") 如何處理百萬(wàn)行EXCEL文件?
如何處理百萬(wàn)行EXCEL文件?
來(lái)源 | OSCHINA 社區(qū)
作者 | 京東云開發(fā)者-京東保險(xiǎn) 孫昊語(yǔ)
一、引言
Excel 表格在后臺(tái)管理系統(tǒng)中使用非常廣泛,多用來(lái)進(jìn)行批量配置、數(shù)據(jù)導(dǎo)出工作。在日常開發(fā)中,我們也免不了進(jìn)行 Excel 數(shù)據(jù)處理。
那么,如何恰當(dāng)?shù)靥幚頂?shù)據(jù)量龐大的 Excel 文件,避免內(nèi)存溢出問題?本文將對(duì)比分析業(yè)界主流的 Excel 解析技術(shù),并給出解決方案。
如果這是您第一次接觸 Excel 解析,建議您從第二章了解本文基礎(chǔ)概念;如果您已經(jīng)對(duì) POI 有所了解,請(qǐng)?zhí)D(zhuǎn)第三章閱讀本文重點(diǎn)內(nèi)容。
二、基礎(chǔ)篇 - POI
說(shuō)到 Excel 讀寫,就離不開這個(gè)圈子的的老大哥 ——POI。
Apache POI 是一款 Apache 軟件基金會(huì)用 Java 編寫的免費(fèi)開源的跨平臺(tái)的 Java API,全稱 Poor Obfuscation Implementation,“簡(jiǎn)潔版的模糊實(shí)現(xiàn)”。它支持我們用 Java 語(yǔ)言和包括 Word、Excel、PowerPoint、Visio 在內(nèi)的所有 Microsoft Office 文檔交互,進(jìn)行數(shù)據(jù)讀寫和修改操作。
(1)“糟糕” 的電子表格
在 POI 中,每種文檔都有一個(gè)與之對(duì)應(yīng)的文檔格式,如 97-2003 版本的 Excel 文件(.xls),文檔格式為 HSSF——Horrible SpreadSheet Format,意為 “糟糕的電子表格格式”。雖然 Apache 幽默而謙虛地將自己的 API 冠以 “糟糕” 之名,不過這確實(shí)是一款全面而強(qiáng)大的 API。
以下是部分 “糟糕” 的 POI 文檔格式,包括 Excel、Word 等:
| Office 文檔 | 對(duì)應(yīng) POI 格式 |
|---|---|
| Excel (.xls) | HSSF (Horrible SpreadSheet Format) |
| Word (.doc) | HWPF (Horrible Word Processor Format) |
| Visio (.vsd) | HDGF (Horrible DiaGram Format) |
| PowerPoint(.ppt) | HSLF(Horrible Slide Layout Format) |
(2)OOXML 簡(jiǎn)介
微軟在 Office 2007 版本推出了基于 XML 的技術(shù)規(guī)范:Office Open XML,簡(jiǎn)稱 OOXML。不同于老版本的二進(jìn)制存儲(chǔ),在新規(guī)范下,所有 Office 文檔都使用了 XML 格式書寫,并使用 ZIP 格式進(jìn)行壓縮存儲(chǔ),大大提升了規(guī)范性,也提高了壓縮率,縮小了文件體積,同時(shí)支持向后兼容。簡(jiǎn)單來(lái)說(shuō),OOXML 定義了如何用一系列的 XML 文件來(lái)表示 Office 文檔。
Xlsx 文件的本質(zhì)是 XML
讓我們看看一個(gè)采用 OOML 標(biāo)準(zhǔn)的 Xlsx 文件的構(gòu)成。我們右鍵點(diǎn)擊一個(gè) Xlsx 文件,可以發(fā)現(xiàn)它可以被 ZIP 解壓工具解壓(或直接修改擴(kuò)展名為.zip 后解壓),這說(shuō)明:Xlsx 文件是用 ZIP 格式壓縮的。解壓后,可以看到如下目錄格式:
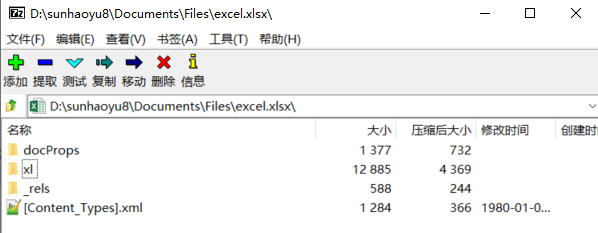
打開其中的 “/xl” 目錄,這是這個(gè) Excel 的主要結(jié)構(gòu)信息:
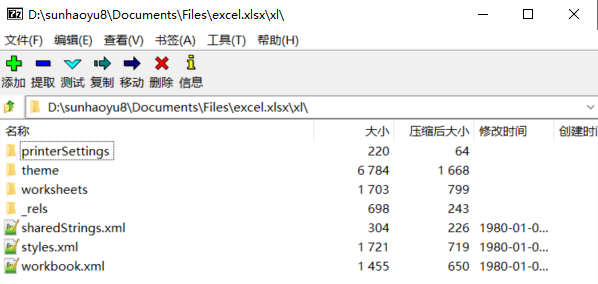
其中 workbook.xml 存儲(chǔ)了整個(gè) Excel 工作簿的結(jié)構(gòu),包含了幾張 sheet 表單,而每張表單結(jié)構(gòu)存儲(chǔ)在 /wooksheets 文件夾中。styles.xml 存放單元格的格式信息,/theme 文件夾存放一些預(yù)定義的字體、顏色等數(shù)據(jù)。為了減少壓縮體積,表單中所有的字符數(shù)據(jù)被統(tǒng)一存放在 sharedStrings.xml 中。經(jīng)過分析不難發(fā)現(xiàn),Xlsx 文件的主體數(shù)據(jù)都以 XML 格式書寫。
XSSF 格式
為了支持新標(biāo)準(zhǔn)的 Office 文檔,POI 也推出了一套兼容 OOXML 標(biāo)準(zhǔn)的 API,稱作 poi-ooxml。如 Excel 2007 文件(.xlsx)對(duì)應(yīng)的 POI 文檔格式為 XSSF(XML SpreadSheet Format)。
以下是部分 OOXML 文檔格式:
| Office 文檔 | 對(duì)應(yīng) POI 格式 |
|---|---|
| Excel (.xlsx) | XSSF (XML SpreadSheet Format) |
| Word (.docx) | XWPF (XML Word Processor Format) |
| Visio (.vsdx) | XDGF (XML DiaGram Format) |
| PowerPoint (.pptx) | XSLF (XML Slide Layout Format) |
(3)UserModel
在 POI 中為我們提供了兩種解析 Excel 的模型,UserModel(用戶模型)和 EventModel(事件模型) 。兩種解析模式都可以處理 Excel 文件,但解析方式、處理效率、內(nèi)存占用量都不盡相同。最簡(jiǎn)單和實(shí)用的當(dāng)屬 UserModel。
UserModel & DOM 解析
用戶模型定義了如下接口:
Workbook - 工作簿,對(duì)應(yīng)一個(gè) Excel 文檔。根據(jù)版本不同,有 HSSFWorkbook、XSSFWorkbook 等類。
Sheet - 表單,一個(gè) Excel 中的若干個(gè)表單,同樣有 HSSFSheet、XSSFSheet 等類。
Row - 行,一個(gè)表單由若干行組成,同樣有 HSSFRow、XSSFRow 等類。
Cell - 單元格,一個(gè)行由若干單元格組成,同樣有 HSSFCell、XSSFCell 等類。
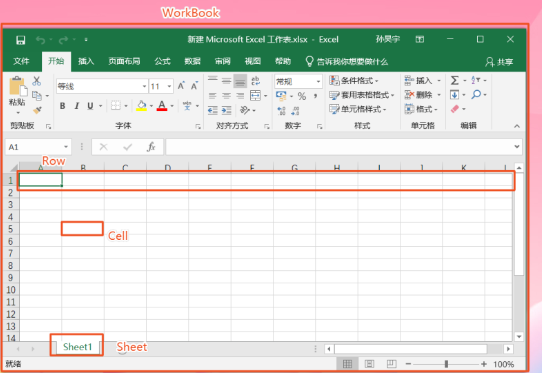
可以看到,用戶模型十分貼合 Excel 用戶的習(xí)慣,易于理解,就像我們打開一個(gè) Excel 表格一樣。同時(shí)用戶模型提供了豐富的 API,可以支持我們完成和 Excel 中一樣的操作,如創(chuàng)建表單、創(chuàng)建行、獲取表的行數(shù)、獲取行的列數(shù)、讀寫單元格的值等。
為什么 UserModel 支持我們進(jìn)行如此豐富的操作?因?yàn)樵?UserModel 中,Excel 中的所有 XML 節(jié)點(diǎn)都被解析成了一棵 DOM 樹,整棵 DOM 樹都被加載進(jìn)內(nèi)存,因此可以進(jìn)行方便地對(duì)每個(gè) XML 節(jié)點(diǎn)進(jìn)行隨機(jī)訪問。
UserModel 數(shù)據(jù)轉(zhuǎn)換
了解了用戶模型,我們就可以直接使用其 API 進(jìn)行各種 Excel 操作。當(dāng)然,更方便的辦法是使用用戶模型將一個(gè) Excel 文件轉(zhuǎn)化成我們想要的 Java 數(shù)據(jù)結(jié)構(gòu),更好地進(jìn)行數(shù)據(jù)處理。
我們很容易想到關(guān)系型數(shù)據(jù)庫(kù) —— 因?yàn)槎叩膶?shí)質(zhì)是一樣的。類比數(shù)據(jù)庫(kù)的數(shù)據(jù)表,我們的思路就有了:
將一個(gè) Sheet 看作表頭和數(shù)據(jù)兩部分,這二者分別包含表的結(jié)構(gòu)和表的數(shù)據(jù)。
對(duì)表頭(第一行),校驗(yàn)表頭信息是否和實(shí)體類的定義的屬性匹配。
對(duì)數(shù)據(jù)(剩余行),從上向下遍歷每一個(gè) Row,將每一行轉(zhuǎn)化為一個(gè)對(duì)象,每一列作為該對(duì)象的一個(gè)屬性,從而得到一個(gè)對(duì)象列表,該列表包含 Excel 中的所有數(shù)據(jù)。
接下來(lái)我們就可以按照我們的需求處理我們的數(shù)據(jù)了,如果想把操作后的數(shù)據(jù)寫回 Excel,也是一樣的邏輯。
使用 UserModel
讓我們看看如何使用 UserModel 讀取 Excel 文件。此處使用 POI 4.0.0 版本,首先引入 poi 和 poi-ooxml 依賴:
org.apache.poi
poi
4.0.0
org.apache.poi
poi-ooxml
4.0.0
我們要讀取一個(gè)簡(jiǎn)單的 Sku 信息表,內(nèi)容如下:
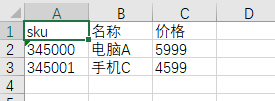
如何將 UserModel 的信息轉(zhuǎn)化為數(shù)據(jù)列表?
我們可以通過實(shí)現(xiàn)反射 + 注解的方式定義表頭到數(shù)據(jù)的映射關(guān)系,幫助我們實(shí)現(xiàn) UserModel 到數(shù)據(jù)對(duì)象的轉(zhuǎn)換。實(shí)現(xiàn)基本思路是:① 自定義注解,在注解中定義列號(hào),用來(lái)標(biāo)注實(shí)體類的每個(gè)屬性對(duì)應(yīng)在 Excel 表頭的第幾列。② 在實(shí)體類定義中,根據(jù)表結(jié)構(gòu),為每個(gè)實(shí)體類的屬性加上注解。③ 通過反射,獲取實(shí)體類的每個(gè)屬性對(duì)應(yīng)在 Excel 的列號(hào),從而到相應(yīng)的列中取得該屬性的值。
以下是簡(jiǎn)單的實(shí)現(xiàn),首先準(zhǔn)備自定義注解 ExcelCol,其中包含列號(hào)和表頭:
import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Target({ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) public @interface ExcelCol { /** * 當(dāng)前列數(shù) */ int index() default 0; /** * 當(dāng)前列的表頭名稱 */ String header() default ""; }接下來(lái),根據(jù) Sku 字段定義 Sku 對(duì)象,并添加注解,列號(hào)分別為 0,1,2,并指定表頭名稱:
import lombok.Data;
import org.shy.xlsx.annotation.ExcelCol;
@Data
public class Sku {
@ExcelCol(index = 0, header = "sku")
private Long id;
@ExcelCol(index = 1, header = "名稱")
private String name;
@ExcelCol(index = 2, header = "價(jià)格")
private Double price;
}
然后,用反射獲取表頭的每一個(gè) Field,并以列號(hào)為索引,存入 Map 中。從 Excel 的第二行開始(第一行是表頭),遍歷后面的每一行,對(duì)每一行的每個(gè)屬性,根據(jù)列號(hào)拿到對(duì)應(yīng) Cell 的值,并為數(shù)據(jù)對(duì)象賦值。根據(jù)單元格中值類型的不同,如文本 / 數(shù)字等,進(jìn)行不同的處理。以下為了簡(jiǎn)化邏輯,只對(duì)表頭出現(xiàn)的類型進(jìn)行了處理,其他情況的處理邏輯類似。全部代碼如下:
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.shy.domain.pojo.Sku;
import org.shy.xlsx.annotation.ExcelCol;
import java.io.FileInputStream;
import java.lang.reflect.Field;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MyUserModel {
public static void main(String[] args) throws Exception {
List skus = parseSkus("D:sunhaoyu8DocumentsFilesskus.xlsx");
System.out.println(JSON.toJSONString(skus));
}
public static List parseSkus(String filePath) throws Exception {
FileInputStream in = new FileInputStream(filePath);
Workbook wk = new XSSFWorkbook(in);
Sheet sheet = wk.getSheetAt(0);
// 轉(zhuǎn)換成的數(shù)據(jù)列表
List skus = new ArrayList<>();
// 獲取Sku的注解信息
Map fieldMap = new HashMap<>(16);
for (Field field : Sku.class.getDeclaredFields()) {
ExcelCol col = field.getAnnotation(ExcelCol.class);
if (col == null) {
continue;
}
field.setAccessible(true);
fieldMap.put(col.index(), field);
}
for (int rowNum = 1; rowNum <= sheet.getLastRowNum(); rowNum++) {
Row r = sheet.getRow(rowNum);
Sku sku = new Sku();
for (int cellNum = 0; cellNum < fieldMap.size(); cellNum++) {
Cell c = r.getCell(cellNum);
if (c != null) {
setFieldValue(fieldMap.get(cellNum), getCellValue(c), sku);
}
}
skus.add(sku);
}
return skus;
}
public static void setFieldValue(Field field, String value, Sku sku) throws Exception {
if (field == null) {
return;
}
//得到此屬性的類型
String type = field.getType().toString();
if (StringUtils.isBlank(value)) {
field.set(sku, null);
} else if (type.endsWith("String")) {
field.set(sku, value);
} else if (type.endsWith("long") || type.endsWith("Long")) {
field.set(sku, Long.parseLong(value));
} else if (type.endsWith("double") || type.endsWith("Double")) {
field.set(sku, Double.parseDouble(value));
} else {
field.set(sku, value);
}
}
public static String getCellValue(Cell cell) {
DecimalFormat df = new DecimalFormat("#.##");
if (cell == null) {
return "";
}
switch (cell.getCellType()) {
case NUMERIC:
return df.format(cell.getNumericCellValue());
case STRING:
return cell.getStringCellValue().trim();
case BLANK:
return null;
}
return "";
}
最后,將轉(zhuǎn)換完成的數(shù)據(jù)列表打印出來(lái)。運(yùn)行結(jié)果如下:
[{"id":345000,"name":"電腦A","price":5999.0},{"id":345001,"name":"手機(jī)C","price":4599.0}]
Tips:如果您的程序出現(xiàn) “NoClassDefFoundError”,請(qǐng)引入 ooxml-schemas 依賴:
org.apache.poi ooxml-schemas 1.4
版本選擇見下表,如 POI 4.0.0 對(duì)應(yīng) ooxml-schemas 1.4 版本:

UserModel 的局限
以上處理邏輯對(duì)于大部分的 Excel 文件都很適用,但最大的缺點(diǎn)是內(nèi)存開銷大,因?yàn)樗械臄?shù)據(jù)都被加載入內(nèi)存。實(shí)測(cè),以上 3 列的 Excel 文件在 7 萬(wàn)行左右就會(huì)出現(xiàn) OOM,而 XLS 文件最大行數(shù)為 65535 行,XLSX 更是達(dá)到了 1048576 行,如果將幾萬(wàn)甚至百萬(wàn)級(jí)別的數(shù)據(jù)全部讀入內(nèi)存,內(nèi)存溢出風(fēng)險(xiǎn)極高。
那么,該如何解決傳統(tǒng) UserModel 無(wú)法處理大批量 Excel 的問題呢?開發(fā)者們給出了許多精彩的解決方案,請(qǐng)看下一章。
三、進(jìn)階篇 - 內(nèi)存優(yōu)化的探索
接下來(lái)介紹本文重點(diǎn)內(nèi)容,同時(shí)解決本文所提出的問題:如何進(jìn)行 Excel 解析的內(nèi)存優(yōu)化,從而處理百萬(wàn)行 Excel 文件?
(1)EventModel
前面我們提到,除了 UserModel 外,POI 還提供了另一種解析 Excel 的模型:EventModel 事件模型。不同于用戶模型的 DOM 解析,事件模型采用了 SAX 的方式去解析 Excel。
EventModel & SAX 解析
SAX 的全稱是 Simple API for XML,是一種基于事件驅(qū)動(dòng)的 XML 解析方法。不同于 DOM 一次性讀入 XML,SAX 會(huì)采用邊讀取邊處理的方式進(jìn)行 XML 操作。簡(jiǎn)單來(lái)講,SAX 解析器會(huì)逐行地去掃描 XML 文檔,當(dāng)遇到標(biāo)簽時(shí)會(huì)觸發(fā)解析處理器,從而觸發(fā)相應(yīng)的事件 Handler。我們要做的就是繼承 DefaultHandler 類,重寫一系列事件處理方法,即可對(duì) Excel 文件進(jìn)行相應(yīng)的處理。
下面是一個(gè)簡(jiǎn)單的 SAX 解析的示例,這是要解析的 XML 文件:一個(gè) sku 表,其中包含兩個(gè) sku 節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)有一個(gè) id 屬性和三個(gè)子節(jié)點(diǎn)。
電腦A 5999.0 手機(jī)C 4599.0
對(duì)照 XML 結(jié)構(gòu),創(chuàng)建 Java 實(shí)體類:
import lombok.Data;
@Data
public class Sku {
private Long id;
private String name;
private Double price;
}
自定義事件處理類 SkuHandler:
import com.alibaba.fastjson.JSON;
import org.shy.domain.pojo.Sku;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SkuHandler extends DefaultHandler {
/**
* 當(dāng)前正在處理的sku
*/
private Sku sku;
/**
* 當(dāng)前正在處理的節(jié)點(diǎn)名稱
*/
private String tagName;
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if ("sku".equals(qName)) {
sku = new Sku();
sku.setId(Long.valueOf((attributes.getValue("id"))));
}
tagName = qName;
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("sku".equals(qName)) {
System.out.println(JSON.toJSONString(sku));
// 處理業(yè)務(wù)邏輯
// ...
}
tagName = null;
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if ("name".equals(tagName)) {
sku.setName(new String(ch, start, length));
}
if ("price".equals(tagName)) {
sku.setPrice(Double.valueOf(new String(ch, start, length)));
}
}
}
其中,SkuHandler 重寫了三個(gè)事件響應(yīng)方法:
startElement()—— 每當(dāng)掃描到新 XML 元素時(shí),調(diào)用此方法,傳入 XML 標(biāo)簽名稱 qName,XML 屬性列表 attributes;
characters()—— 每當(dāng)掃描到未在 XML 標(biāo)簽中的字符串時(shí),調(diào)用此方法,傳入字符數(shù)組、起始下標(biāo)和長(zhǎng)度;
endElement()—— 每當(dāng)掃描到 XML 元素的結(jié)束標(biāo)簽時(shí),調(diào)用此方法,傳入 XML 標(biāo)簽名稱 qName。
我們用一個(gè)變量 tagName 存儲(chǔ)當(dāng)前掃描到的節(jié)點(diǎn)信息,每次掃描節(jié)點(diǎn)發(fā)送變化時(shí),更新 tagName;
用一個(gè) Sku 實(shí)例維護(hù)當(dāng)前讀入內(nèi)存的 Sku 信息,每當(dāng)該 Sku 讀取完成時(shí),我們打印該 Sku 信息,并執(zhí)行相應(yīng)業(yè)務(wù)邏輯。這樣,就可以做到一次讀取一條 Sku 信息,邊解析邊處理。由于每行 Sku 結(jié)構(gòu)相同,因此,只需要在內(nèi)存維護(hù)一條 Sku 信息即可,避免了一次性把所有信息讀入內(nèi)存。
調(diào)用 SAX 解析器時(shí),使用 SAXParserFactory 創(chuàng)建解析器實(shí)例,解析輸入流即可,Main 方法如下:
import org.shy.xlsx.sax.handler.SkuHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.InputStream;
public class MySax {
public static void main(String[] args) throws Exception {
parseSku();
}
public static void parseSku() throws Exception {
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
InputStream inputStream = ClassLoader.getSystemResourceAsStream("skus.xml");
saxParser.parse(inputStream, new SkuHandler());
}
}
輸出結(jié)果如下:
{"id":345000,"name":"電腦A","price":5999.0}
{"id":345001,"name":"手機(jī)C","price":4599.0}
以上演示了 SAX 解析的基礎(chǔ)原理。EventModel 的 API 更復(fù)雜,同樣通過重寫 Event handler,實(shí)現(xiàn) SAX 解析。有興趣的讀者,請(qǐng)參見 POI 官網(wǎng)的示例代碼: https://poi.apache.org/components/spreadsheet/how-to.html
EventModel 的局限
POI 官方提供的 EventModel API 雖然使用 SAX 方式解決了 DOM 解析的問題,但是存在一些局限性:
① 屬于 low level API,抽象級(jí)別低,相對(duì)比較復(fù)雜,學(xué)習(xí)使用成本高。
② 對(duì)于 HSSF 和 XSSF 類型的處理方式不同,代碼需要根據(jù)不同類型分別做兼容。
③ 未能完美解決內(nèi)存溢出問題,內(nèi)存開銷仍有優(yōu)化空間。
④ 僅用于 Excel 解析,不支持 Excel 寫入。
因此,筆者不建議使用 POI 原生的 EventModel,至于有哪些更推薦的工具,請(qǐng)看下文。
(2)SXSSF
SXSSF 簡(jiǎn)介
SXSSF,全稱 Streaming XML SpreadSheet Format,是 POI 3.8-beta3 版本后推出的低內(nèi)存占用的流式 Excel API,旨在解決 Excel 寫入時(shí)的內(nèi)存問題。它是 XSSF 的擴(kuò)展,當(dāng)需要將大批量數(shù)據(jù)寫入 Excel 中時(shí),只需要用 SXSSF 替換 XSSF 即可。SXSSF 的原理是滑動(dòng)窗口 —— 在內(nèi)存中保存一定數(shù)量的行,其余行存儲(chǔ)在磁盤。這么做的好處是內(nèi)存優(yōu)化,代價(jià)是失去了隨機(jī)訪問的能力。SXSSF 可以兼容 XSSF 的絕大多數(shù) API,非常適合了解 UserModel 的開發(fā)者。
內(nèi)存優(yōu)化會(huì)難以避免地帶來(lái)一定限制:
① 在某個(gè)時(shí)間點(diǎn)只能訪問有限數(shù)量的行,因?yàn)槠溆嘈胁⑽幢患虞d入內(nèi)存。
② 不支持需要隨機(jī)訪問的 XSSF API,如刪除 / 移動(dòng)行、克隆 sheet、公式計(jì)算等。
③ 不支持 Excel 讀取操作。
④ 正因?yàn)樗?XSSF 的擴(kuò)展,所以不支持寫入 Xls 文件。
UserModel、EventModel、SXSSF 對(duì)比
到這里就介紹完了所有的 POI Excel API,下表是所有這些 API 的功能對(duì)比,來(lái)自 POI 官網(wǎng):
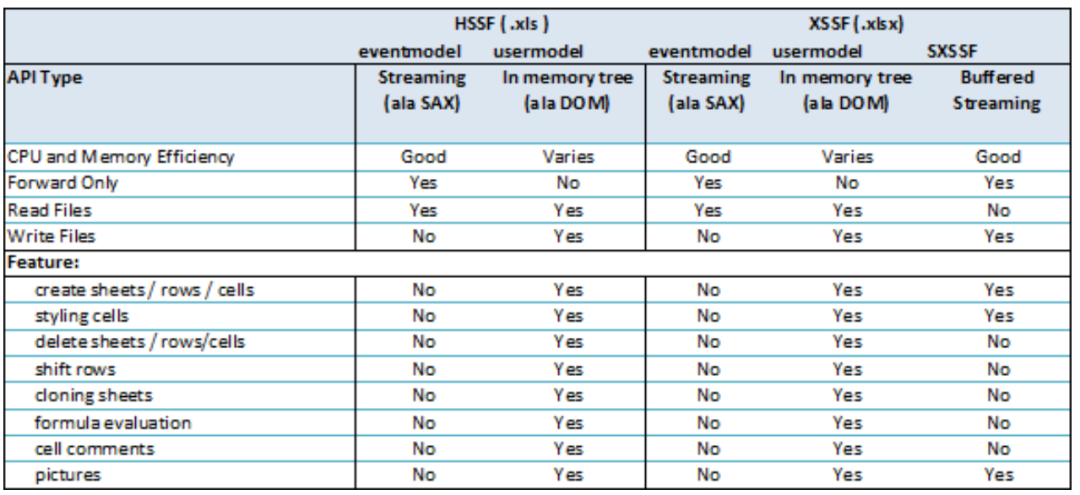
可以看到,UserModel 基于 DOM 解析,功能是最齊全的,支持隨機(jī)訪問,唯一缺點(diǎn)是 CPU 和內(nèi)存效率不穩(wěn)定;
EventModel 是 POI 提供的流式讀取方案,基于 SAX 解析,僅支持向前訪問,其余 API 不支持;
SXSSF 是 POI 提供的流式寫入方案,同樣僅能向前訪問,支持部分 XSSF API。
(3)EasyExcel
EasyExcel 簡(jiǎn)介
為了解決 POI 原生的 SAX 解析的問題,阿里基于 POI 二次開發(fā)了 EasyExcel。下面是引用自 EasyExcel 官網(wǎng)的介紹:
Java 解析、生成 Excel 比較有名的框架有 Apache poi、jxl。但他們都存在一個(gè)嚴(yán)重的問題就是非常的耗內(nèi)存,poi 有一套 SAX 模式的 API 可以一定程度的解決一些內(nèi)存溢出的問題,但 POI 還是有一些缺陷,比如 07 版 Excel 解壓縮以及解壓后存儲(chǔ)都是在內(nèi)存中完成的,內(nèi)存消耗依然很大。easyexcel 重寫了 poi 對(duì) 07 版 Excel 的解析,一個(gè) 3M 的 excel 用 POI sax 解析依然需要 100M 左右內(nèi)存,改用 easyexcel 可以降低到幾 M,并且再大的 excel 也不會(huì)出現(xiàn)內(nèi)存溢出;03 版依賴 POI 的 sax 模式,在上層做了模型轉(zhuǎn)換的封裝,讓使用者更加簡(jiǎn)單方便。
如介紹所言,EasyExcel 同樣采用 SAX 方式解析,但由于重寫了 xlsx 的 SAX 解析,優(yōu)化了內(nèi)存開銷;對(duì) xls 文件,在上層進(jìn)一步進(jìn)行了封裝,降低了使用成本。API 上,采用注解的方式去定義 Excel 實(shí)體類,使用方便;通過事件監(jiān)聽器的方式做 Excel 讀取,相比于原生 EventModel,API 大大簡(jiǎn)化;寫入數(shù)據(jù)時(shí),EasyExcel 對(duì)大批數(shù)據(jù),通過重復(fù)多次寫入的方式從而降低內(nèi)存開銷。
EasyExcel 最大的優(yōu)勢(shì)是使用簡(jiǎn)便,十分鐘可以上手。由于對(duì) POI 的 API 都做了高級(jí)封裝,所以適合不想了解 POI 基礎(chǔ) API 的開發(fā)者。總之,EasyExcel 是一款值得一試的 API。
使用 EasyExcel
引入 easyexcel 依賴:
com.alibaba easyexcel 2.2.3
首先,用注解定義 Excel 實(shí)體類:
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Data;
@Data
public class Sku {
@ExcelProperty(index = 0)
private Long id;
@ExcelProperty(index = 1)
private String name;
@ExcelProperty(index = 2)
private Double price;
}
接下來(lái),重寫 AnalysisEventListener 中的 invoke 和 doAfterAllAnalysed 方法,這兩個(gè)方法分別在監(jiān)聽到單行解析完成的事件時(shí)和全部解析完成的事件時(shí)調(diào)用。每次單行解析完成時(shí),我們打印解析結(jié)果,代碼如下:
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.fastjson.JSON;
import org.shy.domain.pojo.easyexcel.Sku;
public class MyEasyExcel {
public static void main(String[] args) {
parseSku();
}
public static void parseSku() {
//讀取文件路徑
String fileName = "D:sunhaoyu8DocumentsFilesexcel.xlsx";
//讀取excel
EasyExcel.read(fileName, Sku.class, new AnalysisEventListener() {
@Override
public void invoke(Sku sku, AnalysisContext analysisContext) {
System.out.println("第" + analysisContext.getCurrentRowNum() + "行:" + JSON.toJSONString(sku));
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
System.out.println("全部解析完成");
}
}).sheet().doRead();
}
}
測(cè)驗(yàn)一下,用它解析一個(gè)十萬(wàn)行的 excel,該文件用 UserModel 讀取會(huì) OOM,如下:
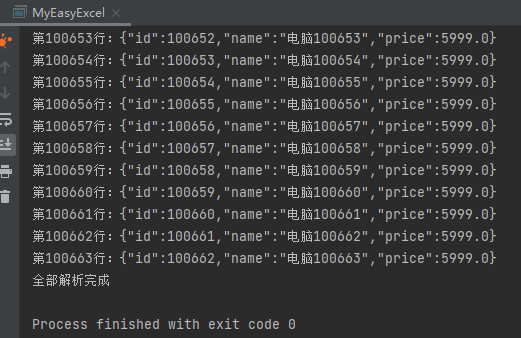
運(yùn)行結(jié)果:
(4)Xlsx-streamer
Xlsx-streamer 簡(jiǎn)介
Xlsx-streamer 是一款用于流式讀取 Excel 的工具,同樣基于 POI 二次開發(fā)。雖然 EasyExcel 可以很好地解決 Excel 讀取的問題,但解析方式為 SAX,需要通過實(shí)現(xiàn)監(jiān)聽器以事件驅(qū)動(dòng)的方式進(jìn)行解析。有沒有其他的解析方式呢?Xlsx-streamer 給出了答案。
譯自官方文檔的描述:
如果您過去曾使用 Apache POI 讀取 Excel 文件,您可能會(huì)注意到它的內(nèi)存效率不是很高。閱讀整個(gè)工作簿會(huì)導(dǎo)致嚴(yán)重的內(nèi)存使用高峰,這會(huì)對(duì)服務(wù)器造成嚴(yán)重破壞。Apache 必須讀取整個(gè)工作簿的原因有很多,但其中大部分與該庫(kù)允許您使用隨機(jī)地址進(jìn)行讀寫有關(guān)。如果(且僅當(dāng))您只想以快速且內(nèi)存高效的方式讀取 Excel 文件的內(nèi)容,您可能不需要此功能。不幸的是,POI 庫(kù)中唯一用于讀取流式工作簿的東西要求您的代碼使用類似 SAX 的解析器。該 API 中缺少所有友好的類,如 Row 和 Cell。該庫(kù)充當(dāng)該流式 API 的包裝器,同時(shí)保留標(biāo)準(zhǔn) POI API 的語(yǔ)法。繼續(xù)閱讀,看看它是否適合您。注意:這個(gè)庫(kù)只支持讀取 XLSX 文件。
如介紹所言,Xlsx-streamer 最大的便利之處是兼容了用戶使用 POI UserModel 的習(xí)慣,它對(duì)所有的 UserModel 接口都給出了自己的流式實(shí)現(xiàn),如 StreamingSheet、StreamingRow 等,對(duì)于熟悉 UserModel 的開發(fā)者來(lái)說(shuō),幾乎沒有學(xué)習(xí)門檻,可以直接使用 UserModel 訪問 Excel。
Xlsx-streamer 的實(shí)現(xiàn)原理和 SXSSF 相同,都是滑動(dòng)窗口 —— 限定讀入內(nèi)存中的數(shù)據(jù)大小,將正在解析的數(shù)據(jù)讀到內(nèi)存緩沖區(qū)中,形成一個(gè)臨時(shí)文件,以防止大量使用內(nèi)存。緩沖區(qū)的內(nèi)容會(huì)隨著解析的過程不斷變化,當(dāng)流關(guān)閉后,臨時(shí)文件也將被刪除。由于內(nèi)存緩沖區(qū)的存在,整個(gè)流不會(huì)被完整地讀入內(nèi)存,從而防止了內(nèi)存溢出。
與 SXSSF 一樣,因?yàn)閮?nèi)存中僅加載入部分行,故犧牲了隨機(jī)訪問的能力,僅能通過遍歷順序訪問整表,這是不可避免的局限。換言之,如果調(diào)用 StreamingSheet.getRow (int rownum) 方法,該方法會(huì)獲取 sheet 的指定行,會(huì)拋出 “不支持該操作” 的異常。
Xlsx-streamer 最大的優(yōu)勢(shì)是兼容 UserModel,尤其適合那些熟悉 UserModel 又不想使用繁瑣的 EventModel 的開發(fā)者。它和 SXSSF 一樣,都通過實(shí)現(xiàn) UserModel 接口的方式給出解決內(nèi)存問題的方案,很好地填補(bǔ)了 SXSSF 不支持讀取的空白,可以說(shuō)它是 “讀取版” 的 SXSSF。
使用 Xlsx-streamer
引入 pom 依賴:
com.monitorjbl
xlsx-streamer
2.1.0
下面是一個(gè)使用 xlsx-streamer 的 demo:
import com.monitorjbl.xlsx.StreamingReader;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import java.io.FileInputStream;
public class MyXlsxStreamer {
public static void main(String[] args) throws Exception {
parseSku();
}
public static void parseSku() throws Exception {
FileInputStream in = new FileInputStream("D:sunhaoyu8DocumentsFilesexcel.xlsx");
Workbook wk = StreamingReader.builder()
//緩存到內(nèi)存中的行數(shù),默認(rèn)是10
.rowCacheSize(100)
//讀取資源時(shí),緩存到內(nèi)存的字節(jié)大小,默認(rèn)是1024
.bufferSize(4096)
//打開資源,必須,可以是InputStream或者是File
.open(in);
Sheet sheet = wk.getSheetAt(0);
for (Row r : sheet) {
System.out.print("第" + r.getRowNum() + "行:");
for (Cell c : r) {
if (c != null) {
System.out.print(c.getStringCellValue() + " ");
}
}
System.out.println();
}
}
}
如代碼所示,Xlsx-streamer 的使用方法為:使用 StreamingReader 進(jìn)行參數(shù)配置和流式讀取,我們可以手動(dòng)配置固定的滑動(dòng)窗口大小,有兩個(gè)指標(biāo),分別是緩存在內(nèi)存中的最大行數(shù)和緩存在內(nèi)存的最大字節(jié)數(shù),這兩個(gè)指標(biāo)會(huì)同時(shí)限制該滑動(dòng)窗口的上限。接下來(lái),我們可以使用 UserModel 的 API 去遍歷訪問讀到的表格。
使用十萬(wàn)行量級(jí)的 excel 文件實(shí)測(cè)一下,運(yùn)行結(jié)果:
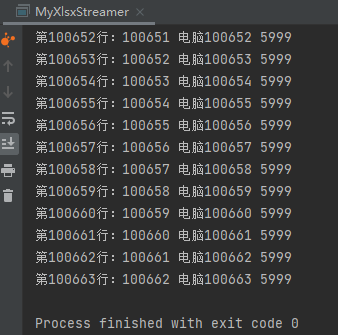
StAX 解析
Xlsx-streamer 底層采用的解析方式,被稱作 StAX 解析。StAX 于 2004 年 3 月在 JSR 173 規(guī)范中引入,是 JDK 6.0 推出的新特性。它的全稱是 Streaming API for XML,流式 XML 解析。更準(zhǔn)確地講,稱作 “流式拉分析”。之所以稱作拉分析,是因?yàn)樗?“流式推分析”——SAX 解析相對(duì)。
之前我們提到,SAX 解析是一種事件驅(qū)動(dòng)的解析模型,每當(dāng)解析到標(biāo)簽時(shí)都會(huì)觸發(fā)相應(yīng)的事件 Handler,將事件 “推” 給響應(yīng)器。在這樣的推模型中,解析器是主動(dòng),響應(yīng)器是被動(dòng),我們不能選擇想要響應(yīng)哪些事件,因此這樣的解析比較不靈活。
為了解決 SAX 解析的問題,StAX 解析采用了 “拉” 的方式 —— 由解析器遍歷流時(shí),原來(lái)的響應(yīng)器變成了驅(qū)動(dòng)者,主動(dòng)遍歷事件解析器(迭代器),從中拉取一個(gè)個(gè)事件并處理。在解析過程中,StAX 支持使用 peek () 方法來(lái) "偷看" 下一個(gè)事件,從而決定是否有必要分析下一個(gè)事件,而不必從流中讀取事件。這樣可以有效提高靈活性和效率。
下面用 StAX 的方式再解析一下相同的 XML:
電腦A 5999.0 手機(jī)C 4599.0
這次我們不需要監(jiān)聽器,把所有處理的邏輯集成在一個(gè)方法中:
import com.alibaba.fastjson.JSON; import org.apache.commons.lang3.StringUtils; import org.shy.domain.pojo.Sku; import javax.xml.stream.XMLEventReader; import javax.xml.stream.XMLInputFactory; import javax.xml.stream.events.Attribute; import javax.xml.stream.events.StartElement; import javax.xml.stream.events.XMLEvent; import java.io.InputStream; import java.util.Iterator; public class MyStax { /** * 當(dāng)前正在處理的sku */ private static Sku sku; /** * 當(dāng)前正在處理的節(jié)點(diǎn)名稱 */ private static String tagName; public static void main(String[] args) throws Exception { parseSku(); } public static void parseSku() throws Exception { XMLInputFactory inputFactory = XMLInputFactory.newInstance(); InputStream inputStream = ClassLoader.getSystemResourceAsStream("skus.xml"); XMLEventReader xmlEventReader = inputFactory.createXMLEventReader(inputStream); while (xmlEventReader.hasNext()) { XMLEvent event = xmlEventReader.nextEvent(); // 開始節(jié)點(diǎn) if (event.isStartElement()) { StartElement startElement = event.asStartElement(); String name = startElement.getName().toString(); if ("sku".equals(name)) { sku = new Sku(); Iterator iterator = startElement.getAttributes(); while (iterator.hasNext()) { Attribute attribute = (Attribute) iterator.next(); if ("id".equals(attribute.getName().toString())) { sku.setId(Long.valueOf(attribute.getValue())); } } } tagName = name; } // 字符 if (event.isCharacters()) { String data = event.asCharacters().getData().trim(); if (StringUtils.isNotEmpty(data)) { if ("name".equals(tagName)) { sku.setName(data); } if ("price".equals(tagName)) { sku.setPrice(Double.valueOf(data)); } } } // 結(jié)束節(jié)點(diǎn) if (event.isEndElement()) { String name = event.asEndElement().getName().toString(); if ("sku".equals(name)) { System.out.println(JSON.toJSONString(sku)); // 處理業(yè)務(wù)邏輯 // ... } } } } }
以上代碼與 SAX 解析的邏輯是等價(jià)的,用 XMLEventReader 作為迭代器從流中讀取事件,循環(huán)遍歷事件迭代器,再根據(jù)事件類型做分類處理。有興趣的小伙伴可以自己動(dòng)手嘗試一下,探索更多 StAX 解析的細(xì)節(jié)。
四、結(jié)論
EventModel、SXSSF、EasyExcel 和 Xlsx-streamer 分別針對(duì) UserModel 的內(nèi)存占用問題給出了各自的解決方案,下面是對(duì)所有本文提到的 Excel API 的對(duì)比:
| UserModel | EventModel | SXSSF | EasyExcel | Xlsx-streamer | |
|---|---|---|---|---|---|
| 內(nèi)存占用量 | 高 | 較低 | 低 | 低 | 低 |
| 全表隨機(jī)訪問 | 是 | 否 | 否 | 否 | 否 |
| 讀 Excel | 是 | 是 | 否 | 是 | 是 |
| 讀取方式 | DOM | SAX | -- | SAX | StAX |
| 寫 Excel | 是 | 是 | 是 | 是 | 否 |
建議您根據(jù)自己的使用場(chǎng)景選擇適合的 API:
處理大批量 Excel 文件的需求,推薦選擇 POI UserModel、EasyExcel;
讀取大批量 Excel 文件,推薦選擇 EasyExcel、Xlsx-streamer;
寫入大批量 Excel 文件,推薦選擇 SXSSF、EasyExcel。
使用以上 API,一定可以滿足關(guān)于 Excel 開發(fā)的需求。當(dāng)然 Excel API 不止這些,還有許多同類型的 API,歡迎大家多多探索和創(chuàng)新。
審核編輯:湯梓紅
-
JAVA
+關(guān)注
關(guān)注
20文章
2986瀏覽量
107055 -
API
+關(guān)注
關(guān)注
2文章
1563瀏覽量
63597 -
Excel
+關(guān)注
關(guān)注
4文章
225瀏覽量
56408 -
開源
+關(guān)注
關(guān)注
3文章
3624瀏覽量
43532
原文標(biāo)題:聊聊Excel解析:如何處理百萬(wàn)行EXCEL文件?
文章出處:【微信號(hào):OSC開源社區(qū),微信公眾號(hào):OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Python利用pandas讀寫Excel文件

利用labview中的屬性節(jié)點(diǎn)寫入EXCEL后,Excel在文件里就打不開。
請(qǐng)問labview如何處理Excel數(shù)據(jù)?
TDMS文件通過Excel查看
大型網(wǎng)站如何處理每天數(shù)百萬(wàn)的訪問量?
Excel文件受損基本急救方法有哪些
基于Java反射機(jī)制的Excel文件導(dǎo)出實(shí)現(xiàn)_楊敏煜
如何使用Python和pandas庫(kù)操作Excel文件
用Labview開發(fā)的DBC文件轉(zhuǎn)Excel表格文件的VI
Spire.Cloud.Excel云端Excel文檔處理SDK






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論