") 緩解AI推理算力焦慮,高帶寬GDDR6成殺手锏?
緩解AI推理算力焦慮,高帶寬GDDR6成殺手锏?

芯東西 5 月 22 日報道,生成式 AI 的日益火爆,正對數(shù)據(jù)中心內(nèi)存性能提出更加苛刻的要求。無論是云端 AI 訓練還是向網(wǎng)絡邊緣轉(zhuǎn)移的 AI 推理,都需要高帶寬、低時延的內(nèi)存。邁向高性能 GDDR6 內(nèi)存接口已是大勢所趨。
近日,推出業(yè)界領先 24Gb/s GDDR6 PHY 的美國半導體 IP 和芯片供應商 Rambus,其兩位高管與芯東西等媒體進行線上交流,分享了 Rambus 在 GDDR6 領域的技術(shù)創(chuàng)新及行業(yè)發(fā)展趨勢。
"ChatGPT 等 AIGC 應用與我們公司的產(chǎn)品組合是非常契合的。"Rambus 大中華區(qū)總經(jīng)理蘇雷說,Rambus China 立足于中國市場,愿意更多、更緊密地支持中國公司在 ChatGPT 產(chǎn)業(yè)的發(fā)展,為他們保駕護航,"Rambus 面對中國客戶的需求,有最好的技術(shù)、最快的響應和最好的技術(shù)支持來服務中國市場。"
據(jù) Rambus IP 核產(chǎn)品營銷高級總監(jiān) Frank Ferro 分享,AI 推理應用對帶寬的需求通常在 200 到 500Gb/s 的范圍之間波動,每一個 GDDR6 設備的帶寬都可以達到 96Gb/s,因此通過將 4-5 個 GDDR6 設備組合在一起,就能輕松滿足 500Gb/s 及以下的帶寬需求。
他談道,如果用到一個 HBM3 設備,基本上會把這個帶寬需求的數(shù)字翻倍,能夠達到接近 800Gb/s 的帶寬,而這超過了 AI 推理本身所需要的 400 到 500Gb/s 帶寬,會使成本增加 3~4 倍。在這種條件下,HBM 并非一個經(jīng)濟高效的選擇,GDDR6 則是一個更好的替代。
他建議按需選擇 HBM 或是 GDDR6 內(nèi)存,對于對高帶寬和低延遲有很高要求的 AI 訓練場景,HBM 可能是更好的選擇;對于需要更大容量、更高帶寬的 AI 推理場景,GDDR6 會是更合適的選擇。
高性能內(nèi)存和互連方案,支持下一代數(shù)據(jù)中心發(fā)展
Rambus 大中華區(qū)總經(jīng)理蘇雷談道,Rambus 主要業(yè)務包含基礎專利授權(quán)、芯片 IP 授權(quán)和內(nèi)存接口芯片。其中芯片 IP 又主要分為接口 IP 和安全 IP。其技術(shù)和產(chǎn)品面向數(shù)據(jù)密集型市場,包括數(shù)據(jù)中心、5G、物聯(lián)網(wǎng) IoT、汽車等細分市場,后續(xù)還將推出 CXL 家族各產(chǎn)品組合芯片。
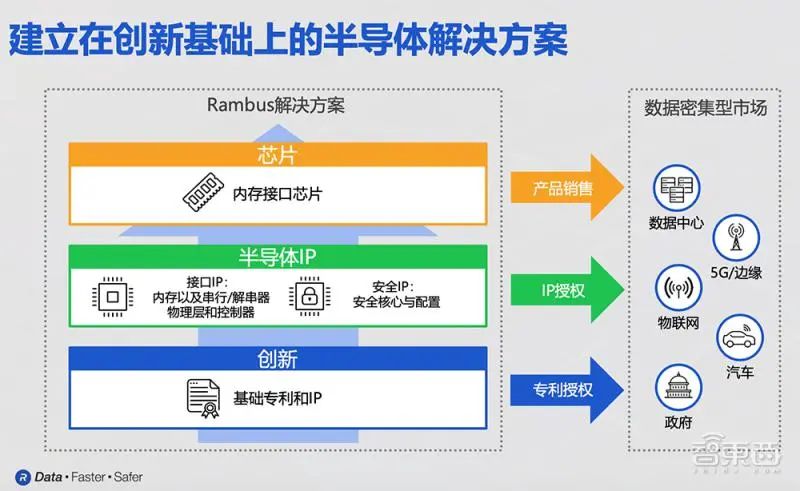
面向數(shù)據(jù)中心,Rambus 非常注重產(chǎn)品和方案的易用性,通過一站式的解決方案以及完善的服務機制,使產(chǎn)品方案變得更易在客戶端集成使用。Rambus 陸續(xù)推出了各內(nèi)存子系統(tǒng)、接口子系統(tǒng),提供業(yè)界領先、可靠的數(shù)據(jù)傳輸。其 GDDR6 接口子系統(tǒng)率先實現(xiàn)高達 24Gb/s 的內(nèi)存接口數(shù)據(jù)速率,并能為每個 GDDR6 內(nèi)存設備提供最高達到 96Gb/s 的帶寬。
Rambus 的內(nèi)存接口芯片產(chǎn)品不斷提高數(shù)據(jù)中心內(nèi)存模塊的速度和容量,同時它擁有非常豐富而全面的安全 IP 產(chǎn)品線,對用于靜態(tài)數(shù)據(jù)以及動態(tài)數(shù)據(jù)安全保護都有著專門安全的產(chǎn)品方案。
總體來說,Rambus 通過領先的高性能內(nèi)存和互聯(lián)解決方案以及硬件級安全,支持下一代數(shù)據(jù)中心的發(fā)展。其產(chǎn)品應用領域聚焦于服務器主內(nèi)存、人工智能和網(wǎng)絡加速器、智能網(wǎng)卡、網(wǎng)絡存儲、網(wǎng)絡交換機以及內(nèi)存擴展和池化等。

內(nèi)存是未來 AI 性能的關(guān)鍵
Rambus IP 核產(chǎn)品營銷高級總監(jiān) Frank Ferro 著重分享了迄今市場推動高性能需求的主要驅(qū)動力,以及未來如何更好滿足 AI 性能需求。
數(shù)據(jù)需求依舊呈現(xiàn)上漲趨勢。ChatGPT 等 AI 相關(guān)應用快速發(fā)展,對內(nèi)存帶寬需求旺盛,因此市面上越來越多公司開始專注于開發(fā)自己個性化、定制化的處理器產(chǎn)品,以更好地滿足神經(jīng)網(wǎng)絡以及專屬應用的需求。
Frank Ferro 強調(diào)說,盡管算力增長非常顯著,但帶寬的進步與之并不匹配,即現(xiàn)有高算力的基礎之上,很多的 GPU 資源其實并沒有得到充分的占用和利用,這造成了現(xiàn)在的困境。
AI 訓練環(huán)節(jié)需要錄入大量數(shù)據(jù)進行分析,需要消耗大量算力。AI 推理環(huán)節(jié)對算力的需求會大幅下降,但對成本和功耗更加敏感。Frank Ferro 談道,一個重要趨勢是 AI 推理越來越多地向邊緣設備上進行集成和轉(zhuǎn)移。在這個變化過程中,擁有更高帶寬、更低時延特性的 GDDR6 方案,能夠幫助邊緣端更好地處理數(shù)據(jù)。
對帶寬需求進一步的增加,驅(qū)動了像 Rambus 這樣的公司不斷地在去打造更加新一代的產(chǎn)品,不斷地提高內(nèi)存帶寬以及接口帶寬的相關(guān)速度。
GDDR6 能夠提供 AI 推理所需的內(nèi)存性能
Rambus 有著豐富的接口 IP 產(chǎn)品組合,同時也提供像 DDR、LPDDR 以及 HBM 等產(chǎn)品,并非常關(guān)注 SerDes 產(chǎn)品的開發(fā),主要聚焦于 PCIe 和 CXL 接口,會開發(fā)配套的 PHY 及控制器。Rambus 的 HBM 產(chǎn)品擁有領先的市占率,同時其 HBM3 產(chǎn)品已經(jīng)能夠提供高達 8.4Gbps/s 的數(shù)據(jù)傳輸速率。
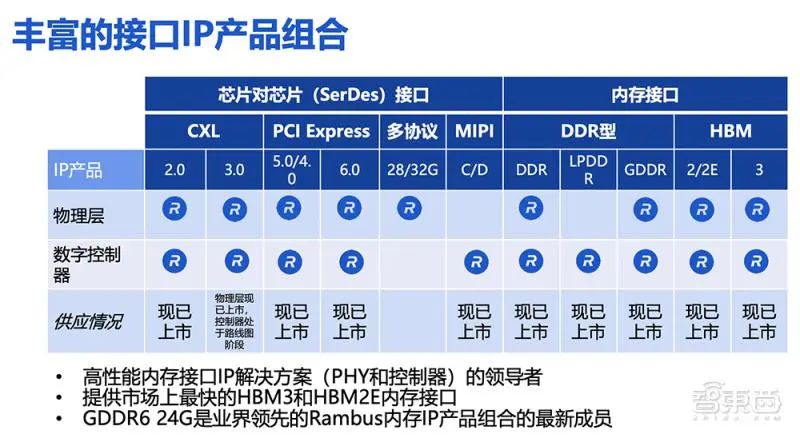
其全新 GDDR6 PHY 及控制器的配套產(chǎn)品已達到業(yè)界領先的 24Gb/s 的數(shù)據(jù)傳輸速率,可為 AI 推理等應用場景帶來巨大性能優(yōu)勢和收益。此外,該產(chǎn)品在功耗管理方面優(yōu)勢明顯,并實現(xiàn)了 PHY 以及控制器的完整集成,即客戶收到產(chǎn)品后,可以直接對其子系統(tǒng)進行定制化應用。
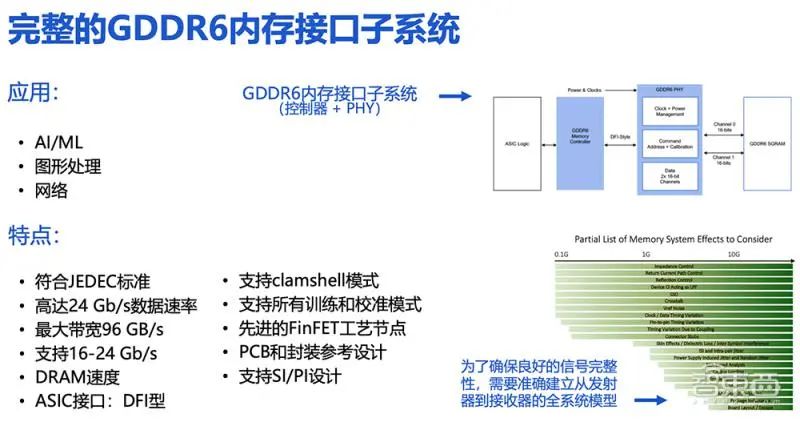
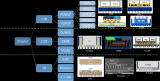
如圖是 GDDR6 內(nèi)存接口系統(tǒng),Rambus 提供的是中間標藍的兩個重要環(huán)節(jié),也就是完整的子系統(tǒng)。Rambus 會根據(jù)客戶具體應用場景和實際的訴求對子系統(tǒng)來進行優(yōu)化,并將其作為完整的子系統(tǒng)來交付給客戶。
clamshell 模式指每個信道可支持兩個 GDDR6 的設備。換句話說,在 clamshell 模式之下,整個容量是直接翻倍乘以 2 的。值得一提的是,GDDR6 現(xiàn)已支持先進的 FinFET 工藝節(jié)點環(huán)境。
此外,Rambus 也會針對 PCB 以及封裝提供相關(guān)的參考設計,同時內(nèi)部有信號完整度和邊緣完整性方面的專家,來幫助客戶完成整個設計工作。
市面上很多 GPU 加速器都已經(jīng)用到 GDDR6。由于在成本和性能之間達到不錯的平衡,GDDR6 成為在 AI 應用場景下比較合理的產(chǎn)品和選擇。而 Rambus 擁有領先的 SI/PI 專業(yè)知識,可以進行早期的協(xié)同設計和開發(fā),確保 GDDR6 產(chǎn)品的性能表現(xiàn),也能更好地去縮短產(chǎn)品的上市時間。
結(jié)語:在帶寬、成本、方案復雜性之間實現(xiàn)平衡
隨著 AI 應用趨于盛行,蘇雷談道,下游廠商首先關(guān)注高帶寬,并開始關(guān)注方案的成本和復雜性,"GDDR 技術(shù)是在帶寬、成本和方案復雜性的各因素之間提供了一個非常完美的折中技術(shù)方案。" 他預計到 2025 年或 2026 年市場上會出現(xiàn)使用 GDDR6 IP 的芯片。
進入全新的 GDDR6 時代,相關(guān)產(chǎn)品已開始采用 16 位的雙讀寫通道。雙讀寫通道加起來是 32 位的數(shù)據(jù)寬度,而 GDDR6 內(nèi)存有 8 個雙讀寫通道,總共可實現(xiàn) 256 位的數(shù)據(jù)傳輸寬度,所以能夠顯著提高數(shù)據(jù)傳輸?shù)乃俣群托剩到y(tǒng)層效率和功耗管理也能得到進一步的優(yōu)化。
除了適用于 AI 推理場景外,F(xiàn)rank Ferro 說,GDDR6 也會在圖形領域和一些網(wǎng)絡應用場景中起到重要作用,能夠大幅降低網(wǎng)絡邊緣設備對 DDR 數(shù)量的需求。
審核編輯 :李倩
-
芯片
+關(guān)注
關(guān)注
459文章
52374瀏覽量
438942 -
控制器
+關(guān)注
關(guān)注
114文章
17059瀏覽量
183636 -
AI
+關(guān)注
關(guān)注
88文章
34839瀏覽量
277364
原文標題:【媒體報道】緩解 AI 推理算力焦慮,高帶寬 GDDR6 成殺手锏?
文章出處:【微信號:Rambus 藍鉑世科技,微信公眾號:Rambus 藍鉑世科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI推理的存儲,看好SRAM?
瑞之辰傳感器:從“卡脖子”到“殺手锏”的技術(shù)突圍

算力革命:RoCE實測推理時延比InfiniBand低30%的底層邏輯
6TOPS算力NPU加持!RK3588如何重塑8K顯示的邊緣計算新邊界
RAKsmart服務器如何重塑AI高并發(fā)算力格局
DeepSeek推動AI算力需求:800G光模塊的關(guān)鍵作用
國產(chǎn)推理服務器如何選擇?深度解析選型指南與華頡科技實戰(zhàn)案例

使用NVIDIA推理平臺提高AI推理性能

沖刺海外高端市場 傳音控股也有殺手锏 ?

AI時代核心存力HBM(上)
基站和雷達知識介紹
OpenAI開啟推理算力新Scaling Law,AI PC和CPU的機會來了
AI網(wǎng)絡物理層底座: 大算力芯片先進封裝技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論