") In-Context-Learning在更大的語言模型上表現(xiàn)不同
In-Context-Learning在更大的語言模型上表現(xiàn)不同
最近,在語言模型領(lǐng)域取得了巨大的進展,部分是因為它們可以通過In-Context- Learning ( ICL)來完 成各種復(fù)雜的任務(wù)。在ICL中,模型在執(zhí)行未見過的用例之前,會首先接收一些輸入-標(biāo)簽對的示例。一 般來說,ICL對模型的增強,有以下原因:
按照上下文示例的格式,利用預(yù)訓(xùn)練階段得到的語義先驗知識來預(yù)測標(biāo)簽(例如,當(dāng)看到帶有“正面情感”和“負面情感”標(biāo)簽的電影評論示例,使用先驗知識來做情感分析)。
從給的上下文示例中學(xué)習(xí)輸入-標(biāo)簽的映射(例如,正面評論應(yīng)該映射到一個標(biāo)簽,負面評論應(yīng)該映射到另一個標(biāo)簽的模式)。
在本文中,我們旨在了解這兩個因素(語義先驗知識和輸入-標(biāo)簽映射)在ICL的影響,尤其是當(dāng)語言模 型的規(guī)模發(fā)生變化時。我們通過2種實驗方法來對這兩個因素進行研究,實驗方法分別為:翻轉(zhuǎn)標(biāo)簽的 ICL (flipped-label ICL)和語義無關(guān)標(biāo)簽的ICL ( SUL- ICL)。
在翻轉(zhuǎn)標(biāo)簽的ICL中,上下文示例的標(biāo)簽的語義被翻轉(zhuǎn)(例如原先的標(biāo)簽為“Negative”,被反轉(zhuǎn)為 “Positive”),使得語義先驗知識和輸入-標(biāo)簽映射不匹配。
ps:可以理解為,語義先驗知識中與該上下文示例相似的標(biāo)簽都是“Negative”的,但是此處通過“翻轉(zhuǎn)標(biāo)簽”方法,變?yōu)椤癙ositive”后,先驗知識與當(dāng)前的上下文示例的輸入-標(biāo)簽映射產(chǎn)生了不匹配。
在SUL- ICL中,上下文示例的標(biāo)簽被替換為與上下文中所呈現(xiàn)的任務(wù)在語義上無關(guān)的詞語(例如,原 先的標(biāo)簽“Positive”,被替換為"Foo")。
ps:例如,原先的標(biāo)簽為影評領(lǐng)域的,現(xiàn)在替換為美食或者其他領(lǐng)域的詞
我們發(fā)現(xiàn),覆蓋先驗知識是隨著模型規(guī)模的增大而涌現(xiàn)的一種能力(ps:覆蓋先驗知識可以理解為,從上 下文示例中學(xué)習(xí),而不是預(yù)訓(xùn)練階段的先驗知識),從語義無關(guān)標(biāo)簽的上下文中學(xué)習(xí)的能力也是如此。我們還發(fā)現(xiàn),指令微調(diào)(Instruct-tuning)對學(xué)習(xí)先驗知識能力的加強上要超過對學(xué)習(xí)輸入-標(biāo)簽映射的 增強。(下圖為普通ICL,翻轉(zhuǎn)標(biāo)簽ICL和語義無關(guān)ICL的示例)
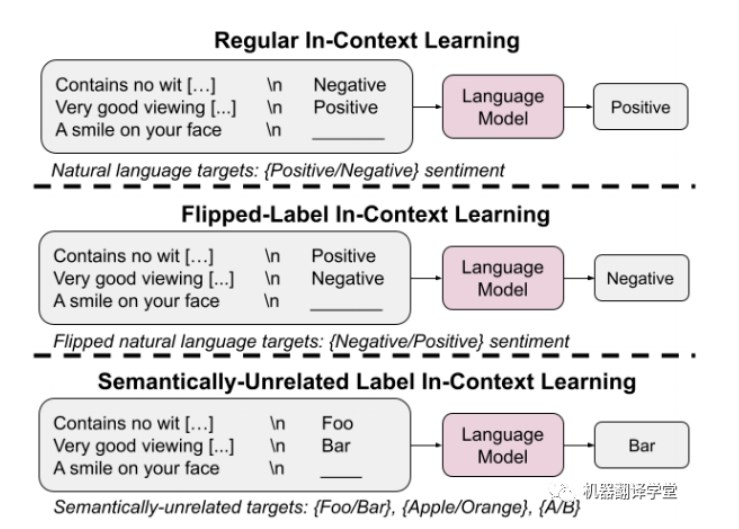
實驗設(shè)計
我們在七個廣泛使用的自然語言處理(NLP)任務(wù)上進行了實驗:情感分析、主/客觀分類、問題分類、 重復(fù)問題識別、蘊含關(guān)系識別、金融情感分析和仇恨言論檢測。我們在5種LLM上進行測試:PaLM、Flan- PaLM、GPT-InstructGPT和Codex。
翻轉(zhuǎn)標(biāo)簽(Flipped Labels-ICL)
在這個實驗中,上下文示例的標(biāo)簽被翻轉(zhuǎn),意味著先驗知識和輸入-標(biāo)簽映射不一致(例如,包含正面情 感的句子被標(biāo)記為“Negative”),從而讓我們可以研究模型是否能夠覆蓋其先驗知識。在這種情況下, 具備覆蓋先驗知識能力的模型的性能應(yīng)該會下降(因為真實的評估標(biāo)簽沒有被翻轉(zhuǎn))。(下圖為使用翻 轉(zhuǎn)標(biāo)簽ICL后,不同語言模型的不同尺寸的在測試集上的準(zhǔn)確率變化)
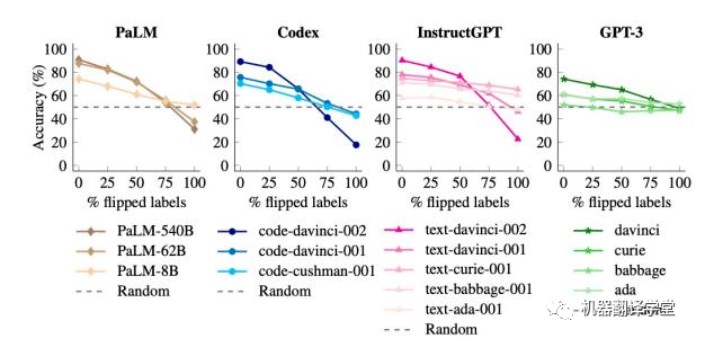
我們發(fā)現(xiàn),當(dāng)沒有標(biāo)簽被翻轉(zhuǎn)時,大型模型的性能優(yōu)于小型模型(如預(yù)期所示)。但是,當(dāng)我們翻轉(zhuǎn)越來越多的標(biāo)簽時,小型模型的性能保持相對穩(wěn)定,而大型模型的性能下降得非常明顯,甚至低于隨機猜 測的水平(例如,對于code-davinci-002模型,性能從90%下降到22.5%)。
這些結(jié)果表明,當(dāng)上下文中出現(xiàn)與先驗知識不一致的輸入-標(biāo)簽映射時,大型模型可以覆蓋預(yù)訓(xùn)練的先驗 知識,而小型模型則無法做到。
?作者說:此處,我理解為,更大的語言模型在覆蓋先驗知識的能力上更強,也就是更容易從給的上下文示例中學(xué)習(xí)到新的知識,如果給的上下文示例中存在與先驗知識沖突的情況,則模型會更加偏重上下文示例。
語義無關(guān)標(biāo)簽(SUL-ICL)
在這個實驗中,我們將標(biāo)簽替換為語義不相關(guān)的標(biāo)簽(例如,在情感分析中,我們使用“foo/bar”代替 “negative/positive”),這意味著模型只能通過學(xué)習(xí)輸入-標(biāo)簽映射來執(zhí)行ICL。如果模型在ICL中主要依 賴于先驗知識,那么在進行這種更改后,其性能應(yīng)該會下降,因為它將無法再利用標(biāo)簽的語義含義進行 預(yù)測。而如果模型能夠在上下文中學(xué)習(xí)輸入-標(biāo)簽映射,它就能夠?qū)W習(xí)這些語義無關(guān)的映射,并且不應(yīng)該 出現(xiàn)主要性能下降。
(下圖為使用語義無關(guān)標(biāo)簽ICL后,不同語言模型的不同尺寸的在測試集上的準(zhǔn)確率變化)
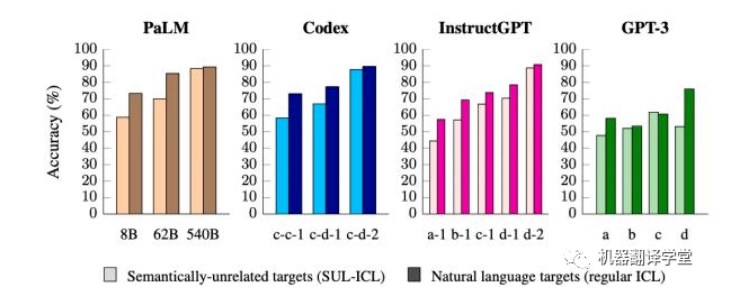
事實上,我們發(fā)現(xiàn)對于小型模型來說,使用語義無關(guān)標(biāo)簽導(dǎo)致了更大的性能下降。這表明,小型模型主要依賴于它們的語義先驗知識進行ICL,而不是從給的的輸入-標(biāo)簽映射示例中學(xué)習(xí)。另一方面,當(dāng)這些標(biāo)簽標(biāo)簽不再具備其原來所有的語義時,大型模型的學(xué)習(xí)上下文中的輸入-標(biāo)簽映射的能力更強。
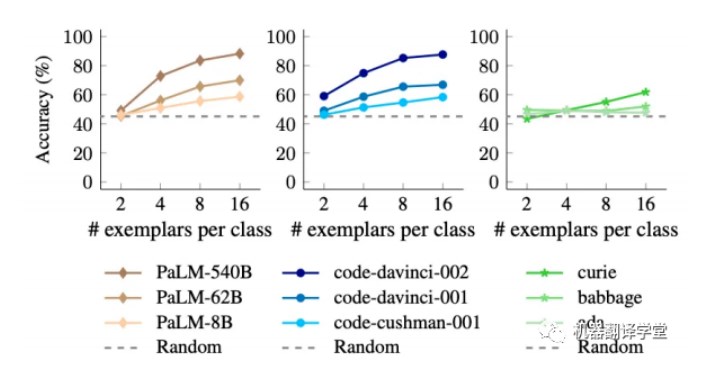
我們還發(fā)現(xiàn),模型輸入更多的上下文示例對于大型模型的性能的提升要強于小模型,這表明大型模型比 小型模型更擅長從上下文示例中學(xué)習(xí)。
(下圖為使用不同數(shù)量的語義無關(guān)標(biāo)簽ICL后,不同語言模型的不同尺寸的在測試集上的準(zhǔn)確率變化)
指令微調(diào)(Instruction tuning)
指令微調(diào)是一種提高模型性能的常用技術(shù),它將各種自然語言處理(NLP)任務(wù)調(diào)整為指令的形式輸入 給模型(例如,“問題:以下句子的情感是什么?答案:積極的“)。然而,由于該過程使用自然語言標(biāo)簽,一個懸而未決的問題是,它是否提高了學(xué)習(xí)輸入-標(biāo)簽映射的能力,亦或是增強了學(xué)習(xí)并應(yīng)用語義先驗知識的能力。這兩者都會給ICL任務(wù)帶來性能提升,因此目前尚不清楚這兩者中哪一個生效了。
我們通過前兩個實驗方法繼續(xù)研究這個問題,但這一次我們專注于比較標(biāo)準(zhǔn)語言模型(PaLM)與經(jīng)過指令微調(diào)的模型(Flan- PaLM)之間的差異。
首先,我們發(fā)現(xiàn)在使用語義無關(guān)標(biāo)簽時, Flan- PaLM要優(yōu)于PaLM。在小型模型中,這種效果非常明顯, Flan- PaLM-8B的性能超過PaLM-8B約9.6%,并且接近PaLM-62B的性能。這一趨勢表明,指令微調(diào)增強了學(xué)習(xí)輸入-標(biāo)簽映射的能力。
(下圖表明:指令微調(diào)后的模型更容易學(xué)習(xí)輸入-標(biāo)簽映射)
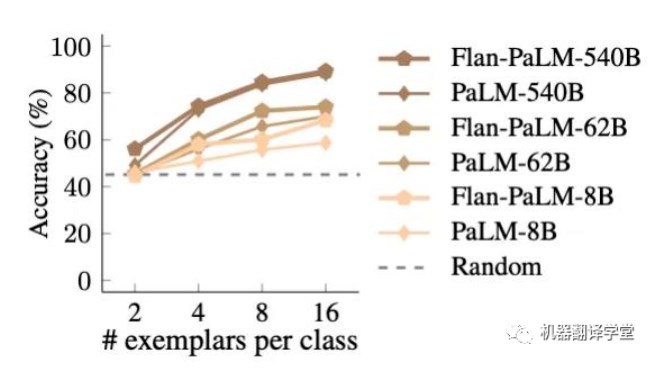
更有趣的是,我們發(fā)現(xiàn)Flan- PaLM在遵循翻轉(zhuǎn)標(biāo)簽方面實際上比PaLM要差,這意味著經(jīng)過指令調(diào)整的模型無法覆蓋其先驗知識(Flan- PaLM模型在100%翻轉(zhuǎn)標(biāo)簽的情況下無法達到低于隨機猜測 的水平,而沒有經(jīng)過指令調(diào)整的PaLM模型在相同設(shè)置下可以達到31%的準(zhǔn)確率)。這些結(jié)果表明,指令調(diào)整必須增加模型在有語義先驗知識可用時依賴于語義先驗知識的程度。
(下圖表示:指令微調(diào)后的模型,在使用翻轉(zhuǎn)標(biāo)簽ICL時,更不容易覆蓋先驗知識)
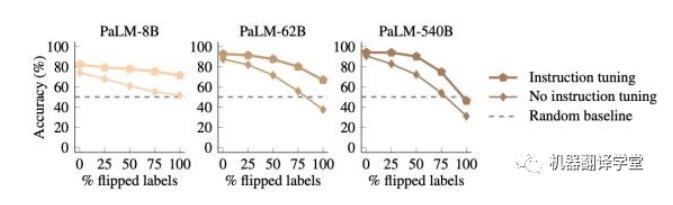
結(jié)合之前的結(jié)果,我們得出結(jié)論,雖然指令微調(diào)提高了學(xué)習(xí)輸入-標(biāo)簽映射的能力,但它在學(xué)習(xí)語義先驗 知識上的加強更為突出。
結(jié)論
通過上述實驗,可以得到以下的結(jié)論:
首先,大語言模型可以在輸入足夠多的翻轉(zhuǎn)標(biāo)簽的情況下學(xué)會對先驗知識的覆蓋,并且這種能力隨 著模型規(guī)模的增大而加強。
其次,使用語義無關(guān)標(biāo)簽進行上下文學(xué)習(xí)的能力隨著模型規(guī)模的增大而加強。
最后,通過對指令微調(diào)后的語言模型的研究,發(fā)現(xiàn)指令微調(diào)雖然可以提高學(xué)習(xí)輸入-標(biāo)簽映射的能 力,但遠不如其對學(xué)習(xí)語義先驗知識的加強。
未來工作
這些結(jié)果強調(diào)了語言模型的ICL行為在模型規(guī)模方面可能發(fā)生變化,而更大的語言模型具有將輸入映射到更多種類型標(biāo)簽的能力,這可能使得模型可以學(xué)習(xí)任意符號的輸入-標(biāo)簽映射。未來的研究可以幫助我們更好地理解這種現(xiàn)象。
審核編輯:劉清
-
Palm
+關(guān)注
關(guān)注
0文章
22瀏覽量
11416 -
icl
+關(guān)注
關(guān)注
0文章
28瀏覽量
17377 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22512
原文標(biāo)題:In-Context-Learning在更大的語言模型上表現(xiàn)不同
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大型語言模型的邏輯推理能力探究
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
大語言模型:原理與工程時間+小白初識大語言模型
Context接口切換介紹
HarmonyOS/OpenHarmony應(yīng)用開發(fā)-Stage模型ArkTS語言AbilityStage
微軟視覺語言模型有顯著超越人類的表現(xiàn)
應(yīng)用于任意預(yù)訓(xùn)練模型的prompt learning模型—LM-BFF

一文解析In-Context Learning
In-context learning如何工作?斯坦福學(xué)者用貝葉斯方法解開其奧秘
In-context learning介紹
首篇!Point-In-Context:探索用于3D點云理解的上下文學(xué)習(xí)

鴻蒙開發(fā)組件:FA模型的Context





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論