") 一致性哈希算法簡(jiǎn)介
一致性哈希算法簡(jiǎn)介
最近有一位讀者跟我交流,說(shuō)除了算法題之外,系統(tǒng)設(shè)計(jì)題是一大痛點(diǎn)。算法題起碼有很多刷題平臺(tái)可以動(dòng)手實(shí)踐,但系統(tǒng)設(shè)計(jì)類的題目一般很難實(shí)踐,所以看一些教程總結(jié)也只是一知半解,遇到讓寫(xiě)代碼實(shí)現(xiàn)系統(tǒng)的就懵了。
比如他最近被問(wèn)到一個(gè)大型爬蟲(chóng)系統(tǒng)的設(shè)計(jì)題,讓手寫(xiě)一致性哈希算法,加上一系列 follow up,就被難住了。
說(shuō)實(shí)話這個(gè)算法的實(shí)現(xiàn)并不難,所以本文就結(jié)合一致性哈希算法在工程中的應(yīng)用場(chǎng)景介紹一下這個(gè)算法算法,并給出代碼實(shí)現(xiàn),避免大家重蹈覆轍。
一致性哈希算法簡(jiǎn)介
這個(gè)名詞大家肯定不陌生,應(yīng)該也大概理解這個(gè)算法的邏輯,不過(guò)我這里還是要再介紹一下。
一致性哈希主要解決把數(shù)據(jù)平均分配到多個(gè)節(jié)點(diǎn)上的問(wèn)題,并且某些節(jié)點(diǎn)上線/下線后依然能夠做到自動(dòng)負(fù)載均衡。
其原理就是抽象出一個(gè)哈希環(huán),把服務(wù)器節(jié)點(diǎn)的 id 通過(guò)哈希函數(shù)映射到這個(gè)哈希環(huán)上:
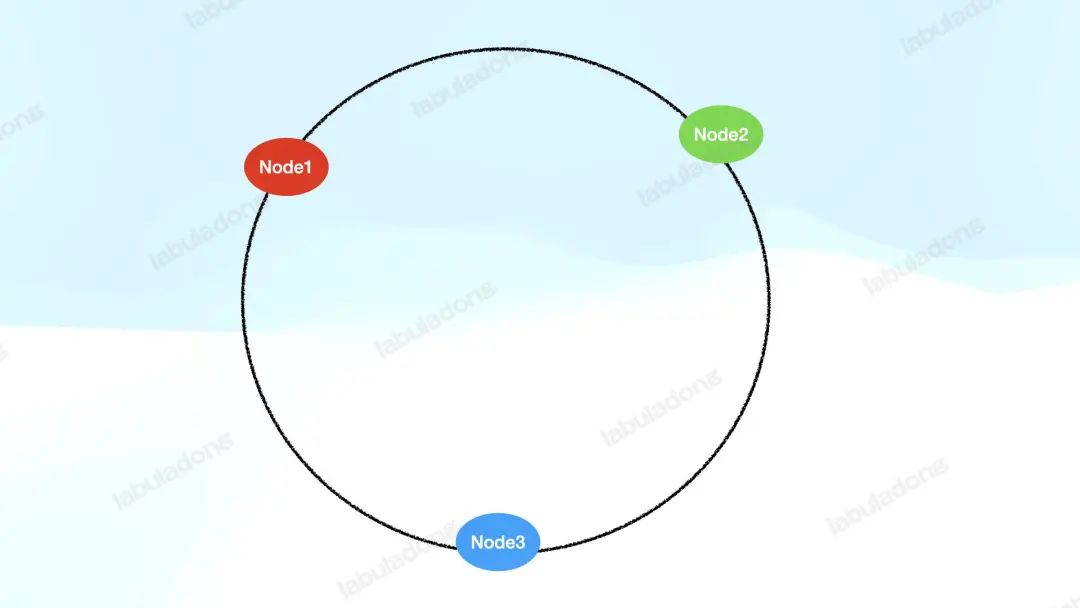
同時(shí),把需要處理的數(shù)據(jù)也通過(guò)哈希函數(shù)映射到這個(gè)哈希環(huán)上,然后順時(shí)針找,遇到的第一個(gè)服務(wù)器節(jié)點(diǎn)來(lái)負(fù)責(zé)處理這個(gè)數(shù)據(jù):
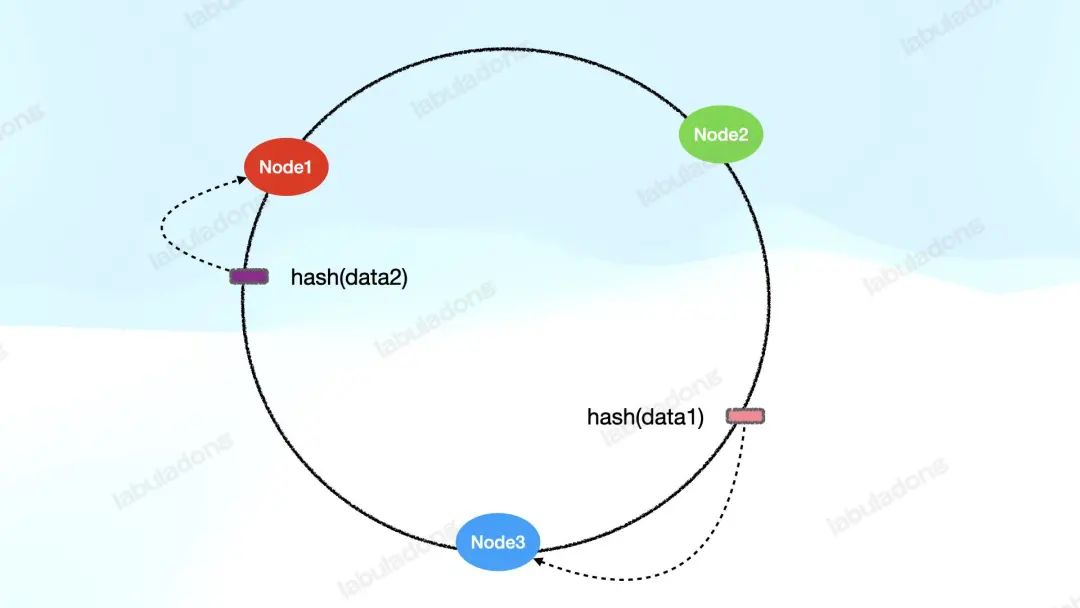
這樣一來(lái),我們其實(shí)已經(jīng)提供了一種機(jī)制將若干數(shù)據(jù)分布在若干服務(wù)節(jié)點(diǎn)上了,不妨稱它為 V1 版本的一致性哈希算法。
但 V1 版本的算法還有問(wèn)題:負(fù)載分布很可能不均衡。由于哈希函數(shù)的結(jié)果是難以預(yù)測(cè)的,所以可能出現(xiàn)這種情況:
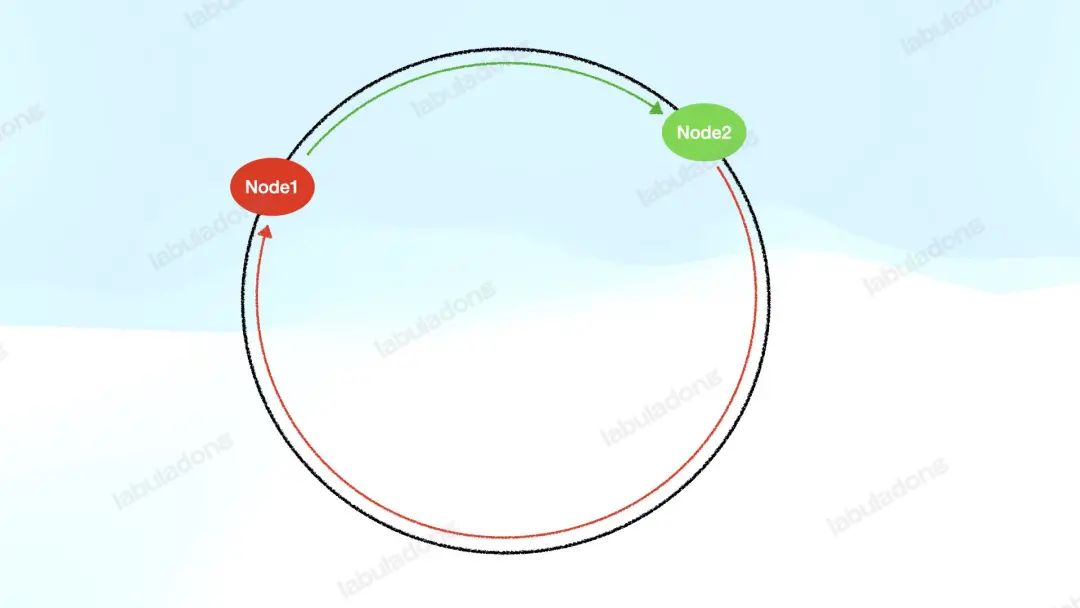
即某些服務(wù)器節(jié)點(diǎn)要負(fù)責(zé)的哈希環(huán)很長(zhǎng),而其他服務(wù)器負(fù)責(zé)的哈希環(huán)很短。這就會(huì)導(dǎo)致某些服務(wù)器負(fù)載很高,而其他的服務(wù)器負(fù)載很低,很不均衡。
而且,當(dāng)某個(gè)服務(wù)器節(jié)點(diǎn)下線后,它的負(fù)載會(huì)順時(shí)針轉(zhuǎn)移到下一個(gè)節(jié)點(diǎn)上,那么某些特定的節(jié)點(diǎn)下線順序很可能導(dǎo)致某些服務(wù)器節(jié)點(diǎn)負(fù)責(zé)的哈希環(huán)不斷加長(zhǎng),負(fù)載不斷增加。專業(yè)點(diǎn)說(shuō),這就是「數(shù)據(jù)傾斜」。
如何解決數(shù)據(jù)傾斜的問(wèn)題呢?可以給每個(gè)服務(wù)器節(jié)點(diǎn)添加若干「虛擬節(jié)點(diǎn)」分布在哈希環(huán)上,我們不妨稱其為 V2 版的一致性哈希算法:
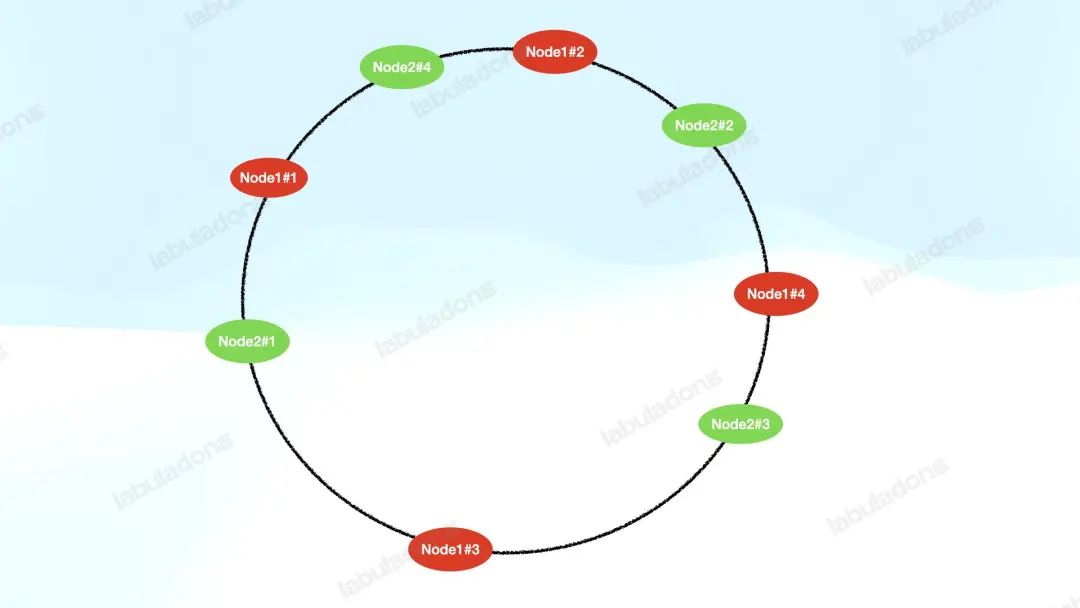
上圖給每個(gè) Node 設(shè)置了 4 個(gè)虛擬節(jié)點(diǎn),這樣一來(lái),由于哈希函數(shù)的隨機(jī)性,每個(gè)服務(wù)器節(jié)點(diǎn)的虛擬節(jié)點(diǎn)能夠平均分布在哈希環(huán)上,那么數(shù)據(jù)就能夠比較均勻地分配到所有服務(wù)器節(jié)點(diǎn)上。
如果某個(gè)服務(wù)器節(jié)點(diǎn)下線,那么該服務(wù)器節(jié)點(diǎn)的所有虛擬節(jié)點(diǎn)都會(huì)從哈希環(huán)上摘除,它們的負(fù)載會(huì)遷移到順時(shí)針的下一個(gè)服務(wù)器節(jié)點(diǎn)上。
和 V1 版算法不同的是,因?yàn)樘摂M節(jié)點(diǎn)有多個(gè),它們的下一位不太可能是同一臺(tái)服務(wù)器的虛擬節(jié)點(diǎn),所以它們的負(fù)載大概率會(huì)均分到多臺(tái)服務(wù)器的虛擬節(jié)點(diǎn)上。
綜上,V2 版算法通過(guò)虛擬節(jié)點(diǎn)的方式完美解決了數(shù)據(jù)傾斜的問(wèn)題,是不是很巧妙?不過(guò)俗話說(shuō),紙上得來(lái)終覺(jué)淺,絕知此事要躬行,我們需要實(shí)踐才能真正寫(xiě)出正確的一致性哈希算法。
比方說(shuō),應(yīng)該用什么數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)哈希環(huán)?如果哈希函數(shù)出現(xiàn)哈希沖突怎么辦?真正寫(xiě)代碼的時(shí)候,這些細(xì)節(jié)問(wèn)題都是要考慮的。
下面我們就結(jié)合代碼和實(shí)際場(chǎng)景來(lái)看看一致性哈希算法的真實(shí)應(yīng)用。
實(shí)際場(chǎng)景分析
就以消息隊(duì)列的消費(fèi)模型為例吧,我在前文用消息隊(duì)列做一個(gè)聯(lián)機(jī)游戲介紹過(guò) Apache Pulsar 的消費(fèi)模型,Pulsar 通過(guò) subscription 的抽象提供多種訂閱模式,其中 key_shared 模式比較有意思:
每條消息會(huì)有一個(gè) key,Pulsar 可以根據(jù)這個(gè) key 分發(fā)消息,保證帶有相同 key 的消息分發(fā)到同一個(gè)消費(fèi)者上。
官網(wǎng)的這幅圖比較好理解,圖中的K就是指消息的 key,V就是指消息的數(shù)據(jù):
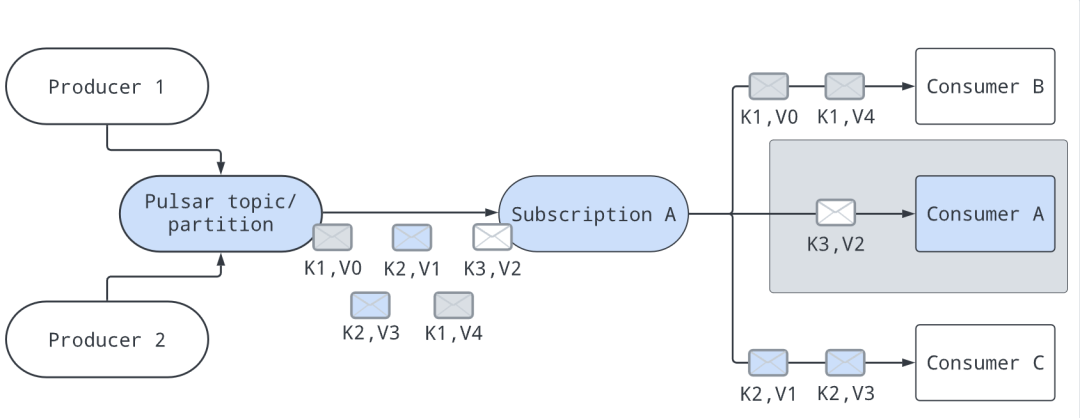
通過(guò)某些算法,所有的消息都會(huì)有消費(fèi)者去處理,比如上圖就是consumerA負(fù)責(zé)處理key=K3的消息,consumerB負(fù)責(zé)處理key=K1的消息,consumerC負(fù)責(zé)處理key=K2的消息。
當(dāng)然,如果有 consumer 加入或者離開(kāi),消息的分配會(huì)重置。比如consumerA下線,那么key=K3的消息會(huì)被分配給其他消費(fèi)者消費(fèi);如果有新的消費(fèi)者consumerD加入,那么當(dāng)前的分配方案也可能會(huì)改變。
簡(jiǎn)單總結(jié)就是:
1、在沒(méi)有 consumer 加入或者離開(kāi)的前提下,保證 key 相同的消息都會(huì)分配到固定的 consumer,不能一會(huì)兒分配到consumerA,一會(huì)兒分配給consumerB。
2、如果有 consumer 加入或者離開(kāi),可以重新進(jìn)行分配每個(gè) consumer 負(fù)責(zé)的 key,要求盡量把 key 平均分配給 consumer,避免出現(xiàn)某些 consumer 負(fù)責(zé)過(guò)多 key 的情況導(dǎo)致數(shù)據(jù)傾斜。
3、以上兩個(gè)操作,尤其是給 consumer 重新分配 key 的操作,效率要盡可能高。
對(duì)于上述場(chǎng)景,你如何設(shè)計(jì)分配算法,把這些帶有 key 的消息高效地、均勻地分配給所有 consumer 呢?
我們來(lái)看看 Pulsar 是如何做的,官網(wǎng)對(duì)這部分的實(shí)現(xiàn)原理描述的比較清楚,參考鏈接如下:
https://pulsar.apache.org/docs/next/concepts-messaging/#key_shared
結(jié)合我之前在學(xué)習(xí)開(kāi)源項(xiàng)目的套路中介紹的查看源碼背景信息的技巧,可以發(fā)現(xiàn) Pulsar 的 key_shared 模式的消費(fèi)者實(shí)現(xiàn)其實(shí)是經(jīng)歷了一些演進(jìn)的。
最開(kāi)始的默認(rèn)實(shí)現(xiàn)方式叫做 Auto-split Hash Range,即抽象出來(lái)一個(gè)[0, 65535]的哈希區(qū)間,讓每個(gè) consumer 負(fù)責(zé)這個(gè)區(qū)間的一部分。比如有C1~C44 個(gè) consumer,那么它們會(huì)平分整個(gè)哈希區(qū)間:
016,38432,76849,15265,536 |-------C3------|-------C2------|-------C4------|-------C1------|
然后我們可以對(duì)每條消息的 key 計(jì)算哈希值并求模映射到[0, 65535]的區(qū)間中,這樣我們就可以選出負(fù)責(zé)處理這條消息的 consumer 了,而且 key 相同的消息總會(huì)分配到這個(gè) consumer 上。
那么如果有 consumer 上線或者下線怎么處理呢?
如果有 consumer 下線,那么它負(fù)責(zé)的哈希區(qū)間會(huì)直接交給右側(cè)的 consumer。比如上例中C4下線,那么哈希區(qū)間就會(huì)變成這樣:
016,38432,76865,536 |-------C3------|-------C2------|----------------C1---------------|
當(dāng)然這里也有個(gè)特殊情況,就是下線的那個(gè) consumer 右邊沒(méi)有其他 consumer 的情況,我們可以讓它左邊的 consumer 頂上來(lái)。比如現(xiàn)在的C1下線,那么就讓左邊的C2負(fù)責(zé)C1的區(qū)間:
016,38465,536 |-------C3------|--------------------------C2-----------------------|
如果有 consumer 上線,那么算法可以把最長(zhǎng)的哈希區(qū)間平分,分一半給新來(lái)的 consumer。比如此時(shí)C5上線,我們就可以把C2負(fù)責(zé)的一半哈希區(qū)間分給C5:
016,38440,96065,536 |-------C3------|-----------C5-----------|----------C2----------|
這就是 Auto-split Hash Range 的方案,不算復(fù)雜,具體的實(shí)現(xiàn)可以看 Pulsar 源碼中HashRangeAutoSplitStickyKeyConsumerSelector這個(gè)類,我在這里就不列舉了。
這個(gè)方案的問(wèn)題主要還是數(shù)據(jù)傾斜,比如上面的例子出現(xiàn)的這種情況,C2的負(fù)載顯然比C3多很多:
016,38465,536 |-------C3------|--------------------------C2-----------------------|
按照這個(gè)算法邏輯,一些 consumer 下線后很容易產(chǎn)生這種數(shù)據(jù)傾斜的情況,所以這個(gè)解決方案并不能均勻地把 key 分配給 consumer。
那么如何優(yōu)化這個(gè)算法呢?就要用到一致性哈希算法了。
一致性哈希算法的實(shí)現(xiàn)
結(jié)合我在本文開(kāi)頭對(duì)一致性哈希算法的介紹,應(yīng)該很容易想到優(yōu)化思路。其實(shí)現(xiàn)在 Pulsar 就是使用一致性哈希算法來(lái)實(shí)現(xiàn)的 key_shared 訂閱。
首先抽象出一個(gè)值在[0, MAX_INT]的哈希環(huán),然后給每個(gè) consumer 分配 100 個(gè)虛擬節(jié)點(diǎn)映射到這個(gè)哈希環(huán)上。接下來(lái),我們把 key 的哈希值放在哈希環(huán)上,順時(shí)針?lè)较蛘业阶罱?consumer 虛擬節(jié)點(diǎn),也就找到了負(fù)責(zé)處理這個(gè) key 的 consumer。
哈希環(huán)我們一般用 TreeMap 實(shí)現(xiàn),直接看 Pulsar 源碼中ConsistentHashingStickyKeyConsumerSelector的實(shí)現(xiàn)吧,我提取了其中的關(guān)鍵邏輯并添加了詳細(xì)的注釋:
classConsistentHashingStickyKeyConsumerSelector{
//哈希環(huán),虛擬節(jié)點(diǎn)的哈希值->consumer列表
//因?yàn)榇嬖诠_突,多個(gè)虛擬節(jié)點(diǎn)可能映射到同一個(gè)哈希值,所以值為L(zhǎng)ist類型
NavigableMap>hashRing=newTreeMap<>();
//每個(gè)consumer有100個(gè)虛擬節(jié)點(diǎn)
intnumberOfPoints=100;
//將該consumer的100個(gè)虛擬節(jié)點(diǎn)添加到哈希環(huán)上
publicvoidaddConsumer(Consumerconsumer){
for(inti=0;i());
hashRing.get(hash).add(consumer);
}
}
//在哈希環(huán)上刪除該consumer的所有虛擬節(jié)點(diǎn)
publicvoidremoveConsumer(Consumerconsumer){
for(inti=0;i>ceilingEntry=hashRing.ceilingEntry(hash);
ListconsumerList;
if(ceilingEntry!=null){
consumerList=ceilingEntry.getValue();
}else{
//哈希環(huán)順時(shí)針轉(zhuǎn)一圈,回到開(kāi)頭尋找第一個(gè)節(jié)點(diǎn)
consumerList=hashRing.firstEntry().getValue();
}
//保證相同的key都會(huì)分配到同一個(gè)consumer
returnconsumerList.get(hash%consumerList.size());
}
}
當(dāng)消息被發(fā)送過(guò)來(lái)后,Pulsar 可以通過(guò)select方法選擇對(duì)應(yīng)的 consumer 來(lái)處理數(shù)據(jù);當(dāng)新的 consumer 上線時(shí),可以通過(guò)addConsumer將它的虛擬節(jié)點(diǎn)放到哈希環(huán)上并開(kāi)始接收消息;當(dāng)有 consumer 下線時(shí),可以通過(guò)removeConsumer將它的虛擬節(jié)點(diǎn)從哈希環(huán)上摘除,由其他 consumer 承擔(dān)它的工作。
因?yàn)槊總€(gè) consumer 有 100 個(gè)虛擬節(jié)點(diǎn),所以在 consumer 下線時(shí),負(fù)載其實(shí)是均勻地分配給了其他 consumer,因此一致性哈希算法能夠解決之前 Auto-split Hash Range 方案數(shù)據(jù)傾斜的問(wèn)題。
審核編輯:劉清
-
虛擬機(jī)
+關(guān)注
關(guān)注
1文章
964瀏覽量
29155 -
哈希算法
+關(guān)注
關(guān)注
1文章
56瀏覽量
10936
原文標(biāo)題:一致性哈希算法設(shè)計(jì)題,栽了
文章出處:【微信號(hào):TheAlgorithm,微信公眾號(hào):算法與數(shù)據(jù)結(jié)構(gòu)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
順序一致性和TSO一致性分別是什么?SC和TSO到底哪個(gè)好?
一致性規(guī)劃研究
CMP中Cache一致性協(xié)議的驗(yàn)證
加速器一致性接口
分布式一致性算法Yac
基于軌跡標(biāo)簽的謠言一致性維護(hù)算法
Cache一致性協(xié)議優(yōu)化研究
優(yōu)化模型的乘性偏好關(guān)系一致性改進(jìn)
一致性哈希是什么?為什么它是可擴(kuò)展的分布式系統(tǒng)架構(gòu)的一個(gè)必要工具
哈希圖一致性算法已被驗(yàn)證為異步拜占庭容錯(cuò)
基于改進(jìn)一致性的多無(wú)人機(jī)編隊(duì)控制算法
Dubbo負(fù)載均衡策略之一致性哈希
如何保證緩存一致性

DDR一致性測(cè)試的操作步驟
深入理解數(shù)據(jù)備份的關(guān)鍵原則:應(yīng)用一致性與崩潰一致性的區(qū)別






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論