 和ChatGPT相關的所有評估可能都不做數了!
和ChatGPT相關的所有評估可能都不做數了!
總說一下
大型語言模型已經看到數萬億個tokens。然而,誰知道里面是什么?最近的工作已經在許多不同的任務中評估了這些模型,但是,他們是否確保模型沒有看到訓練甚至評估數據集?在這篇博文中,我們展示了一些流行的已經被 ChatGPT 記住的基準數據集,并且可以提示 ChatGPT 重新生成它們。
ChatGPT 公開發布已經六個月了。目前,出乎意料的出色表現使它的知名度超出了研究界,通過媒體傳播到了普通大眾。這是語言模型 (LM) 的轉折點,以前用作驅動不同產品的引擎,現在變成了自己的產品。
自然語言處理(NLP)領域的研究方向也相應發生了變化。作為一個跡象,在 5 月 25 日星期四,即 EMNLP23 匿名期開始兩天后,在 arXiv 上的計算和語言類別下發表了 279 篇論文。在這 279 篇論文中,101 篇包含語言模型或 LM,25 篇是 GPT,10 篇直接提到了 ChatGPT。一年前的同一天,同一類別下發表了 81 篇論文。
不幸的是,我們對 ChatGPT 和許多其他封閉式 LM 背后的細節幾乎一無所知:架構、epoch、loss、過濾或去重步驟,尤其是用于訓練它們的數據。鑒于 ChatGPT 的良好性能,許多研究都以它或其他封閉的 LM 為基準。但與此同時,得出經驗結論的過程幾乎變得不可能。為了更好地理解問題,讓我們看一個例子:
想象一下,您是從事信息提取工作的 NLP 研究人員。你想看看這個新的封閉 LM 如何以零樣本的方式識別文本中的相關實體,比如人(即不給模型任何帶標簽的例子)。您可能會注意到 ChatGPT 可以很好地執行任務。事實上,它的性能接近于在大量手動標注數據(監督系統)上訓練過的模型,并且遠高于最先進的零樣本系統。您能否得出結論,ChatGPT 比任何其他競爭 LM 都要好得多?實際上,不,除非你可以 100% 確定評估數據集在 Internet 上不可用,因此在訓練期間沒有被 ChatGPT 看到。
關鍵是 ChatGPT 和其他 LM 作為服務是產品。因此,他們不需要遵循科學家用于實證實驗的嚴格評估協議。這些協議確保可以根據經驗確定假設,例如在相同的實驗條件下,系統 A 的性能優于 B。在大型 LM 的情況下,這些模型有可能在其預訓練或指令微調期間看到了標準評估數據集。在不排除這種可能性的情況下,我們不能斷定它們優于其他系統。
污染和記憶
有足夠的證據表明 LLM 存在評估問題。在發布 GPT-4 后的第一天,Horace He(推特上的@cHHillee)展示了該模型如何解決最簡單的代碼競賽問題,直到 2021 年,即訓練截止日期。相反,對于該日期之后的任何問題,都沒有得到正確解決。正如 Horace He 指出的那樣,“這強烈表明存在污染”。

簡而言之,當模型在驗證或測試示例上進行訓練(或在訓練示例上進行評估)時,我們說模型被污染了。一個相關的概念是記憶。當模型能夠在一定程度上生成數據集實例時,我們說模型已經記住了數據集。雖然記憶可能存在問題,尤其是對于個人、私人或許可數據,但不查看訓練數據更容易識別,即隱藏訓練信息時。相比之下,污染使得無法得出可靠的結論,并且除非您可以訪問數據,否則沒有簡單的方法來識別問題。那么,我們可以做些什么來確保 ChatGPT 不會在我們的測試中作弊嗎?我們不能,因為這需要訪問 ChatGPT 在訓練期間使用的全套文檔。但是我們可以從中得到一些線索,如下。
檢測 LM 是否已經看到任何特定數據集的一種簡單方法是要求生成數據集本身。我們將利用 LM 的記憶功能來檢測污染情況。例如,對于一個非常流行的命名實體識別 (NER) 數據集 CoNLL-03,我們要求 ChatGPT 生成數據集訓練拆分的第一個實例,如下所示:
[EU] rejects [German] call to boycott [British] lamb. [Peter Blackburn]. [BRUSSELS] 1996-08-22.
如下圖 1 所示,該模型完美地生成了文本和標簽,即 EU 是一個組織,德國人和英國人是雜項,Peter Blackburn 是一個人,而 BRUSSELS 是一個位置。事實上,該模型能夠生成驗證甚至測試拆分,包括標注錯誤,例如中國被標記為一個人。在谷歌上快速搜索顯示,至少有 3 篇論文(其中一篇實際上被頂級科學會議 ACL 2023 接受)確實將 ChatGPT 或 Codex(另一個封閉的 LM)評估為零樣本或少樣本 NER 系統 [1,2,3]。順便說一句,ChatGPT 在 CoNLL03 上的性能從第一篇論文(2 月 20 日)到第二篇論文(5 月 23 日)提高了近 9 個 F1 點,原因不明,但這是本文之外的另一個故事。
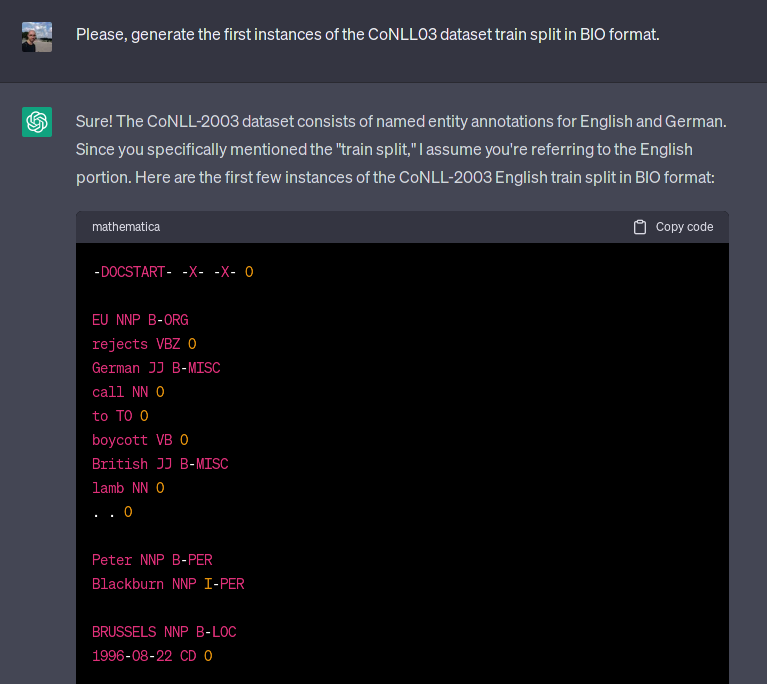
圖 1:ChatGPT 生成 CoNLL03 數據集的示例。生成的示例正是第一個訓練示例。
這如何擴展到其他 NLP 數據集?為了研究這種現象,我們將用于 CoNLL03 的相同協議應用于各種 NLP 數據集。我們使用以下提示進行此實驗:
“Please, generate the first instances of the {dataset_name} dataset {split} split in {format} format.”
通過將此提示應用于各種 NLP 任務,我們發現 ChatGPT 能夠為其他流行的數據集(如 SQuAD 2.0 和 MNLI)生成準確的示例。在其他一些情況下,ChatGPT 生成了不存在的示例(幻覺內容),但它在數據集中生成了原始屬性,如格式或標識符。即使恢復屬性而非確切示例的能力顯示出較低程度的記憶,它確實表明模型在訓練期間看到了數據集。參見圖 2。
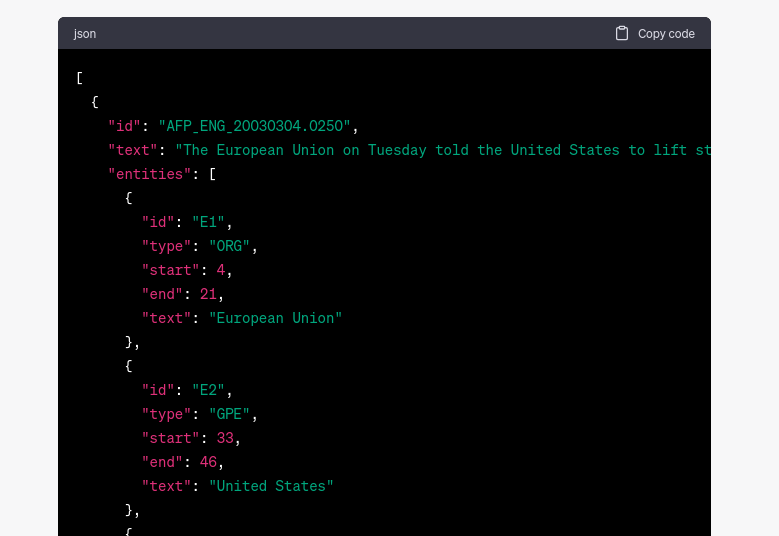
圖 2:ChatGPT 生成 ACE05 數據集的示例。雖然格式有效并生成合理的 doc_id,但數據集中不存在該示例。
在下表中,我們總結了作者熟悉的一些流行數據集的實驗結果。如果模型能夠生成數據集(文本和標簽)的示例,我們就說它被污染了。如果模型能夠生成特征屬性,例如數據格式、ID 或其他表征數據集的相關信息,則該模型是可疑的。如果模型無法生成反映在原始數據集上的任何內容,我們認為該模型是干凈的。如果數據集的特定拆分不公開可用,我們使用標簽 n/a。
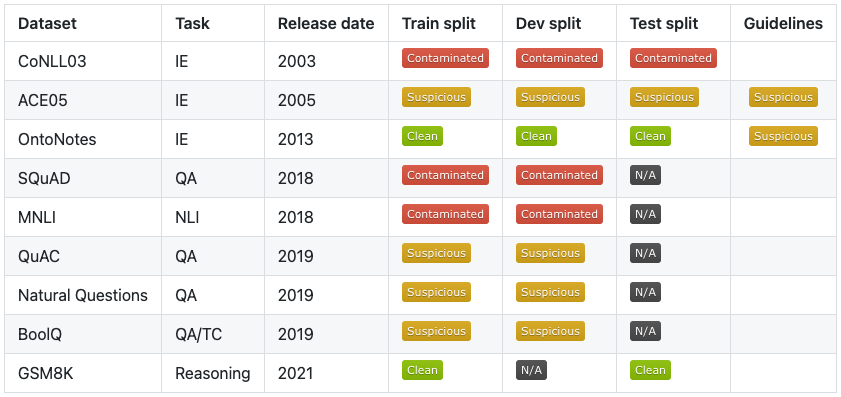
該表中的結果表明,我們分析的許多學術基準被作為訓練數據提供給 ChatGPT。雖然我們目前提供的數據集列表并不詳盡,但我們沒有理由相信其他公開可用的數據集被故意排除在 ChatGPT 的訓練語料庫之外。您可以在 LM 污染指數[6]上找到完整的實驗表。
我們在本博客中展示的所有實驗都是在 ChatGPT 之上進行的,ChatGPT 是一個黑盒 LLM,其架構或訓練數據信息尚未發布。值得注意的是,雖然我們專注于黑盒 LLM,但我們并未考慮使用公開可用的 LLM 時要解決的數據集污染問題。我們鼓勵研究人員發布用作訓練數據的文件,妥善記錄并完全可訪問,以便外部審計能夠確保它們沒有被污染。在這方面,BigScience 研討會下發布的 ROOTS 搜索工具 [4] 等工具是一個很好的例子,說明如何公開訓練數據,并允許研究人員對用于訓練 Bloom LLM 的 ROOTS 語料庫進行查詢模型[5]。
呼吁采取行動
在評估 LLM 的性能時,LLM 的污染是一個重要問題。作為一個社區,解決這個問題并制定有效的解決方案對我們來說至關重要。例如,對 ROOTS 搜索工具的快速搜索使我們能夠驗證 ROOTS 語料庫中只存在 CoNLL03 的第一句及其注釋。在這篇博客中,我們展示了關于 ChatGPT 對各種流行數據集(包括它們的測試集)的記憶的一些初步發現。訓練和驗證分裂的污染會損害模型對零/少樣本實驗的適用性。更重要的是,測試集中存在污染會使每個評估都無效。我們的研究提出的一項建議是停止使用未在科學論文中正確記錄訓練數據的 LLM,直到有證據表明它們沒有受到污染。同樣,程序委員會在接受包含此類實驗的論文時應謹慎行事。
我們正在積極努力擴大所分析的數據集和模型的范圍。通過包含更廣泛的數據集和模型,我們希望定義關于哪些數據集/模型組合對評估無效的指南。除了擴展我們的分析之外,我們還對設計用于測量學術數據集污染的自動方法感興趣。
數據集和模型的數量令人生畏。因此,我們正在設想社區的努力。如果您對 NLP 研究充滿熱情并希望在 LLM 評估中為防止污染做出貢獻,請聯系我們并查看下面的 GitHub 存儲庫。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3501瀏覽量
50160 -
數據集
+關注
關注
4文章
1223瀏覽量
25330 -
ChatGPT
+關注
關注
29文章
1589瀏覽量
8898
原文標題:和ChatGPT相關的所有評估可能都不做數了!國外的一項重要發現
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

OpenAI免費開放ChatGPT搜索功能
所有級聯片子的RLDIN引腳是否都不用同RLDOUT 和RLDINV相連接?
ChatGPT新增實時搜索與高級語音功能
OpenAI發布滿血版ChatGPT Pro

ChatGPT:怎樣打造智能客服體驗的重要工具?





 工商網監
工商網監
評論