 基于多任務預訓練模塊化提示
基于多任務預訓練模塊化提示

Prompt Tuning 可以讓預訓練的語言模型快速適應下游任務。雖然有研究證明:當訓練數據足夠多的時候,Prompt Tuning 的微調結果可以媲美整個模型的訓練調優,但當面對 Few-shot 場景時,PT 的調優方法還是存在一定的局限性。針對這個問題,復旦提出了多任務預訓練模塊化 Prompt(簡稱為:),來提高模型在 Few-shot 場景下的 PT 效果,使模型能夠快速適應下游任務。
背景介紹
基于 Prompt Learning 的預訓練模型在 Few-shot 場景下取得了顯著的進展,它縮小了模型訓練和下游任務微調之間的差距,并且通過將下游任務轉換成統一的語言建模任務,可以重復使用預訓練模型頭,而不是訓練一個隨機初始化的分類頭來解決有限數據的任務。然而,基于 Prompt Learning 通常需要針對每個下游任務進行全參數微調,這就需要大量的計算資源,尤其當面對上百億的大模型的時候。
隨著時間推移,近期有很多工作致力于有效的 prompt learning 方法的研究,該方法只需學習少量的 soft prompt 參數,并且能夠保持 PTM 主體參數不變。與模型的整體調優相比,prompt 調優優勢明顯,它對計算資源要求較低并且針對特定的下游任務能夠實現快速調優匹配。但是盡管已經證明,當訓練數據足夠時,提示調整可以與完整模型調整的性能相匹配,但由于隨機初始化的 soft prompt 在預訓練和微調之間引入了新的差距,因此在 Few-shot 中無法從零開始訓練 soft prompt。
「為了彌補 Prompt Tuning 的預訓練和微調之間的差距,本文提出了多任務預訓練模塊化提示 (),它是一組在 38 個中文任務上預訓練的可組合提示」,在下游任務中,預訓練的 prompt 可以有選擇地進行激活和組合,提高對未知任務的泛化能力。為了彌合預訓練和微調之間的差距,將上下游任務制定為統一到了一個機器閱讀理解任務中。 通過在梯度下降、黑盒調優兩種學習范式的實驗,證明了 在 Few-shot 學習場景中,相比比 Prompt tuning、完整模型調優和其它的 Prompt 預訓練方法都具有顯著的優勢,最后作者還證明了僅通過學習 8 個參數來組合預訓練的模塊化提示,就可以實現對下游任務的快速適應。
方法介紹
方法主要通過以下三個步驟實現對下游任務的快速適應:(1) 在大規模無標簽數據上進行自監督預訓練;(2) 使用多任務學習進行預訓練模塊指令和相應的 route;(3) 激活并調整子集指令以進行對下游任務的適應。具體流程圖如下所示: 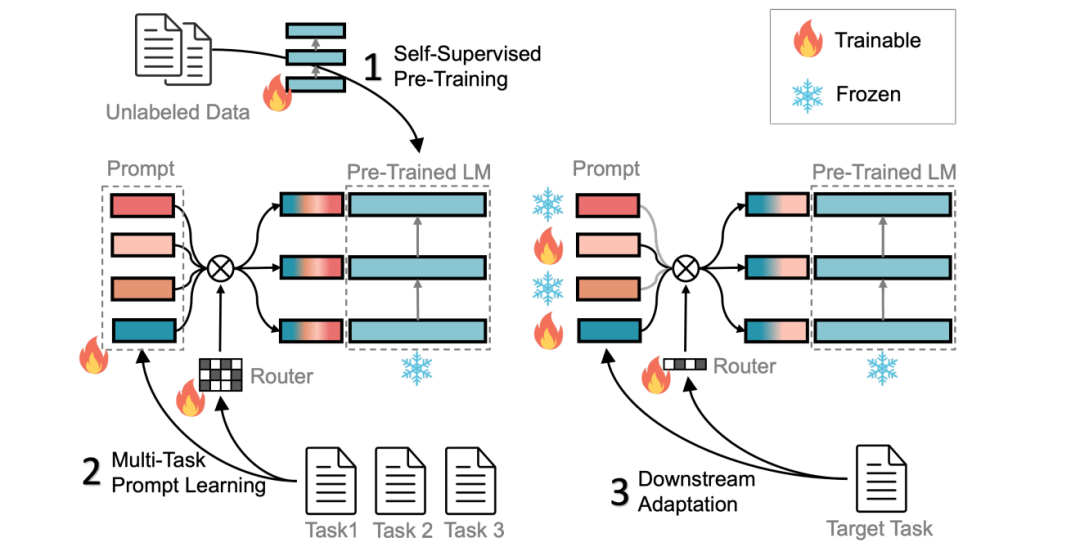 ?方法的主要內容包括:「統一為 MRC 任務、深度模塊化 Prompt、多任務預訓練、下游 FT」等四個方面。 「統一 MRC 任務」:基于 Prompt 的學習方法不能涵蓋較廣范圍的任務,并且任務之間的標簽詞可能不同,從而導致預訓練模型在不同任務上的效果不佳。基于 MCC 方法,可以將上下游任務轉化成 MCC 任務使得不同任務可以共享相同的標簽詞,但該方法當面對大于 16 個標簽的分類任務時仍存在局限性。為此 方法將上下游任務統一成機器閱讀理解 (MRC) 格式,通過構建一個查詢來進行分類任務,進而可以處理不同標簽數的任務,從而實現更廣泛的任務支持。 「深度模塊化 Prompt」:為了增加 soft prompt 的能力,使其匹配訓練數據的復雜性,作者從深度和寬度兩個維度擴展了 soft prompt,具體如下圖所示:
?方法的主要內容包括:「統一為 MRC 任務、深度模塊化 Prompt、多任務預訓練、下游 FT」等四個方面。 「統一 MRC 任務」:基于 Prompt 的學習方法不能涵蓋較廣范圍的任務,并且任務之間的標簽詞可能不同,從而導致預訓練模型在不同任務上的效果不佳。基于 MCC 方法,可以將上下游任務轉化成 MCC 任務使得不同任務可以共享相同的標簽詞,但該方法當面對大于 16 個標簽的分類任務時仍存在局限性。為此 方法將上下游任務統一成機器閱讀理解 (MRC) 格式,通過構建一個查詢來進行分類任務,進而可以處理不同標簽數的任務,從而實現更廣泛的任務支持。 「深度模塊化 Prompt」:為了增加 soft prompt 的能力,使其匹配訓練數據的復雜性,作者從深度和寬度兩個維度擴展了 soft prompt,具體如下圖所示:
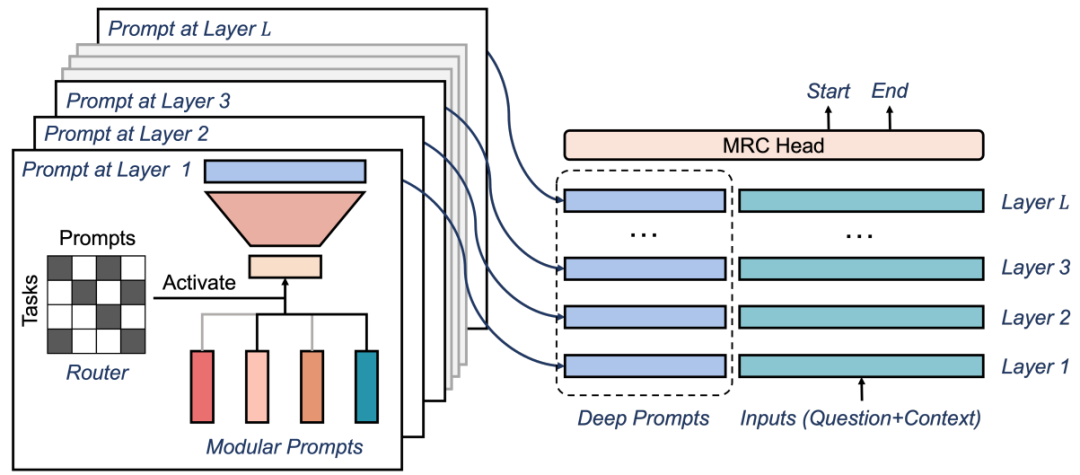
其中:首先在深度方面,作者增加了 LSTM 層或 Transformer Decoder 來實現深度擴展。這些層使得模型可以更好地學習輸入序列的表示,并且能夠考慮更多的上下文信息;其次在寬度方面,作者在 soft prompt 里面添加了更多的詞匯和語義信息。通過深度和寬度的拓展,soft prompt 可以更好地匹配訓練數據的復雜性,從而提高模型的性能和準確率。
「多任務預訓練」:多任務學習已被證明可以提高各種任務的 prompt learning 的表現。作者對由 38 個不同類型、領域、大小的中文 NLP 任務組成的混合任務進行了深度模塊化提示的預訓練。為了處理不平衡的數據大小,對于每次向前計算,首先隨機從 1 到 38 中選擇一個任務 ID,然后獲取對應于所選擇任務的一個批次的訓練數據,從而每個任務的學習步驟數量應該是相同的。
「下游 FT」:為了能夠快速適應下游任務,本文通過兩個階段進行微調,如下圖所示:
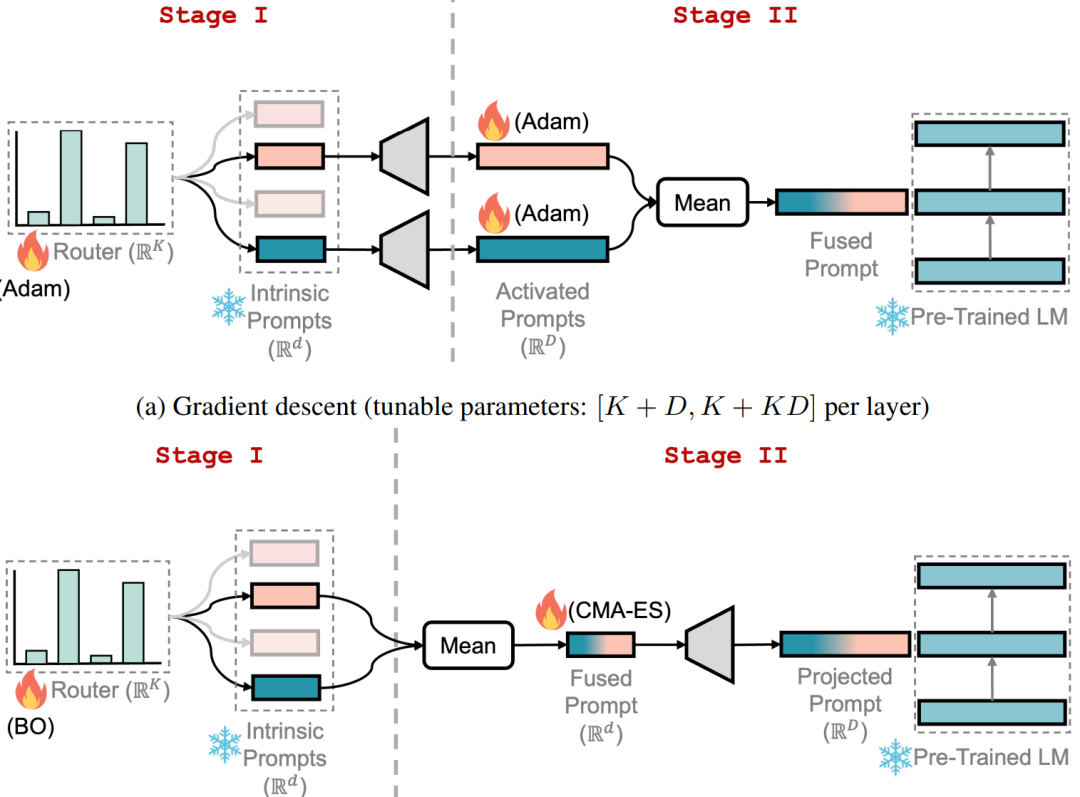
其中:在第一階段,為每個層分配一個隨機路由,并訓練 route 選擇性地重用預訓練的模塊提示來解決目標任務,同時保持所有其他參數凍結。在第二階段,凍結 route 并只微調選擇的提示。整個微調過程中,PTM 參數保持不變。同時作者探索了基于梯度下降和黑盒調優兩種學習范式下的微調。對于梯度下降,使用 Adam 優化器進行兩個階段的微調。對于黑盒 FT,采用貝葉斯優化在第一階段優化 route,并采用 CMAES 優化選擇的內在 prompt ,同時凍結映射矩陣 A。
實驗思路 在 38 個中文 NLP 任務上預訓練,然后在 14 個下游任務上進行評估。在 Few-Shot 下的實驗表明,具體如下圖所示,可以發現「其性能明顯優于 PT、全模型微調和之前的 prompt 訓練方法」。僅通過調整 route(僅有 8 個參數)凍結 PTM 和所有 prompt,就可以實現對下游任務的快速適應。 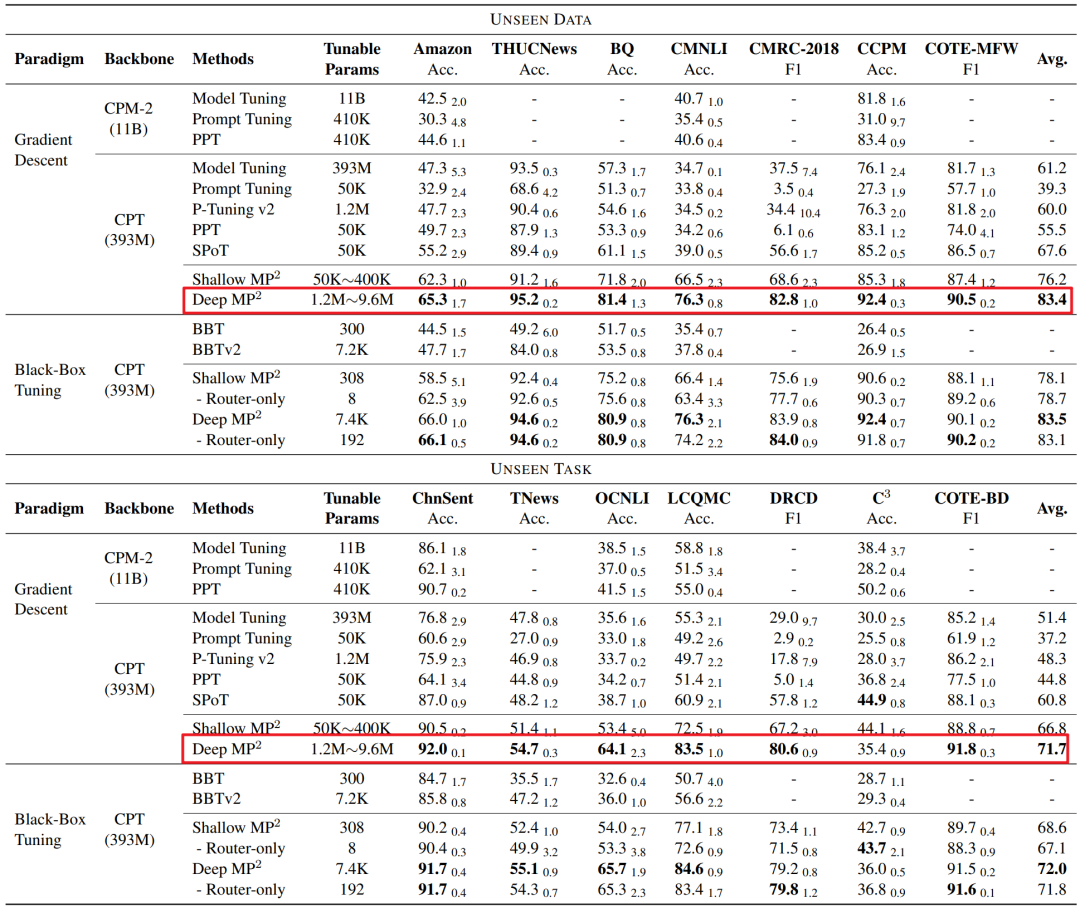
責任編輯:彭菁
-
模塊
+關注
關注
7文章
2790瀏覽量
50668 -
數據
+關注
關注
8文章
7261瀏覽量
92216 -
語言模型
+關注
關注
0文章
563瀏覽量
10833
原文標題:ACL 2023 | 復旦邱錫鵬組提出模塊化Prompt多任務預訓練,可快速適應下游任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于CVR建模的多任務聯合學習訓練方法——ESMM
【大語言模型:原理與工程實踐】大語言模型的預訓練
setjmp構建簡單協作式多任務系統
多任務編程多任務處理是指什么
嵌入式多任務GUI的通用解決方案
實時多任務嵌入式軟件的架構方式的設計應用
新的預訓練方法——MASS!MASS預訓練幾大優勢!

一種基于多任務聯合訓練的閱讀理解模型

基于預訓練模型和長短期記憶網絡的深度學習模型





 工商網監
工商網監
評論