") HighLight:視覺重定位,同等精度下速度提升300倍
HighLight:視覺重定位,同等精度下速度提升300倍
論文題目:Accelerated Coordinate Encoding:Learning to Relocalize in Minutes using RGB and Poses
代碼主頁:https://github.com/nianticlabs/ace
這篇文章來自CVPR 2023(Highlight),作者來自鼎鼎大名的Niantic Labs,是一個很有名的VR游戲開發(fā)公司,做了增強現(xiàn)實游戲Ingress和位置發(fā)現(xiàn)應(yīng)用Field Trip和pokemon go手游。其引領(lǐng)著全球VR游戲的發(fā)展歷史。
1 介紹
本文是一篇基于學(xué)習(xí)的視覺定位算法,更具體的是通過網(wǎng)絡(luò)學(xué)習(xí)回歸圖像密集像素三維坐標(biāo),建立2D-3D對應(yīng)后放在魯棒姿態(tài)估計器(RANSAC PNP + 迭代優(yōu)化)中估計相機六自由度姿態(tài)。
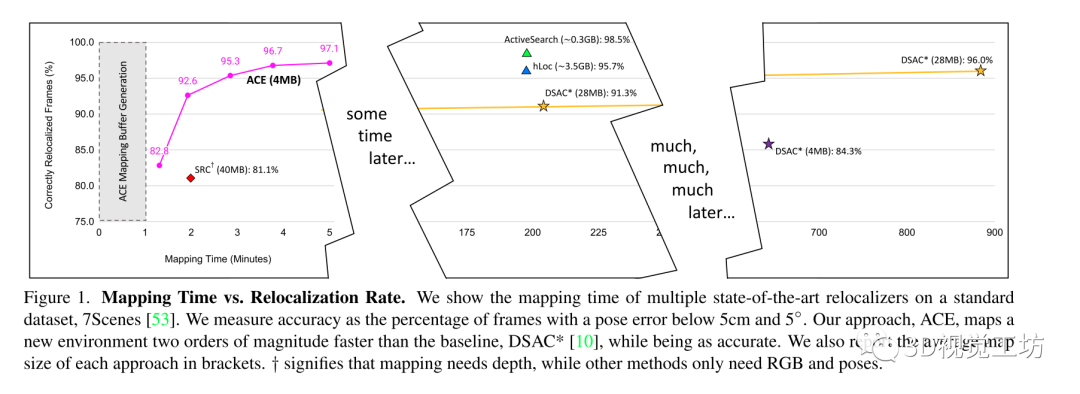
與以往基于學(xué)習(xí)的視覺定位算法的區(qū)別在于:以前的方法往往需要數(shù)小時或數(shù)天的訓(xùn)練,而且每個新場景都需要再次進行訓(xùn)練,使得該方法在大多數(shù)應(yīng)用程序中不太現(xiàn)實,所以在本文中作者團隊提出的方法改善了這一確定,使得可以在不到5分鐘的時間內(nèi)實現(xiàn)同樣的精度。
具體的,作者講定位網(wǎng)絡(luò)分為場景無關(guān)的特征backbone和場景特定的預(yù)測頭。而且預(yù)測頭不使用傳統(tǒng)的卷積網(wǎng)絡(luò),而是使用MLP,這可以在每次訓(xùn)練迭代中同時對數(shù)千個視點進行優(yōu)化,導(dǎo)致穩(wěn)定和極快的收斂。
此外使用一個魯棒姿態(tài)求解器的curriculum training替代有效但緩慢的端到端訓(xùn)練。
其方法在制圖方面比最先進的場景坐標(biāo)回歸快了300倍!
curriculum training:Curriculum training是一種訓(xùn)練方法,訓(xùn)練時向模型提供訓(xùn)練樣本的難度逐漸變大。在對新數(shù)據(jù)進行訓(xùn)練時,此方法需要對任務(wù)進行標(biāo)注,將任務(wù)分為簡單、中等或困難,然后對數(shù)據(jù)進行采樣。
把原來的卷積網(wǎng)絡(luò)預(yù)測頭換成MLP預(yù)測頭的動機是什么?作者認(rèn)為場景坐標(biāo)回歸可以看作從高維特征向量到場景空間三維點的映射,與卷積網(wǎng)絡(luò)相比,多層感知器(MLP)可以很好地表示這種映射,而且訓(xùn)練一個特定場景的MLP允許在每次訓(xùn)練迭代中一次優(yōu)化多個(通常是所有可用的)視圖,這會導(dǎo)致非常穩(wěn)定的梯度,使其能夠在非常積極的、高學(xué)習(xí)率的機制下操作。把這個和curriculum training結(jié)合在一起,讓網(wǎng)絡(luò)在后期訓(xùn)練階段burn in可靠的場景結(jié)構(gòu),使其模擬了端到端訓(xùn)練方案,以此會極大提升訓(xùn)練速度和效率。
2 主要貢獻(xiàn)
(1)加速坐標(biāo)編碼(ACE),一個場景坐標(biāo)回歸算法,可以在5分鐘內(nèi)映射一個新場景,以前最先進的場景坐標(biāo)回歸系統(tǒng)需要數(shù)小時才能達(dá)到相當(dāng)?shù)闹囟ㄎ痪取?/p>
(2)ACE將場景編碼成4MB的網(wǎng)絡(luò)權(quán)重,以前的場景坐標(biāo)回歸系統(tǒng)需要7倍的存儲空間
(3)只需要RGB圖像和對應(yīng)的pose進行訓(xùn)練,以前的依賴于像深度圖或場景網(wǎng)格這樣的先驗知識來進行。
3 方法
算法的目標(biāo)是估計給定的RGB圖像I的相機姿態(tài)h。定義的相機姿態(tài)為一個剛體變換,其將相機空間下的坐標(biāo)ei映射到場景空間的坐標(biāo)yi,即yi = h*ei。
其中C表示2D像素位置和3D場景坐標(biāo)之間的對應(yīng),g表示一個魯棒的姿態(tài)估計器。
設(shè)計的網(wǎng)絡(luò)學(xué)習(xí)預(yù)測給定2D圖像點對應(yīng)的3D場景點,即:
其中f表示學(xué)習(xí)到的權(quán)重參數(shù)化的網(wǎng)絡(luò),表示從圖像I的像素位置附近提取的圖像patch,所以f是一個patchs到場景坐標(biāo)的映射。
網(wǎng)絡(luò)在訓(xùn)練時在所有建圖圖像用他們的ground truth 作為監(jiān)督進行訓(xùn)練:
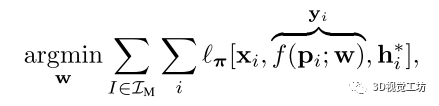
3.1 通過解關(guān)聯(lián)梯度進行高效訓(xùn)練
作者認(rèn)為以往的方法在每次訓(xùn)練迭代中優(yōu)化了成千上萬個patch的預(yù)測,但它們都來自同一幅圖像,因此它們的損失和梯度將是高度相關(guān)的。所以這篇文章的關(guān)鍵思想是在整個訓(xùn)練集上隨機化patches,并從許多不同的視圖中構(gòu)造batch,這種方法可以解關(guān)聯(lián)batch中的梯度,從而得到穩(wěn)定的訓(xùn)練,而且對高學(xué)習(xí)率具有魯棒性,并最終實現(xiàn)快速收斂。
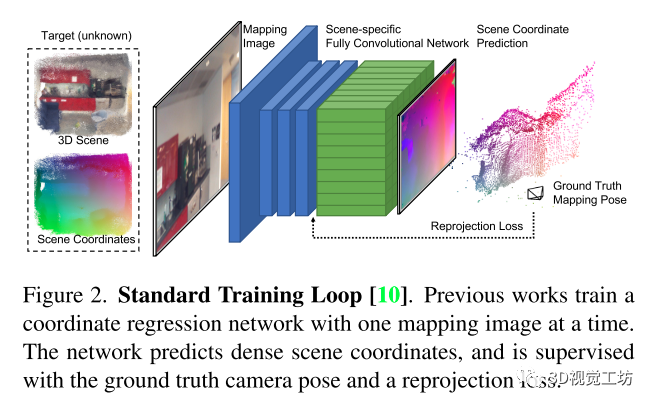
以往的方法的網(wǎng)絡(luò)如下圖所示,一次一副圖像,切圖像特征編碼器和預(yù)測頭解碼器都是CNN
作者將網(wǎng)絡(luò)拆分為卷積主干和多層感知器(MLP)頭,如下圖所示:
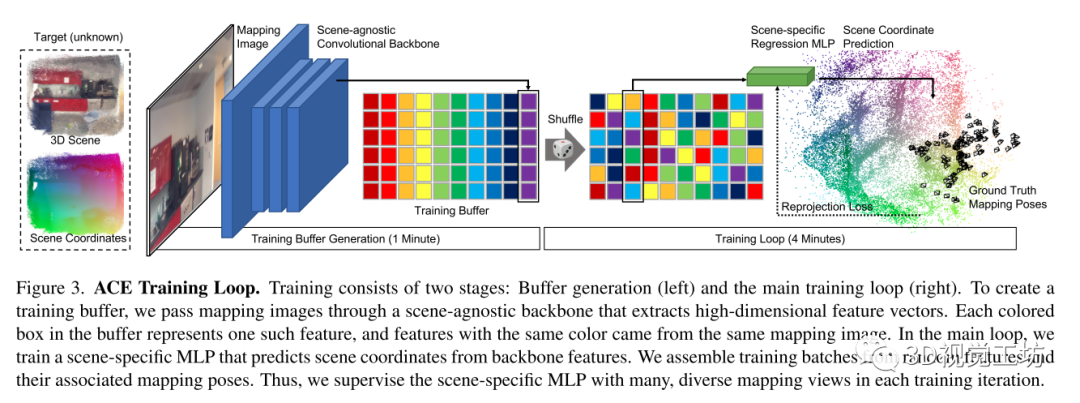
所以網(wǎng)絡(luò)拆分成兩部分:
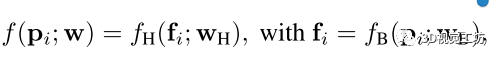
其中是用來預(yù)測表示圖像特征的高維向量,是用來預(yù)測場景坐標(biāo)的回歸頭
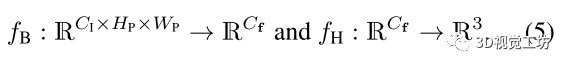
作者認(rèn)為可以用場景無關(guān)的卷積網(wǎng)絡(luò)實現(xiàn)一個通用的特征提取器,可以使用一個MLP而不是另一個卷積網(wǎng)絡(luò)來實現(xiàn)。這樣做因為在預(yù)測patch對應(yīng)的場景坐標(biāo)時是不需要空間上下文的,也就是說,與backbone不同,不需要訪問鄰近的像素來進行計算,因此可以用所有圖像中的隨機樣本構(gòu)建的訓(xùn)練batch,具體就是通過在所有圖像上運行預(yù)訓(xùn)練的backbone來構(gòu)建一個固定大小的訓(xùn)練緩沖區(qū),這個緩沖區(qū)包含數(shù)以百萬計的特征及其相關(guān)像素位置、相機內(nèi)參和ground truth ,在訓(xùn)練的第一分鐘就產(chǎn)生了這個緩沖。然后開始在緩沖區(qū)上迭代主訓(xùn)練循環(huán),即在每個epoch的開始,shuffle緩沖區(qū)以混合所有圖像數(shù)據(jù)的特征,在每個訓(xùn)練步驟中,構(gòu)建數(shù)千個特征batch,這可能同時計算數(shù)千個視圖的參數(shù)更新,這樣不僅梯度計算對于MLP回歸頭非常高效,而且梯度也是不相關(guān)的,這允許使用高學(xué)習(xí)速度來快速收斂。
3.2 課程(Curriculum)訓(xùn)練
課程(Curriculum)訓(xùn)練:比如像我們上課一樣,開始會講一些簡單的東西,然后再慢慢深入學(xué)習(xí)復(fù)雜的東西,類比網(wǎng)絡(luò),就是開始給寬松的閾值,讓網(wǎng)絡(luò)學(xué)習(xí)簡單的知識,后續(xù)隨著訓(xùn)練時間的進行,增大閾值,讓網(wǎng)絡(luò)學(xué)習(xí)復(fù)雜且魯棒的知識。
具體的,在整個訓(xùn)練過程中使用一個移動的內(nèi)閾值,開始時是寬松的,隨著訓(xùn)練的進行,限制會越來越多,使得網(wǎng)絡(luò)可以專注于已經(jīng)很好的預(yù)測,而忽略在姿態(tài)估計過程中RANSAC會過濾掉的不太精確的預(yù)測。
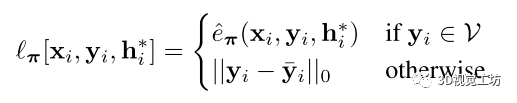
這種損失優(yōu)化了所有有效坐標(biāo)預(yù)測的魯棒重投影誤差,有效的預(yù)測指在圖像平面前方10cm到1000m之間,且重投影誤差低于1000px。
再使用tanh夾持重投影誤差:
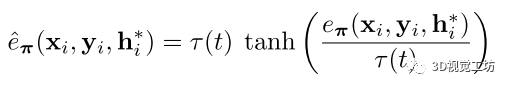
根據(jù)在訓(xùn)練過程中變化的閾值τ動態(tài)地重新縮放tanh:
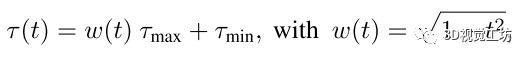
其中t∈(0,1)表示相對訓(xùn)練進度。這個課程訓(xùn)練實現(xiàn)了一個循環(huán)的τ閾值時間表,τ閾值在訓(xùn)練開始時保持在附近,在訓(xùn)練結(jié)束時趨于。
3.3 Backbone訓(xùn)練
backbone可以使用任何密集的特征描述網(wǎng)絡(luò)。作者提出了一種簡單的方法來訓(xùn)練一個適合場景坐標(biāo)回歸的特征描述網(wǎng)絡(luò)。為了訓(xùn)練backbone,采用DSAC*的圖像級訓(xùn)練,并將其與課程訓(xùn)練相結(jié)合。用N個回歸頭并行地訓(xùn)練N個場景,而不是用一個回歸頭訓(xùn)練一個場景的backbone。這種瓶頸架構(gòu)使得backbone預(yù)測適用于廣泛場景的特性。在ScanNet的100個場景上訓(xùn)練1周,得到11MB的權(quán)重,可用于在任何新場景上提取密集的描述符。
4 實驗
主要在兩個室內(nèi)數(shù)據(jù)集7Scenes和12Scenes和一個室外數(shù)據(jù)集Cambridge上進行訓(xùn)練測試:
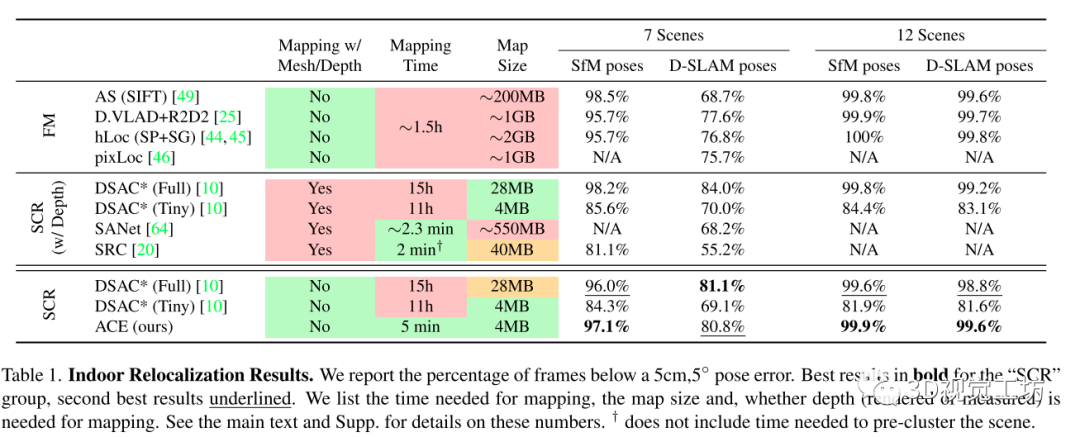
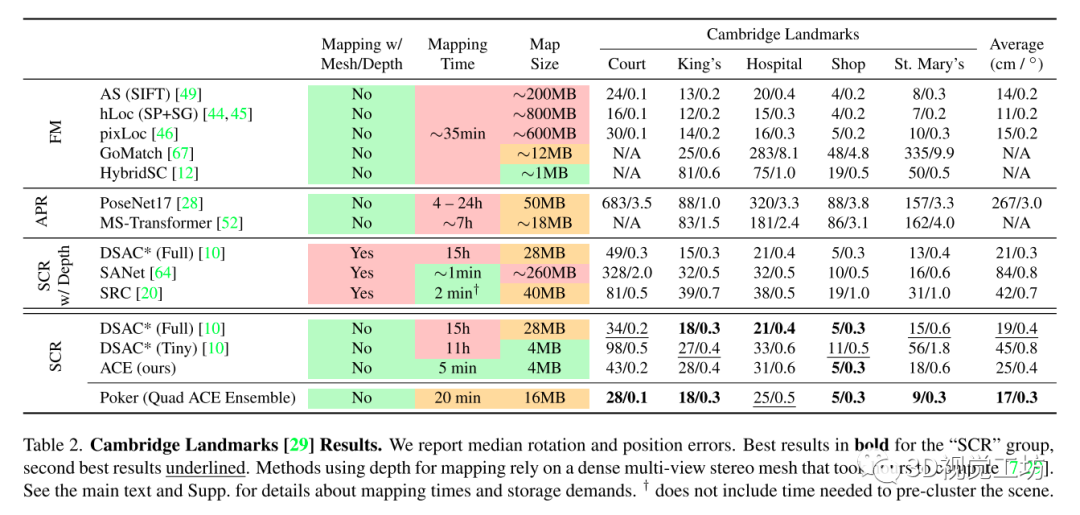
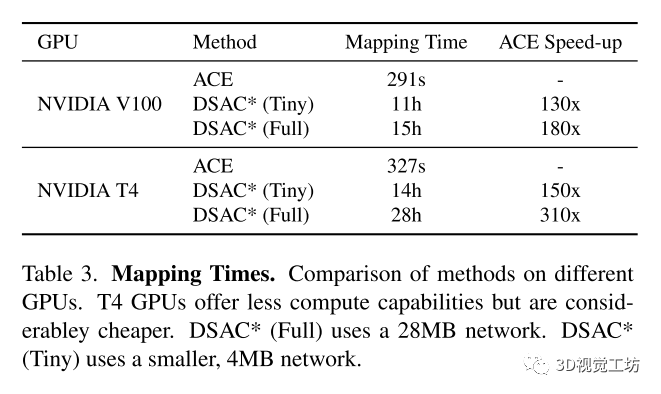
和DSAC*比較了在建圖訓(xùn)練上的時間損耗:
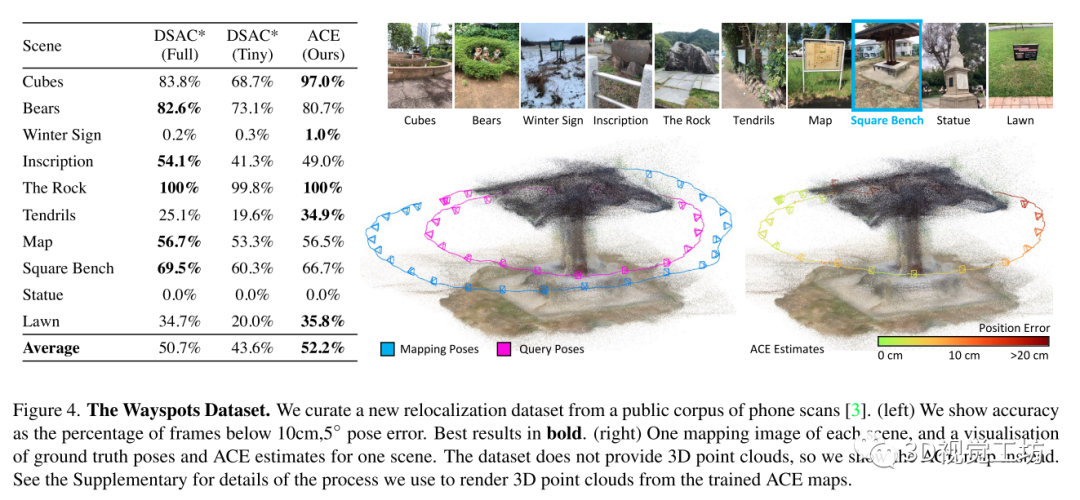
以及在無地圖定位數(shù)據(jù)集(自己構(gòu)建的 WaySpots)上的定位結(jié)果:

5 總結(jié)
這是一個能夠在5分鐘內(nèi)訓(xùn)練新環(huán)境的重定位算法。
與之前的場景坐標(biāo)回歸方法相比,將建圖的成本和存儲消耗降低了兩個數(shù)量級,使得算法具有實用性。
是一篇理論與工程完美結(jié)合的文章。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4702瀏覽量
94976 -
精度
+關(guān)注
關(guān)注
0文章
265瀏覽量
20393 -
卷積網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
43瀏覽量
2464
原文標(biāo)題:CVPR 2023 | HighLight:視覺重定位,同等精度下速度提升300倍
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
低成本高精度定位方案是未來市場趨勢,基于uwb高精度定位的案例分析
直線電機定位精度和重復(fù)定位精度
視覺定位方案求助,謝
深圳CCD視覺檢測定位系統(tǒng)有什么特點?
四元數(shù)數(shù)控:深圳機器視覺引導(dǎo)定位是什么?
CCD視覺定位系統(tǒng)在紫外激光打標(biāo)機上的應(yīng)用
高精度定位技術(shù)需求日益凸顯,和SKYLAB了解一下高精度定位方案
iOS 12正式版即將推出,高負(fù)載下app啟動速度最高提升至2倍
蘋果正式宣布了iOS 13系統(tǒng)解鎖速度提升30%應(yīng)用程序啟動速度提升一倍
復(fù)雜環(huán)境下的自動駕駛高精度定位技術(shù)
教你們視覺SLAM如何去提高定位精度
華為DATS路面感知響應(yīng)速度提升100倍

鐵路轉(zhuǎn)轍機視覺高精度定位抓取,大幅提升了產(chǎn)線自動化、柔性化水平
CVPR 2023:視覺重定位,同等精度下速度提升300倍

激光焊接視覺定位引導(dǎo)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論