") 深度學(xué)習(xí)低光圖像增強(qiáng)綜述(譯)
深度學(xué)習(xí)低光圖像增強(qiáng)綜述(譯)
論文原文地址:https://arxiv.org/abs/2104.10729v1
github:https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open
百度云(word版翻譯及原文pdf):https://pan.baidu.com/s/1zJ7tU-GpT7O3FYvSN-_7ZA?pwd=gzrr 密碼:gzrr
Lighting the Darkness in the Deep Learning Era
Abstract
低光圖像增強(qiáng) (LLIE)旨在提高在照明較差的環(huán)境中捕獲的圖像的感知或可解釋性。該領(lǐng)域的最新進(jìn)展以基于深度學(xué)習(xí)的解決方案為主,其中采用了許多學(xué)習(xí)策略、網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)、訓(xùn)練數(shù)據(jù)等。在本文中,我們提供了一個(gè)全面的調(diào)研,涵蓋從算法分類到未解決的開(kāi)放問(wèn)題的各個(gè)方面。為了檢驗(yàn)現(xiàn)有方法的泛化性,我們提出了一個(gè)大規(guī)模的低光圖像和視頻數(shù)據(jù)集,其中圖像和視頻是由不同的手機(jī)相機(jī)在不同的光照條件下拍攝的。此外,我們首次提供了一個(gè)統(tǒng)一的在線平臺(tái),涵蓋了許多流行的 LLIE 方法,其結(jié)果可以通過(guò)用戶友好的 Web 界面生成。除了在公開(kāi)可用的數(shù)據(jù)集和我們提出的數(shù)據(jù)集上對(duì)現(xiàn)有方法進(jìn)行定性和定量評(píng)估外,我們還驗(yàn)證了它們?cè)诤诎抵腥四槞z測(cè)的性能。本研究中的數(shù)據(jù)集和在線平臺(tái)可以作為未來(lái)研究的參考來(lái)源,促進(jìn)該研究領(lǐng)域的發(fā)展。本文提出的平臺(tái)和收集的方法、數(shù)據(jù)集和評(píng)估指標(biāo)是公開(kāi)的,并將定期更新在https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open。我們將發(fā)布我們的低光圖像和視頻數(shù)據(jù)集。
1 INTRODUCTION
由于不可避免的環(huán)境和/或技術(shù)限制(例如照明不足和曝光時(shí)間有限),圖像通常在次優(yōu)照明條件(sub-optimallighting condition)下拍攝,受到背光、非均勻照明和弱照明的影響。此類圖像的美學(xué)質(zhì)量受損,并且造成諸如目標(biāo)跟蹤、識(shí)別和檢測(cè)等高級(jí)任務(wù)信息的不理想的傳輸。圖 1 展示了由次優(yōu)照明條件引起的退化的一些示例。
弱光增強(qiáng)是圖像處理的基本任務(wù)之一。它在不同領(lǐng)域有廣泛的應(yīng)用,包括視覺(jué)監(jiān)控、自動(dòng)駕駛和計(jì)算攝影。尤其是智能手機(jī)攝影已變得非常常見(jiàn)。受限于相機(jī)光圈的大小、實(shí)時(shí)處理的要求以及內(nèi)存的限制,在昏暗的環(huán)境中使用智能手機(jī)的相機(jī)拍照尤其具有挑戰(zhàn)性。在此類應(yīng)用中增強(qiáng)低光圖像和視頻是一個(gè)令人興奮的研究領(lǐng)域。
傳統(tǒng)的弱光增強(qiáng)方法包括基于直方圖均衡的方法 和基于Retinex 模型的方法 。后者受到的關(guān)注相對(duì)較多。典型的基于Retinex 模型的方法通過(guò)某種先驗(yàn)或正則化將低光圖像分解為反射分量和照明分量。估計(jì)的反射分量被視為增強(qiáng)結(jié)果。這種方法有一些局限性:1)將反射分量視為增強(qiáng)結(jié)果的理想假設(shè)并不總是成立,特別是考慮到各種照明屬性,這可能導(dǎo)致不切實(shí)際的增強(qiáng),例如細(xì)節(jié)丟失和顏色失真,2)噪聲通常在Retinex 模型中被忽略,因此在增強(qiáng)的結(jié)果中保留或放大,3)找到有效的先驗(yàn)或正則化具有挑戰(zhàn)性。不準(zhǔn)確的先驗(yàn)或正則化可能會(huì)導(dǎo)致增強(qiáng)結(jié)果中的偽影和顏色偏差,以及 4) 由于其復(fù)雜的優(yōu)化過(guò)程,運(yùn)行時(shí)間相對(duì)較長(zhǎng)。

近年來(lái),自第一個(gè)開(kāi)創(chuàng)性工作LLNet[1]以來(lái),基于深度學(xué)習(xí)的 LLIE 取得了令人矚目的成功。與傳統(tǒng)方法相比,基于深度學(xué)習(xí)的解決方案具有更好的準(zhǔn)確性、魯棒性和速度,因此近年來(lái)受到越來(lái)越多的關(guān)注。圖 2 顯示了基于深度學(xué)習(xí)的 LLIE 方法的一個(gè)簡(jiǎn)明里程碑。如圖所示,自 2017 年以來(lái),基于深度學(xué)習(xí)的解決方案的數(shù)量逐年增長(zhǎng)。這些解決方案中使用的學(xué)習(xí)策略包括監(jiān)督學(xué)習(xí) (SL)、強(qiáng)化學(xué)習(xí) (RL)、無(wú)監(jiān)督學(xué)習(xí) (UL)、零樣本學(xué)習(xí) (ZSL) 和半監(jiān)督學(xué)習(xí) (SSL)。請(qǐng)注意,我們僅在圖 2 中報(bào)告了一些具有代表性的方法。實(shí)際上,從 2017 年到 2020 年,關(guān)于基于深度學(xué)習(xí)的方法的論文有 100 多篇,超過(guò)了常規(guī)方法的總數(shù)。此外,雖然一些通用的照片增強(qiáng)方法 [38]、[39]、[40]、[41]、[42]、[43]、[44]、[45]、[46] 可以將圖像的亮度提高到在某種程度上,我們?cè)诒敬握{(diào)查中省略了它們,因?yàn)樗鼈儾⒎侵荚谔幚砀鞣N低光照條件。我們專注于專為弱光圖像和視頻增強(qiáng)而開(kāi)發(fā)的基于深度學(xué)習(xí)的解決方案。
盡管深度學(xué)習(xí)主導(dǎo)了 LLIE 的研究,但缺乏對(duì)基于深度學(xué)習(xí)的解決方案的深入和全面的調(diào)查。文獻(xiàn)[47]、[48] 為兩篇 LLIE綜述文章。與主要回顧傳統(tǒng) LLIE 方法的 [47] 和從人類和機(jī)器視覺(jué)的角度探索幾種傳統(tǒng)和基于深度學(xué)習(xí)的 LLIE 方法的實(shí)驗(yàn)性能的 [48] 相比,我們的調(diào)查具有以下獨(dú)特特征:1)我們的工作是第一個(gè)系統(tǒng)全面地回顧基于深度學(xué)習(xí)的 LLIE 的最新進(jìn)展。我們?cè)诟鱾€(gè)方面進(jìn)行了深入的分析和討論,涵蓋學(xué)習(xí)策略、網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)、訓(xùn)練數(shù)據(jù)集、測(cè)試數(shù)據(jù)集、評(píng)估指標(biāo)等。2)我們提出了一個(gè)包含由在不同的照明條件下使用不同的設(shè)備來(lái)評(píng)估現(xiàn)有方法的泛化性。因此,我們?yōu)殛P(guān)鍵的開(kāi)放性問(wèn)題、挑戰(zhàn)和未來(lái)方向提供見(jiàn)解。此外,據(jù)我們所知,我們是第一個(gè)比較 LLIE 方法在不同現(xiàn)實(shí)世界場(chǎng)景中捕獲的低光視頻上性能的。3) 我們提供了一個(gè)在線平臺(tái),涵蓋了許多流行的基于深度學(xué)習(xí)的 LLIE 方法,結(jié)果可以通過(guò)用戶友好的 Web 界面生成。這個(gè)統(tǒng)一的平臺(tái)解決了比較不同深度學(xué)習(xí)平臺(tái)中實(shí)現(xiàn)的不同方法并需要不同硬件配置的問(wèn)題。使用我們的平臺(tái),沒(méi)有任何 GPU 的人可以在線評(píng)估任何輸入圖像的不同方法的結(jié)果。
我們希望我們的調(diào)查能夠提供新的見(jiàn)解和啟發(fā),以促進(jìn)對(duì)基于深度學(xué)習(xí)的 LLIE 的理解,促進(jìn)對(duì)提出的未解決問(wèn)題的研究,并加快該研究領(lǐng)域的發(fā)展。
2 DEEP LEARNING-BASED LLIE
2.1 Problem Definition
我們首先給出基于深度學(xué)習(xí)的 LLIE 問(wèn)題的通用公式。對(duì)于寬高的低光圖像,過(guò)程可以建模為:
其中是增強(qiáng)結(jié)果,表示具有可訓(xùn)練參數(shù)的網(wǎng)絡(luò)。深度學(xué)習(xí)的目的是找到使誤差最小的最優(yōu)網(wǎng)絡(luò)參數(shù):
其中是 ground truth,損失函數(shù)驅(qū)動(dòng)網(wǎng)絡(luò)的優(yōu)化。在網(wǎng)絡(luò)訓(xùn)練過(guò)程中可以使用監(jiān)督損失和無(wú)監(jiān)督損失等各種損失函數(shù)。更多細(xì)節(jié)將在第 3 節(jié)中介紹。
2.2 Learning Strategies
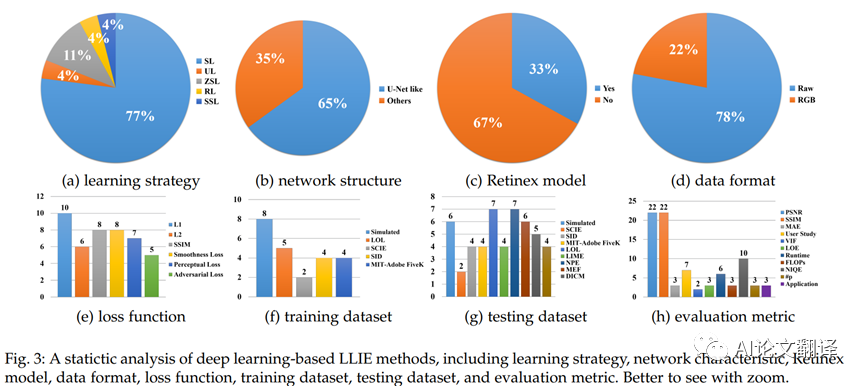
根據(jù)不同的學(xué)習(xí)策略,我們將現(xiàn)有的 LLIE 方法分為監(jiān)督學(xué)習(xí)、強(qiáng)化學(xué)習(xí)、無(wú)監(jiān)督學(xué)習(xí)、零樣本學(xué)習(xí)和半監(jiān)督學(xué)習(xí)。圖 3 給出了從不同角度進(jìn)行的統(tǒng)計(jì)分析。在下文中,我們回顧了每種策略的一些代表性方法。
監(jiān)督學(xué)習(xí)。對(duì)于基于監(jiān)督學(xué)習(xí)的 LLIE 方法,它們可以進(jìn)一步分為端到端方法、基于深度Retinex 的方法和現(xiàn)實(shí)數(shù)據(jù)驅(qū)動(dòng)方法。
第一個(gè)基于深度學(xué)習(xí)的 LLIE 方法 LLNet[1] 采用堆疊稀疏去噪自動(dòng)編碼器 [49] 的變體同時(shí)對(duì)低光圖像進(jìn)行增亮和去噪。這項(xiàng)開(kāi)創(chuàng)性的工作激發(fā)了 LLIE 中端到端網(wǎng)絡(luò)的使用。呂等人。[3] 提出了一種端到端的多分支增強(qiáng)網(wǎng)絡(luò)(MBLLEN)。MBLLEN通過(guò)特征提取模塊、增強(qiáng)模塊和融合模塊提取有效的特征表示來(lái)提高 LLIE 的性能。同一作者 [15] 提出了其他三個(gè)子網(wǎng)絡(luò),包括Illumination-Net、Fusion-Net 和 Restoration-Net,以進(jìn)一步提高性能。任等人。[12] 設(shè)計(jì)了一個(gè)更復(fù)雜的端到端網(wǎng)絡(luò),包括用于圖像內(nèi)容增強(qiáng)的編碼器-解碼器網(wǎng)絡(luò)和用于圖像邊緣增強(qiáng)的循環(huán)神經(jīng)網(wǎng)絡(luò)。與 [12] 類似,Zhu 等人。[16] 提出了一種稱為 EEMEFN的方法。EEMEFN包括兩個(gè)階段:多曝光融合和邊緣增強(qiáng)。為 LLIE 提出了一種多曝光融合網(wǎng)絡(luò) TBEFN[20]。TBEFN在兩個(gè)分支中估計(jì)一個(gè)傳遞函數(shù),可以得到兩個(gè)增強(qiáng)結(jié)果。最后,采用簡(jiǎn)單的平均方案來(lái)融合這兩個(gè)圖像,并通過(guò)細(xì)化單元進(jìn)一步細(xì)化結(jié)果。此外,在 LLIE 中引入了金字塔網(wǎng)絡(luò)(LPNet) [18]、殘差網(wǎng)絡(luò) [19] 和拉普拉斯金字塔 [21](DSLR)。這些方法通過(guò) LLIE 常用的端到端網(wǎng)絡(luò)結(jié)構(gòu)學(xué)習(xí)有效和高效地集成特征表示。最近,基于觀察到噪聲在不同頻率層中表現(xiàn)出不同程度的對(duì)比度,Xu 等人。[50] 提出了一種基于頻率的分解和增強(qiáng)網(wǎng)絡(luò)。該網(wǎng)絡(luò)在低頻層通過(guò)噪聲抑制恢復(fù)圖像內(nèi)容,同時(shí)在高頻層推斷細(xì)節(jié)。
與在端到端網(wǎng)絡(luò)中直接學(xué)習(xí)增強(qiáng)結(jié)果相比,由于物理上可解釋的Retinex 理論 [51]、[52],基于深度Retinex 的方法在大多數(shù)情況下享有更好的增強(qiáng)性能。基于深度視網(wǎng)膜的方法通常通過(guò)專門的子網(wǎng)絡(luò)分別增強(qiáng) il 亮度分量和反射率分量。在 [4] 中提出了一個(gè)Retinex-Net。Retinex-Net 包括一個(gè)Decom-Net,它將輸入圖像拆分為與光無(wú)關(guān)的反射率和結(jié)構(gòu)感知平滑照明,以及一個(gè)調(diào)整照明圖以進(jìn)行低光增強(qiáng)的Enhance-Net。為了減少計(jì)算負(fù)擔(dān),Li 等人。[5] 提出了一種用于弱光照?qǐng)D像增強(qiáng)的輕量級(jí)LightenNet,它僅由四層組成。LightenNet 將弱光照?qǐng)D像作為輸入,然后估計(jì)其光照?qǐng)D。基于Retinex理論[51]、[52],通過(guò)將光照?qǐng)D除以輸入圖像得到增強(qiáng)圖像。為了準(zhǔn)確估計(jì)光照?qǐng)D,Wang 等人。[53] 通過(guò)他們提出的DeepUPE 網(wǎng)絡(luò)提取全局和局部特征以學(xué)習(xí)圖像到照明的映射。張等人。[11] 分別開(kāi)發(fā)了三個(gè)子網(wǎng)絡(luò),用于層分解、反射率恢復(fù)和光照調(diào)整,稱為 KinD。此外,作者通過(guò)多尺度照明注意模塊減輕了 KinD[11] 結(jié)果中留下的視覺(jué)缺陷。改進(jìn)后的 KinD 稱為 KinD++[54]。為了解決基于深度Retinex 的方法中忽略噪聲的問(wèn)題,Wang 等人。[10] 提出了一種漸進(jìn)式Retinex 網(wǎng)絡(luò),其中 IM-Net估計(jì)光照,NM-Net 估計(jì)噪聲水平。這兩個(gè)子網(wǎng)絡(luò)以漸進(jìn)的機(jī)制工作,直到獲得穩(wěn)定的結(jié)果。范等人。[14] 集成語(yǔ)義分割和Retinex 模型,以進(jìn)一步提高實(shí)際案例中的增強(qiáng)性能。核心思想是使用語(yǔ)義先驗(yàn)來(lái)指導(dǎo)照明分量和反射分量的增強(qiáng)。
盡管上述方法可以獲得不錯(cuò)的性能,但由于使用了合成訓(xùn)練數(shù)據(jù),它們?cè)谡鎸?shí)的低光照情況下表現(xiàn)出較差的泛化能力。為了解決這個(gè)問(wèn)題,一些方法試圖生成更真實(shí)的訓(xùn)練數(shù)據(jù)或捕獲真實(shí)數(shù)據(jù)。蔡等人。[6]構(gòu)建了一個(gè)多曝光圖像數(shù)據(jù)集,其中不同曝光水平的低對(duì)比度圖像有其對(duì)應(yīng)的高質(zhì)量參考圖像。每個(gè)高質(zhì)量的參考圖像都是通過(guò)從不同方法增強(qiáng)的 13 個(gè)結(jié)果中主觀選擇最佳輸出而獲得的。此外,在構(gòu)建的數(shù)據(jù)集上訓(xùn)練頻率分解網(wǎng)絡(luò),并通過(guò)兩階段結(jié)構(gòu)分別增強(qiáng)高頻層和低頻層。陳等人。[2] 收集一個(gè)真實(shí)的低光圖像數(shù)據(jù)集 (SID) 并訓(xùn)練 U-Net[55] 以學(xué)習(xí)從低光原始數(shù)據(jù)到 sRGB 空間中相應(yīng)的長(zhǎng)曝光高質(zhì)量參考圖像的映射。此外,陳等人。[8] 將 SID 數(shù)據(jù)集擴(kuò)展到低光視頻 (DRV)。DRV 包含具有相應(yīng)長(zhǎng)時(shí)間曝光基本事實(shí)的靜態(tài)視頻。為了保證處理動(dòng)態(tài)場(chǎng)景視頻的泛化能力,提出了一種孿生網(wǎng)絡(luò)。為了增強(qiáng)黑暗中的運(yùn)動(dòng)物體,Jiang 和 Zheng[9] 設(shè)計(jì)了一個(gè)同軸光學(xué)系統(tǒng)來(lái)捕獲時(shí)間同步和空間對(duì)齊的低光和高光視頻對(duì)(SMOID)。與 DRV 視頻數(shù)據(jù)集 [8] 不同,SMOID 視頻數(shù)據(jù)集包含動(dòng)態(tài)場(chǎng)景。為了在 sRGB 空間中學(xué)習(xí)從原始低光視頻到高光視頻的映射,提出了一種基于 3DU-Net 的網(wǎng)絡(luò)。考慮到以前的低光視頻數(shù)據(jù)集的局限性,例如 DRV 數(shù)據(jù)集 [8] 僅包含統(tǒng)計(jì)視頻和 SMOID 數(shù)據(jù)集 [9] 僅具有 179 個(gè)視頻對(duì),Triantafyllidou等人。[17] 提出了一種低光視頻合成管道,稱為 SIDGAN。SIDGAN可以通過(guò)具有中間域映射的半監(jiān)督雙CycleGAN 生成動(dòng)態(tài)視頻數(shù)據(jù)(RAW-to-RGB)。為了訓(xùn)練這個(gè)管道,從Vimeo-90K 數(shù)據(jù)集 [56] 中收集了真實(shí)世界的視頻。低光原始視頻數(shù)據(jù)和相應(yīng)的長(zhǎng)曝光圖像是從 DRV 數(shù)據(jù)集 [8] 中采樣的。利用合成的訓(xùn)練數(shù)據(jù),這項(xiàng)工作采用與 [2] 相同的 U-Net 網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行低光視頻增強(qiáng)。
強(qiáng)化學(xué)習(xí)。在沒(méi)有配對(duì)訓(xùn)練數(shù)據(jù)的情況下,Yu 等人。[22] 通過(guò)強(qiáng)化對(duì)抗學(xué)習(xí)來(lái)學(xué)習(xí)曝光照片,命名為 DeepExposure。具體地,首先根據(jù)曝光將輸入圖像分割成子圖像。對(duì)于每個(gè)子圖像,策略網(wǎng)絡(luò)基于強(qiáng)化學(xué)習(xí)順序?qū)W習(xí)局部曝光。獎(jiǎng)勵(lì)評(píng)估函數(shù)通過(guò)對(duì)抗學(xué)習(xí)來(lái)近似。最后,利用每次局部曝光對(duì)輸入進(jìn)行修飾,從而獲得不同曝光下的多張修飾圖像。最終的結(jié)果是通過(guò)融合這些圖像來(lái)實(shí)現(xiàn)的。
無(wú)監(jiān)督學(xué)習(xí)。在配對(duì)數(shù)據(jù)上訓(xùn)練深度模型可能會(huì)導(dǎo)致過(guò)度擬合和泛化能力有限。為了解決這個(gè)問(wèn)題,在 [23] 中提出了一種名為EnligthenGAN 的無(wú)監(jiān)督學(xué)習(xí)方法。EnlightenGAN 采用注意力引導(dǎo)的 U-Net[55] 作為生成器,并使用全局-局部鑒別器來(lái)確保增強(qiáng)的結(jié)果看起來(lái)像真實(shí)的正常光圖像。除了全局和局部對(duì)抗性損失外,還提出了全局和局部自特征保持損失來(lái)保留增強(qiáng)前后的圖像內(nèi)容。這是穩(wěn)定訓(xùn)練這種單路徑生成對(duì)抗網(wǎng)絡(luò)(GAN)結(jié)構(gòu)的關(guān)鍵點(diǎn)
Zero-shot Learning。監(jiān)督學(xué)習(xí)、強(qiáng)化學(xué)習(xí)和無(wú)監(jiān)督學(xué)習(xí)方法要么泛化能力有限,要么訓(xùn)練不穩(wěn)定。為了解決這些問(wèn)題,提出了零樣本學(xué)習(xí)來(lái)僅從測(cè)試圖像中學(xué)習(xí)增強(qiáng)。注意,低層視覺(jué)任務(wù)中的零樣本學(xué)習(xí)概念是用來(lái)強(qiáng)調(diào)該方法不需要配對(duì)或非配對(duì)的訓(xùn)練數(shù)據(jù),這與它在高層視覺(jué)任務(wù)中的定義不同。張等人。[24] 提出了一種零樣本學(xué)習(xí)方法,稱為 ExCNet,用于背光圖像恢復(fù)。首先使用一個(gè)網(wǎng)絡(luò)來(lái)估計(jì)最適合輸入背光圖像的 S 曲線。一旦估計(jì)了 S 曲線,輸入圖像就會(huì)使用引導(dǎo)濾波器 [57] 分為基礎(chǔ)層和細(xì)節(jié)層。然后通過(guò)估計(jì)的 S 曲線調(diào)整基礎(chǔ)層。最后,Webercontrast [58] 用于融合細(xì)節(jié)層和調(diào)整后的基礎(chǔ)層。為了訓(xùn)練 ExCNet,作者將損失函數(shù)表述為基于塊的能量最小化問(wèn)題。朱等人。[26] 提出了一個(gè)三分支 CNN,稱為 RRDNet,用于恢復(fù)曝光不足的圖像。RRDNet通過(guò)迭代最小化專門設(shè)計(jì)的損失函數(shù)將輸入圖像分解為照明、反射和噪聲。為了驅(qū)動(dòng)零樣本學(xué)習(xí),提出了結(jié)合視網(wǎng)膜重構(gòu)損失、紋理增強(qiáng)損失和光照引導(dǎo)噪聲估計(jì)損失的方法。與基于圖像重建的方法 [1]、[3]、[4]、[11]、[12]、[21]、[54] 不同,在 [25] 中提出了一種深度曲線估計(jì)網(wǎng)絡(luò)零 DCE ]。Zero-DCE 將光增強(qiáng)制定為圖像特定曲線估計(jì)的任務(wù),它將低光圖像作為輸入并產(chǎn)生高階曲線作為其輸出。這些曲線用于對(duì)輸入的動(dòng)態(tài)范圍進(jìn)行逐像素調(diào)整,以獲得增強(qiáng)的圖像。此外,還提出了一種加速和輕型版本,稱為Zero-DCE++ [59]。這種基于曲線的方法在訓(xùn)練期間不需要任何配對(duì)或非配對(duì)數(shù)據(jù)。他們通過(guò)一組非參考損失函數(shù)實(shí)現(xiàn)零參考學(xué)習(xí)。此外,與需要大量計(jì)算資源的基于圖像重建的方法不同,圖像到曲線的映射只需要輕量級(jí)網(wǎng)絡(luò),從而實(shí)現(xiàn)快速的推理速度。半監(jiān)督學(xué)習(xí)。為了結(jié)合監(jiān)督學(xué)習(xí)和無(wú)監(jiān)督學(xué)習(xí)的優(yōu)勢(shì),近年來(lái)提出了半監(jiān)督學(xué)習(xí)。楊等人。[27]提出了一種半監(jiān)督深度遞歸帶網(wǎng)絡(luò)(DRBN)。DRBN首先在監(jiān)督學(xué)習(xí)下恢復(fù)增強(qiáng)圖像的線性波段表示,然后通過(guò)基于無(wú)監(jiān)督對(duì)抗學(xué)習(xí)的可學(xué)習(xí)線性變換重新組合給定波段來(lái)獲得改進(jìn)的波段表示
觀察圖 3(a),我們可以發(fā)現(xiàn)監(jiān)督學(xué)習(xí)是基于深度學(xué)習(xí)的 LLIE 方法中的主流。比例達(dá)到77%。這是因?yàn)楫?dāng) LOL[4]、SID [2]和各種低光/正常光圖像合成方法等配對(duì)訓(xùn)練數(shù)據(jù)公開(kāi)可用時(shí),監(jiān)督學(xué)習(xí)相對(duì)容易。然而,基于監(jiān)督學(xué)習(xí)的方法面臨一些挑戰(zhàn):1) 收集涵蓋各種現(xiàn)實(shí)世界弱光條件的大規(guī)模配對(duì)數(shù)據(jù)集是困難的,2) 合成的弱光圖像不能準(zhǔn)確地表示現(xiàn)實(shí)世界的照度諸如空間變化的照明和不同級(jí)別的噪聲等條件,以及 3) 在配對(duì)數(shù)據(jù)上訓(xùn)練深度模型可能會(huì)導(dǎo)致對(duì)具有不同照明屬性的真實(shí)世界圖像的過(guò)度擬合和有限泛化
因此,一些方法采用無(wú)監(jiān)督學(xué)習(xí)、強(qiáng)化學(xué)習(xí)、半監(jiān)督學(xué)習(xí)和零樣本學(xué)習(xí)來(lái)繞過(guò)監(jiān)督學(xué)習(xí)中的挑戰(zhàn)。盡管這些方法實(shí)現(xiàn)了競(jìng)爭(zhēng)性能,但它們?nèi)匀淮嬖谝恍┚窒扌裕?)對(duì)于無(wú)監(jiān)督學(xué)習(xí)/半監(jiān)督學(xué)習(xí)方法,如何實(shí)現(xiàn)穩(wěn)定的訓(xùn)練、避免顏色偏差以及建立跨域信息的關(guān)系對(duì)當(dāng)前的方法提出了挑戰(zhàn) , 2) 對(duì)于強(qiáng)化學(xué)習(xí)方法,設(shè)計(jì)有效的獎(jiǎng)勵(lì)機(jī)制和實(shí)施高效穩(wěn)定的訓(xùn)練是錯(cuò)綜復(fù)雜的,以及 3) 對(duì)于零樣本學(xué)習(xí)方法,非參考損失的設(shè)計(jì)在保色、去除偽影時(shí)非常重要,并且應(yīng)該考慮梯度反向傳播。
3TECHNICAL REVIEW AND DISCUSSION
在本節(jié)中,我們首先總結(jié)表 1 中具有代表性的基于深度學(xué)習(xí)的 LLIE 方法,然后分析和討論它們的技術(shù)特點(diǎn)。
表1:基于深度學(xué)習(xí)的代表性方法的基本特征總結(jié),包括學(xué)習(xí)策略、網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)、訓(xùn)練數(shù)據(jù)集、測(cè)試數(shù)據(jù)集、評(píng)估指標(biāo)、輸入數(shù)據(jù)格式以及模型是否基于Retinex。“simulated”是指通過(guò)與合成訓(xùn)練數(shù)據(jù)相同的方法模擬測(cè)試數(shù)據(jù)。“self-selected”代表作者選擇的真實(shí)世界圖像。“#P”表示可訓(xùn)練參數(shù)的數(shù)量。“-”表示該項(xiàng)目不可用或未在論文中注明。
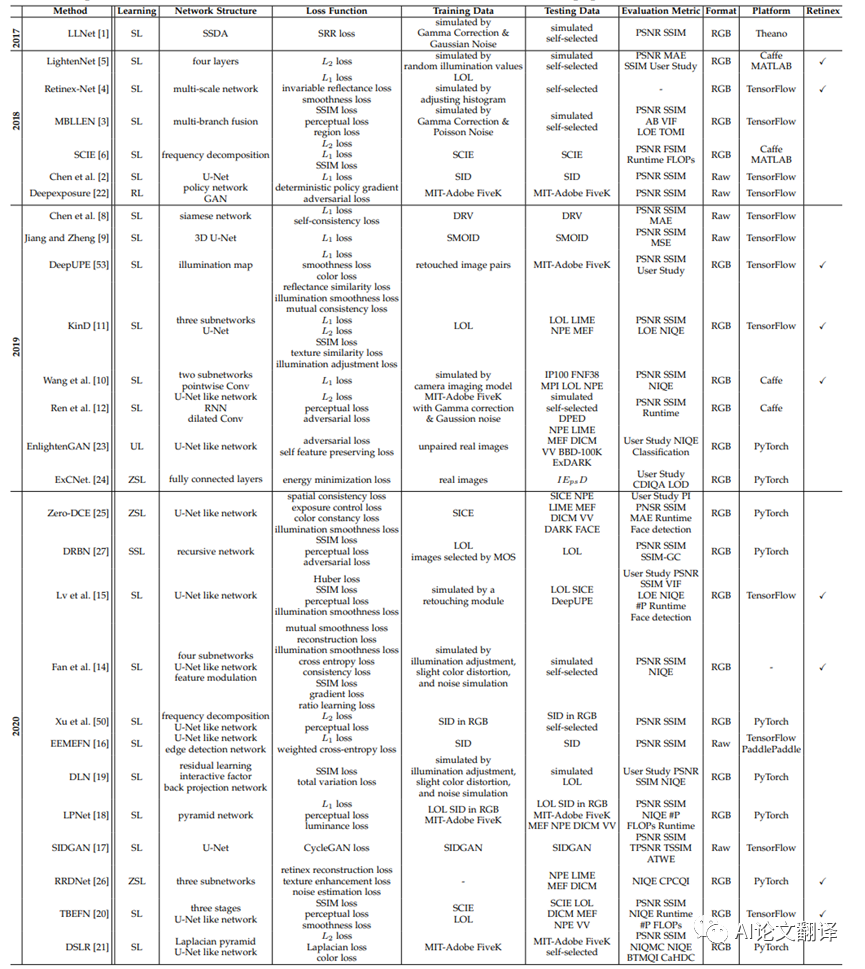
3.1 Network Structure
現(xiàn)有模型中使用了多種網(wǎng)絡(luò)結(jié)構(gòu)和設(shè)計(jì),從基本的 U-Net、金字塔網(wǎng)絡(luò)、多級(jí)網(wǎng)絡(luò)到頻率分解網(wǎng)絡(luò)。分析圖3(b)可以看出,LLIE中主要采用U-Net和類U-Net網(wǎng)絡(luò)。這是因?yàn)?U-Net 可以有效地集成多尺度特征,并同時(shí)使用低級(jí)和高級(jí)特征。這些特性對(duì)于實(shí)現(xiàn)令人滿意的低光增強(qiáng)是必不可少的。
然而,在當(dāng)前的 LLIE 網(wǎng)絡(luò)結(jié)構(gòu)中可能會(huì)忽略一些關(guān)鍵問(wèn)題:
1)在經(jīng)過(guò)幾個(gè)卷積層后,由于其像素值較小,極低光圖像的梯度在梯度反向傳播過(guò)程中可能會(huì)消失,這會(huì)降低增強(qiáng)性能并影響網(wǎng)絡(luò)訓(xùn)練的收斂性。
2)類 U-Net 的網(wǎng)絡(luò)中使用的跳躍連接可能會(huì)在最終結(jié)果中引入噪聲和冗余特征。應(yīng)該仔細(xì)考慮如何有效濾除噪聲并融合低級(jí)和高級(jí)特征。
3)雖然為 LLIE 提出了一些設(shè)計(jì)和組件,但大部分都是從相關(guān)的低級(jí)視覺(jué)任務(wù)中借用或修改的。在設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)時(shí)應(yīng)考慮低光數(shù)據(jù)的特性。
3.2 Combination of Deep Model and Retinex Theory
如圖 3(c) 所示,幾乎 1/3 的方法將深度網(wǎng)絡(luò)的設(shè)計(jì)與Retinex 理論相結(jié)合,例如,設(shè)計(jì)不同的子網(wǎng)絡(luò)來(lái)估計(jì)Retinex 模型的組件,并估計(jì)光照?qǐng)D來(lái)指導(dǎo)學(xué)習(xí)網(wǎng)絡(luò)。盡管這種組合可以建立基于深度學(xué)習(xí)和基于模型的方法之間的聯(lián)系,但它們各自的弱點(diǎn)可能會(huì)引入最終模型中:1)反射率是基于Retinex 的 LLIE 方法中使用的最終增強(qiáng)結(jié)果的理想假設(shè)仍然會(huì)影響最終結(jié)果,以及 2)盡管引入了Retinex 理論,但深度網(wǎng)絡(luò)中過(guò)度擬合的風(fēng)險(xiǎn)仍然存在。因此,當(dāng)研究人員將深度學(xué)習(xí)與Retinex 理論相結(jié)合時(shí),應(yīng)該仔細(xì)考慮如何取其精華,去其糟粕。
3.3 Data Format
如圖 3(d) 所示,原始數(shù)據(jù)格式Raw在大多數(shù)方法中占主導(dǎo)地位。盡管原始數(shù)據(jù)僅限于特定傳感器,例如基于拜耳模式的傳感器,但數(shù)據(jù)涵蓋更廣的色域和更高的動(dòng)態(tài)范圍。因此,在原始數(shù)據(jù)上訓(xùn)練的深度模型通常可以恢復(fù)清晰的細(xì)節(jié)和高對(duì)比度,獲得鮮艷的色彩,減少噪聲和偽影的影響,并提高極低光圖像的亮度。盡管如此,RGB 格式也用于某些方法,因?yàn)樗ǔJ侵悄苁謾C(jī)相機(jī)、Go-Pro 相機(jī)和無(wú)人機(jī)相機(jī)產(chǎn)生的最終圖像形式。在未來(lái)的研究中,從不同模式的原始數(shù)據(jù)到RGB格式的平滑轉(zhuǎn)換將有可能結(jié)合RGB數(shù)據(jù)的便利性和LLIE對(duì)原始數(shù)據(jù)的高質(zhì)量增強(qiáng)的優(yōu)勢(shì)。
3.4 Loss Function
在圖3(e)中,LLIE模型中常用的損失函數(shù)包括重建損失(L1、L2、SSIM)、感知損失和平滑損失。此外,根據(jù)不同的需求和策略,還采用了顏色損失、曝光損失和對(duì)抗損失。我們將代表性損失函數(shù)詳述如下。
重建損失(ReconstructionLoss)。常用的 L1、L2 和 SSIM 損失可以表示為:
其中和分別代表ground truth和增強(qiáng)結(jié)果,、和分別是輸入圖像的高度、寬度和通道。均值和方差分別由和表示。根據(jù) SSIM 損失 [60] 中的默認(rèn)值,將常數(shù)和設(shè)置為 0.02 和 0.03。不同的重建損失有其優(yōu)點(diǎn)和缺點(diǎn)。損失傾向于懲罰較大的錯(cuò)誤,但可以容忍小錯(cuò)誤。損失可以很好地保留顏色和亮度,因?yàn)闊o(wú)論局部結(jié)構(gòu)如何,都會(huì)對(duì)誤差進(jìn)行同等加權(quán)。損失很好地保留了結(jié)構(gòu)和紋理。詳細(xì)分析見(jiàn)[61]。
感知損失。[62]提出了感知損失來(lái)限制與特征空間中的基本事實(shí)相似的結(jié)果。損失提高了結(jié)果的視覺(jué)質(zhì)量。它被定義為增強(qiáng)結(jié)果的特征表示與對(duì)應(yīng)的ground-truth的特征表示之間的歐幾里得距離。特征表示通常是從在ImageNet 數(shù)據(jù)集 [64] 上預(yù)訓(xùn)練的 VGG 網(wǎng)絡(luò) [63] 中提取的。感知損失可以表示為:
其中、和分別是特征圖的高度、寬度和通道數(shù)。函數(shù)表示從 VGG 網(wǎng)絡(luò)的第個(gè)卷積層(在 ReLU 激活之后)提取的特征表示。
平滑度損失。為了去除增強(qiáng)結(jié)果中的噪聲或保留相鄰像素的關(guān)系,通常使用平滑損失(TV loss)來(lái)約束增強(qiáng)結(jié)果或估計(jì)的光照?qǐng)D,可以表示為:
其中和分別是水平和垂直梯度操作。
對(duì)抗性損失
。為了鼓勵(lì)增強(qiáng)的結(jié)果與參考圖像區(qū)分開(kāi)來(lái),對(duì)抗性學(xué)習(xí)解決了以下優(yōu)化問(wèn)題:其中生成器試圖生成“假”圖像來(lái)欺騙鑒別器。鑒別器試圖將“假”圖像與參考圖像區(qū)分開(kāi)來(lái)。輸入是從源流形中采樣的,而是從目標(biāo)流形中采樣的任意參考圖像。為了優(yōu)化生成器,應(yīng)該最小化這個(gè)損失函數(shù):其中輸出增強(qiáng)的結(jié)果。為了優(yōu)化鑒別器,這個(gè)損失函數(shù)被最小化:
曝光損失。作為基于的方法中的關(guān)鍵損失函數(shù)之一,曝光損失衡量了在沒(méi)有配對(duì)或未配對(duì)圖像作為參考圖像的情況下增強(qiáng)結(jié)果的曝光水平,可以表示為:
其中M是固定大小(默認(rèn)為16×16)的非重疊區(qū)域的數(shù)量,Y是增強(qiáng)結(jié)果中區(qū)域的平均強(qiáng)度值。
LLIE 網(wǎng)絡(luò)中常用的損失函數(shù),如 L1、L2、SSIM、感知損失,也用于圖像重建網(wǎng)絡(luò)中,用于圖像超分辨率 [65]、圖像去噪 [66]、圖像去訓(xùn)練(Imagedetraining) [67]、[68 ]和圖像去模糊[69]。與這些通用損失不同,為 LLIE 專門設(shè)計(jì)的曝光損失激發(fā)了非參考損失的設(shè)計(jì)。非參考損失不依賴參考圖像,從而使模型具有更好的泛化能力。在設(shè)計(jì)損失函數(shù)時(shí)考慮圖像特征是一項(xiàng)正在進(jìn)行的研究。
3.5 Training Datasets
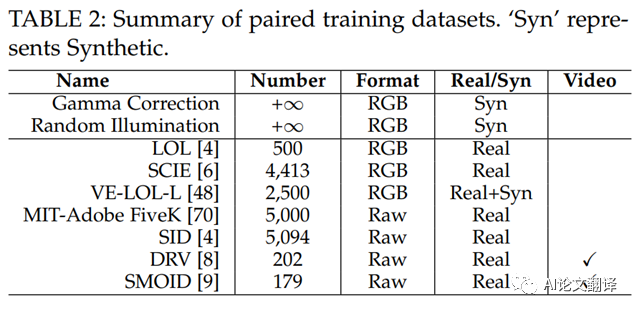
圖 3(f) 報(bào)告了使用各種配對(duì)訓(xùn)練數(shù)據(jù)集來(lái)訓(xùn)練低光增強(qiáng)網(wǎng)絡(luò)。這些數(shù)據(jù)集包括真實(shí)世界捕獲的數(shù)據(jù)集和合成數(shù)據(jù)集。我們將它們列在表 2 中,并詳細(xì)介紹如下。
Gamma 校正模擬
。由于其非線性和簡(jiǎn)單性,伽瑪校正用于調(diào)整視頻或靜止圖像系統(tǒng)中的亮度或三色值。它由冪律表達(dá)式定義。
其中輸入 和輸出通常在 [0,1] 范圍內(nèi)。通常情況下,常數(shù)設(shè)置為 1。功率 控制輸出的亮度。直觀地說(shuō),輸入在<1時(shí)變亮, ??>1時(shí)變暗。輸入可以是圖像的三個(gè) RGB 通道,也可以是與亮度相關(guān)的通道,例如 CIELab顏色空間中的 通道和 顏色空間中的 通道。使用校正調(diào)整亮度相關(guān)通道后,顏色空間中的相應(yīng)通道按等比例調(diào)整,以避免產(chǎn)生偽影和顏色偏差。
為了模擬在真實(shí)世界的低光照?qǐng)鼍爸信臄z的圖像,將高斯噪聲、泊松噪聲或真實(shí)噪聲添加到 校正圖像中。使用 校正合成的低光圖像可以表示為:
其中代表噪聲模型,代表值的校正函數(shù),是正常光和高質(zhì)量圖像或亮度相關(guān)通道。雖然該函數(shù)通過(guò)改變 值來(lái)產(chǎn)生不同光照水平的微光圖像,但由于非線性調(diào)整,它往往會(huì)在合成的微光圖像中引入偽影和顏色偏差。
隨機(jī)照明模擬
。根據(jù)Retinex 模型,圖像可以分解為反射分量和光照分量。基于圖像內(nèi)容與光照分量無(wú)關(guān)且光照分量中的局部區(qū)域具有相同強(qiáng)度的假設(shè),可以通過(guò)下式獲得弱光圖像。其中是范圍內(nèi)的隨機(jī)光照值。可以將噪聲添加到合成圖像中。這種線性函數(shù)避免了偽影,但強(qiáng)假設(shè)要求合成僅在局部區(qū)域具有相同亮度的圖像塊上運(yùn)行。由于上下文信息的疏忽,在此類圖像塊上訓(xùn)練的深度模型可能會(huì)導(dǎo)致次優(yōu)性能。
LOL。LOL[4] 是第一個(gè)在真實(shí)場(chǎng)景中拍攝的配對(duì)低光/正常光圖像數(shù)據(jù)集。通過(guò)改變曝光時(shí)間和 ISO 來(lái)收集低光圖像。LOL 包含 500 對(duì)以 RGB 格式保存的大小為400×600 的低光/正常光圖像。
SCIE。SCIE 是低對(duì)比度和良好對(duì)比度圖像對(duì)的多曝光圖像數(shù)據(jù)集。它包括 589 個(gè)室內(nèi)和室外場(chǎng)景的多重曝光序列。每個(gè)序列有3到18張不同曝光級(jí)別的低對(duì)比度圖像,因此總共包含4,413張多重曝光圖像。589張高質(zhì)量的參考圖像是從13種具有代表性的增強(qiáng)算法的結(jié)果中選擇得到的。即許多多重曝光圖像具有相同的高對(duì)比度參考圖像。圖像分辨率介于3,000×2,000 和6,000×4,000 之間。SCIE 中的圖像以 RGB 格式保存。
MIT-Adobe FiveK。MIT-Adobe FiveK [70] 被收集用于全局色調(diào)調(diào)整,但已用于 LLIE。這是因?yàn)檩斎雸D像具有低光和低對(duì)比度。MIT-Adobe FiveK 包含 5,000 張圖像,每張圖像都由 5 位訓(xùn)練有素的攝影師進(jìn)行美化,以呈現(xiàn)視覺(jué)上令人愉悅的效果,類似于明信片。因此,每個(gè)輸入都有五個(gè)修飾結(jié)果。通常,專家C的結(jié)果在訓(xùn)練階段被用作地面ground-truth圖像。圖片都是Raw原始格式。要訓(xùn)練能夠處理 RGB 格式圖像的網(wǎng)絡(luò),需要使用 AdobeLightroom 對(duì)圖像進(jìn)行預(yù)處理,并按照此過(guò)程將其保存為 RGB 格式。圖像通常被調(diào)整為長(zhǎng)邊為500像素的大小。
SID。SID[2] 包含 5,094 張?jiān)级唐毓鈭D像,每張圖像都有對(duì)應(yīng)的長(zhǎng)曝光參考圖像。不同的長(zhǎng)曝光參考圖像的數(shù)量為424。換句話說(shuō),多個(gè)短曝光圖像對(duì)應(yīng)于相同的長(zhǎng)曝光參考圖像。這些圖像是在室內(nèi)和室外場(chǎng)景中使用兩臺(tái)相機(jī)拍攝的:索尼 α7S II和富士 X-T2。因此,圖像具有不同的傳感器模式(索尼相機(jī)的拜耳傳感器和富士相機(jī)的 APS-CX-Trans 傳感器)。索尼的分辨率為4,240×2,832,富士的分辨率為6,000×4,000。通常,長(zhǎng)曝光圖像由 libraw(一個(gè)原始圖像處理庫(kù))處理并保存在 sRGB 顏色空間中,并隨機(jī)裁剪512×512 塊進(jìn)行訓(xùn)練。
VE-LOL。VE-LOL[48] 包含兩個(gè)子集:用于訓(xùn)練和評(píng)估 LLIE 方法的配對(duì) VE-LOLL 和用于評(píng)估 LLIE 方法對(duì)人臉檢測(cè)效果的未配對(duì)VE-LOL-H。具體來(lái)說(shuō),VE-LOLL 包括 2,500 個(gè)配對(duì)圖像。其中,1000雙是合成的,1500雙是真實(shí)的。VE-LOL-H 包括 10,940張未配對(duì)的圖像,其中人臉是用邊界框手動(dòng)注釋的。
DRV。DRV[8] 包含 202 個(gè)靜態(tài)原始視頻,每個(gè)視頻都有一個(gè)對(duì)應(yīng)的長(zhǎng)曝光ground-truth。每個(gè)視頻在連續(xù)拍攝模式下以每秒大約 16 到 18 幀的速度拍攝,最多可拍攝 110 幀。這些圖像由索尼 RX100VI 相機(jī)在室內(nèi)和室外場(chǎng)景中拍攝,因此全部采用 BayerRaw 格式。分辨率為3,672×5,496。
SMOID。SMOID[9] 包含 179 對(duì)由同軸光學(xué)系統(tǒng)拍攝的視頻,每對(duì)有 200 幀。因此,SMOID 包括 35,800個(gè)極低光BayerRaw 圖像及其相應(yīng)的光照良好的 RGB 計(jì)數(shù)器。SMOID 中的視頻由不同光照條件下的移動(dòng)車輛和行人組成。
一些問(wèn)題對(duì)上述配對(duì)訓(xùn)練數(shù)據(jù)集提出了挑戰(zhàn):1)由于合成數(shù)據(jù)和真實(shí)數(shù)據(jù)之間的差距,在合成數(shù)據(jù)上訓(xùn)練的深度模型在處理真實(shí)世界的圖像和視頻時(shí)可能會(huì)引入偽影和顏色偏差,2)數(shù)據(jù)的規(guī)模和多樣性,真實(shí)的訓(xùn)練數(shù)據(jù)不能令人滿意,因此一些方法會(huì)結(jié)合合成數(shù)據(jù)來(lái)增加訓(xùn)練數(shù)據(jù)。這可能會(huì)導(dǎo)致次優(yōu)增強(qiáng),并且 3) 輸入圖像和相應(yīng)的 ground-truth可能會(huì)由于運(yùn)動(dòng)、硬件和環(huán)境的影響而存在錯(cuò)位。這將影響使用逐像素?fù)p失函數(shù)訓(xùn)練的深度網(wǎng)絡(luò)的性能。
3.6 Testing Datasets
除了成對(duì)數(shù)據(jù)集[2]、[4]、[6]、[8]、[9]、[48]、[70]中的測(cè)試子集外,還有一些從相關(guān)工作中收集或常見(jiàn)的測(cè)試數(shù)據(jù)用于實(shí)驗(yàn)比較。它們是從 LIME[32]、NPE[30]、MEF[71]、DICM[72] 和 VV2 收集的。此外,一些數(shù)據(jù)集,如黑暗中的人臉檢測(cè)[73]和低光圖像中的檢測(cè)和識(shí)別[74]被用來(lái)測(cè)試LLIE對(duì)高級(jí)視覺(jué)任務(wù)的影響。我們總結(jié)了表 3 中常用的測(cè)試數(shù)據(jù)集,并介紹了具有代表性的測(cè)試數(shù)據(jù)集如下。
BBD-100K。
BBD-100K [75] 是最大的駕駛視頻數(shù)據(jù)集,包含 10,000個(gè)視頻,涵蓋一天中許多不同時(shí)間、天氣條件和駕駛場(chǎng)景的 1,100 小時(shí)駕駛體驗(yàn),以及 10 個(gè)任務(wù)注釋。在 BBD-100K夜間拍攝的視頻用于驗(yàn)證 LLIE 對(duì)高級(jí)視覺(jué)任務(wù)的影響以及在真實(shí)場(chǎng)景中的增強(qiáng)性能。
ExDARK。
ExDARK[74] 數(shù)據(jù)集是為低光圖像中的對(duì)象檢測(cè)和識(shí)別而構(gòu)建的。 ExDARK數(shù)據(jù)集包含 7,363 張從極低光環(huán)境到暮光環(huán)境的低光圖像,其中包含 12 個(gè)對(duì)象類,并使用圖像類標(biāo)簽和局部對(duì)象邊界框進(jìn)行注釋。黑臉。 DARKFACE [73] 數(shù)據(jù)集包含 6,000 張夜間室外場(chǎng)景中拍攝的低光圖像,每張圖像都標(biāo)有人臉邊界框。從圖 3(g) 中,我們可以觀察到人們更喜歡在實(shí)驗(yàn)中使用自己收集的測(cè)試數(shù)據(jù)。主要原因有三點(diǎn):1)除了成對(duì)數(shù)據(jù)集的測(cè)試劃分,沒(méi)有公認(rèn)的評(píng)估基準(zhǔn),2)常用的測(cè)試集存在規(guī)模小(部分測(cè)試集僅包含10張圖像)等缺點(diǎn) )、重復(fù)的內(nèi)容和光照特性,以及未知的實(shí)驗(yàn)設(shè)置,以及 3) 一些常用的測(cè)試數(shù)據(jù)最初不是為了評(píng)估 LLIE 而收集的。一般來(lái)說(shuō),當(dāng)前的測(cè)試數(shù)據(jù)集可能會(huì)導(dǎo)致偏差和不公平的比較。
3.7 Evaluation Metrics
除了基于人類感知的主觀評(píng)估外,圖像質(zhì)量評(píng)估 (IQA) 指標(biāo),包括完全參考和非參考 IQA 指標(biāo),能夠客觀地評(píng)估圖像質(zhì)量。此外,用戶研究、可訓(xùn)練參數(shù)的數(shù)量、FLOP、運(yùn)行時(shí)和基于應(yīng)用程序的評(píng)估也反映了 LLIE 模型的性能,如圖 3(h) 所示。我們將詳細(xì)介紹它們?nèi)缦隆?/p>
PSNR 和 MSE
。 PSNR 和 MSE 是低級(jí)視覺(jué)任務(wù)中廣泛使用的 IQA 指標(biāo)。它們總是非負(fù)的,更接近無(wú)限(PSNR)和零(MSE)的值更好。然而,像素級(jí) PSNR 和 MSE 可能無(wú)法準(zhǔn)確地指示圖像質(zhì)量的視覺(jué)感知,因?yàn)樗鼈兒雎粤讼噜徬袼氐年P(guān)系。
MAE
。 MAE 表示平均絕對(duì)誤差,作為成對(duì)觀測(cè)值之間誤差的度量。 MAE值越小,相似度越高。
SSIM
。 SSIM 用于衡量?jī)煞鶊D像之間的相似度。它是一種基于感知的模型,將圖像退化視為結(jié)構(gòu)信息的感知變化。值為1只有在兩組相同數(shù)據(jù)的情況下才能達(dá)到,表明結(jié)構(gòu)相似。
LOE
。 LOE 表示反映增強(qiáng)圖像自然度的亮度順序誤差。對(duì)于 LOE,LOE 值越小,亮度順序保持得越好。應(yīng)用。除了提高視覺(jué)質(zhì)量外,圖像增強(qiáng)的目的之一是服務(wù)于高級(jí)視覺(jué)任務(wù)。因此,LLIE 對(duì)高級(jí)視覺(jué)應(yīng)用程序的影響通常被檢查以驗(yàn)證不同方法的性能。目前在 LLIE 中使用的評(píng)估方法需要在幾個(gè)方面進(jìn)行改進(jìn):1)雖然 PSNR、MSE、MAE 和 SSIM 是經(jīng)典和流行的指標(biāo),但它們距離捕捉人類的真實(shí)視覺(jué)感知還很遠(yuǎn),2)一些指標(biāo)最初不是為低光圖像設(shè)計(jì)的。它們用于評(píng)估圖像信息和對(duì)比度的保真度。使用這些指標(biāo)可能會(huì)反映圖像質(zhì)量,但它們與弱光增強(qiáng)的真正目的相去甚遠(yuǎn),3)缺乏專門為弱光圖像設(shè)計(jì)的指標(biāo),除了LOE指標(biāo)。此外,沒(méi)有用于評(píng)估低光視頻增強(qiáng)的指標(biāo),4) 期望能有一個(gè)可以平衡人類視覺(jué)和機(jī)器感知的指標(biāo)。
4 BENCHMARKING AND EMPIRICAL ANALYSIS
本節(jié)提供實(shí)證分析,并強(qiáng)調(diào)基于深度學(xué)習(xí)的 LLIE 中的一些關(guān)鍵挑戰(zhàn)。為了便于分析,我們提出了一個(gè)大規(guī)模的低光圖像和視頻數(shù)據(jù)集來(lái)檢查不同基于深度學(xué)習(xí)的解決方案的性能。此外,我們開(kāi)發(fā)了第一個(gè)在線平臺(tái),可以通過(guò)用戶友好的網(wǎng)絡(luò)界面生成基于深度學(xué)習(xí)的 LLIE 模型的結(jié)果。在本節(jié)中,我們對(duì)幾個(gè)基準(zhǔn)和我們提出的數(shù)據(jù)集進(jìn)行了廣泛的評(píng)估。在實(shí)驗(yàn)中,我們比較了13 種具有代表性的方法,包括 7 種基于監(jiān)督學(xué)習(xí)的方法(LLNet[1]、LightenNet[5]、Retinex-Net[4]、MBLLEN[3]、KinD[11]、KinD++[54]、 TBEFN[20]、DSLR[21])、一種基于無(wú)監(jiān)督學(xué)習(xí)的方法(EnlightenGAN[23])、一種基于半監(jiān)督學(xué)習(xí)的方法(DRBN[27])和三種基于零樣本學(xué)習(xí)的方法( ExCNet[24]、零 DCE[25]、RRDNet[26])。我們使用公開(kāi)可用的代碼來(lái)生成結(jié)果以進(jìn)行公平比較。
4.1 A New Low-Light Image and Video Dataset
我們提出了一個(gè)名為L(zhǎng)oLi-Phone 的大規(guī)模低光圖像和視頻數(shù)據(jù)集,以全面徹底地驗(yàn)證 LLIE 方法的性能。LoLi-Phone 是同類中最大、最具挑戰(zhàn)性的真實(shí)世界測(cè)試數(shù)據(jù)集。特別是,該數(shù)據(jù)集包含由 18 種不同手機(jī)相機(jī)拍攝的 120 個(gè)視頻(55,148 張圖像),包括 iPhone6s、iPhone7、iPhone7Plus、iPhone8Plus、iPhone11、iPhone11 Pro、iPhoneXS、iPhoneXR、iPhoneSE、小米小米 9、小米 Mix 3、Pixel 3、Pixel 4、OppoR17、VivoNex、LG M322、一加 5T、華為 Mate20 Pro 在各種光照條件下(例如弱光、曝光不足、月光、暮光、黑暗、極暗)、背光、非均勻光和彩色光。)在室內(nèi)和室外場(chǎng)景中。表 4 提供了LoLi-Phone 數(shù)據(jù)集的摘要。我們?cè)趫D 4 中展示了 LoLi 電話數(shù)據(jù)集的幾個(gè)示例。我們將發(fā)布建議的LoLi-Phone 數(shù)據(jù)集。
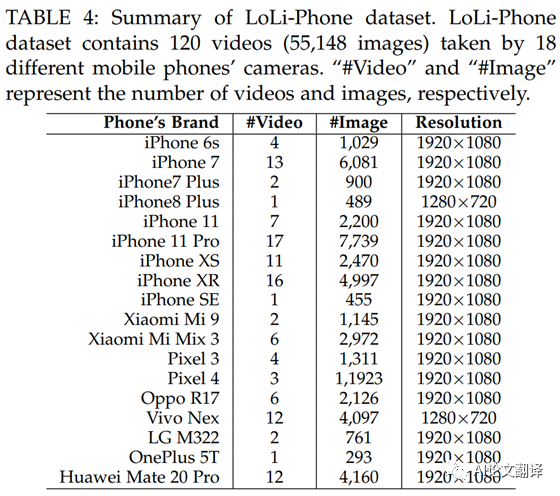

Fig. 4: Several images sampled from the proposedLoLiPhone dataset. The images and videos are taken by different devices underdiverse lighting conditions and scenes.
這個(gè)具有挑戰(zhàn)性的數(shù)據(jù)集是在真實(shí)場(chǎng)景中收集的,包含各種低光圖像和視頻。因此,它適用于評(píng)估不同低光圖像和視頻增強(qiáng)模型的泛化能力。值得注意的是,該數(shù)據(jù)集可用作基于無(wú)監(jiān)督學(xué)習(xí)的方法的訓(xùn)練數(shù)據(jù)集和合成方法的參考數(shù)據(jù)集,以生成逼真的低光圖像和視頻。
4.2 Online Evaluation Platform
不同的深度模型可以在不同的深度學(xué)習(xí)平臺(tái)上實(shí)現(xiàn),例如 Caffe、Theano、TensorFlow和PyTorch。因此,不同的算法需要不同的配置、GPU 版本和硬件規(guī)格。這樣的要求讓很多研究人員望而卻步,尤其是對(duì)于剛接觸這個(gè)領(lǐng)域甚至可能沒(méi)有 GPU 資源的初學(xué)者。為了解決這些問(wèn)題,我們開(kāi)發(fā)了一個(gè)名為 LoLiPlatform 的 LLIE 在線平臺(tái)。該平臺(tái)可在http://mc.nankai.edu. cn/ll/ 。
到目前為止,LoLi 平臺(tái)涵蓋了 13 種流行的基于深度學(xué)習(xí)的 LLIE 方法,包括 LLNet[1]、LightenNet[5]、Retinex-Net[4]、EnlightenGAN[23]、MBLLEN[3]、KinD [11]、KinD++[54]、TBEFN[20]、DSLR[21]、DRBN[27]、ExCNet[24]、Zero-DCE[25] 和 RRDNet[26],通過(guò)一個(gè)用戶友好的網(wǎng)絡(luò)界面,可以將任何輸入的結(jié)果輸出。我們會(huì)定期在這個(gè)平臺(tái)上提供新的方法。我們希望這個(gè) LoLi 平臺(tái)能夠通過(guò)為用戶提供靈活的界面來(lái)運(yùn)行現(xiàn)有的基于深度學(xué)習(xí)的 LLIE 方法并開(kāi)發(fā)他們自己的新 LLIE 方法,從而為不斷發(fā)展的研究社區(qū)服務(wù)。
4.3 Benchmarking Results
為了定性和定量地評(píng)估不同的方法,除了提出的LoLi-Phone 數(shù)據(jù)集外,我們還采用了常用的 LOL[4] 和MIT-Adobe FiveK [70] 數(shù)據(jù)集。更多視覺(jué)結(jié)果可以在補(bǔ)充材料中找到。此外,不同手機(jī)攝像頭拍攝的真實(shí)微光視頻對(duì)比結(jié)果可以在YouTube上找到
https://www.youtube.com/watch?v=Elo9TkrG5Oo&t=6s
.具體來(lái)說(shuō),我們從LoLi-Phone 數(shù)據(jù)集的每個(gè)視頻中平均選擇 5 張圖像,形成一個(gè)包含 600 張圖像的圖像測(cè)試數(shù)據(jù)集(記為L(zhǎng)oLi-Phone imgT)。此外,我們從每個(gè)手機(jī)品牌的LoLi-Phone 數(shù)據(jù)集的視頻中隨機(jī)選擇一個(gè)視頻,形成一個(gè)包含 18 個(gè)視頻的視頻測(cè)試數(shù)據(jù)集(記為L(zhǎng)oLi-Phone-vidT)。我們將LoLi-Phone-imgT 和 LoLi-Phone-vidT 中幀的分辨率減半,因?yàn)橐恍┗谏疃葘W(xué)習(xí)的方法無(wú)法處理測(cè)試圖像和視頻的全分辨率。對(duì)于 LOL 數(shù)據(jù)集,我們采用包含 15 個(gè)在真實(shí)場(chǎng)景中捕獲的低光圖像的原始測(cè)試集進(jìn)行測(cè)試,記為L(zhǎng)OL-test。對(duì)于MIT-Adobe FiveK 數(shù)據(jù)集,我們按照 [40] 中的處理將圖像解碼為 PNG 格式,并使用Lightroom 將它們調(diào)整為具有 512 像素的長(zhǎng)邊。我們采用與[40]相同的測(cè)試數(shù)據(jù)集,麻省理工學(xué)院 Adobe FiveK-test,包括 500 張圖像,其中專家 C 的修飾結(jié)果作為相應(yīng)的基本事實(shí)。
定性比較
(QualitativeComparison)。我們首先在圖 5 和圖 6 中展示了不同方法對(duì)從LOL-test 和MIT-Adobe FiveK-test 數(shù)據(jù)集采樣的圖像的結(jié)果。如圖 5 所示,所有方法都提高了輸入圖像的亮度和對(duì)比度。然而,當(dāng)將結(jié)果與基本事實(shí)進(jìn)行比較時(shí),它們都沒(méi)有成功地恢復(fù)輸入圖像的準(zhǔn)確顏色。特別是,LLNet[1] 會(huì)產(chǎn)生模糊結(jié)果。LightenNet [5] 和 RRDNet[26] 產(chǎn)生曝光不足的結(jié)果,而 MBLLEN[3] 和 ExCNet[24] 往往會(huì)過(guò)度曝光圖像。 KinD[11]、KinD++[54]、TBEFN[20]、DSLR[21]、EnlightenGAN[23] 和 DRBN[27] 引入了明顯的偽影。在圖 6 中,LLNet [5]、KinD++ [54]、TBEFN [20] 和 RRDNet [26] 產(chǎn)生了過(guò)度曝光的結(jié)果。 Retinex-Net [4]、KinD++ [54] 和 RRDNet [26] 在結(jié)果中產(chǎn)生偽影和模糊。我們發(fā)現(xiàn) MIT Adobe FiveK 數(shù)據(jù)集的基本事實(shí)仍然包含一些暗區(qū)。這是因?yàn)樵摂?shù)據(jù)集最初是為全局圖像修飾而設(shè)計(jì)的,其中恢復(fù)低光區(qū)域不是該任務(wù)的主要優(yōu)先事項(xiàng)。


我們還觀察到 LOL 數(shù)據(jù)集和MIT-Adobe FiveK 數(shù)據(jù)集中的輸入圖像相對(duì)沒(méi)有噪聲,這與真實(shí)的低光場(chǎng)景不同。盡管一些 LLIE 方法 [18]、[21]、[53] 將 MITAdobe FiveK 數(shù)據(jù)集作為訓(xùn)練或測(cè)試數(shù)據(jù)集,但我們認(rèn)為該數(shù)據(jù)集不適合 LLIE 的任務(wù),因?yàn)樗牟黄ヅ?不令人滿意的基礎(chǔ) LLIE的真相。為了檢查不同方法的泛化能力,我們對(duì)從我們的LoLi-Phone-imgT 數(shù)據(jù)集中采樣的圖像進(jìn)行比較。不同方法的視覺(jué)結(jié)果如圖 7 和圖 8 所示。如圖 7 所示,所有方法都不能有效地提高輸入低光圖像的亮度和去除噪聲。此外,Retinex-Net[4]、MBLLEN[3] 和 DRBN[27] 會(huì)產(chǎn)生明顯的偽影。在圖 8 中,所有方法都增強(qiáng)了該輸入圖像的亮度。然而,只有 MBLLEN[3] 和 RRDNet[26] 在沒(méi)有顏色偏差、偽影和曝光過(guò)度/不足的情況下獲得視覺(jué)上令人愉悅的增強(qiáng)效果。值得注意的是,對(duì)于有光源的區(qū)域,沒(méi)有一種方法可以在不放大這些區(qū)域周圍的噪聲的情況下使圖像變亮。將光源考慮到 LLIE 將是一個(gè)有趣的探索方向。結(jié)果表明增強(qiáng)LoLi-Phone-imgT 數(shù)據(jù)集圖像的難度。
定量比較
(QuantitativeComparison)。對(duì)于具有基本事實(shí)的測(cè)試集,即LOL-test 和MIT-Adobe FiveK-test,我們采用 MSE、PSNR、SSIM[60] 和 LPIPS[76] 指標(biāo)來(lái)定量比較不同的方法。 LPIPS[76] 是一種基于深度學(xué)習(xí)的圖像質(zhì)量評(píng)估指標(biāo),它通過(guò)深度視覺(jué)表示來(lái)測(cè)量結(jié)果與其對(duì)應(yīng)的基本事實(shí)之間的感知相似性。對(duì)于 LPIPS,我們采用基于AlexNet 的模型來(lái)計(jì)算感知相似度。較低的 LPIPS 值表明在感知相似性方面更接近相應(yīng)的基本事實(shí)的結(jié)果。在表 5 中,我們展示了定量結(jié)果。


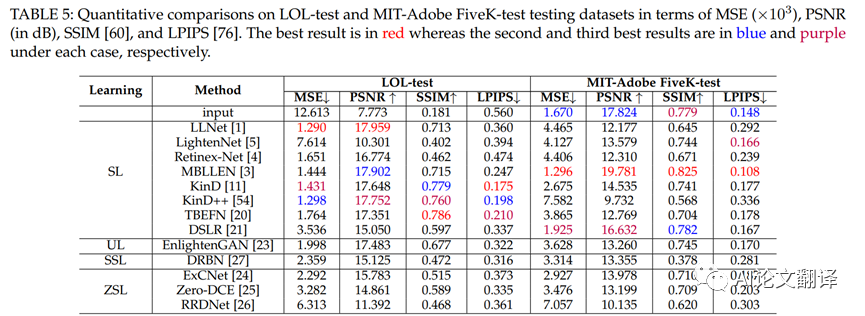
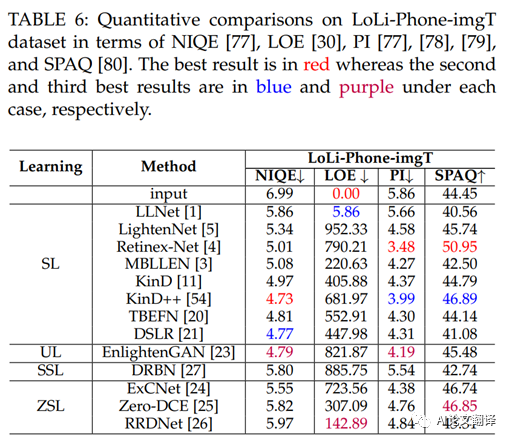
如表 5 所示,在LOL-test 和MIT-Adobe FiveK-test 上,基于監(jiān)督學(xué)習(xí)的方法的定量分?jǐn)?shù)優(yōu)于基于無(wú)監(jiān)督學(xué)習(xí)、基于半監(jiān)督學(xué)習(xí)和基于零樣本學(xué)習(xí)的方法數(shù)據(jù)集。其中,LLNet[1] 在LOL-test 數(shù)據(jù)集上獲得了最好的 MSE 和 PSNR 值;但是,它在MIT-Adobe FiveK-test 數(shù)據(jù)集上的性能下降。這可能是由于 LLNet [1] 對(duì) LOL 數(shù)據(jù)集的偏見(jiàn),因?yàn)樗鞘褂?LOL 訓(xùn)練數(shù)據(jù)集進(jìn)行訓(xùn)練的。對(duì)于 LOL 測(cè)試數(shù)據(jù)集,TBEFN[20] 獲得最高的 SSIM 值,而 KinD[11] 獲得最低的 LPIPS 值。盡管有些方法是在 LOL 訓(xùn)練數(shù)據(jù)集上訓(xùn)練的,但在 LOL 測(cè)試數(shù)據(jù)集上的這四個(gè)評(píng)估指標(biāo)中沒(méi)有贏家。對(duì)于MIT-Adobe FiveK-test 數(shù)據(jù)集,MBLLEN [3] 在四個(gè)評(píng)估指標(biāo)下優(yōu)于所有比較方法,盡管在合成訓(xùn)練數(shù)據(jù)上進(jìn)行了訓(xùn)練。盡管如此,MBLLEN[3] 仍然無(wú)法在兩個(gè)測(cè)試數(shù)據(jù)集上獲得最佳性能。對(duì)于LoLi-Phone-imgT 測(cè)試集,我們使用非參考圖像質(zhì)量評(píng)估指標(biāo),即 NIQE [77]、感知指數(shù) (PI)[77]、[78]、[79]、LOE[30] 和 SPAQ[80]定量比較不同的方法。在 LOE 方面,LOE 值越小,亮度順序保持得越好。對(duì)于NIQE,NIQE值越小,視覺(jué)質(zhì)量越好。較低的 PI 值表示更好的感知質(zhì)量。 SPAQ 是為智能手機(jī)攝影的感知質(zhì)量評(píng)估而設(shè)計(jì)的。較大的 SPAQ 值表明智能手機(jī)攝影的感知質(zhì)量更好。定量結(jié)果見(jiàn)表 6。觀察表 6,我們可以發(fā)現(xiàn)Retinex-Net [4]、KinD++[54] 和EnlightenGAN [23] 的性能相對(duì)優(yōu)于其他方法。 Retinex-Net [4] 獲得了最好的 PI 和 SPAQ 分?jǐn)?shù)。這些分?jǐn)?shù)表明Retinex-Net [4] 增強(qiáng)了結(jié)果的良好感知質(zhì)量。然而,從圖 7(d) 和圖 8(d) 來(lái)看,Retinex-Net[4] 的結(jié)果明顯受到偽影和顏色偏差的影響。因此,我們認(rèn)為非參考 PI 和 SPAQ 指標(biāo)可能不適合低光圖像的感知質(zhì)量評(píng)估。此外,KinD++[54] 的 NIQE 得分最低,而原始輸入的 LOE 得分最低。對(duì)于事實(shí)上的標(biāo)準(zhǔn) LOE 指標(biāo),我們質(zhì)疑亮度順序是否可以有效地反映增強(qiáng)性能。總體而言,非參考 IQA 指標(biāo)在評(píng)估增強(qiáng)的低光圖像質(zhì)量時(shí)存在偏差。
為了準(zhǔn)備LoLi-vidT 測(cè)試集中的視頻,我們首先丟棄連續(xù)幀中沒(méi)有明顯物體的視頻。總共選擇了10個(gè)視頻。對(duì)于每個(gè)視頻,我們選擇一個(gè)出現(xiàn)在所有幀中的對(duì)象。然后,我們使用跟蹤器 [81] 跟蹤輸入視頻的連續(xù)幀中的對(duì)象,并確保相同的對(duì)象出現(xiàn)在邊界框中。我們丟棄了具有不準(zhǔn)確對(duì)象跟蹤的幀。收集每一幀中邊界框的坐標(biāo)。我們使用這些坐標(biāo)來(lái)裁剪通過(guò)不同方法增強(qiáng)的結(jié)果中的相應(yīng)區(qū)域,并計(jì)算連續(xù)幀中對(duì)象的平均亮度方差 (ALV) 分?jǐn)?shù):其中是視頻的幀數(shù),表示第幀邊界框區(qū)域的平均亮度值,表示視頻中所有邊界框區(qū)域的平均亮度值。較低的 ALV 值表明增強(qiáng)視頻的時(shí)間相干性更好。 LoLividT測(cè)試集的10個(gè)視頻平均的不同方法的ALV值如表7所示。每個(gè)視頻的不同方法的ALV值可以在補(bǔ)充材料中找到。此外,我們按照[9]在補(bǔ)充材料中繪制它們的亮度曲線。如表 7 所示,TBEFN[20] 在 ALV 值方面獲得了最佳的時(shí)間相干性,而 LLNet[1] 和EnlightenGAN [23] 分別排名第二和第三。相比之下,作為表現(xiàn)最差的 ExCNet [24] 的 ALV 值達(dá)到了1375.29。這是因?yàn)榛诹銋⒖紝W(xué)習(xí)的 ExCNet[24] 的性能對(duì)于連續(xù)幀的增強(qiáng)是不穩(wěn)定的。換句話說(shuō),ExCNet[24] 可以有效地提高某些幀的亮度,而在其他幀上效果不佳。
4.4 Computational Complexity
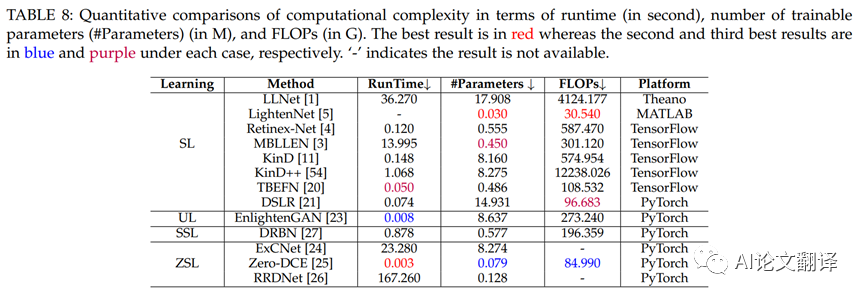
在表 8 中,我們比較了不同方法的計(jì)算復(fù)雜度,包括運(yùn)行時(shí)、可訓(xùn)練參數(shù)和使用 NVIDA1080Ti GPU 對(duì) 32 張大小為1200×900×3 的圖像進(jìn)行平均的 FLOP。為了公平比較,我們省略了LightenNet [5],因?yàn)橹挥衅浯a的 CPU 版本是公開(kāi)可用的。此外,我們沒(méi)有報(bào)告 ExCNet[24] 和 RRDNet[26] 的 FLOP,因?yàn)閿?shù)量取決于輸入圖像(不同的輸入需要不同的迭代次數(shù))。如表 8 所示,Zero-DCE[25] 的運(yùn)行時(shí)間最短,因?yàn)樗鼉H通過(guò)輕量級(jí)網(wǎng)絡(luò)估計(jì)幾個(gè)曲線參數(shù)。因此,它的可訓(xùn)練參數(shù)和 FLOP 數(shù)量要少得多。此外,LightenNet[5] 的可訓(xùn)練參數(shù)和 FLOP 的數(shù)量是比較方法中最少的。這是因?yàn)長(zhǎng)ightenNet [5] 通過(guò)一個(gè)由四個(gè)卷積層組成的微型網(wǎng)絡(luò)來(lái)估計(jì)輸入圖像的光照?qǐng)D。相比之下,LLNet[1] 和 KinD++[54] 的 FLOPs 非常大,分別達(dá)到4124.177G 和12238.026G。由于耗時(shí)的優(yōu)化過(guò)程,基于 SSL 的 ExCNet[24] 和 RRDNet[26] 的運(yùn)行時(shí)間很長(zhǎng)。
4.5 Application-Based Evaluation
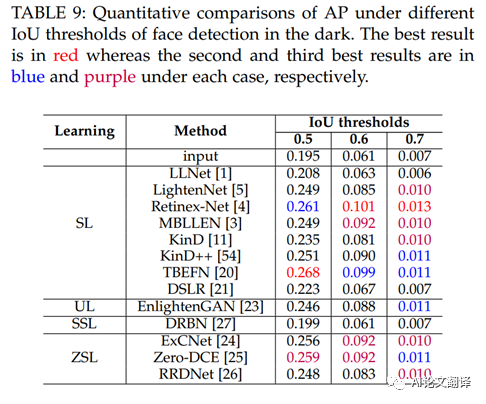
我們研究了低光圖像增強(qiáng)方法在黑暗中人臉檢測(cè)的性能。按照 [25] 中提出的設(shè)置,我們使用 DARKFACE 數(shù)據(jù)集 [73],該數(shù)據(jù)集由在黑暗中拍攝的人臉圖像組成。由于測(cè)試集的邊界框不是公開(kāi)可用的,我們對(duì)從訓(xùn)練和驗(yàn)證集中隨機(jī)采樣的 500 張圖像進(jìn)行評(píng)估。在 WIDERFACE 數(shù)據(jù)集 [83] 上訓(xùn)練的雙鏡頭人臉檢測(cè)器 (DSFD)[82] 被用作人臉檢測(cè)器。我們將不同 LLIE 方法的結(jié)果提供給 DSFD[82],并在圖 9 中描繪了 0.5IoU 閾值下的精度 - 召回 (P-R) 曲線。此外,我們使用評(píng)估比較了不同 IoU 閾值下的平均精度 (AP) 表 9 中 DARKFACE 數(shù)據(jù)集 [73] 中提供的工具 3。如圖 9 所示,所有基于深度學(xué)習(xí)的解決方案都提高了黑暗中人臉檢測(cè)的性能,表明基于深度學(xué)習(xí)的 LLIE 解決方案在黑暗中人臉檢測(cè)的有效性。如表 9 所示,不同 IoU 閾值下表現(xiàn)最佳者的 AP 得分范圍為 0.268 到 0.013,不同 IoU 閾值下的輸入 AP 得分非常低。結(jié)果表明仍有改進(jìn)的余地。值得注意的是,Retinex-Net[4]、Zero-DCE[25] 和 TBEFN[20] 在黑暗中的人臉檢測(cè)方面取得了相對(duì)穩(wěn)健的性能。我們?cè)趫D 10 中展示了不同方法的視覺(jué)結(jié)果。盡管Retinex-Net [4] 在 AP 分?jǐn)?shù)上的表現(xiàn)優(yōu)于其他方法,但其視覺(jué)結(jié)果包含明顯的偽影和不自然的紋理。一般來(lái)說(shuō),零 DCE[25] 在 AP 分?jǐn)?shù)和黑暗中人臉檢測(cè)的感知質(zhì)量之間取得了很好的平衡。

4.6 Discussion
從實(shí)驗(yàn)結(jié)果中,我們獲得了一些有趣的觀察和見(jiàn)解:
根據(jù)測(cè)試數(shù)據(jù)集和評(píng)估指標(biāo),不同方法的性能存在顯著差異。就常用測(cè)試數(shù)據(jù)集的全參考 IQA 指標(biāo)而言,MBLLEN[3]、KinD++[54] 和 DSLR[21] 通常優(yōu)于其他比較方法。對(duì)于手機(jī)拍攝的真實(shí)世界低光圖像,基于監(jiān)督學(xué)習(xí)的Retinex-Net [4] 和 KinD++ [54] 在非參考 IQA 指標(biāo)中獲得了更好的分?jǐn)?shù)。對(duì)于手機(jī)拍攝的真實(shí)世界低光視頻,TBEFN[20] 更好地保留了時(shí)間相干性。在計(jì)算效率方面,LightenNet[5] 和Zero-DCE [25] 表現(xiàn)突出。從黑暗中的人臉檢測(cè)方面來(lái)看,TBEFN[20]、Retinex-Net[4]和Zero-DCE[25]排名前三。沒(méi)有方法總是贏。總體而言,在大多數(shù)情況下,Retinex-Net[4]、[20]、Zero-DCE[25] 和 DSLR[21] 是更好的選擇。
提出的LoLi-Phone 數(shù)據(jù)集的低光圖像和視頻在大多數(shù)方法中都失敗了。現(xiàn)有方法的泛化能力需要進(jìn)一步提高。值得注意的是,僅使用平均亮度方差來(lái)評(píng)估低光視頻增強(qiáng)的不同方法的性能是不夠的。更有效和更全面的評(píng)估指標(biāo)將指導(dǎo)弱光視頻增強(qiáng)技術(shù)的發(fā)展走向正確的軌道。
關(guān)于學(xué)習(xí)策略,監(jiān)督學(xué)習(xí)在大多數(shù)情況下取得了更好的性能,但需要大量的計(jì)算資源和配對(duì)的訓(xùn)練數(shù)據(jù)。相比之下,零樣本學(xué)習(xí)在實(shí)際應(yīng)用中更具吸引力,因?yàn)樗恍枰鋵?duì)或非配對(duì)的訓(xùn)練數(shù)據(jù)。因此,基于零樣本學(xué)習(xí)的方法具有更好的泛化能力。然而,基于零樣本學(xué)習(xí)的方法的定量性能不如其他方法。
視覺(jué)結(jié)果和定量 IQA 分?jǐn)?shù)之間存在差距。換句話說(shuō),良好的視覺(jué)外觀并不總能產(chǎn)生良好的 IQA 分?jǐn)?shù)。人類感知與IQA分?jǐn)?shù)之間的關(guān)系值得更多研究。追求更好的視覺(jué)感知或定量分?jǐn)?shù)取決于具體的應(yīng)用。例如,為了向觀察者展示結(jié)果,應(yīng)該更多地關(guān)注視覺(jué)感知。相比之下,當(dāng) LLIE 方法應(yīng)用于黑暗中的人臉檢測(cè)時(shí),準(zhǔn)確性比視覺(jué)感知更重要。因此,在比較不同方法時(shí),應(yīng)進(jìn)行更全面和徹底的比較。
基于深度學(xué)習(xí)的 LLIE 方法有利于在黑暗中進(jìn)行人臉檢測(cè)。這些結(jié)果進(jìn)一步支持了增強(qiáng)低光圖像和視頻的重要性。然而,與正常光照?qǐng)D像中人臉檢測(cè)的高精度相比,盡管使用了LLIE方法,但在黑暗中人臉檢測(cè)的準(zhǔn)確率卻極低。
5 FUTURE RESEARCH DIRECTIONS
低光圖像增強(qiáng)是一個(gè)具有挑戰(zhàn)性的研究課題。從第 4 節(jié)中介紹的實(shí)驗(yàn)可以看出,仍有改進(jìn)的余地。我們建議潛在的未來(lái)研究方向如下。
有效的學(xué)習(xí)策略
。如前所述,當(dāng)前的 LLIE 模型主要采用監(jiān)督學(xué)習(xí),需要大量配對(duì)訓(xùn)練數(shù)據(jù),并且可能在特定數(shù)據(jù)集上過(guò)擬合。盡管一些研究人員試圖將無(wú)監(jiān)督學(xué)習(xí)(例如對(duì)抗性學(xué)習(xí))引入 LLIE,但 LLIE 與這些學(xué)習(xí)策略之間的內(nèi)在關(guān)系尚不清楚,它們?cè)?LLIE 中的有效性需要進(jìn)一步改進(jìn)。零樣本學(xué)習(xí)已在真實(shí)場(chǎng)景中顯示出強(qiáng)大的性能,同時(shí)不需要配對(duì)訓(xùn)練數(shù)據(jù)。獨(dú)特的優(yōu)勢(shì)表明零樣本學(xué)習(xí)是一個(gè)潛在的研究方向,特別是在零參考損失、深度先驗(yàn)和優(yōu)化策略的制定方面。
專門的網(wǎng)絡(luò)結(jié)構(gòu)
。網(wǎng)絡(luò)結(jié)構(gòu)可以顯著影響增強(qiáng)性能。如前7所述,大多數(shù) LLIE 深度模型采用 U-Net 或類似 U-Net 的結(jié)構(gòu)。盡管它們?cè)谀承┣闆r下取得了可喜的性能,但仍然缺乏研究這種編碼器-解碼器網(wǎng)絡(luò)結(jié)構(gòu)是否最適合 LLIE 任務(wù)。由于參數(shù)空間大,一些網(wǎng)絡(luò)結(jié)構(gòu)需要高內(nèi)存占用和長(zhǎng)推理時(shí)間。這樣的網(wǎng)絡(luò)結(jié)構(gòu)對(duì)于實(shí)際應(yīng)用來(lái)說(shuō)是不可接受的。因此,考慮到光照不均勻、像素值小、噪聲抑制和顏色恒定等弱光圖像的特點(diǎn),研究一種更有效的 LLIE 網(wǎng)絡(luò)結(jié)構(gòu)是值得的。人們還可以通過(guò)考慮低光圖像的局部相似性或考慮更有效的操作(例如深度可分離卷積層[84]和自校準(zhǔn)卷積[85])來(lái)設(shè)計(jì)更有效的網(wǎng)絡(luò)結(jié)構(gòu)。可以考慮神經(jīng)架構(gòu)搜索(NAS)技術(shù)[86]、[87]以獲得更有效和高效的LLIE網(wǎng)絡(luò)結(jié)構(gòu)。將變壓器架構(gòu) [88]、[89] 改編為 LLIE 可能是一個(gè)潛在且有趣的研究方向。
損失函數(shù)
。損失函數(shù)約束輸入圖像和ground-truth之間的關(guān)系,并推動(dòng)深度網(wǎng)絡(luò)的優(yōu)化。在 LLIE 中,常用的損失函數(shù)是從相關(guān)的視覺(jué)任務(wù)中借用的。沒(méi)有專門的損失函數(shù)來(lái)指導(dǎo)弱光視頻增強(qiáng)網(wǎng)絡(luò)的優(yōu)化。因此,需要設(shè)計(jì)更適合 LLIE 的損失函數(shù)。此外,最近的研究揭示了使用深度神經(jīng)網(wǎng)絡(luò)來(lái)近似人類對(duì)圖像質(zhì)量的視覺(jué)感知的可能性 [90]、[91]。這些思想和基礎(chǔ)理論可用于指導(dǎo)弱光增強(qiáng)網(wǎng)絡(luò)的適當(dāng)損失函數(shù)的設(shè)計(jì)。
真實(shí)的訓(xùn)練數(shù)據(jù)
。盡管 LLIE 有多個(gè)訓(xùn)練數(shù)據(jù)集,但它們的真實(shí)性、規(guī)模和多樣性落后于真正的弱光條件。因此,如第 4 節(jié)所示,當(dāng)前的 LLIE 深度模型在遇到在現(xiàn)實(shí)世界場(chǎng)景中捕獲的低光圖像時(shí)無(wú)法達(dá)到令人滿意的性能。需要更多的努力來(lái)研究大規(guī)模和多樣化的現(xiàn)實(shí)世界配對(duì) LLIE 訓(xùn)練數(shù)據(jù)集的集合或生成更真實(shí)的合成數(shù)據(jù)。
標(biāo)準(zhǔn)測(cè)試數(shù)據(jù)
。目前,還沒(méi)有公認(rèn)的 LLIE 評(píng)估基準(zhǔn)。研究人員更喜歡選擇自己的測(cè)試數(shù)據(jù),這些數(shù)據(jù)可能會(huì)偏向于他們提出的方法。盡管一些研究人員留下了一些配對(duì)數(shù)據(jù)作為測(cè)試數(shù)據(jù),但訓(xùn)練和測(cè)試分區(qū)的劃分在文獻(xiàn)中大多是臨時(shí)的。因此,在不同方法之間進(jìn)行公平比較通常是費(fèi)力的,如果不是不可能的話。此外,一些測(cè)試數(shù)據(jù)要么易于處理,要么最初不是為弱光增強(qiáng)而收集的。需要有一個(gè)標(biāo)準(zhǔn)的低光圖像和視頻測(cè)試數(shù)據(jù)集,其中包括大量具有相應(yīng)groundtruth的測(cè)試樣本,涵蓋多種場(chǎng)景和具有挑戰(zhàn)性的光照條件。
特定于任務(wù)的評(píng)估指標(biāo)
。 LLIE中常用的評(píng)價(jià)指標(biāo)可以在一定程度上反映圖像質(zhì)量。然而,如何衡量 LLIE 方法增強(qiáng)結(jié)果的好壞仍然挑戰(zhàn)當(dāng)前的 IQA 指標(biāo),特別是對(duì)于非參考測(cè)量。此外,當(dāng)前的 IQA 指標(biāo)要么側(cè)重于人類視覺(jué)感知,例如主觀質(zhì)量,要么強(qiáng)調(diào)機(jī)器感知,例如對(duì)高級(jí)視覺(jué)任務(wù)的影響。需要一種同時(shí)考慮人類感知和機(jī)器感知的評(píng)估指標(biāo)。因此,預(yù)計(jì)該研究方向?qū)㈤_(kāi)展更多工作,努力為 LLIE 設(shè)計(jì)更準(zhǔn)確和特定任務(wù)的評(píng)估指標(biāo)。
強(qiáng)大的泛化能力
。觀察真實(shí)世界測(cè)試數(shù)據(jù)的實(shí)驗(yàn)結(jié)果,大多數(shù)方法由于泛化能力有限而失敗。泛化能力差是由合成訓(xùn)練數(shù)據(jù)、小規(guī)模訓(xùn)練數(shù)據(jù)、無(wú)效的網(wǎng)絡(luò)結(jié)構(gòu)、不切實(shí)際的假設(shè)和不準(zhǔn)確的先驗(yàn)等因素造成的。探索提高基于深度學(xué)習(xí)的 LLIE 模型泛化能力的方法非常重要。
低光視頻增強(qiáng)的擴(kuò)展
。與視頻去模糊 [92]、視頻去噪 [93] 和視頻超分辨率 [94] 等其他低級(jí)視覺(jué)任務(wù)中視頻增強(qiáng)的快速發(fā)展不同,低光視頻增強(qiáng)受到的關(guān)注較少。將現(xiàn)有的LLIE 方法直接應(yīng)用于視頻通常會(huì)導(dǎo)致不滿意的結(jié)果和閃爍的偽影。需要更多的努力來(lái)有效地消除視覺(jué)閃爍,利用相鄰幀之間的時(shí)間信息,并加快增強(qiáng)速度。
整合語(yǔ)義信息
。語(yǔ)義信息對(duì)于弱光增強(qiáng)至關(guān)重要。它指導(dǎo)網(wǎng)絡(luò)在增強(qiáng)過(guò)程中區(qū)分不同的區(qū)域。沒(méi)有訪問(wèn)語(yǔ)義先驗(yàn)的網(wǎng)絡(luò)很容易偏離區(qū)域的原始顏色,例如,在增強(qiáng)后將黑色頭發(fā)變成灰色。因此,將語(yǔ)義先驗(yàn)整合到 LLIE 模型中是一個(gè)很有前景的研究方向。在圖像超分辨率 [95]、[96] 和人臉恢復(fù) [97] 上也進(jìn)行了類似的工作。
審核編輯 黃宇
-
圖像增強(qiáng)
+關(guān)注
關(guān)注
0文章
54瀏覽量
10143 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122583
發(fā)布評(píng)論請(qǐng)先 登錄
基于深度學(xué)習(xí)的傳統(tǒng)圖像增強(qiáng)算法

深度學(xué)習(xí)在預(yù)測(cè)和健康管理中的應(yīng)用
低照度圖像增強(qiáng)算法
深度學(xué)習(xí)怎么實(shí)現(xiàn)圖像到圖像的翻譯
基于深度學(xué)習(xí)的圖像修復(fù)模型及實(shí)驗(yàn)對(duì)比

基于模板、檢索和深度學(xué)習(xí)的圖像描述生成方法
基于深度學(xué)習(xí)的光學(xué)成像算法綜述
基于深度學(xué)習(xí)的目標(biāo)檢測(cè)研究綜述

深度學(xué)習(xí)在軌跡數(shù)據(jù)挖掘中的應(yīng)用研究綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論