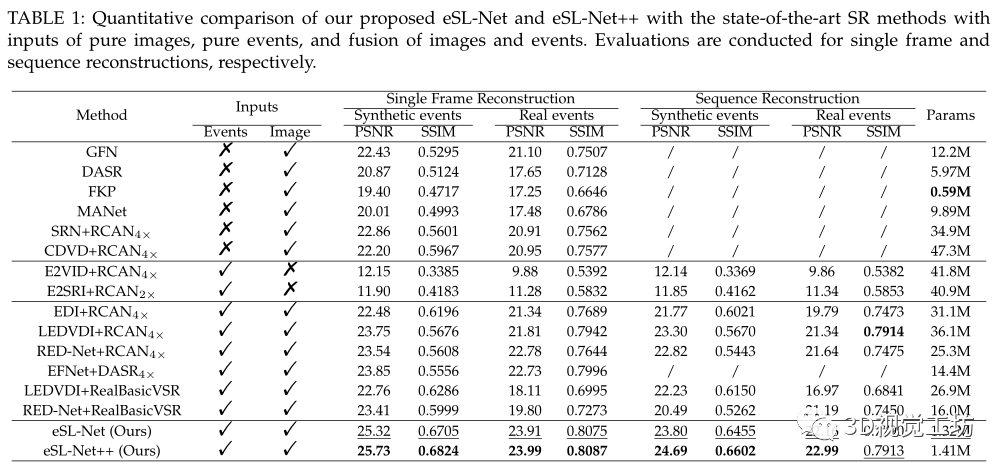
作者使用NVIDIA Titan-RTX GPU在50個epoch的合成訓(xùn)練數(shù)據(jù)集上訓(xùn)練提出的eSL-Net,并將其與最先進(jìn)的基于事件的強(qiáng)度重建方法進(jìn)行比較,包括EDI,互補(bǔ)濾波器方法(CF)和manifold正則化方法(MR)。此外,為了證明其同時解決去噪、去模糊和超分辨率三個問題的能力,將其與EDI、CF和MR進(jìn)行了比較,并配置了性能優(yōu)良的SR網(wǎng)絡(luò)RCAN。
我的思考
作者用壓縮感知領(lǐng)域的字典和稀疏編碼的思路來設(shè)計輕量化稀疏學(xué)習(xí)網(wǎng)絡(luò)同時處理圖像與事件信息是一個新穎的思路,利用對稀疏編碼ɑ進(jìn)行迭代優(yōu)化的方式巧妙地將事件信息作用在圖像信息中,完成清晰圖像的生成,解決了運(yùn)動模糊的問題。
不過針對去噪和超分辨率這兩個問題,作者在模型設(shè)計時只是簡單提了一下,說利用作用在事件流和潛在清晰圖像Dx上的卷積操作就可以實(shí)現(xiàn)去噪和超分辨率了,并在實(shí)驗(yàn)部分用更高的PSNR和SSIM指標(biāo)來驗(yàn)證模型確實(shí)有超分辨率的效果,但是我認(rèn)為只是單純用基于數(shù)據(jù)驅(qū)動的卷積運(yùn)算來解決事件相機(jī)的去噪和超分辨率問題,還有很大的提升空間。
摘要
由于運(yùn)動模糊和低空間分辨率,單運(yùn)動模糊圖像(SRB)的超分辨率是一個嚴(yán)重的不適定問題。在本文中,作者利用事件數(shù)據(jù)來減輕SRB的情況,并提出了一種基于事件增強(qiáng)的SRB (E-SRB)算法,該算法可以從一張低分辨率的模糊圖像生成一系列清晰清晰的高分辨率圖像。
為了達(dá)到這一目的,作者設(shè)計了一個基于事件增強(qiáng)的圖像退化模型,同時考慮低空間分辨率、運(yùn)動模糊和事件噪聲。然后,作者基于雙重稀疏學(xué)習(xí)方案構(gòu)建了一個基于事件增強(qiáng)的稀疏學(xué)習(xí)網(wǎng)絡(luò)(eSL-Net++),其中事件和強(qiáng)度圖像都用稀疏表示建模。
此外,作者還提出了一種基于事件的shuffle-and-merge方案,將單幀SRB擴(kuò)展到序列幀SRB,而無需任何額外的訓(xùn)練過程。在合成數(shù)據(jù)集和真實(shí)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,提出的eSL-Net++在很大程度上優(yōu)于最先進(jìn)的方法。
目前需要解決的問題
1)運(yùn)動由模糊變清晰。事件數(shù)據(jù)嵌入的幀內(nèi)信息補(bǔ)償了模糊低分辨率圖像中被擦除的運(yùn)動和紋理信息。
2)超分辨率。當(dāng)遇到運(yùn)動模糊時,事件數(shù)據(jù)極高的時間分辨率保持了動態(tài)場景幀內(nèi)的時間連續(xù)性。因此,類似于視頻超分辨率,即使是單個運(yùn)動模糊圖像,也可以通過事件數(shù)據(jù)的時間相關(guān)性來提高超分辨率性能。
作者的貢獻(xiàn)
1)作者提出采用事件來提高SRB的性能,其中基于事件增強(qiáng)的圖像退化模型(EDM)考慮了事件噪聲、運(yùn)動模糊和低空間分辨率。
2)作者提出了一種基于雙稀疏學(xué)習(xí)方案的eSL-Net++來解決E-SRB的挑戰(zhàn),其中事件噪聲抑制、運(yùn)動去模糊和圖像SR同時得到解決。
3)作者提出了一種嚴(yán)格的事件shuffle-and-merge方案,將eSL-Net++擴(kuò)展到從單個模糊LR圖像中恢復(fù)高幀率HR視頻序列,而無需任何額外的訓(xùn)練過程。
算法理論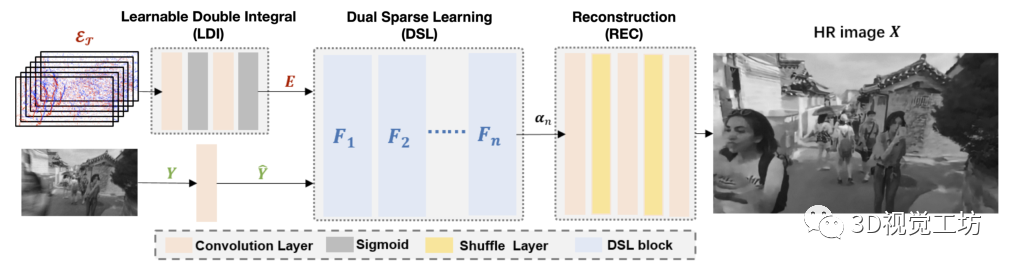
圖3 eSL-Net++的模型流程

圖4 eSL-Net++的模型細(xì)節(jié)


實(shí)驗(yàn)結(jié)果
我的思考
雖然同樣都是基于數(shù)據(jù)增強(qiáng)的稀疏學(xué)習(xí)模型,相比于eSL-Net,eSL-Net++主要的優(yōu)化在于它不僅僅是將事件通過卷積直接作用在圖像上來迭代計算圖像的稀疏編碼ɑ,而是也將圖像作用在事件上來迭代計算事件的稀疏編碼β,通過這種相互作用的編碼方式實(shí)現(xiàn)兩種模態(tài)的信息相互補(bǔ)償,雖然最終的清晰圖像生成還是得依靠圖像的稀疏編碼ɑ,但是在圖像對事件的補(bǔ)償過程中同樣能夠?qū)κ录M(jìn)行有效地去噪,能夠間接性提高最終清晰圖像的生成精度。 綜上,eSL-Net和eSL-Net++最值得借鑒學(xué)習(xí)的地方就是,兩者利用稀疏編碼的思想對圖像和事件進(jìn)行處理的過程,需要進(jìn)一步查看源碼來學(xué)習(xí)。
審核編輯:劉清
-
傳感器
+關(guān)注
關(guān)注
2564文章
52665瀏覽量
764204 -
機(jī)器人
+關(guān)注
關(guān)注
213文章
29533瀏覽量
211721 -
計算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46591 -
APS
+關(guān)注
關(guān)注
0文章
354瀏覽量
17952
原文標(biāo)題:TPAMI 2023|eSL-Net++:基于事件相機(jī)的超分辨率圖像恢復(fù)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
新手關(guān)于圖像超分辨率的問題~
序列圖像超分辨率重建算法研究

單幅模糊圖像超分辨率盲重建
序列圖像超分辨率重建
使用深度學(xué)習(xí)來實(shí)現(xiàn)圖像超分辨率
基于目標(biāo)檢測的海上艦船圖像超分辨率研究
如何有效匹配鏡頭分辨率和相機(jī)分辨率?
單張圖像超分辨率和立體圖像超分辨率的相關(guān)工作

基于CNN的圖像超分辨率示例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論