 Temporal-Shift-Module在 FPGA上解決視頻理解問題的實用性和性能
Temporal-Shift-Module在 FPGA上解決視頻理解問題的實用性和性能
在這個項目中,將在線和離線 TSM 網絡部署到 FPGA,通過 2D CNN 執行視頻理解任務。
介紹
在這個項目中,展示了 Temporal-Shift-Module ( https://hanlab.mit.edu/projects/tsm/)在 FPGA 上解決視頻理解問題的實用性和性能。
TSM 是一種網絡結構,可以通過 2D CNN 有效學習時間關系。在較高級別上,這是通過一次對單個幀(在線 TSM)或多個幀(離線 TSM)執行推理并在這些張量流經網絡時在這些張量之間轉移激活來完成的。這是通過將shift操作插入 2D 主干網的bottleneck層(在本例中為 mobilenetv2 和 resnet50)來完成的。然后,該shift操作會打亂時間相鄰幀之間的部分輸入通道。
詳細的解析可以看下面的文章:
?
https://zhuanlan.zhihu.com/p/64525610
?
將這樣的模型部署到 FPGA 可以帶來許多好處。首先,由于 TSM 已經在功效方面帶來了巨大優勢,部署到 FPGA 可以進一步推動這一點。
TSM網絡結構
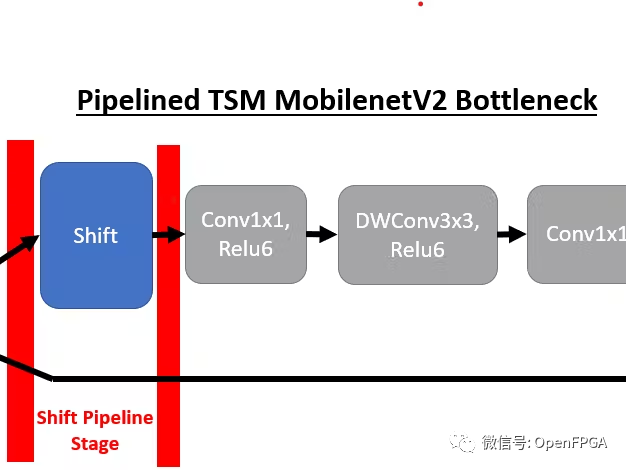
我們將首先回顧這些 TSM 網絡的底層結構以及到 DPU 兼容實現的轉換。TSM 網絡的核心結構是插入骨干模型bottleneck層中的時間shift模塊,以實現時間建模。例如,插入shift操作后,TSM MobilenetV2 bottleneck層具有以下結構:
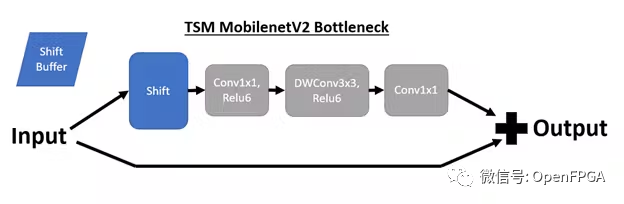
Online Shift
在演示的在線 TSM 網絡中,如果我們處于時間步驟 T,我們也處于推理輪 T。shift模塊將輸入通道的前 1/8 移位到包含來自上一推理輪的相同通道的shift緩沖區( T – 1)。然后,第 (T – 1) 輪的內容被移入 T 輪的當前張量。
Offline Shift
對于離線 TSM,如 resnet50 演示(當前禁用)中所使用的,shift緩沖區被繞過。相反,我們將N 個相鄰的時間步驟作為批次中的張量進行處理。通道可以在批次內直接移動,而不是將步驟 (T – 1) 中的通道存儲在緩沖區中。此外,這使得能夠訪問批次內的未來回合(即推理步驟 T 可以與步驟 T + 1 存在于同一批次中)。通過這種訪問,離線shift也會將通道從步驟 T + 1 移位到步驟 T 的張量中。
DPU模型優化
為了將TSM部署到 DPU,需要對原始 TSM 模型進行兩項重大更改。第一個是將shift模塊與網絡分離,因為我們無法使用支持的張量流操作來實現shift操作。為了實現這一目標,我們在每次出現shift模塊時對模型進行管道化。
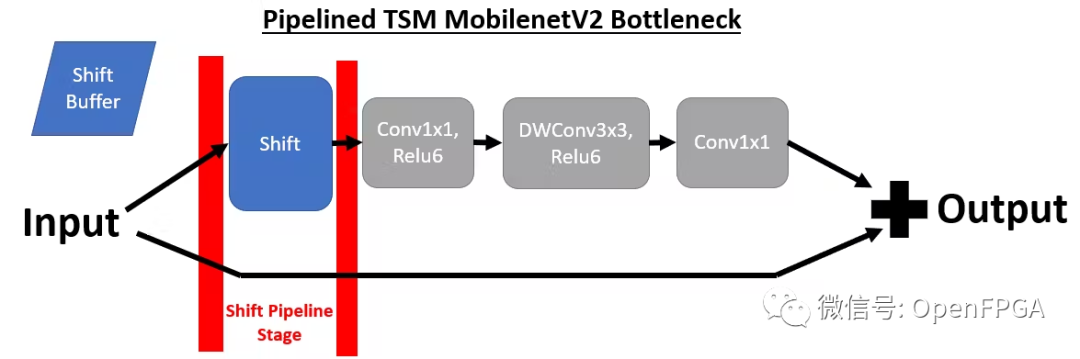
通過將shift模塊放置在其自己的管道階段,我們可以靈活地從 DPU 內核卸載shift操作。下面我們可以看到 MobilenetV2 在線 TSM 的前 4 個管道階段(從右到左)。如果比較兩個bottleneck層實現,并刪除shift操作,則這對應于以下轉換,其中bottleneck層在移位模塊之前包含 1 個輸出,在shift模塊之后包含 2 個輸入。一個輸入包含來自頂部分支的移位后張量,另一個輸入包含底部分支中未移位的殘差張量。
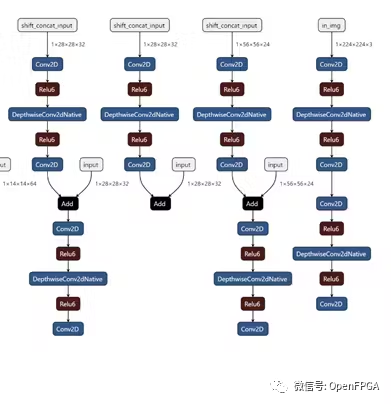
為簡單起見,這里我們使用 mobilenetV2 主干網來可視化 TSM,但 resnet-50 主干網也使用相同的方法。
為了實現這種流水線結構, Tensorflow 模型中有一個標志,指示我們是否要生成不包括移位操作的拆分模型(用于 DPU 部署)或在 Tensorflow 中實現移位操作的普通統一模型。如果設置了分割標志,則在每次移位操作之前添加新的輸出,并在移位后添加新的占位符,其中輸入移位后的輸入。
因為移位(shift)模塊僅插入到類似于上面所示的 3 級 MobilenetV2 瓶頸的結構中,所以邏輯的實現得到了簡化。然而,對于 resnet 模型,我們確保在快捷路徑中的歸約邏輯之后插入移位管道階段。由于移位+卷積路徑在瓶頸層完成之前獨立于快捷路徑,因此快捷路徑上的操作可以放置在3個階段中的任何一個中。
DPU量化策略
雖然如上所述對模型進行流水線化簡化了轉換實現,但由于我們的網絡不再是單個內核,因此使 DPU 部署變得復雜。相反,我們為每個管道階段都有一個內核,無需進行移位操作(MobilenetV2 為 11,resnet50 為 17)。
為了量化這樣的網絡,我們必須為每個內核提供未量化的輸入。為了生成這些信息,我們的模型可以在沒有管道階段的情況下生成。然后,我們直接在 Tensorflow 中對來自真實校準數據集的幀進行推理,但是我們在每個管道邊界轉儲中間網絡狀態。轉儲的狀態包括需要饋送到 vai_q_tensorflow 的節點名稱等元數據以及相應的張量數據。當在校準集中重復推理時,所有這些信息都會被“波及”。
轉儲此中間推理信息后,我們獲得了輸入 vai_q_tensorflow 的每個內核的輸入張量。該邏輯全部由我們的tensorflow模型腳本和quantize_split.sh腳本中的DUMP_QUANTIZE標志處理(項目結構在“Deployment”部分中描述)。一旦對所有內核運行量化,我們就可以為每個內核生成一個 ELF 文件,就可以集成到我們的主代碼中。
演示
下面我們介紹 2 個平臺(ZCU104 和 Ultra96V2)和 2 個模型(MobilenetV2 Online TSM 和 Resnet50 Offline TSM)的性能細分。我們將 FPS 計算為 1/(預處理 + 推理延遲)。
MobilenetV2 在線 TSM 延遲:
ZCU104 (60.1 FPS) - B4096,300MHz,RAM 高,啟用所有功能

Ultra96V2 (38.4 FPS) - B2304,300MHz,RAM 低,啟用所有功能

現在,我們可以將推理延遲與之前在移動設備和 NVIDIA Jetson 平臺上收集的 TSM 數據進行比較。
-
FPGA
+關注
關注
1643文章
21983瀏覽量
614672 -
模塊
+關注
關注
7文章
2784瀏覽量
49757 -
網絡
+關注
關注
14文章
7780瀏覽量
90479
原文標題:在這個項目中,將在線和離線 TSM 網絡部署到 FPGA,通過 2D CNN 執行視頻理解任務。
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
利用ADI μModule穩壓器優化FPGA電源設計

Labview FPGA Module有人用過嗎?
深刻認識Shift RAM學習筆記
簡單語法怎么理解
SPI slave無法理解語法
實用性很強的程序分享!
在視頻監控系統中使用FPGA進行視頻處理
XtremeDSP視頻入門套件(VSK)加速FPGA上的視頻
通過XtremeDSP視頻入門套件加速FPGA上的視頻應用開發


FPGA視頻教程之FPGA在視頻圖像處理領域的應用視頻資料說明





 工商網監
工商網監
評論