 AI推理的存儲,看好SRAM?
AI推理的存儲,看好SRAM?

電子發燒友網報道(文/黃晶晶)近幾年,生成式AI引領行業變革,AI訓練率先崛起,帶動高帶寬內存HBM一飛沖天。但我們知道AI推理的廣泛應用才能推動AI普惠大眾。在AI推理方面,業內巨頭、初創公司等都看到了其前景并提前布局。AI推理也使得存儲HBM不再是唯一熱門,更多存儲芯片與AI推理芯片結合,擁有了市場機會。
已經有不少AI推理芯片、存算一體芯片將SRAM替代DRAM,從而獲得更快的訪問速度、更低的刷新延遲等。
靜態隨機存取存儲器(Static Random-Access Memory,SRAM)是隨機存取存儲器的一種。這種存儲器只要保持通電,里面儲存的數據就可以恒常保持。相對之下,動態隨機存取存儲器(DRAM)里面所儲存的數據就需要周期性地更新。但當電力供應停止時,SRAM儲存的數據還是會消失,這與在斷電后還能儲存資料的ROM或閃存不同。
SRAM具有較高的性能,但SRAM的集成度較低,功耗較DRAM大,SRAM需要很大的面積。同樣面積的硅片可以做出更大容量的DRAM,因此SRAM顯得更貴。SRAM可作為置于CPU與主存間的高速緩存,不需要定期刷新,響應速度非常快,可用于CPU的一級緩沖、二級緩沖。
GroqLPU近存計算
在AI推理大潮下,Groq公司開發的語言處理單元(Language Processing Unit,即LPU),以其獨特的架構,帶來了極高的推理性能的表現。
Groq的芯片采用14nm制程,搭載了230MB SRAM以保證內存帶寬,片上內存帶寬達80TB/s。
SRAM 的訪問速度比 DRAM 快得多,這使得它在某些計算密集型應用中表現得非常出色。Groq LPU 芯片采用大容量 SRAM內存有助于提高機器學習和人工智能等計算密集型工作負載的效率。
Groq成立于 2016 年,總部位于美國加利福尼亞州山景城,是一家 AI 推理芯片廠商。該公司核心團隊來源于谷歌最初的張量處理單元(TPU)工程團隊。Groq 創始人兼CEO Jonathan Ross是谷歌TPU項目的核心研發人員。
2024年8月,Groq 在最新一輪融資中籌集了 6.4 億美元,由 BlackRock Inc. 基金領投,并得到了思科和三星投資部門的支持。
2024 年 12 月Groq在沙特阿拉伯達曼構建了中東地區最大的推理集群,該集群包括了 19000 個Groq LPU,并在 8 天內上線。
今年2月,Groq成功從沙特阿拉伯籌集 15 億美元融資,用于擴展其位于沙特阿拉伯的 AI 基礎設施。
AxeleraAIPU芯片:內存計算+RISC-V架構
Axelera公司介紹,內存計算是一種完全不同的數據處理方法,在這種方法中,存儲器設備的橫桿陣列可以用來存儲矩陣,并在沒有中間數據移動的情況下“就地”執行矩陣向量乘法。專有的數字內存計算(D-IMC)技術是實現高能效和卓越性能的關鍵。基于SRAM(靜態隨機訪問存儲器)和數字計算相結合,每個存儲單元有效地成為一個計算單元。這從根本上增加了每個計算機周期的操作數(每個存儲單元每個周期一次乘法和一次累加),而不受噪音或較低精度等問題的影響。
已經有不少AI推理芯片、存算一體芯片將SRAM替代DRAM,從而獲得更快的訪問速度、更低的刷新延遲等。
靜態隨機存取存儲器(Static Random-Access Memory,SRAM)是隨機存取存儲器的一種。這種存儲器只要保持通電,里面儲存的數據就可以恒常保持。相對之下,動態隨機存取存儲器(DRAM)里面所儲存的數據就需要周期性地更新。但當電力供應停止時,SRAM儲存的數據還是會消失,這與在斷電后還能儲存資料的ROM或閃存不同。
SRAM具有較高的性能,但SRAM的集成度較低,功耗較DRAM大,SRAM需要很大的面積。同樣面積的硅片可以做出更大容量的DRAM,因此SRAM顯得更貴。SRAM可作為置于CPU與主存間的高速緩存,不需要定期刷新,響應速度非常快,可用于CPU的一級緩沖、二級緩沖。
GroqLPU近存計算
在AI推理大潮下,Groq公司開發的語言處理單元(Language Processing Unit,即LPU),以其獨特的架構,帶來了極高的推理性能的表現。
Groq的芯片采用14nm制程,搭載了230MB SRAM以保證內存帶寬,片上內存帶寬達80TB/s。
SRAM 的訪問速度比 DRAM 快得多,這使得它在某些計算密集型應用中表現得非常出色。Groq LPU 芯片采用大容量 SRAM內存有助于提高機器學習和人工智能等計算密集型工作負載的效率。
Groq成立于 2016 年,總部位于美國加利福尼亞州山景城,是一家 AI 推理芯片廠商。該公司核心團隊來源于谷歌最初的張量處理單元(TPU)工程團隊。Groq 創始人兼CEO Jonathan Ross是谷歌TPU項目的核心研發人員。
2024年8月,Groq 在最新一輪融資中籌集了 6.4 億美元,由 BlackRock Inc. 基金領投,并得到了思科和三星投資部門的支持。
2024 年 12 月Groq在沙特阿拉伯達曼構建了中東地區最大的推理集群,該集群包括了 19000 個Groq LPU,并在 8 天內上線。
今年2月,Groq成功從沙特阿拉伯籌集 15 億美元融資,用于擴展其位于沙特阿拉伯的 AI 基礎設施。
AxeleraAIPU芯片:內存計算+RISC-V架構
Axelera公司介紹,內存計算是一種完全不同的數據處理方法,在這種方法中,存儲器設備的橫桿陣列可以用來存儲矩陣,并在沒有中間數據移動的情況下“就地”執行矩陣向量乘法。專有的數字內存計算(D-IMC)技術是實現高能效和卓越性能的關鍵。基于SRAM(靜態隨機訪問存儲器)和數字計算相結合,每個存儲單元有效地成為一個計算單元。這從根本上增加了每個計算機周期的操作數(每個存儲單元每個周期一次乘法和一次累加),而不受噪音或較低精度等問題的影響。
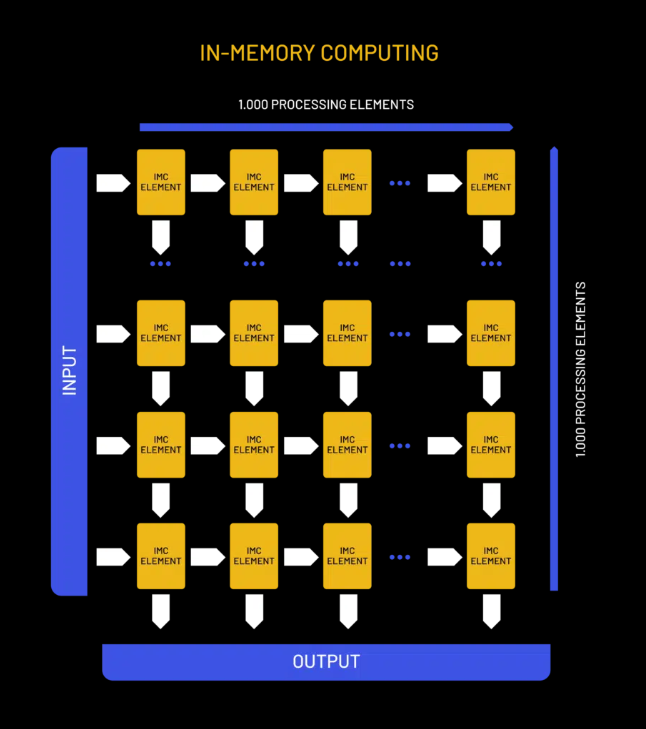
Axelera的AIPU芯片采用了創新的內存計算技術。與傳統的磁盤存儲相比,內存計算將數據存儲在主內存(RAM)中,從而加快了數據處理速度。這一技術使得Axelera的芯片在提供高計算性能的同時,能以更低的成本和能耗來進行邊緣AI計算。該芯片還采用了開源的RISC-V指令集架構(ISA)。RISC-V作為一種低成本、高效且靈活的ISA,允許根據特定的應用需求進行定制。它為Axelera提供了極大的設計自由度和創新空間。
去年,Axelera獲得了來自三星電子風險投資部門三星Catalyst的大力支持,成功籌集了6800萬美元,至此Axelera的總融資額已達到1.2億美元。新投資者包括三星基金、歐洲創新委員會基金、創新產業戰略伙伴關系基金和Invest-NL。
EnCharge AI:模擬存內計算
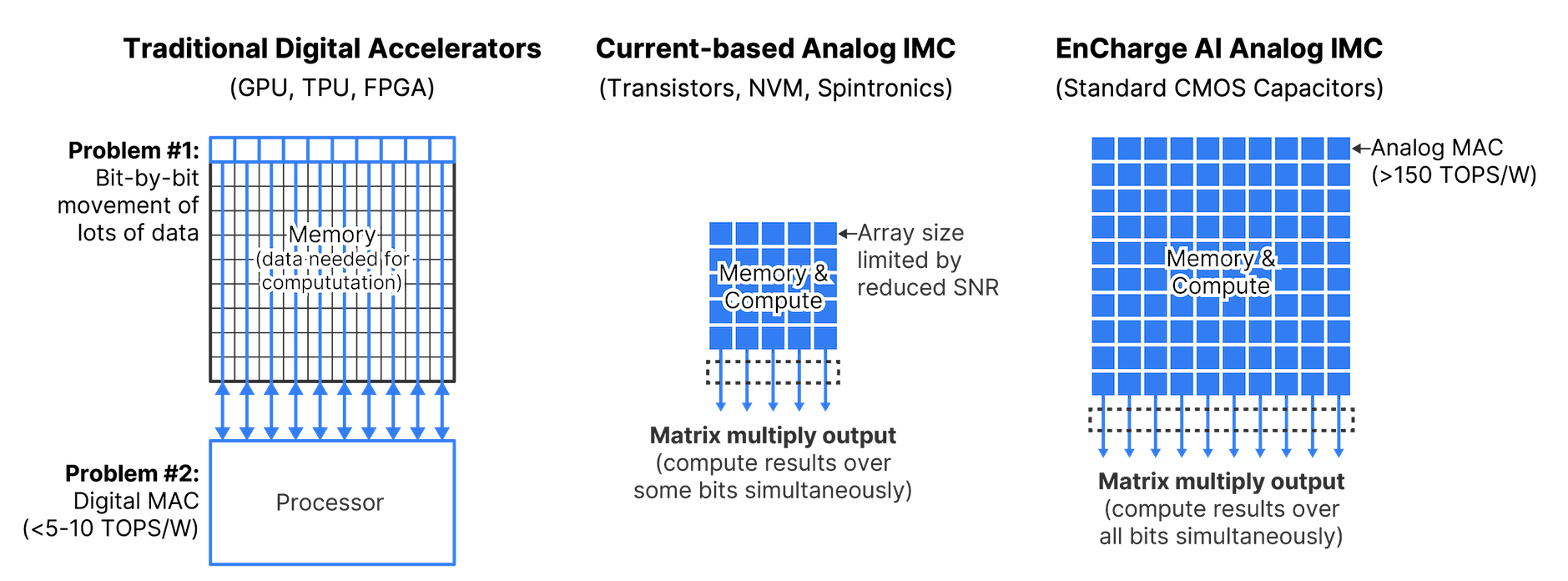
AI 芯片初創公司 EnCharge AI表示,已開發出一種用于 AI 推理的新型內存計算架構,EnCharge AI的核心技術是基于模擬存內計算的AI芯片。這種創新的芯片設計采用"基于電荷的存儲器",通過讀取存儲平面上的電流而非單個比特單元來處理數據,使用更精確的電容器替代了傳統的半導體。
與GPU等數字加速器相比,每瓦性能提高了 20 倍。EnCharge AI的推理芯片僅需一瓦的功率就能以8位元精度提供150 TOPS的AI運算。
EnCharge AI源自普林斯頓大學,該公司創始人兼CEO Naveen Verma的相關研究項目涉及到內存計算。用于機器學習計算的內存計算采用在RAM中運行計算的方式,以減少存儲設備帶來的延遲。
今年初,EnCharge AI完成超額認購的1億美元b輪融資。此輪超額認購融資使EnCharge AI的總融資額超過1.44億美元,將推動其首款以客戶端運算為主的AI加速器產品,并在2025年實現商業化。
d-Matrix:數字內存計算DIMC架構
d-Matrix采用數字內存計算(DIMC)的引擎架構將計算移動到RAM(內存)附近,該數字存算一體技術將存儲器與計算單元中的乘法累加器(MAC)進行了合并,獲得了更大的計算帶寬和效率,降低延遲,減少能耗。首批采用d-Matrix的DIMC架構的產品Jayhawk II處理器,包含約165億晶體管的Chiplet。每個Jayhawk II Chiplet都包含一個RISC-V核心對Chiplet進行管理,每個核心有八個并行操作的DIMC單元。
去年底d-Matrix首款人工智能芯片Corsair開始出貨。每張Corsair卡由多個DIMC計算核心驅動,具有2400 TFLOP的8位峰值計算能力、2GBSRAM和高達256GB的LPDDR6。
d-Matrix公司是一家位于加利福尼亞州圣克拉拉市的初創公司,專注于人工智能芯片的研發。該公司的主要產品是針對數據中心和云計算中的AI服務器設計的芯片,旨在優化人工智能推理工作負載。d-Matrix公司已經獲得了多家知名投資機構的支持,包括微軟風險投資部門、新加坡投資公司淡馬錫、Palo Alto Networks等,D-Matrix曾在2022年4月獲得了4400萬美元融資,由 M12 和韓國半導體制造商 SK 海力士公司領投。累計融資超過1.6億美元。
雖然說SRAM的擁有成本比較高,但其在AI推理運算中能夠減少數據來回傳輸的延遲,避免拖慢整個AI處理的速度。在AI推理的浪潮下,SRAM將發揮更大的作用。還有哪些存儲芯片因AI推理而贏得機會,我們將持續關注報道。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
存儲
+關注
關注
13文章
4533瀏覽量
87488 -
sram
+關注
關注
6文章
786瀏覽量
115993 -
AI
+關注
關注
88文章
35182瀏覽量
280204
發布評論請先 登錄
相關推薦
熱點推薦
AI驅動新型存儲器技術,國內新興存儲企業進階
為了加速AI的訓練與推理應用。但另一方面,新型存儲也在AI時代扮演越來越重要的角色,最近國內新興存儲企業也將目光投向于此,并推出新產品等,以
發表于 10-16 08:10
?1479次閱讀

信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
DeepSeek-R1:強大的AI推理引擎底座DeepSeek是由杭州深度求索人工智能基礎技術研究有限公司開發的新一代AI大模型。其核心優勢在于強大的推理引擎能力,融合了自然語言處理(
發表于 07-16 15:29
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命 Google 發布了 Ironwood,這是其第七代張量處理單元 (TPU),專為推理而設計。這款功能強大的 AI

英偉達GTC25亮點:NVIDIA Blackwell Ultra 開啟 AI 推理新時代
英偉達GTC25亮點:NVIDIA Blackwell Ultra 開啟 AI 推理新時代
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
DeepSeek-R1 上的吞吐量提高了 30 倍 NVIDIA 發布了開源推理軟件 NVIDIA Dynamo,旨在以高效率、低成本加速并擴展 AI 工廠中的 AI 推理模型。 作
NVIDIA 與行業領先的存儲企業共同推出面向 AI 時代的新型企業基礎設施
存儲提供商構建搭載 AI 查詢智能體的基礎設施,利用 NVIDIA 計算、網絡和軟件,針對復雜查詢進行推理并快速生成準確響應 ? 美國加利福尼亞州圣何塞 —— GTC —— 太平洋時間 2025 年
發表于 03-19 10:11
?245次閱讀

AI變革正在推動終端側推理創新
尖端AI推理模型DeepSeek R1一經問世,便在整個科技行業引起波瀾。因其性能能夠媲美甚至超越先進的同類模型,顛覆了關于AI發展的傳統認知。
不再是HBM,AI推理流行,HBF存儲的機會來了?
NAND閃存和高帶寬存儲器(HBM)的特性,能更好地滿足AI推理的需求。 ? HBF的堆疊設計類似于HBM,通過硅通孔(TSVs)將多個高性能閃存核心芯片堆疊,連接到可并行訪問閃存子陣列的邏輯芯片上。也就是基于 SanDisk


生成式AI推理技術、市場與未來
OpenAI o1、QwQ-32B-Preview、DeepSeek R1-Lite-Preview的相繼發布,預示著生成式AI研究正從預訓練轉向推理(Inference),以提升AI邏輯推理

AI推理CPU當道,Arm驅動高效引擎
AI的訓練和推理共同鑄就了其無與倫比的處理能力。在AI訓練方面,GPU因其出色的并行計算能力贏得了業界的青睞,成為了當前AI大模型最熱門的芯片;而在

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案
麗蟾科技通過 Leaper 資源管理平臺集成 NVIDIA AI Enterprise,為企業和科研機構提供了一套高效、靈活的 AI 訓練與推理加速解決方案。無論是在復雜的 AI 開發

李開復:中國擅長打造經濟實惠的AI推理引擎
10月22日上午,零一萬物公司的創始人兼首席執行官李開復在與外媒的交流中透露,其公司旗下的Yi-Lightning(閃電模型)在推理成本上已實現了顯著優勢,比OpenAI的GPT-4o模型低了31倍。他強調,中國擅長打造經濟實惠的AI推
AMD助力HyperAccel開發全新AI推理服務器
HyperAccel 是一家成立于 2023 年 1 月的韓國初創企業,致力于開發 AI 推理專用型半導體器件和硬件,最大限度提升推理工作負載的存儲器帶寬使用,并通過將此解決方案應用于






 工商網監
工商網監
評論