 電子發(fā)燒友App
電子發(fā)燒友App


本文原標(biāo)題How to Configure an Encoder-Decoder Model for Neural Machine Translation,作者為Jason Brownlee,全文由景智AI編譯。
翻譯/? 崔躍輝、葉倚青
校對(duì)/? 葉倚青
用于循環(huán)神經(jīng)網(wǎng)絡(luò)的編碼-解碼架構(gòu),在標(biāo)準(zhǔn)機(jī)器翻譯基準(zhǔn)上取得了最新的成果,并被用于工業(yè)翻譯服務(wù)的核心。
該模型很簡(jiǎn)單,但是考慮到訓(xùn)練所需的大量數(shù)據(jù),以及調(diào)整模型中無(wú)數(shù)的設(shè)計(jì)方案,想要獲得最佳的性能是非常困難的。值得慶幸的是,研究科學(xué)家已經(jīng)使用谷歌規(guī)模的硬件為我們做了這項(xiàng)工作,并提供了一套啟發(fā)式的方法,來(lái)配置神經(jīng)機(jī)器翻譯的編碼-解碼模型和預(yù)測(cè)一般的序列。
在景智AI網(wǎng)這篇譯文中,您將會(huì)獲得,在神經(jīng)機(jī)器翻譯和其他自然語(yǔ)言處理任務(wù)中,如何最好地配置編碼-解碼循環(huán)神經(jīng)網(wǎng)絡(luò)的各種細(xì)節(jié)。
閱讀完景智AI網(wǎng)譯文后,你將知道:
谷歌的研究調(diào)查了各個(gè)模型針對(duì)編碼-解碼的設(shè)計(jì)方案,以此來(lái)分離出它們的作用效果。
關(guān)于一些設(shè)計(jì)方案的結(jié)果和建議,諸如關(guān)于詞嵌入、編碼和解碼深度以及注意力機(jī)制。
一系列基礎(chǔ)模型設(shè)計(jì)方案,它們可以作為你自己的序列到序列的項(xiàng)目的起始點(diǎn)。
讓我們開(kāi)始吧:
Sporting Park
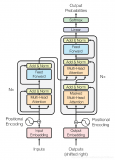
神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯的編碼-解碼模型
用于循環(huán)神經(jīng)網(wǎng)絡(luò)的編碼-解碼架構(gòu),取代了經(jīng)典的基于短語(yǔ)的統(tǒng)計(jì)機(jī)器翻譯系統(tǒng),以獲得最新的結(jié)果。
根據(jù)他們2016年發(fā)表的論文“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”,谷歌現(xiàn)已在他們的Google翻譯服務(wù)的核心中使用這種方法。
這種架構(gòu)的問(wèn)題是模型很大,需要非常大量的數(shù)據(jù)集來(lái)訓(xùn)練。 這受到模型訓(xùn)練花費(fèi)數(shù)天或數(shù)周的影響,并且需要非常昂貴的計(jì)算資源。 因此,關(guān)于不同設(shè)計(jì)選擇對(duì)模型的影響及其對(duì)模型技能的影響,已經(jīng)做了很少的工作。
Denny Britz等人清楚地給出了解決方案。 在他們的2017年論文“神經(jīng)機(jī)器翻譯體系的大量探索”中,他們?yōu)闃?biāo)準(zhǔn)的英德翻譯任務(wù)設(shè)計(jì)了一個(gè)基準(zhǔn)模型,列舉了一套不同的模型設(shè)計(jì)選擇,并描述了它們對(duì)技能的影響。他們聲稱,完整的實(shí)驗(yàn)耗費(fèi)了超過(guò)250,000個(gè)GPU計(jì)算時(shí)間,至少可以說(shuō)是令人印象深刻的。
我們報(bào)告了數(shù)百次實(shí)驗(yàn)運(yùn)行的實(shí)驗(yàn)結(jié)果和方差數(shù),對(duì)應(yīng)于標(biāo)準(zhǔn)WMT英語(yǔ)到德語(yǔ)翻譯任務(wù)超過(guò)250,000個(gè)GPU小時(shí)。我們的實(shí)驗(yàn)為建立和擴(kuò)展NMT體系結(jié)構(gòu)提供了新的見(jiàn)解和實(shí)用建議 。
在本文中,我們將審視這篇文章的一些發(fā)現(xiàn),我們可以用它來(lái)調(diào)整我們自己的神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯模型,以及一般的序列到序列模型 。
有關(guān)編碼-解碼體系結(jié)構(gòu)和注意力機(jī)制的更多背景信息,請(qǐng)參閱以下文章:
Encoder-Decoder Long Short-Term Memory Networks
Attention in Long Short-Term Memory Recurrent Neural Networks
基線模型
我們可以通過(guò)描述用作所有實(shí)驗(yàn)起點(diǎn)的基線模型開(kāi)始。
選擇基線模型配置,使得模型在翻譯任務(wù)上能夠很好地執(zhí)行。
嵌入:512維
RNN小區(qū): 門控循環(huán)單元或GRU
編碼器:雙向
編碼深度: 2層 (每個(gè)方向一層)
解碼深度:2層
注意: Bahdanau風(fēng)格
優(yōu)化器:Adam
信息丟失:20%的投入
每個(gè)實(shí)驗(yàn)都從基準(zhǔn)模型開(kāi)始,并且改變了一個(gè)要素,試圖隔離設(shè)計(jì)決策對(duì)模型技能的影響,在這種情況下,BLEU得分。
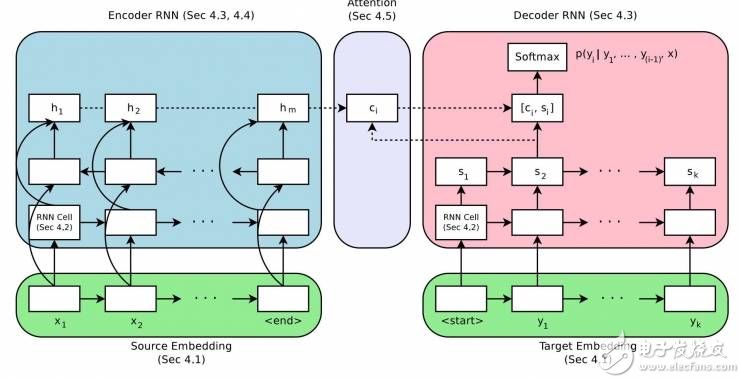
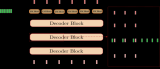
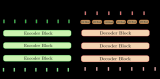
神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯的編碼-解碼體系結(jié)構(gòu)
取自“Massive Exploration of Neural Machine Translation Architectures”
嵌入大小
一個(gè)詞嵌入(word embedding)用于表示單詞輸入到編碼器。
這是一個(gè)分散表示(distributed representation),其中每個(gè)單詞映射到一個(gè)具有連續(xù)值的固定大小向量上。這種方法的好處是,具有相似含義的不同詞語(yǔ)將具有類似的表示。
通常在訓(xùn)練數(shù)據(jù)上擬合模型時(shí)學(xué)習(xí)這種分散表示。嵌入大小定義了用于表示單詞的矢量長(zhǎng)度。一般認(rèn)為,更大的維度會(huì)導(dǎo)致更具表現(xiàn)力的表示(representation),反過(guò)來(lái)功能更好。
有趣的是,結(jié)果顯示最大尺寸的測(cè)試確實(shí)取得了最好的結(jié)果,但增加尺寸的收益總體來(lái)說(shuō)較小。
[結(jié)果顯示] 2048維的嵌入取得最佳的整體效果,他們只小幅這樣做了。即使是很小的128維嵌入也表現(xiàn)出色,收斂速度幾乎快了一倍。??
建議:從一個(gè)小的嵌入大小開(kāi)始,比如128,也許稍后增加尺寸會(huì)輕微增強(qiáng)功能。
RNN 單元種類共有三種常用的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN):
簡(jiǎn)單循環(huán)神經(jīng)網(wǎng)絡(luò)
長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)
門控循環(huán)單元(GRU)
LSTM是為了解決簡(jiǎn)單循環(huán)神經(jīng)網(wǎng)絡(luò)中限制循環(huán)神經(jīng)網(wǎng)絡(luò)深度學(xué)習(xí)的梯度消失問(wèn)題而開(kāi)發(fā)的。GRU是為了簡(jiǎn)化LSTM而開(kāi)發(fā)的。結(jié)果顯示GRU和LSTM都顯著強(qiáng)于簡(jiǎn)單RNN,但是LSTM總體上更好。
在我們的實(shí)驗(yàn)中,LSTM?? 單元始終勝過(guò)GRU單元。
建議:在你的模型中使用LSTM RNN單元。
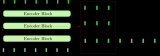
編碼-解碼深度
通常認(rèn)為,深度網(wǎng)絡(luò)比淺層網(wǎng)絡(luò)表現(xiàn)更好。
關(guān)鍵在于找到網(wǎng)絡(luò)深度、模型功能和訓(xùn)練時(shí)間之間的平衡。 這是因?yàn)椋绻麑?duì)功能的改善微小,我們一般沒(méi)有無(wú)窮的資源來(lái)訓(xùn)練超深度網(wǎng)絡(luò)。
作者正在探索編碼模型和解碼模型的深度,以及對(duì)模型功能的影響。
說(shuō)到編碼,研究發(fā)現(xiàn)深度對(duì)功能并沒(méi)有顯著影響,更驚人的是,一個(gè)1層的雙向模型僅優(yōu)于一個(gè)4層的結(jié)構(gòu)很少。一個(gè)2層雙向編碼器只比其他經(jīng)測(cè)試的結(jié)構(gòu)強(qiáng)一點(diǎn)點(diǎn)。
我們沒(méi)有發(fā)現(xiàn)確鑿證據(jù)可以證明編碼深度有必要超過(guò)兩層。
建議:?使用1層的雙向編碼器,然后擴(kuò)展到2個(gè)雙向?qū)樱源藢⒐δ苄》葟?qiáng)化。
關(guān)于解碼器也是類似的。1,2,4層的解碼器之間的功能差異很小。4層的解碼器略勝一籌。8層解碼器在測(cè)試條件下沒(méi)有收斂。
在解碼器這里,深度模型比淺層模型表現(xiàn)略好。
建議:用1層的解碼器作為起步,然后用4層的解碼器獲得更優(yōu)的結(jié)果。
編碼器輸入的方向
源文本序列可以通過(guò)以下幾種順序發(fā)送給編碼器:
正向,即通常的方式
反向
正反向同時(shí)進(jìn)行
作者發(fā)現(xiàn)了輸入序列的順序?qū)δP凸δ艿挠绊懀噍^于其他多種單向、雙向結(jié)構(gòu)。
總之,他們證實(shí)了先前的發(fā)現(xiàn):反向序列優(yōu)于正向序列、雙向的比反向序列略好。
……雙向編碼器通常比單向編碼器表現(xiàn)更好,但不是絕對(duì)優(yōu)勢(shì)。具有反向數(shù)據(jù)源的編碼器全部?jī)?yōu)于和它們相當(dāng)?shù)奈捶聪虻膶?duì)照。
建議:使用反向輸入序列或者轉(zhuǎn)變?yōu)殡p向,以此將功能小幅度強(qiáng)化。
注意力機(jī)制
原始的編碼-解碼模型有一個(gè)問(wèn)題:編碼器會(huì)將輸入信息安排進(jìn)一個(gè)固定長(zhǎng)度的內(nèi)部表達(dá)式,而解碼器必須從其中計(jì)算出整個(gè)輸出序列。
注意力機(jī)制是一個(gè)進(jìn)步,它允許編碼器“關(guān)注”輸入序列中不同的字符并在輸出序列中分別輸出。
作者觀察了幾種簡(jiǎn)單的注意力機(jī)制的變種。結(jié)果顯示具備注意力機(jī)制將大幅提升模型表現(xiàn)。
當(dāng)我們期待基于注意力機(jī)制的模型完勝時(shí),才驚訝地發(fā)現(xiàn)沒(méi)有“注意力”地模型表現(xiàn)多么糟糕。
Bahdanau, et al. 在他們2015年的論文“Neural machine translation by jointly learning to align and translate”中表述的一種簡(jiǎn)單加權(quán)平均的注意力機(jī)制表現(xiàn)最好。
建議:使用注意力機(jī)制并優(yōu)先使用Bahdanau的加權(quán)平均的注意力機(jī)制。
推斷
神經(jīng)系統(tǒng)機(jī)器翻譯常常使用集束搜索來(lái)對(duì)模型輸出序列中的單詞的概率取樣。
通常認(rèn)為,集束的寬度越寬,搜索就越全面,結(jié)果就越好。
結(jié)果顯示,3-5的適中的集束寬度表現(xiàn)最好,通過(guò)長(zhǎng)度折損僅能略微優(yōu)化。作者建議針對(duì)特定問(wèn)題調(diào)節(jié)寬度。
我們發(fā)現(xiàn),調(diào)節(jié)準(zhǔn)確的集束搜索對(duì)好結(jié)果的取得非常關(guān)鍵,它可以持續(xù)獲得不止一個(gè)的BLE點(diǎn)。
建議:從貪婪式搜索開(kāi)始(集束=1) 并且根據(jù)你的具體問(wèn)題調(diào)節(jié)。
最終模型
作者把他們的發(fā)現(xiàn)都應(yīng)用在同一個(gè)“最好的模型”中,然后將這個(gè)模型的結(jié)果與其他表現(xiàn)突出的模型和體現(xiàn)最高水平的結(jié)果比較。
此模型的具體配置如下表,摘自論文。當(dāng)你為自然語(yǔ)言處理程序開(kāi)發(fā)自己的編碼-解碼模型時(shí),這些參數(shù)可以作為一個(gè)好的起始點(diǎn)。
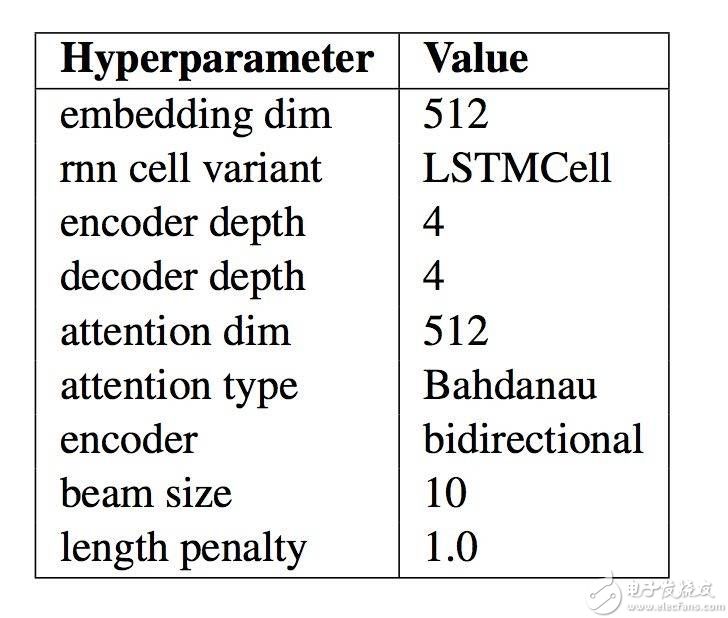
最終的神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯模型的模型配置總結(jié)
“Massive Exploration of Neural Machine Translation Architectures”
此系統(tǒng)的結(jié)果令人印象深刻,它用更簡(jiǎn)單的模型達(dá)到了接近最先進(jìn)的水平,而這并不是論文的最終目標(biāo)。
……我們確實(shí)證明了通過(guò)仔細(xì)的超參數(shù)調(diào)整和優(yōu)良的初始化,基于標(biāo)準(zhǔn)的WMT也可能達(dá)到最先進(jìn)的水平。
很重要的一點(diǎn),作者將他們的代碼作為了開(kāi)源項(xiàng)目,稱作“tf-seq2seq”。2017年,因?yàn)槠渲袃晌蛔髡邥r(shí)谷歌的大腦訓(xùn)練項(xiàng)目的成員,他們的成果在谷歌研究博客上發(fā)布,標(biāo)題為“Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow“。
延伸閱讀
如果你想深入了解,這部分提供關(guān)于此話題的更多資源。
Massive Exploration of Neural Machine Translation Architectures, 2017.
Denny Britz Homepage
WildML Blog
Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow, 2017.
tf-seq2seq: A general-purpose encoder-decoder framework for Tensorflow
tf-seq2seq Project Documentation
tf-seq2seq Tutorial: Neural Machine Translation Background
Neural machine translation by jointly learning to align and translate, 2015.
總結(jié)
本文闡述了在神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯系統(tǒng)和其他自然語(yǔ)言處理任務(wù)中,如何最好地配置一個(gè)編碼-解碼循環(huán)神經(jīng)網(wǎng)絡(luò)。具體是這些:
谷歌的研究調(diào)查了各個(gè)模型針對(duì)編碼-解碼的設(shè)計(jì)方案,以此來(lái)分離出它們的作用效果。
關(guān)于一些設(shè)計(jì)方案的結(jié)果和建議,諸如關(guān)于詞嵌入、編碼和解碼深度以及注意力機(jī)制。
一系列基礎(chǔ)模型設(shè)計(jì)方案,它們可以作為你自己的序列到序列的項(xiàng)目的起始點(diǎn)。



































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論