 PyTorch教程-10.7. 用于機器翻譯的編碼器-解碼器 Seq2Seq
PyTorch教程-10.7. 用于機器翻譯的編碼器-解碼器 Seq2Seq
在所謂的 seq2seq 問題中,如機器翻譯(如 第 10.5 節所述),其中輸入和輸出均由可變長度的未對齊序列組成,我們通常依賴編碼器-解碼器架構(第10.6 節)。在本節中,我們將演示編碼器-解碼器架構在機器翻譯任務中的應用,其中編碼器和解碼器均作為 RNN 實現( Cho等人,2014 年,Sutskever等人,2014 年)。
在這里,編碼器 RNN 將可變長度序列作為輸入并將其轉換為固定形狀的隱藏狀態。稍后,在 第 11 節中,我們將介紹注意力機制,它允許我們訪問編碼輸入,而無需將整個輸入壓縮為單個固定長度的表示形式。
然后,為了生成輸出序列,一次一個標記,由一個單獨的 RNN 組成的解碼器模型將在給定輸入序列和輸出中的前一個標記的情況下預測每個連續的目標標記。在訓練期間,解碼器通常會以官方“ground-truth”標簽中的前面標記為條件。然而,在測試時,我們希望根據已經預測的標記來調節解碼器的每個輸出。請注意,如果我們忽略編碼器,則 seq2seq 架構中的解碼器的行為就像普通語言模型一樣。圖 10.7.1說明了如何在機器翻譯中使用兩個 RNN 進行序列到序列學習。

圖 10.7.1使用 RNN 編碼器和 RNN 解碼器進行序列到序列學習。
在圖 10.7.1中,特殊的“”標記標志著序列的結束。一旦生成此令牌,我們的模型就可以停止進行預測。在 RNN 解碼器的初始時間步,有兩個特殊的設計決策需要注意:首先,我們以特殊的序列開始“”標記開始每個輸入。其次,我們可以在每個解碼時間步將編碼器的最終隱藏狀態輸入解碼器(Cho等人,2014 年)。在其他一些設計中,例如Sutskever等人。( 2014 ),RNN 編碼器的最終隱藏狀態僅在第一個解碼步驟用于啟動解碼器的隱藏狀態。
import collections import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l
import collections import math from mxnet import autograd, gluon, init, np, npx from mxnet.gluon import nn, rnn from d2l import mxnet as d2l npx.set_np()
import collections import math from functools import partial import jax import optax from flax import linen as nn from jax import numpy as jnp from d2l import jax as d2l
import collections import math import tensorflow as tf from d2l import tensorflow as d2l
10.7.1。教師強迫
雖然在輸入序列上運行編碼器相對簡單,但如何處理解碼器的輸入和輸出則需要更加小心。最常見的方法有時稱為 教師強制。在這里,原始目標序列(標記標簽)作為輸入被送入解碼器。更具體地說,特殊的序列開始標記和原始目標序列(不包括最終標記)被連接起來作為解碼器的輸入,而解碼器輸出(用于訓練的標簽)是原始目標序列,移動了一個標記: “”,“Ils”,“regardent”,“。” →“Ils”、“regardent”、“.”、“”(圖 10.7.1)。
我們在10.5.3 節中的實施為教師強制準備了訓練數據,其中用于自監督學習的轉移標記類似于9.3 節中的語言模型訓練。另一種方法是將來自前一個時間步的預測標記作為當前輸入提供給解碼器。
下面,我們 將更詳細地解釋圖 10.7.1中描繪的設計。我們將在第 10.5 節中介紹的英語-法語數據集上訓練該模型進行機器翻譯 。
10.7.2。編碼器
回想一下,編碼器將可變長度的輸入序列轉換為固定形狀的上下文變量 c(見圖 10.7.1)。
考慮一個單序列示例(批量大小 1)。假設輸入序列是x1,…,xT, 這樣xt是個 tth令牌。在時間步t, RNN 變換輸入特征向量xt為了xt 和隱藏狀態ht?1從上一次進入當前隱藏狀態ht. 我們可以使用一個函數f表達RNN循環層的變換:
(10.7.1)ht=f(xt,ht?1).
通常,編碼器通過自定義函數將所有時間步的隱藏狀態轉換為上下文變量q:
(10.7.2)c=q(h1,…,hT).
例如,在圖 10.7.1中,上下文變量只是隱藏狀態hT對應于編碼器 RNN 在處理輸入序列的最終標記后的表示。
在這個例子中,我們使用單向 RNN 來設計編碼器,其中隱藏狀態僅取決于隱藏狀態時間步和之前的輸入子序列。我們還可以使用雙向 RNN 構建編碼器。在這種情況下,隱藏狀態取決于時間步長前后的子序列(包括當前時間步長的輸入),它編碼了整個序列的信息。
現在讓我們來實現 RNN 編碼器。請注意,我們使用嵌入層來獲取輸入序列中每個標記的特征向量。嵌入層的權重是一個矩陣,其中行數對應于輸入詞匯表的大小 ( vocab_size),列數對應于特征向量的維度 ( embed_size)。對于任何輸入令牌索引i,嵌入層獲取ith權矩陣的行(從 0 開始)返回其特征向量。在這里,我們使用多層 GRU 實現編碼器。
def init_seq2seq(module): #@save """Initialize weights for Seq2Seq.""" if type(module) == nn.Linear: nn.init.xavier_uniform_(module.weight) if type(module) == nn.GRU: for param in module._flat_weights_names: if "weight" in param: nn.init.xavier_uniform_(module._parameters[param]) class Seq2SeqEncoder(d2l.Encoder): #@save """The RNN encoder for sequence to sequence learning.""" def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = d2l.GRU(embed_size, num_hiddens, num_layers, dropout) self.apply(init_seq2seq) def forward(self, X, *args): # X shape: (batch_size, num_steps) embs = self.embedding(X.t().type(torch.int64)) # embs shape: (num_steps, batch_size, embed_size) outputs, state = self.rnn(embs) # outputs shape: (num_steps, batch_size, num_hiddens) # state shape: (num_layers, batch_size, num_hiddens) return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.initialize(init.Xavier())
def forward(self, X, *args):
# X shape: (batch_size, num_steps)
embs = self.embedding(d2l.transpose(X))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
vocab_size: int
embed_size: int
num_hiddens: int
num_layers: int
dropout: float = 0
def setup(self):
self.embedding = nn.Embed(self.vocab_size, self.embed_size)
self.rnn = d2l.GRU(self.num_hiddens, self.num_layers, self.dropout)
def __call__(self, X, *args, training=False):
# X shape: (batch_size, num_steps)
embs = self.embedding(d2l.transpose(X).astype(jnp.int32))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs, training=training)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
def call(self, X, *args):
# X shape: (batch_size, num_steps)
embs = self.embedding(tf.transpose(X))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
下面用一個具體的例子來說明上述編碼器的實現。下面,我們實例化一個隱藏單元數為 16 的兩層 GRU 編碼器。給定一個小批量序列輸入X (批量大小:4,時間步數:9),最后一層在所有時間步的隱藏狀態(enc_outputs由編碼器的循環層返回)是一個形狀的張量(時間步數、批量大小、隱藏單元數)。
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = torch.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = np.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = jnp.zeros((batch_size, num_steps)) (enc_outputs, enc_state), _ = encoder.init_with_output(d2l.get_key(), X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = tf.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
由于我們在這里使用 GRU,因此最終時間步的多層隱藏狀態的形狀為(隱藏層數、批量大小、隱藏單元數)。
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_len(enc_state, num_layers) d2l.check_shape(enc_state[0], (batch_size, num_hiddens))
10.7.3。解碼器
給定一個目標輸出序列y1,y2,…,yT′對于每個時間步t′(我們用t′為了與輸入序列時間步長區分開來),解碼器為在步驟中出現的每個可能標記分配一個預測概率yt′+1以目標中的先前標記為條件y1,…,yt′和上下文變量c, IE, P(yt′+1∣y1,…,yt′,c).
預測后續令牌t′+1在目標序列中,RNN 解碼器采用上一步的目標標記 yt′,前一時間步的隱藏 RNN 狀態 st′?1, 和上下文變量 c作為其輸入,并將它們轉換為隱藏狀態st′在當前時間步。我們可以使用一個函數g表達解碼器隱藏層的變換:
(10.7.3)st′=g(yt′?1,c,st′?1).
在獲得解碼器的隱藏狀態后,我們可以使用輸出層和 softmax 操作來計算預測分布 p(yt′+1∣y1,…,yt′,c) 在隨后的輸出令牌上t′+1.
按照圖 10.7.1,在如下實現解碼器時,我們直接使用編碼器最后一個時間步的隱藏狀態來初始化解碼器的隱藏狀態。這要求 RNN 編碼器和 RNN 解碼器具有相同的層數和隱藏單元。為了進一步合并編碼的輸入序列信息,上下文變量在所有時間步都與解碼器輸入連接在一起。為了預測輸出標記的概率分布,我們使用全連接層來轉換 RNN 解碼器最后一層的隱藏狀態。
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(embed_size+num_hiddens, num_hiddens,
num_layers, dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(init_seq2seq)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def forward(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(X.t().type(torch.int32))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = context.repeat(embs.shape[0], 1, 1)
# Concat at the feature dimension
embs_and_context = torch.cat((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
self.initialize(init.Xavier())
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def forward(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(d2l.transpose(X))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = np.tile(context, (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = np.concatenate((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
vocab_size: int
embed_size: int
num_hiddens: int
num_layers: int
dropout: float = 0
def setup(self):
self.embedding = nn.Embed(self.vocab_size, self.embed_size)
self.rnn = d2l.GRU(self.num_hiddens, self.num_layers, self.dropout)
self.dense = nn.Dense(self.vocab_size)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def __call__(self, X, state, training=False):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(d2l.transpose(X).astype(jnp.int32))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = jnp.tile(context, (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = jnp.concatenate((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state,
training=training)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.dense = tf.keras.layers.Dense(vocab_size)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def call(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(tf.transpose(X))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = tf.tile(tf.expand_dims(context, 0), (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = tf.concat((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = tf.transpose(self.dense(outputs), (1, 0, 2))
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
為了說明實現的解碼器,下面我們使用與上述編碼器相同的超參數對其進行實例化。正如我們所見,解碼器的輸出形狀變為(批量大小、時間步數、詞匯量大小),其中張量的最后一個維度存儲預測的標記分布。
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers)
state = decoder.init_state(encoder.init_with_output(d2l.get_key(), X)[0])
(dec_outputs, state), _ = decoder.init_with_output(d2l.get_key(), X,
state)
d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_len(state[1], num_layers) d2l.check_shape(state[1][0], (batch_size, num_hiddens))
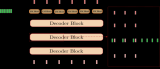
總而言之,上述 RNN 編碼器-解碼器模型中的層如圖 10.7.2所示。

圖 10.7.2 RNN 編碼器-解碼器模型中的層。
10.7.4。用于序列到序列學習的編碼器-解碼器
將它們全部放在代碼中會產生以下結果:
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return torch.optim.Adam(self.parameters(), lr=self.lr)
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return gluon.Trainer(self.parameters(), 'adam',
{'learning_rate': self.lr})
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
encoder: nn.Module
decoder: nn.Module
tgt_pad: int
lr: float
def validation_step(self, params, batch, state):
l, _ = self.loss(params, batch[:-1], batch[-1], state)
self.plot('loss', l, train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return optax.adam(learning_rate=self.lr)
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return tf.keras.optimizers.Adam(learning_rate=self.lr)
10.7.5。帶掩蔽的損失函數
在每個時間步,解碼器預測輸出標記的概率分布。與語言建模一樣,我們可以應用 softmax 來獲得分布并計算交叉熵損失以進行優化。回想一下10.5 節,特殊的填充標記被附加到序列的末尾,因此不同長度的序列可以有效地加載到相同形狀的小批量中。但是,填充令牌的預測應排除在損失計算之外。為此,我們可以用零值屏蔽不相關的條目,以便任何不相關的預測與零的乘積等于零。
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = (Y.reshape(-1) != self.tgt_pad).type(torch.float32) return (l * mask).sum() / mask.sum()
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = (Y.reshape(-1) != self.tgt_pad).astype(np.float32) return (l * mask).sum() / mask.sum()
@d2l.add_to_class(Seq2Seq)
@partial(jax.jit, static_argnums=(0, 5))
def loss(self, params, X, Y, state, averaged=False):
Y_hat = state.apply_fn({'params': params}, *X,
rngs={'dropout': state.dropout_rng})
Y_hat = Y_hat.reshape((-1, Y_hat.shape[-1]))
Y = Y.reshape((-1,))
fn = optax.softmax_cross_entropy_with_integer_labels
l = fn(Y_hat, Y)
mask = (Y.reshape(-1) != self.tgt_pad).astype(jnp.float32)
return (l * mask).sum() / mask.sum(), {}
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = tf.cast(tf.reshape(Y, -1) != self.tgt_pad, tf.float32) return tf.reduce_sum(l * mask) / tf.reduce_sum(mask)
10.7.6。訓練
現在我們可以創建和訓練一個 RNN 編碼器-解碼器模型,用于機器翻譯數據集上的序列到序列學習。
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005, training=True)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
with d2l.try_gpu():
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1)
trainer.fit(model, data)

10.7.7。預言
為了預測每一步的輸出序列,將前一時間步的預測標記作為輸入饋入解碼器。一個簡單的策略是對解碼器在每一步預測時分配最高概率的令牌進行采樣。與訓練一樣,在初始時間步,序列開始(“”)標記被送入解碼器。這個預測過程如圖 10.7.3所示 。當預測到序列結尾(“”)標記時,輸出序列的預測就完成了。

圖 10.7.3使用 RNN 編碼器-解碼器逐個標記地預測輸出序列標記。
在下一節中,我們將介紹基于波束搜索的更復雜的策略(第 10.8 節)。
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
batch = [a.to(device) for a in batch]
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [tgt[:, 0].unsqueeze(1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state)
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return torch.cat(outputs[1:], 1), attention_weights
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
batch = [a.as_in_context(device) for a in batch]
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [np.expand_dims(tgt[:, 0], 1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state)
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return np.concatenate(outputs[1:], 1), attention_weights
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, params, batch, num_steps,
save_attention_weights=False):
src, tgt, src_valid_len, _ = batch
enc_all_outputs, inter_enc_vars = self.encoder.apply(
{'params': params['encoder']}, src, src_valid_len, training=False,
mutable='intermediates')
# Save encoder attention weights if inter_enc_vars containing encoder
# attention weights is not empty. (to be covered later)
enc_attention_weights = []
if bool(inter_enc_vars) and save_attention_weights:
# Encoder Attention Weights saved in the intermediates collection
enc_attention_weights = inter_enc_vars[
'intermediates']['enc_attention_weights'][0]
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [jnp.expand_dims(tgt[:,0], 1), ], []
for _ in range(num_steps):
(Y, dec_state), inter_dec_vars = self.decoder.apply(
{'params': params['decoder']}, outputs[-1], dec_state,
training=False, mutable='intermediates')
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
# Decoder Attention Weights saved in the intermediates collection
dec_attention_weights = inter_dec_vars[
'intermediates']['dec_attention_weights'][0]
attention_weights.append(dec_attention_weights)
return jnp.concatenate(outputs[1:], 1), (attention_weights,
enc_attention_weights)
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len, training=False)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [tf.expand_dims(tgt[:, 0], 1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state, training=False)
outputs.append(tf.argmax(Y, 2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return tf.concat(outputs[1:], 1), attention_weights
10.7.8。預測序列的評估
我們可以通過將預測序列與目標序列(ground-truth)進行比較來評估預測序列。但是,比較兩個序列之間的相似性的適當衡量標準究竟是什么?
BLEU (Bilingual Evaluation Understudy) 雖然最初是為評估機器翻譯結果而提出的 ( Papineni et al. , 2002 ),但已廣泛用于測量不同應用的輸出序列質量。原則上,對于任何n-grams 在預測序列中,BLEU 評估是否這n-grams 出現在目標序列中。
表示為pn的精度n-grams,即匹配數量的比值n-grams 在預測和目標序列中的數量n-預測序列中的克。解釋一下,給定一個目標序列A,B, C,D,E,F, 和一個預測序列 A,B,B,C,D, 我們有 p1=4/5,p2=3/4,p3=1/3, 和 p4=0. 此外,讓lenlabel和 lenpred分別是目標序列和預測序列中的標記數。那么,BLEU 被定義為
(10.7.4)exp?(min(0,1?lenlabellenpred))∏n=1kpn1/2n,
在哪里k是最長的n-grams 用于匹配。
根據(10.7.4)中BLEU的定義,每當預測序列與目標序列相同時,BLEU為1。而且,由于匹配時間較長n-grams 更難,BLEU 給更長的時間賦予更大的權重n-克精度。具體來說,當pn是固定的,pn1/2n增加為n增長(原始論文使用pn1/n). 此外,由于預測較短的序列往往會獲得更高的 pn值, (10.7.4)中乘法項之前的系數 懲罰較短的預測序列。例如,當k=2, 給定目標序列A,B, C,D,E,F和預測序列 A,B, 雖然p1=p2=1, 懲罰因子 exp?(1?6/2)≈0.14降低 BLEU。
我們按如下方式實施 BLEU 措施。
def bleu(pred_seq, label_seq, k): #@save
"""Compute the BLEU."""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, min(k, len_pred) + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
最后,我們使用經過訓練的 RNN 編碼器-解碼器將一些英語句子翻譯成法語,并計算結果的 BLEU。
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['nous', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['je', 'le', 'refuse', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(trainer.state.params, data.build(engs, fras),
data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['', '.'], bleu,0.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['il', 'est', 'mouillé', '.'], bleu,0.658 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ['je', 'l’ai', 'vu', '.'], bleu,0.000 he's calm . => ['il', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', ' ', '.'], bleu,0.512
10.7.9。概括
按照編碼器-解碼器架構的設計,我們可以使用兩個 RNN 來設計序列到序列學習的模型。在編碼器-解碼器訓練中,teacher forcing 方法將原始輸出序列(與預測相反)饋送到解碼器。在實現編碼器和解碼器時,我們可以使用多層 RNN。我們可以使用掩碼來過濾掉不相關的計算,比如在計算損失時。至于評估輸出序列,BLEU 是一種流行的衡量方法,通過匹配n-預測序列和目標序列之間的克。
10.7.10。練習
你能調整超參數來改善翻譯結果嗎?
在損失計算中不使用掩碼重新運行實驗。你觀察到什么結果?為什么?
如果編碼器和解碼器的層數或隱藏單元數不同,我們如何初始化解碼器的隱藏狀態?
在訓練中,用將前一時間步的預測輸入解碼器來代替教師強制。這對性能有何影響?
用 LSTM 替換 GRU 重新運行實驗。
還有其他方法可以設計解碼器的輸出層嗎?
-
解碼器
+關注
關注
9文章
1164瀏覽量
41763 -
pytorch
+關注
關注
2文章
809瀏覽量
13802
發布評論請先 登錄
機器翻譯不可不知的Seq2Seq模型
神經機器翻譯的方法有哪些?
在機器學習中如何進行基本翻譯
神經機器翻譯的編碼-解碼架構有了新進展, 具體要怎么配置?
這款名為Seq2Seq-Vis的工具能將人工智能的翻譯過程進行可視化
如此強大的機器翻譯架構內部的運行機制究竟是怎樣的?
一文看懂NLP里的模型框架 Encoder-Decoder和Seq2Seq
淺析Google Research的LaserTagger和Seq2Edits

PyTorch教程-10.6. 編碼器-解碼器架構

PyTorch教程-11.4. Bahdanau 注意力機制

基于transformer的編碼器-解碼器模型的工作原理
基于 Transformers 的編碼器-解碼器模型
神經編碼器-解碼器模型的歷史





 工商網監
工商網監
評論