 Linux 性能優化總結!2
Linux 性能優化總結!2
內存
Linux內存是怎么工作的
內存映射
大多數計算機用的主存都是動態隨機訪問內存(DRAM),只有內核才可以直接訪問物理內存。Linux內核給每個進程提供了一個獨立的虛擬地址空間,并且這個地址空間是連續的。這樣進程就可以很方便的訪問內存(虛擬內存)。
虛擬地址空間的內部分為內核空間和用戶空間兩部分,不同字長的處理器地址空間的范圍不同。32位系統內核空間占用1G,用戶空間占3G。64位系統內核空間和用戶空間都是128T,分別占內存空間的最高和最低處,中間部分為未定義。
并不是所有的虛擬內存都會分配物理內存,只有實際使用的才會。分配后的物理內存通過內存映射管理。為了完成內存映射,內核為每個進程都維護了一個頁表,記錄虛擬地址和物理地址的映射關系。頁表實際存儲在CPU的內存管理單元MMU中,處理器可以直接通過硬件找出要訪問的內存。
當進程訪問的虛擬地址在頁表中查不到時,系統會產生一個缺頁異常,進入內核空間分配物理內存,更新進程頁表,再返回用戶空間恢復進程的運行。
MMU以頁為單位管理內存,頁大小4KB。為了解決頁表項過多問題Linux提供了多級頁表和HugePage的機制。
虛擬內存空間分布
用戶空間內存從低到高是五種不同的內存段:
- 只讀段 代碼和常量等
- 數據段 全局變量等
- 堆 動態分配的內存,從低地址開始向上增長
- 文件映射 動態庫、共享內存等,從高地址開始向下增長
- 棧 包括局部變量和函數調用的上下文等,棧的大小是固定的。一般8MB
內存分配與回收
分配
malloc 對應到系統調用上有兩種實現方式:
-
brk() 針對小塊內存(<128K),通過移動堆頂位置來分配。
內存釋放后不立即歸還內存,而是被緩存起來。
-
mmap() 針對大塊內存(>128K),直接用內存映射來分配,即在文件映射段找一塊空閑內存分配。
前者的緩存可以減少缺頁異常的發生,提高內存訪問效率。但是由于內存沒有歸還系統,在內存工作繁忙時,頻繁的內存分配/釋放會造成內存碎片。
后者在釋放時直接歸還系統,所以每次mmap都會發生缺頁異常。
在內存工作繁忙時,頻繁內存分配會導致大量缺頁異常,使內核管理負擔增加。
上述兩種調用并沒有真正分配內存,這些內存只有在首次訪問時,才通過缺頁異常進入內核中,由內核來分配
回收
內存緊張時,系統通過以下方式來回收內存:
- 回收緩存:LRU算法回收最近最少使用的內存頁面;
- 回收不常訪問內存:把不常用的內存通過交換分區寫入磁盤
- 殺死進程:OOM內核保護機制(進程消耗內存越大 oom_score 越大,占用 CPU 越多 oom_score 越小,可以通過 /proc 手動調整 oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj如何查看內存使用情況
free來查看整個系統的內存使用情況
top/ps來查看某個進程的內存使用情況
- VIRT 進程的虛擬內存大小
- RES 常駐內存的大小,即進程實際使用的物理內存大小,不包括swap和共享內存
- SHR 共享內存大小,與其他進程共享的內存,加載的動態鏈接庫以及程序代碼段
- %MEM 進程使用物理內存占系統總內存的百分比
怎樣理解內存中的Buffer和Cache?
buffer是對磁盤數據的緩存,cache是對文件數據的緩存,它們既會用在讀請求也會用在寫請求中
如何利用系統緩存優化程序的運行效率
緩存命中率
緩存命中率是指直接通過緩存獲取數據的請求次數,占所有請求次數的百分比。命中率越高說明緩存帶來的收益越高,應用程序的性能也就越好。
安裝bcc包后可以通過cachestat和cachetop來監測緩存的讀寫命中情況。
安裝pcstat后可以查看文件在內存中的緩存大小以及緩存比例
#首先安裝Goexport GOPATH=~/goexport PATH=~/go/bin:$PATHgo get golang.org/x/sys/unixgo ge github.com/tobert/pcstat/pcstatdd緩存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生產一個512MB的臨時文件echo 3 > /proc/sys/vm/drop_caches #清理緩存pcstat file #確定剛才生成文件不在系統緩存中,此時cached和percent都是0cachetop 5dd if=file of=/dev/null bs=1M #測試文件讀取速度#此時文件讀取性能為30+MB/s,查看cachetop結果發現并不是所有的讀都落在磁盤上,讀緩存命中率只有50%。dd if=file of=/dev/null bs=1M #重復上述讀文件測試#此時文件讀取性能為4+GB/s,讀緩存命中率為100%pcstat file #查看文件file的緩存情況,100%全部緩存O_DIRECT選項繞過系統緩存
cachetop 5sudo docker run --privileged --name=app -itd feisky/app:io-directsudo docker logs app #確認案例啟動成功#實驗結果表明每讀32MB數據都要花0.9s,且cachetop輸出中顯示1024次緩存全部命中但是憑感覺可知如果緩存命中讀速度不應如此慢,讀次數時1024,頁大小為4K,五秒的時間內讀取了1024*4KB數據,即每秒0.8MB,和結果中32MB相差較大。說明該案例沒有充分利用緩存,懷疑系統調用設置了直接I/O標志繞過系統緩存。因此接下來觀察系統調用。
strace -p $(pgrep app)#strace 結果可以看到openat打開磁盤分區/dev/sdb1,傳入參數為O_RDONLY|O_DIRECT這就解釋了為什么讀32MB數據那么慢,直接從磁盤讀寫肯定遠遠慢于緩存。找出問題后我們再看案例的源代碼發現flags中指定了直接IO標志。刪除該選項后重跑,驗證性能變化。
內存泄漏,如何定位和處理?
對應用程序來說,動態內存的分配和回收是核心又復雜的一個邏輯功能模塊。管理內存的過程中會發生各種各樣的“事故”:
- 沒正確回收分配的內存,導致了泄漏
- 訪問的是已分配內存邊界外的地址,導致程序異常退出
內存的分配與回收
虛擬內存分布從低到高分別是只讀段,數據段,堆,內存映射段,棧五部分。其中會導致內存泄漏的是:
- 堆:由應用程序自己來分配和管理,除非程序退出這些堆內存不會被系統自動釋放。
- 內存映射段:包括動態鏈接庫和共享內存,其中共享內存由程序自動分配和管理
內存泄漏的危害比較大,這些忘記釋放的內存,不僅應用程序自己不能訪問,系統也不能把它們再次分配給其他應用。內存泄漏不斷累積甚至會耗盡系統內存。
如何檢測內存泄漏
預先安裝systat,docker,bcc
sudo docker run --name=app -itd feisky/app:mem-leaksudo docker logs appvmstat 3可以看到free在不斷下降,buffer和cache基本保持不變。說明系統的內存一致在升高。但并不能說明存在內存泄漏。此時可以通過memleak工具來跟蹤系統或進程的內存分配/釋放請求
/usr/share/bcc/tools/memleak -a -p $(pidof app)從 memleak 輸出可以看到,應用在不停地分配內存,并且這些分配的地址并沒有被回收。通過調用棧看到是 fibonacci 函數分配的內存沒有釋放。定位到源碼后查看源碼來修復增加內存釋放函數即可。
為什么系統的 Swap 變高
系統內存資源緊張時通過內存回收和OOM殺死進程來解決。其中可回收內存包括:
- 緩存/緩沖區,屬于可回收資源,在文件管理中通常叫做文件頁
- 在應用程序中通過fsync將臟頁同步到磁盤
- 交給系統,內核線程pdflush負責這些臟頁的刷新
- 被應用程序修改過暫時沒寫入磁盤的數據(臟頁),要先寫入磁盤然后才能內存釋放
- 內存映射獲取的文件映射頁,也可以被釋放掉,下次訪問時從文件重新讀取
對于程序自動分配的堆內存,也就是我們在內存管理中的匿名頁,雖然這些內存不能直接釋放,但是 Linux 提供了 Swap 機制將不常訪問的內存寫入到磁盤來釋放內存,再次訪問時從磁盤讀取到內存即可。
Swap原理
Swap本質就是把一塊磁盤空間或者一個本地文件當作內存來使用,包括換入和換出兩個過程:
- 換出:將進程暫時不用的內存數據存儲到磁盤中,并釋放這些內存
- 換入:進程再次訪問內存時,將它們從磁盤讀到內存中
Linux如何衡量內存資源是否緊張?
-
直接內存回收新的大塊內存分配請求,但剩余內存不足。
此時系統會回收一部分內存;
-
kswapd0 內核線程定期回收內存。
為了衡量內存使用情況,定義了pages_min,pages_low,pages_high 三個閾值,并根據其來進行內存的回收操作。
-
剩余內存 < pages_min,進程可用內存耗盡了,只有內核才可以分配內存
-
pages_min < 剩余內存 < pages_low,內存壓力較大,kswapd0執行內存回收,直到剩余內存 > pages_high
-
pages_low < 剩余內存 < pages_high,內存有一定壓力,但可以滿足新內存請求
-
剩余內存 > pages_high,說明剩余內存較多,無內存壓力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
-
NUMA 與 SWAP
很多情況下系統剩余內存較多,但 SWAP 依舊升高,這是由于處理器的 NUMA 架構。
在NUMA架構下多個處理器劃分到不同的 Node,每個Node都擁有自己的本地內存空間。在分析內存的使用時應該針對每個Node單獨分析
numactl --hardware #查看處理器在Node的分布情況,以及每個Node的內存使用情況內存三個閾值可以通過 /proc/zoneinfo 來查看,該文件中還包括活躍和非活躍的匿名頁/文件頁數。
當某個Node內存不足時,系統可以從其他Node尋找空閑資源,也可以從本地內存中回收內存。通過/proc/sys/vm/zone_raclaim_mode來調整。
- 0表示既可以從其他Node尋找空閑資源,也可以從本地回收內存
- 1,2,4 表示只回收本地內存,2表示可以會回臟數據回收內存,4表示可以用Swap方式回收內存。
swappiness
在實際回收過程中Linux根據 /proc/sys/vm/swapiness 選項來調整使用Swap的積極程度,從 0-100,數值越大越積極使用 Swap,即更傾向于回收匿名頁;數值越小越消極使用 Swap,即更傾向于回收文件頁。
注意:這只是調整 Swap 積極程度的權重,即使設置為0,當剩余內存+文件頁小于頁高閾值時,還是會發生 Swap。
Swap升高時如何定位分析
free #首先通過free查看swap使用情況,若swap=0表示未配置Swap#先創建并開啟swapfallocate -l 8G /mnt/swapfilechmod 600 /mnt/swapfilemkswap /mnt/swapfileswapon /mnt/swapfile
free #再次執行free確保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模擬大文件讀取sar -r -S 1 #查看內存各個指標變化 -r內存 -S swap#根據結果可以看出,%memused在不斷增長,剩余內存kbmemfress不斷減少,緩沖區kbbuffers不斷增大,由此可知剩余內存不斷分配給了緩沖區#一段時間之后,剩余內存很小,而緩沖區占用了大部分內存。此時Swap使用之間增大,緩沖區和剩余內存只在小范圍波動
停下sar命令cachetop5 #觀察緩存#可以看到dd進程讀寫只有50%的命中率,未命中數為4w+頁,說明正式dd進程導致緩沖區使用升高watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #觀察內存指標變化#發現升級內存在一個小范圍不停的波動,低于頁低閾值時會突然增大到一個大于頁高閾值的值說明剩余內存和緩沖區的波動變化正是由于內存回收和緩存再次分配的循環往復。有時候 Swap 用的多,有時候緩沖區波動更多。此時查看 swappiness 值為60,是一個相對中和的配置,系統會根據實際運行情況來選去合適的回收類型。
如何“快準狠”找到系統內存存在的問題
內存性能指標
- 系統內存指標
- 已用內存/剩余內存
- 共享內存 (tmpfs實現)
- 可用內存:包括剩余內存和可回收內存
- 緩存:磁盤讀取文件的頁緩存,slab分配器中的可回收部分
- 緩沖區:原始磁盤塊的臨時存儲,緩存將要寫入磁盤的數據
進程內存指標
- 虛擬內存:5大部分
- 常駐內存:進程實際使用的物理內存,不包括Swap和共享內存
- 共享內存:與其他進程共享的內存,以及動態鏈接庫和程序的代碼段
- Swap 內存:通過Swap換出到磁盤的內存
缺頁異常
- 可以直接從物理內存中分配,次缺頁異常
- 需要磁盤 IO 介入(如 Swap),主缺頁異常。此時內存訪問會慢很多
內存性能工具
根據不同的性能指標來找合適的工具:
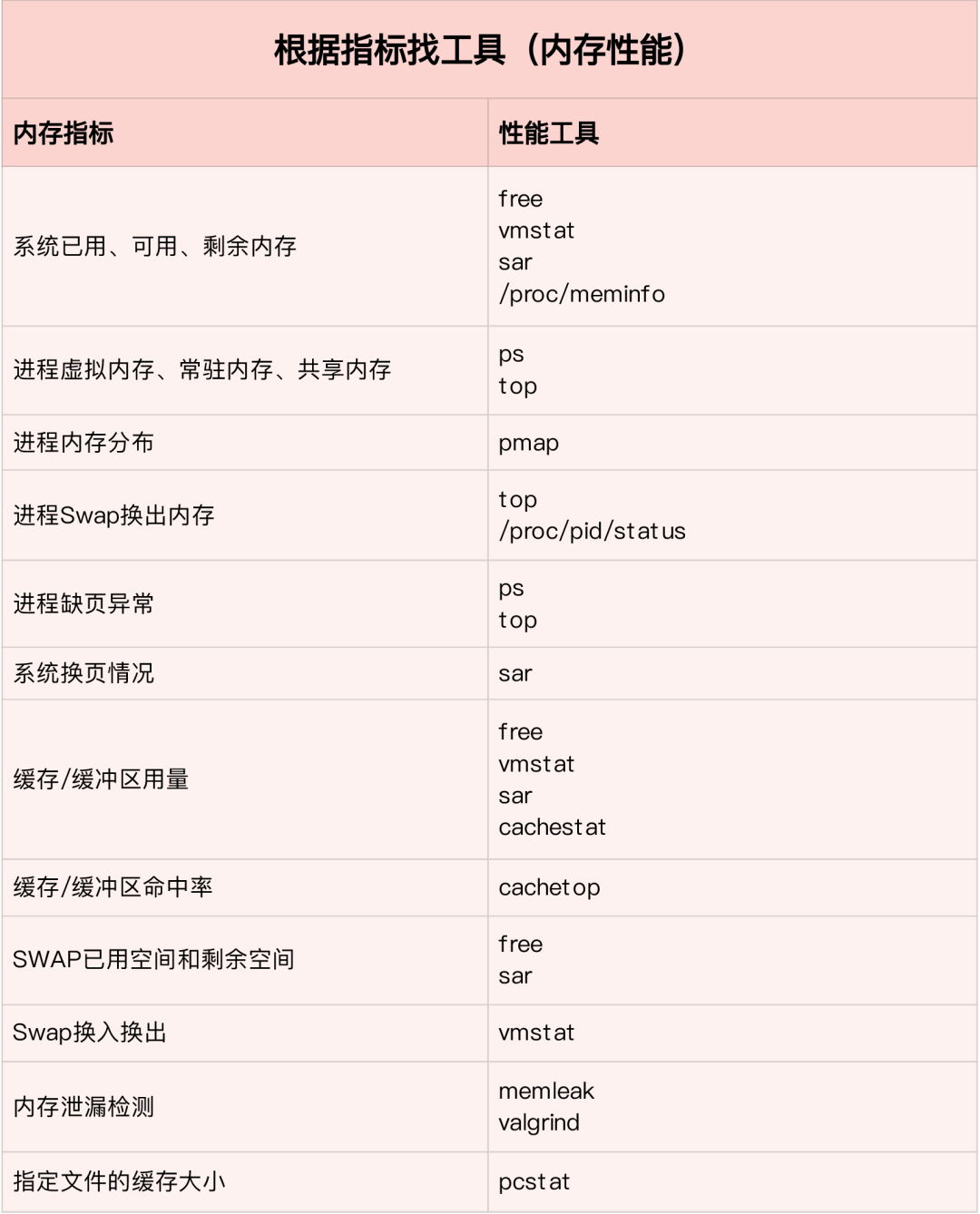
內存分析工具包含的性能指標:
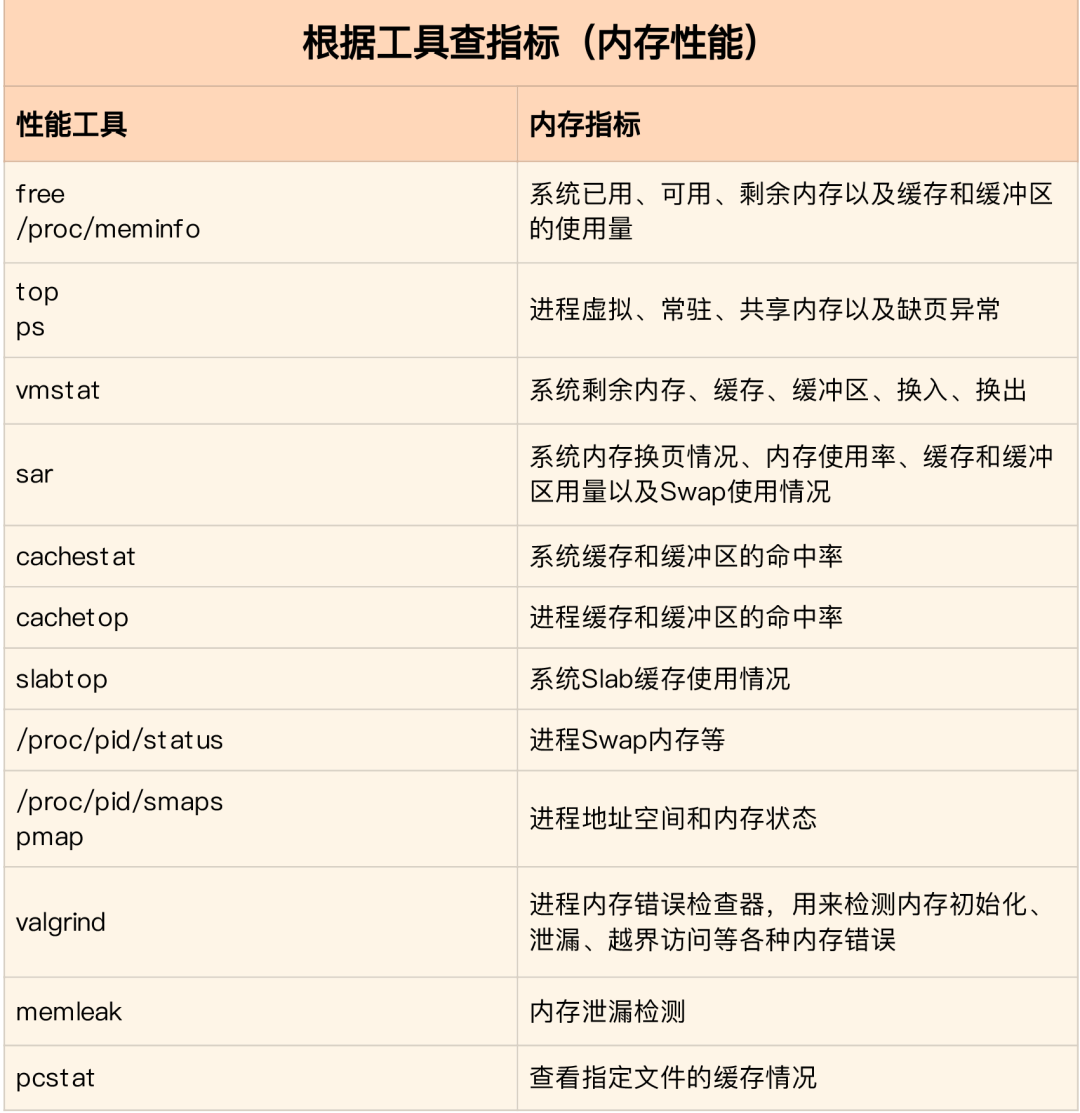
-
DRAM
+關注
關注
40文章
2343瀏覽量
185273 -
Linux
+關注
關注
87文章
11475瀏覽量
212999 -
計算機
+關注
關注
19文章
7637瀏覽量
90322 -
虛擬內存
+關注
關注
0文章
78瀏覽量
8221
發布評論請先 登錄
HBase性能優化方法總結
Linux系統的性能優化策略
基于Linux的Socket網絡編程的性能優化



Linux CPU的性能應該如何優化
Linux的基礎學習筆記資料總結

Linux 性能優化總結!1

Linux 性能優化總結!3
Linux內核slab性能優化的核心思想





 工商網監
工商網監
評論