 基于學習的激光雷達定位退化場景估計
基于學習的激光雷達定位退化場景估計
摘要

基于激光雷達的定位與建圖系統是許多現代機器人系統中的核心組成部分。其直接繼承了環境的深度與幾何信息,從而允許精確的運動估計與實時生成高質量的地圖。然而,不充分的環境約束會導致定位失敗,這種情況經常發生在諸如隧道等對稱的場景中。本文的工作準確地解決了這個問題,通過神經網絡法來檢測機器人的周圍環境是否發生退化。我們特別關注于激光雷達的幀間匹配,因為其是許多激光雷達里程計的至關重要的部件。與之前的方法不同的是,我們的方法直接根據原始的點云測量來檢測定位失敗的可能,而不是在配準過程中檢測。此外,之前的方法在泛化能力上有所局限,因為需要人為調節退化檢測的閾值。我們提出的方法通過從一系列不同的環境中學習來使得網絡在各個場景中都表現得更好,從而避免了這個問題。此外,該網絡專門針對模擬數據進行訓練,避免在具有挑戰性和退化且通常難以訪問的環境中進行艱巨的數據收集。所提出的方法在未經任何修改的情況下,在具有挑戰性的環境和兩種不同的傳感器類型上進行的實地實驗中進行了測試。觀察到的檢測性能與最先進方法在專門調整閾值后的性能相當。
主要貢獻
提出一種基于學習的方法,來檢測單幀點云在六個自由度上是否發生退化。
提出一種驗證方法,來驗證四足機器人在挑戰性與退化場景下的定位能力。
所有部分都經過完備的設計與實現,包括數據集的采集與生成。相關的部分均會在機器人社區開源。
方法論
1. 問題建模
本文想檢測機器人在某個時刻的定位能力:(localizability)。這可以通過一個6維的向量表示:
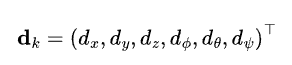
其中,x, y, z表示平移方向上的分量,Φ,θ,ψ表示旋轉方向上的分量(歐拉角表示)。向量d_k的每個分量都是二值的(0或者1,其中0表示該分量上的定位信息可靠,1則表示不可靠)。
估計d_k的過程可以構建為一個多標簽二值分類問題,并且通過一個神經網絡分類器得到結果。
2. 訓練數據生成
按照上述的問題建模方式,一個重要的點是如何生成帶有標簽的訓練數據?具體而言,對一個點云,如何評估它在六個自由度上的退化情況?
本文提出的方法是加擾動然后看配準誤差的方式。對于某個點云s以及采集到它時機器人的位姿T,生成M個子點云,生成一個子點云的方式為:
1. 對位姿進行擾動,擾動的值通過對0均值高斯分布進行采樣,每個維度上的高斯分布的δ為:
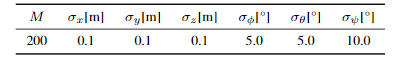
2. 根據擾動后的位姿,在仿真環境中,通過光線投射來獲得一個新的子點云。
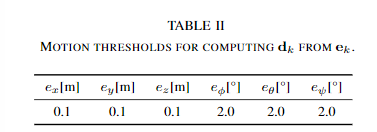
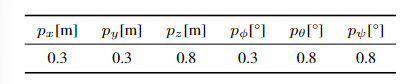
將這M個子點云與原始點云進行配準,配準方法為點到面的ICP方法。計算每個子點云配準得到的transform與原始擾動的transform的差值e,分解到六個維度上取絕對值,并相加求平均值得到e_p。通過評估e_p在6個維度上是否超過特定的閾值,來判斷原始點云是否容易在特定的維度上發生退化。6個維度上的閾值為:
3. 網絡結構
上一步獲得了帶有標簽的點云,這一步則是通過網絡來學習并訓練。本文所采取的網絡結構基于3D ResUNet(見論文Fully convolutional geometric features),其具體網絡結構為:
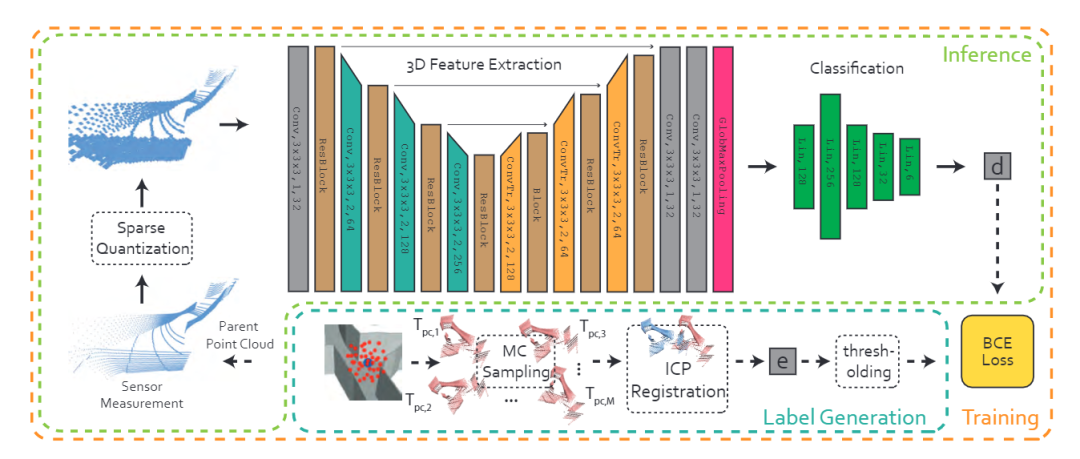
分類網絡則是一個5層的MLP,輸出是一個6維的向量。
該網絡的損失函數定義為:
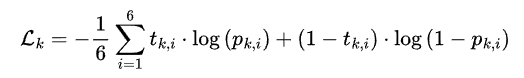
其中,t表示第k個點云在第i個分量上的標簽,而p則表示網絡預測的對應的概率值。
由于網絡預測的是一個概率值,在使用時本文通過對各個維度設置不同的閾值來確定各個維度是否發生退化,其值為
方法論
1. 消融實驗
在該實驗中,將特征提取網絡換為Point-Net,并且比較了更換前后的各項分類性能:
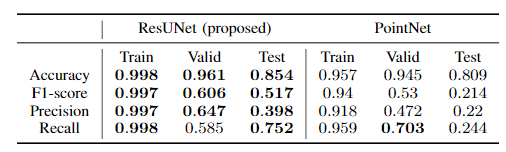
從表格中可以得出,在大部分指標中,ResUNet均高于PointNet。
2.實地實驗
在三個場景中進行了場地實驗:隧道、開闊戶外與城鎮場景。采用的SLAM框架為CompSLAM(見論文Complementary multi–modal sensor fusion forresilient robot pose estimation in subterranean environments)。這個框架中,所用的評估退化的方式是Ji Zhang的論文“On Degeneracy of Optimization-based State Estimation Problems”中提到的方法(該論文在泡泡機器人-點云時空中亦有詳細翻譯,有興趣同學可以自行搜索)。CompSLAM在檢測到激光雷達出現退化后,切換為VIO的結果進行遞推,而在沒有退化的場景中,用VIO的結果作為LOAM的先驗進行幀間配準。本文將該方法替換為所提出的基于學習的方法,并與原始版本的CompSLAM進行比較。
a. 隧道場景:
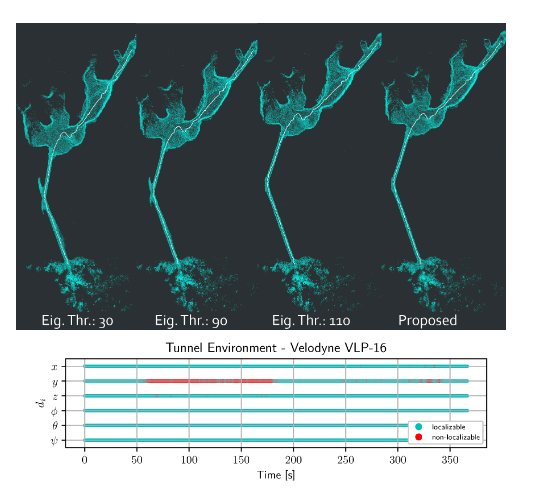
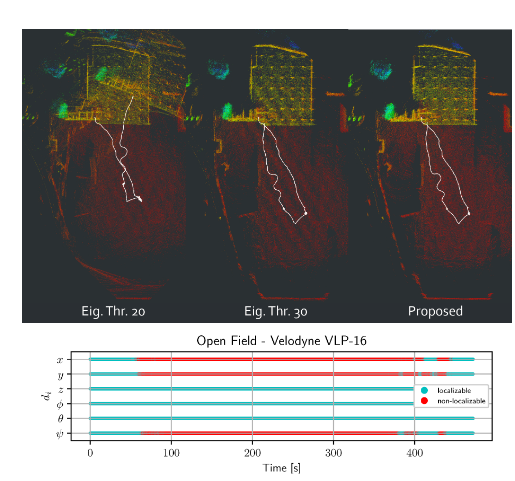
下圖給出了隧道場景中的建圖效果。其中左邊三幅圖為Ji zhang的方法采用不同閾值后的結果,最右則為本文提出的結果。而下面的條狀圖則表示各個維度出現退化的時間。可以看出,本文提出的方法與Ji Zhang的方法在閾值為110時的效果類似。
b. 開放戶外場景:
同隧道場景。
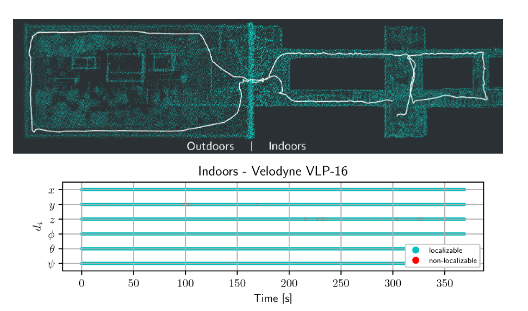
c. 城市場景:
這個場景中沒有做對比試驗,而是僅僅測試了提出的方法。測試場景為咖啡店的內部與外部。機器人從室內走到室外并且回到室內,可以看到建圖保持了較好的一致性,并且學習到的6維向量表示全程都沒有發生退化情況
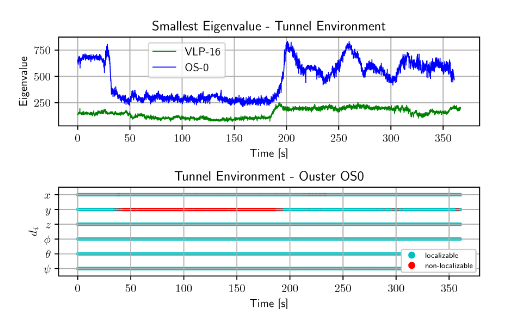
3. 泛化實驗
對于隧道場景,利用VLP-16與Ouster 128線的激光雷達進行測試。從下圖中可以看出,利用Ji zhang的方法(即求一個特定矩陣的最小特征值),對于兩個傳感器,其最小特征值的差別是巨大的。然而本文所提出的方法仍能比較好的檢測到隧道的特定段發生了退化,并且與場地實驗中的隧道實驗保持一致。
評價與未來工作
1. 個人評價
這項工作的創新在于直接對點云進行退化的評估,而不是根據配準的結果。數據的生成與訓練的方式都比較直接易懂,并且實驗的效果也很好。
這個方法是應用在類似于LOAM的系統上的,因此制作訓練集的時候,只用單幀點云的匹配結果來生成退化label。對于類似于Fast-LIO這樣直接進行scan-map配準的方法,這種制作訓練集并訓練的方式不一定可靠:因為在一些場景下,可能出現scan-scan配準退化,但scan-map不一定是退化的(local map有更豐富的信息)。解決這個問題的途徑之一,可以在訓練的時候也采用scan-map的配準方法來評價配準誤差。
2. 未來工作
本文的作者提出的未來工作有:
1)網絡直接出6x6的位姿協方差矩陣。
2)根據退化信息來決定優化的時候,僅僅優化部分維度而不是所有維度。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102916 -
激光雷達
+關注
關注
971文章
4203瀏覽量
192083 -
數據集
+關注
關注
4文章
1223瀏覽量
25295
原文標題:基于學習的激光雷達定位退化場景估計
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論