 In-context learning介紹
In-context learning介紹

1 簡介?????????
隨著大規模預訓練語言模型(LLM)能力的不斷提升,in-context learning(ICL)逐漸成為自然語言處理領域一個新的范式。ICL通過任務相關的若干示例或者指令來增強上下文,從而提升語言模型預測效果,通過探索ICL的性能來評估跟推斷LLM能力也成為一種新的趨勢。
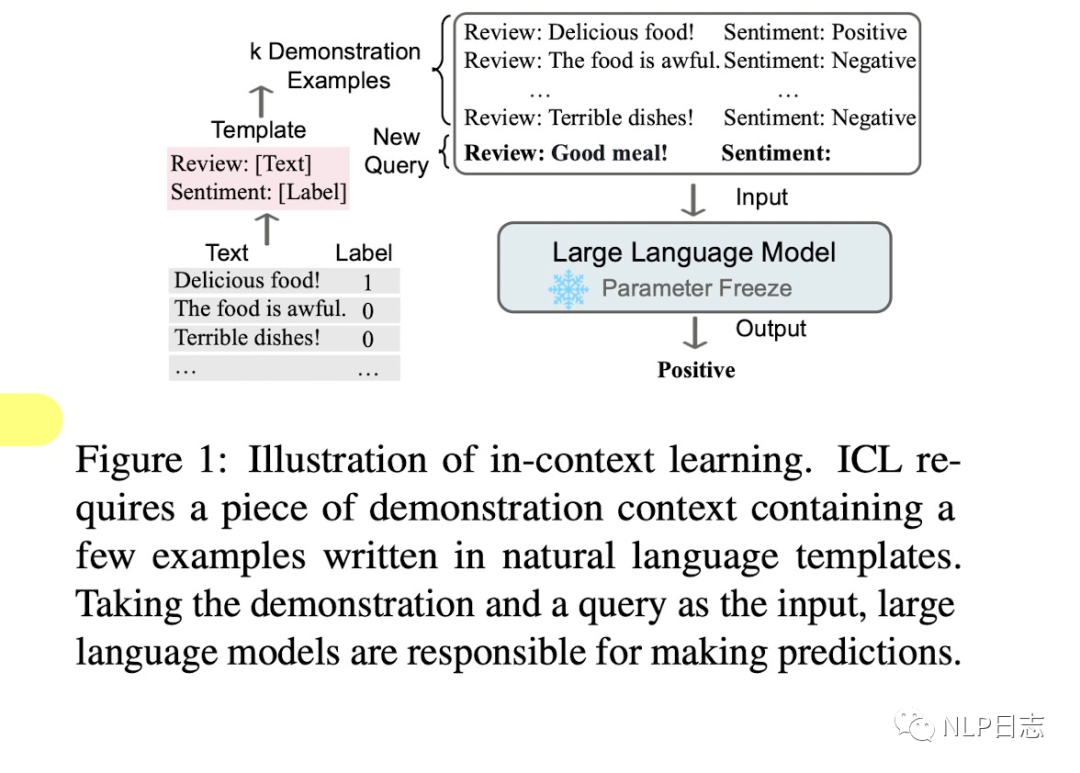
圖1: In-context learning示例
2 介紹
In-context learning是一種學習范式,它允許語言模型通過以演示形式組織的若干個示例或者指令來學習任務。In-context learning的核心在于從任務相關的類比樣本中學習,ICL要求若干示例以特定形式進行演示,然后將當前輸入x跟上述示例通過prompt拼接到一起作為語言模型的輸入。本質上,它利用訓練有素的語言模型根據演示的示例來估計候選答案的可能性。簡單理解,就是通過若干個完整的示例,讓語言模型更好地理解當前的任務,從而做出更加準確的預測。
從定義上可以發現in-context learning跟其他相關概念的差異,比如prompt learning跟few-shot learning。Prompt learning是通過學習合適的prompt來鼓勵模型預測出更加合適的結果,而prompt既可以是離散型,也可以是連續型。嚴格來講,in-context learning可以視為prompt learning中的一小部分,如果將in-context learning中的若干示例的演示視作prompt的話。Few-shot learning指的是在給定少量監督數據下利用參數更新來學習最佳模型參數的訓練方法,但in-context learning則不然,它不要求參數更新。
In-context learning有以下幾個優勢,
a)若干示例組成的演示是用自然語言撰寫的,這提供了一個跟LLM交流的可解釋性手段,通過這些示例跟模版讓語言模型更容易利用到人類的知識。
b)類似于人類類比學習的決策過程,舉一反三。
c)相比于監督學習,它不需要模型訓練,減小了計算模型適配新任務的計算成本,更容易應用到更多真實場景。
3 方法????????
In-context learning可以分為兩部分,分為作用于Training跟inference階段
3.1 Training
在推理前,通過持續學習讓語言模型的ICL能力得到進一步提升,這個過程稱之為warmup,warmup會優化語言模型對應參數或者新增參數,區別于傳統的finetune,finetune旨在提升LLM在特定任務上的表現,而warmup則是提升模型整理的ICL性能。
Supervised in-context training
通過構建對應的in-context的監督數據跟多任務訓練,進行對應的in-context finetune,從而縮小預訓練跟下游ICL的差距。除此之外,instruct tuning通過在instruction上訓練能提升LLM的ICL能力。
Self-supervised in-context training
根據ICL的格式將原始數據轉換成input-output的pair對數據后利用四個自監督目標進行訓練,包括掩碼語言,分類任務等。
Supervised training跟self-supervised training旨在通過引入更加接近于in-context learning的訓練目標從而縮小預訓練跟ICL之間的差距。比起需要示例的in-context finetuning,只涉及任務描述的instruct finetuning更加簡單且受歡迎。另外,在warmup這個階段,語言模型只需要從少量數據訓練就能明顯提升ICL能力,不斷增加相關數據并不能帶來ICL能力的持續提升。從某種角度上看,這些方法通過更加模型參數可以提升ICL能力也表明了原始的LLM具備這種潛力。雖然ICL不要求warmup,但是一般推薦在推理前增加一個warmup過程。
3.2 Inference
很多研究表明LLM的ICL性能嚴重依賴于演示示例的格式,以及示例順序等等,在使用目前很多LLM模型時我們也會發現,在推理時,同一個問題如果加上不同的示例,可能會得到不同的模型生成結果。
Demonstration Selection
對于ICL而言,那些樣本是好的?語言模型的輸入長度是有限制的,如何從眾多的樣本中挑選其中合適的部分作為示例這個過程非常重要。按照選擇的方法主要可以分為無監督跟有監督兩種。
其中無監督的方法分為以下幾種,首先就是根據句向量距離或者互信息等方式選擇跟當前輸入x最相似的樣本作為演示例,另外還有利用自使用方法去選擇最佳的示例排列,有的方法還會考慮到演示示例的泛化能力,盡可能去提高示例的多樣性。除了上述這些從人工撰寫的樣本中選擇示例的方式外,還可以利用語言模型自身去生成合適的演示示例。
至于監督的方法也有幾種,第一種是先利用無監督檢索器召回若干相似的樣本,再通過監督學習訓練的Efficient Prompt Retriever進行打分,從而篩選出最合適的樣本。此外還有基于prompt tuning跟強化學習的方式去選擇樣本。
Demonstration ordering
挑選完演示示例后,如何對其進行排序也非常重要。排序的方法既有不需要訓練的,也有根據示例跟當前輸入距離遠近進行排序的,也可以根據自定義的熵指標進行重排。
Demonstration Formatting
如何設計演示示例的格式?最簡單的方式就是將示例們的x-y對按照順序直接拼接到一起。但是對于復雜的推理問題,語言模型很難直接根據x推理出y,這種格式就不適用了。另外,有的研究旨在設計更好的任務指令instruction作為演示內容,上述的格式也就不適用了。對于這兩類場景,除了人工撰寫的方式外,還可以利用語言模型自身去生成對應的演示內容。
4 總結????????????????
上面關于in-context learning的介紹可能會讓人感到些許困惑,instruction tuning也算是其中一種,但是instruction里不一定有演示示例,我個人想法也是如此,如果大多數instruction里也會提及對應的任務示例,但是不排除部分instruction只涉及到任務定義,所以前面將in-context learning跟任務示例強綁定可能就不太嚴謹了。但是大家能理解其中的含義即可,也沒必要深究其中的某些表述。????
毋庸置疑,在大規模語言模型能力快速提升的今天,in-context learning的熱度還將持續一段時間,如何通過構建合適的in-context來進一步激發語言模型在特定任務下的表現是值得思考的問題,如果能讓語言模型自身去寫對應的任務示例或者指令,讓模型自己指導自己執行任務,不就進一步解放生產力了嘛。細品下autoGPT,不也是ai自己指導自己完成任務嘛。
審核編輯:劉清
-
icl
+關注
關注
0文章
28瀏覽量
17399 -
語言模型
+關注
關注
0文章
561瀏覽量
10790
原文標題:In-context learning綜述篇
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
鴻蒙開發接口Ability框架:【Context】
Context接口切換介紹
Ensemble Learning Task
把ChatGPT加入Flutter開發,會有怎樣的體驗?
一文解析In-Context Learning
In-context learning如何工作?斯坦福學者用貝葉斯方法解開其奧秘
大模型LLM領域,有哪些可以作為學術研究方向?

In-Context-Learning在更大的語言模型上表現不同
首篇!Point-In-Context:探索用于3D點云理解的上下文學習

基于Tansformer架構的ChatGPT原理解析
關于GO CONTEXT機制實現原則
基于單一LLM的情感分析方法的局限性

無監督域自適應場景:基于檢索增強的情境學習實現知識遷移

谷歌提出大規模ICL方法
鴻蒙開發組件:FA模型的Context





 工商網監
工商網監
評論