") MySQL處理大數(shù)據(jù)表的3種方案
MySQL處理大數(shù)據(jù)表的3種方案
場景
當我們業(yè)務(wù)數(shù)據(jù)庫表中的數(shù)據(jù)越來越多,如果你也和我遇到了以下類似場景,那讓我們一起來解決這個問題
數(shù)據(jù)的插入,查詢時長較長
后續(xù)業(yè)務(wù)需求的擴展 在表中新增字段 影響較大
表中的數(shù)據(jù)并不是所有的都為有效數(shù)據(jù) 需求只查詢時間區(qū)間內(nèi)的
評估表數(shù)據(jù)體量
我們可以從表容量/磁盤空間/實例容量三方面評估數(shù)據(jù)體量,接下來讓我們分別展開來看看
表容量
表容量主要從表的記錄數(shù)、平均長度、增長量、讀寫量、總大小量進行評估。一般對于OLTP的表,建議單表不要超過2000W行數(shù)據(jù)量,總大小15G以內(nèi)。訪問量:單表讀寫量在1600/s以內(nèi)
查詢行數(shù)據(jù)的方式:我們一般查詢表數(shù)據(jù)有多少數(shù)據(jù)時用到的經(jīng)典sql語句如下:
selectcount(*)fromtable selectcount(1)fromtable
但是當數(shù)據(jù)量過大的時候,這樣的查詢就可能會超時,所以我們要換一種查詢方式
use庫名 showtablestatuslike'表名'; 或:showtablestatuslike'表名'G;
上述方法不僅可以查詢表的數(shù)據(jù),還可以輸出表的詳細信息 , 加 G 可以格式化輸出。包括表名 存儲引擎 版本 行數(shù) 每行的字節(jié)數(shù)等等,大家可以自行試一下哈
磁盤空間
查看指定數(shù)據(jù)庫容量大小
select table_schemaas'數(shù)據(jù)庫', table_nameas'表名', table_rowsas'記錄數(shù)', truncate(data_length/1024/1024,2)as'數(shù)據(jù)容量(MB)', truncate(index_length/1024/1024,2)as'索引容量(MB)' frominformation_schema.tables orderbydata_lengthdesc,index_lengthdesc;
查詢單個庫中所有表磁盤占用大小
select table_schemaas'數(shù)據(jù)庫', table_nameas'表名', table_rowsas'記錄數(shù)', truncate(data_length/1024/1024,2)as'數(shù)據(jù)容量(MB)', truncate(index_length/1024/1024,2)as'索引容量(MB)' frominformation_schema.tables wheretable_schema='mysql' orderbydata_lengthdesc,index_lengthdesc;
查詢出的結(jié)果如下:

建議數(shù)據(jù)量占磁盤使用率的70%以內(nèi)。同時,對于一些數(shù)據(jù)增長較快,可以考慮使用大的慢盤進行數(shù)據(jù)歸檔(歸檔可以參考方案三)
實例容量
MySQL是基于線程的服務(wù)模型,因此在一些并發(fā)較高的場景下,單實例并不能充分利用服務(wù)器的CPU資源,吞吐量反而會卡在mysql層,可以根據(jù)業(yè)務(wù)考慮自己的實例模式
出現(xiàn)問題的原因
上面我們已經(jīng)查到我們數(shù)據(jù)表的體量了 那么為什么單表數(shù)據(jù)量越大 業(yè)務(wù)的執(zhí)行效率就越慢 根本原因是什么呢?
一個表的數(shù)據(jù)量達到好幾千萬或者上億時,加索引的效果沒那么明顯啦。性能之所以會變差,是因為維護索引的B+樹結(jié)構(gòu)層級變得更高了,查詢一條數(shù)據(jù)時,需要經(jīng)歷的磁盤IO變多,因此查詢性能變慢。
?
大家是否還記得,一個B+樹大概可以存放多少數(shù)據(jù)量呢?
?
InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。
B+樹葉子存的是數(shù)據(jù),內(nèi)部節(jié)點存的是鍵值+指針。索引組織表通過非葉子節(jié)點的二分查找法以及指針確定數(shù)據(jù)在哪個頁中,進而再去數(shù)據(jù)頁中找到需要的數(shù)據(jù);
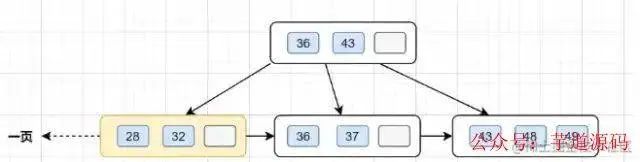
假設(shè)B+樹的高度為2的話,即有一個根結(jié)點和若干個葉子結(jié)點。這棵B+樹的存放總記錄數(shù)為=根結(jié)點指針數(shù)*單個葉子節(jié)點記錄行數(shù)。
如果一行記錄的數(shù)據(jù)大小為1k,那么單個葉子節(jié)點可以存的記錄數(shù) =16k/1k =16.
非葉子節(jié)點內(nèi)存放多少指針呢?我們假設(shè)主鍵ID為bigint類型,長度為8字節(jié)(面試官問你int類型,一個int就是32位,4字節(jié)),而指針大小在InnoDB源碼中設(shè)置為6字節(jié),所以就是8+6=14字節(jié),16k/14B =16*1024B/14B = 1170
因此,一棵高度為2的B+樹,能存放1170 * 16=18720條這樣的數(shù)據(jù)記錄。同理一棵高度為3的B+樹,能存放1170 *1170 *16 =21902400,也就是說,可以存放兩千萬左右的記錄。B+樹高度一般為1-3層,已經(jīng)滿足千萬級別的數(shù)據(jù)存儲。
如果B+樹想存儲更多的數(shù)據(jù),那樹結(jié)構(gòu)層級就會更高,查詢一條數(shù)據(jù)時,需要經(jīng)歷的磁盤IO變多,因此查詢性能變慢。
如何解決單表數(shù)據(jù)量太大,查詢變慢的問題
知道了根本原因之后,我們就需要考慮如何優(yōu)化數(shù)據(jù)庫來解決問題了
這里提供了三種解決方案,包括數(shù)據(jù)表分區(qū),分庫分表,冷熱數(shù)據(jù)歸檔 了解完這些方案之后大家可以選取適合自己業(yè)務(wù)的方案
方案一:數(shù)據(jù)表分區(qū)
為什么要分區(qū):表分區(qū)可以在區(qū)間內(nèi)查詢對應(yīng)的數(shù)據(jù),降低查詢范圍 并且索引分區(qū) 也可以進一步提高命中率,提升查詢效率 分區(qū)是指將一個表的數(shù)據(jù)按照條件分布到不同的文件上面,未分區(qū)前都是存放在一個文件上面的,但是它還是指向的同一張表,只是把數(shù)據(jù)分散到了不同文件而已。
我們首先看一下分區(qū)有什么優(yōu)缺點:
表分區(qū)有什么好處?
與單個磁盤或文件系統(tǒng)分區(qū)相比,可以存儲更多的數(shù)據(jù)。
對于那些已經(jīng)失去保存意義的數(shù)據(jù),通常可以通過刪除與那些數(shù)據(jù)有關(guān)的分區(qū),很容易地刪除那些數(shù)據(jù)。相反地,在某些情況下,添加新數(shù)據(jù)的過程又可以通過為那些新數(shù)據(jù)專門增加一個新的分區(qū),來很方便地實現(xiàn)。
一些查詢可以得到極大的優(yōu)化,這主要是借助于滿足一個給定WHERE語句的數(shù)據(jù)可以只保存在一個或多個分區(qū)內(nèi),這樣在查找時就不用查找其他剩余的分區(qū)。因為分區(qū)可以在創(chuàng)建了分區(qū)表后進行修改,所以在第一次配置分區(qū)方案時還不曾這么做時,可以重新組織數(shù)據(jù),來提高那些常用查詢的效率。
涉及到例如SUM()和COUNT()這樣聚合函數(shù)的查詢,可以很容易地進行并行處理。這種查詢的一個簡單例子如 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。通過“并行”,這意味著該查詢可以在每個分區(qū)上同時進行,最終結(jié)果只需通過總計所有分區(qū)得到的結(jié)果。
通過跨多個磁盤來分散數(shù)據(jù)查詢,來獲得更大的查詢吞吐量。
表分區(qū)的限制因素
一個表最多只能有1024個分區(qū)。
MySQL5.1中,分區(qū)表達式必須是整數(shù),或者返回整數(shù)的表達式。在MySQL5.5中提供了非整數(shù)表達式分區(qū)的支持。
如果分區(qū)字段中有主鍵或者唯一索引的列,那么多有主鍵列和唯一索引列都必須包含進來。即:分區(qū)字段要么不包含主鍵或者索引列,要么包含全部主鍵和索引列。
分區(qū)表中無法使用外鍵約束。
MySQL的分區(qū)適用于一個表的所有數(shù)據(jù)和索引,不能只對表數(shù)據(jù)分區(qū)而不對索引分區(qū),也不能只對索引分區(qū)而不對表分區(qū),也不能只對表的一部分數(shù)據(jù)分區(qū)。
在進行分區(qū)之前可以用如下方法 看下數(shù)據(jù)庫表是否支持分區(qū)哈
mysql>showvariableslike'%partition%'; +-------------------+-------+ |Variable_name|Value| +-------------------+-------+ |have_partitioning|YES| +-------------------+-------+ 1rowinset(0.00sec)
方案二:數(shù)據(jù)庫分表
為什么要分表:分表后,顯而易見,單表數(shù)據(jù)量降低,樹的高度變低,查詢經(jīng)歷的磁盤io變少,則可以提高效率 mysql 分表分為兩種 水平分表和垂直分表
分庫分表就是為了解決由于數(shù)據(jù)量過大而導(dǎo)致數(shù)據(jù)庫性能降低的問題,將原來獨立的數(shù)據(jù)庫拆分成若干數(shù)據(jù)庫組成 ,將數(shù)據(jù)大表拆分成若干數(shù)據(jù)表組成,使得單一數(shù)據(jù)庫、單一數(shù)據(jù)表的數(shù)據(jù)量變小,從而達到提升數(shù)據(jù)庫性能的目的。
水平分表
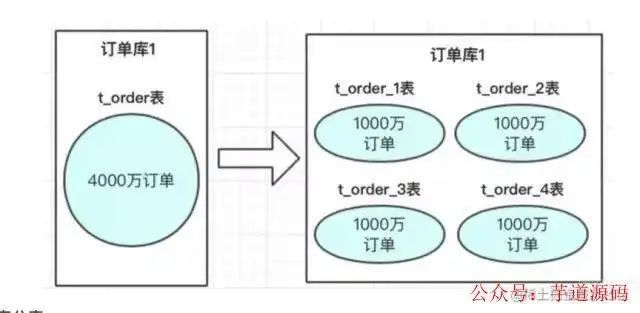
定義:數(shù)據(jù)表行的拆分,通俗點就是把數(shù)據(jù)按照某些規(guī)則拆分成多張表或者多個庫來存放。分為庫內(nèi)分表和分庫。
比如一個表有4000萬數(shù)據(jù),查詢很慢,可以分到四個表,每個表有1000萬數(shù)據(jù)
垂直分表
定義:列的拆分,根據(jù)表之間的相關(guān)性進行拆分。常見的就是一個表把不常用的字段和常用的字段就行拆分,然后利用主鍵關(guān)聯(lián)。或者一個數(shù)據(jù)庫里面有訂單表和用戶表,數(shù)據(jù)量都很大,進行垂直拆分,用戶庫存用戶表的數(shù)據(jù),訂單庫存訂單表的數(shù)據(jù)
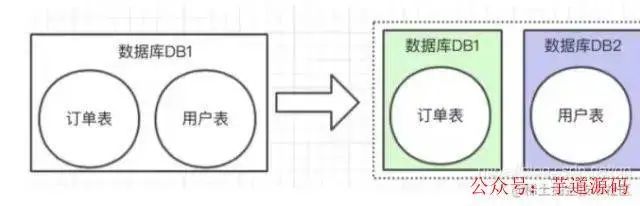
缺點:垂直分隔的缺點比較明顯,數(shù)據(jù)不在一張表中,會增加join 或 union之類的操作
知道了兩個知識后,我們來看一下分庫分表的方案
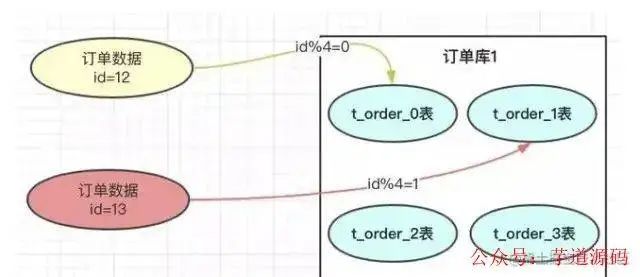
1.取模方案:
拆分之前,先預(yù)估一下數(shù)據(jù)量。比如用戶表有4000w數(shù)據(jù),現(xiàn)在要把這些數(shù)據(jù)分到4個表user1 user2 uesr3 user4。
比如id = 17,17對4取模為1,加上 ,所以這條數(shù)據(jù)存到user2表。
?
注意:進行水平拆分后的表要去掉auto_increment自增長。這時候的id可以用一個id 自增長臨時表獲得,或者使用 redis incr的方法。
?
優(yōu)點:數(shù)據(jù)均勻的分到各個表中,出現(xiàn)熱點問題的概率很低。
缺點:以后的數(shù)據(jù)擴容遷移比較困難難,當數(shù)據(jù)量變大之后,以前分到4個表現(xiàn)在要分到8個表,取模的值就變了,需要重新進行數(shù)據(jù)遷移。
2.range 范圍方案
以范圍進行拆分數(shù)據(jù),就是在某個范圍內(nèi)的訂單,存放到某個表中。比如id=12存放到user1表,id=1300萬的存放到user2 表。
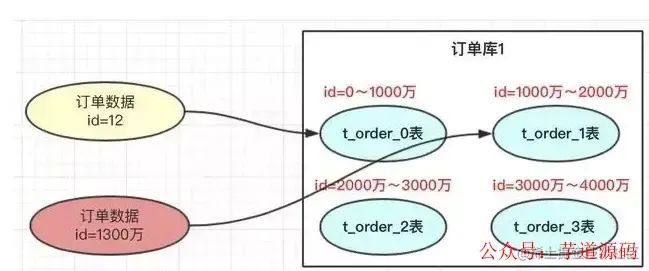
優(yōu)點:有利于將來對數(shù)據(jù)的擴容
缺點:如果熱點數(shù)據(jù)都存在一個表中,則壓力都在一個表中,其他表沒有壓力。
?
我們看到以上兩種方案 都存在缺點 但是卻又是互補的,那么我們將這兩個方案結(jié)合會怎樣呢?
?
3.hash取模和range方案結(jié)合
如下圖 我們可以看到 group 組存放id 為0~4000萬的數(shù)據(jù),然后有三個數(shù)據(jù)庫 DB0 DB1 DB2,DB0里面有四個數(shù)據(jù)庫,DB1 和DB2 有三個數(shù)據(jù)庫
假如id為15000 然后對10取模(為啥對10 取模 因為有10個表),取0 然后 落在DB_0,然后在根據(jù)range 范圍,落在Table_0 里面。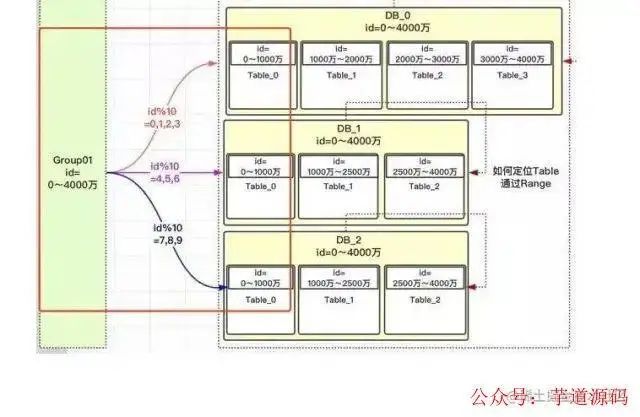
總結(jié):采用hash取模和range方案結(jié)合 既可以避免熱點數(shù)據(jù)的問題,也有利于將來對數(shù)據(jù)的擴容
我們已經(jīng)了解了 mysql分區(qū)和分表的知識 那我們看一下這兩個技術(shù)有何不同以及適用場景
分區(qū)分表的區(qū)別
1、實現(xiàn)方式上
mysql的分表是真正的分表,一張表分成很多表后,每一個小表都是完整的一張表,都對應(yīng)三個文件,一個.MYD數(shù)據(jù)文件,.MYI索引文件,.frm表結(jié)構(gòu)
分區(qū)不一樣,一張大表進行分區(qū)后,他還是一張表,不會變成二張表,但是他存放數(shù)據(jù)的區(qū)塊變多了。
2、提高性能上
分表重點是存取數(shù)據(jù)時,如何提高mysql并發(fā)能力上;
而分區(qū)呢,如何突破磁盤的讀寫能力,從而達到提高mysql性能的目的。
3、實現(xiàn)的難易度上
1、分表的方法有很多,用merge來分表,是最簡單的一種方式。這種方式根分區(qū)難易度差不多,并且對程序代碼來說可以做到透明的。如果是用其他分表方式就比分區(qū)麻煩了。
2、分區(qū)實現(xiàn)是比較簡單的,建立分區(qū)表,根建平常的表沒什么區(qū)別,并且對開代碼端來說是透明的
分區(qū)分表的聯(lián)系
1、都能提高mysql的性高,在高并發(fā)狀態(tài)下都有一個良好的表現(xiàn)。
2、分表和分區(qū)不矛盾,可以相互配合的,對于那些大訪問量,并且表數(shù)據(jù)比較多的表,我們可以采取分表和分區(qū)結(jié)合的方式,訪問量不大,但是表數(shù)據(jù)很多的表,我們可以采取分區(qū)的方式等。
分庫分表存在的問題
1、事務(wù)問題
在執(zhí)行分庫分表之后,由于數(shù)據(jù)存儲到了不同的庫上,數(shù)據(jù)庫事務(wù)管理出現(xiàn)了困難。如果依賴數(shù)據(jù)庫本身的分布式事務(wù)管理功能去執(zhí)行事務(wù),將付出高昂的性能代價;如果由應(yīng)用程序去協(xié)助控制,形成程序邏輯上的事務(wù),又會造成編程方面的負擔。
2、跨庫跨表的join問題
在執(zhí)行了分庫分表之后,難以避免會將原本邏輯關(guān)聯(lián)性很強的數(shù)據(jù)劃分到不同的表、不同的庫上,這時,表的關(guān)聯(lián)操作將受到限制,我們無法join位于不同分庫的表,也無法join分表粒度不同的表,結(jié)果原本一次查詢能夠完成的業(yè)務(wù),可能需要多次查詢才能完成。
3、額外的數(shù)據(jù)管理負擔和數(shù)據(jù)運算壓力
額外的數(shù)據(jù)管理負擔,最顯而易見的就是數(shù)據(jù)的定位問題和數(shù)據(jù)的增刪改查的重復(fù)執(zhí)行問題,這些都可以通過應(yīng)用程序解決,但必然引起額外的邏輯運算。
例如,對于一個記錄用戶成績的用戶數(shù)據(jù)表userTable,業(yè)務(wù)要求查出成績最好的100位,在進行分表之前,只需一個order by語句就可以搞定,但是在進行分表之后,將需要n個order by語句,分別查出每一個分表的前100名用戶數(shù)據(jù),然后再對這些數(shù)據(jù)進行合并計算,才能得出結(jié)果。
方案三:冷熱歸檔
為什么要冷熱歸檔:其實原因和方案二類似,都是降低單表數(shù)據(jù)量,樹的高度變低,查詢經(jīng)歷的磁盤io變少,則可以提高效率 如果大家的業(yè)務(wù)數(shù)據(jù),有明顯的冷熱區(qū)分,比如:只需要展示近一周或一個月的數(shù)據(jù)。那么這種情況這一周喝一個月的數(shù)據(jù)我們稱之為熱數(shù)據(jù),其余數(shù)據(jù)為冷數(shù)據(jù)。那么我們可以將冷數(shù)據(jù)歸檔在其他的庫表中,提高我們熱數(shù)據(jù)的操作效率。
接下來講一下歸檔的過程
創(chuàng)建歸檔表 創(chuàng)建的歸檔表 原則上要與原表保持一致
歸檔表數(shù)據(jù)的初始化
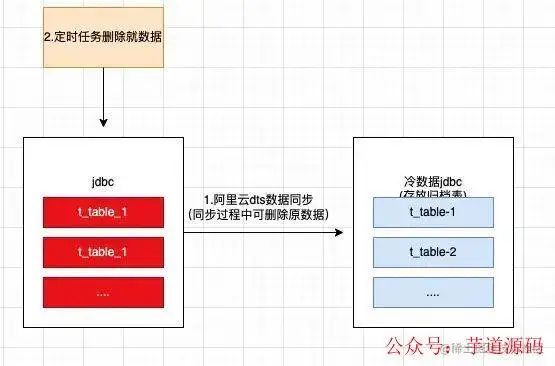
業(yè)務(wù)增量數(shù)據(jù)處理過程
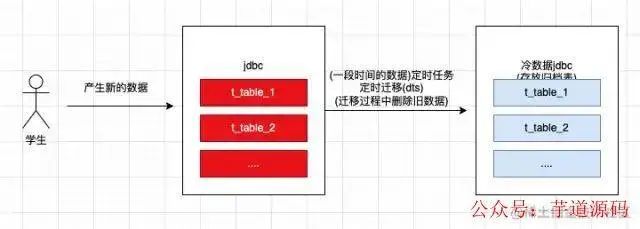
數(shù)據(jù)的獲取過程
以上三種方案我們?nèi)绾芜x型

大家可以根據(jù)自己的業(yè)務(wù)場景,去選擇合適自己業(yè)務(wù)的方案,我這邊就給大家提供一下思路~
審核編輯:劉清
-
cpu
+關(guān)注
關(guān)注
68文章
11048瀏覽量
216119 -
MySQL
+關(guān)注
關(guān)注
1文章
849瀏覽量
27606 -
MYSQL數(shù)據(jù)庫
+關(guān)注
關(guān)注
0文章
96瀏覽量
9793
原文標題:MySQL 處理大數(shù)據(jù)表的 3 種方案,寫的太好了,建議收藏!!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
MySQL筆記和小練習
常見大數(shù)據(jù)應(yīng)用有哪些?
Sql過濾重復(fù)數(shù)據(jù)處理方法
大數(shù)據(jù)專業(yè)技術(shù)學(xué)習之大數(shù)據(jù)處理流程
MySQL表分區(qū)類型及介紹
DKH企業(yè)級大數(shù)據(jù)解決方案的優(yōu)勢分析
為什么BLE的數(shù)據(jù)表中需要兩種服務(wù)?
什么是大數(shù)據(jù)?大數(shù)據(jù)的特點有哪些
MySQL批量插入數(shù)據(jù)的四種方案(性能測試對比)
MySQL到ES的4種常用數(shù)據(jù)同步方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論