") 10個(gè)Python自動(dòng)探索性數(shù)據(jù)分析神庫!
10個(gè)Python自動(dòng)探索性數(shù)據(jù)分析神庫!
探索性數(shù)據(jù)分析是數(shù)據(jù)科學(xué)模型開發(fā)和數(shù)據(jù)集研究的重要組成部分之一。在拿到一個(gè)新數(shù)據(jù)集時(shí)首先就需要花費(fèi)大量時(shí)間進(jìn)行EDA來研究數(shù)據(jù)集中內(nèi)在的信息。自動(dòng)化的EDA Python包可以用幾行Python代碼執(zhí)行EDA。
在本文中整理了10個(gè)可以自動(dòng)執(zhí)行EDA并生成有關(guān)數(shù)據(jù)的見解的Python包,看看他們都有什么功能,能在多大程度上幫我們自動(dòng)化解決EDA的需求。
DTale
Pandas-profiling
sweetviz
autoviz
dataprep
KLib
dabl
speedML
datatile
edaviz
1、D-Tale
D-Tale使用Flask作為后端、React前端并且可以與ipython notebook和終端無縫集成。D-Tale可以支持Pandas的DataFrame, Series, MultiIndex, DatetimeIndex和RangeIndex。
importdtale importpandasaspd dtale.show(pd.read_csv("titanic.csv"))

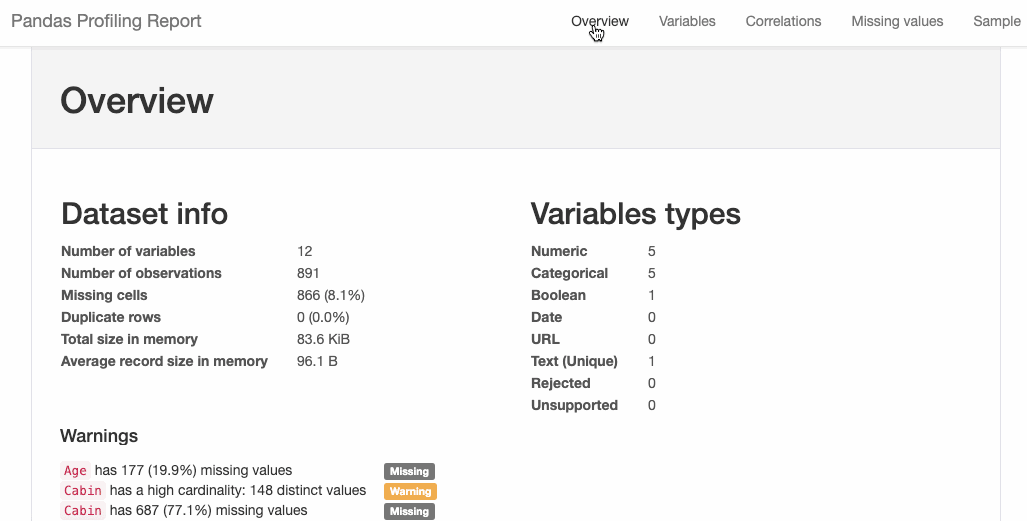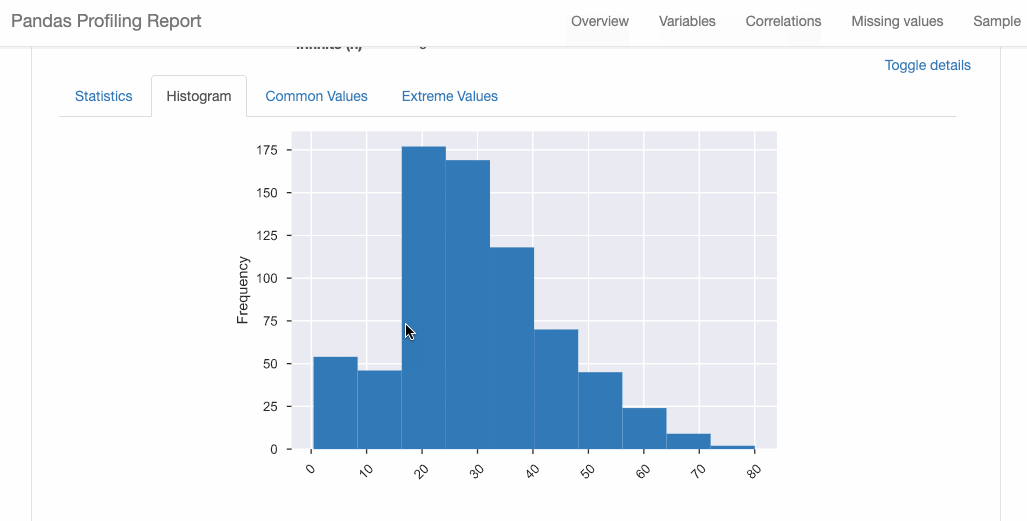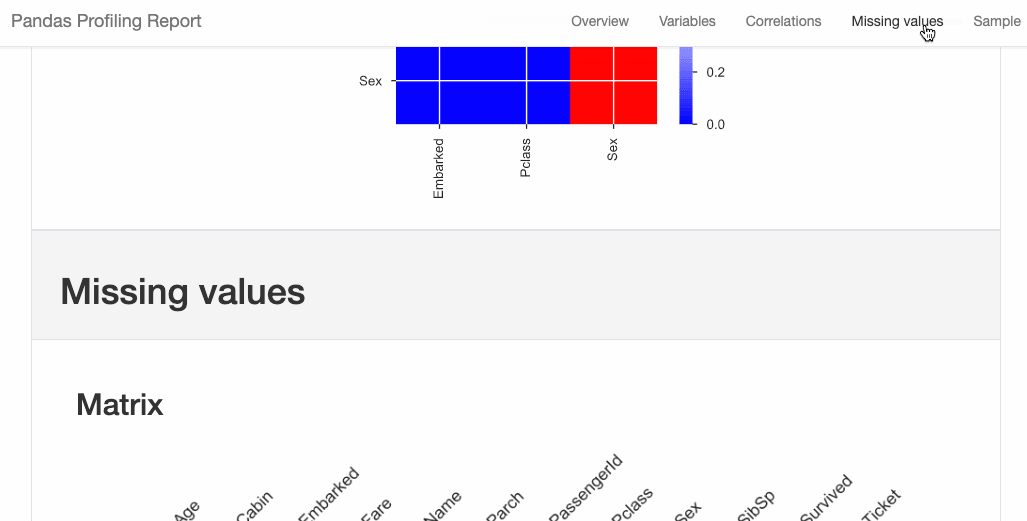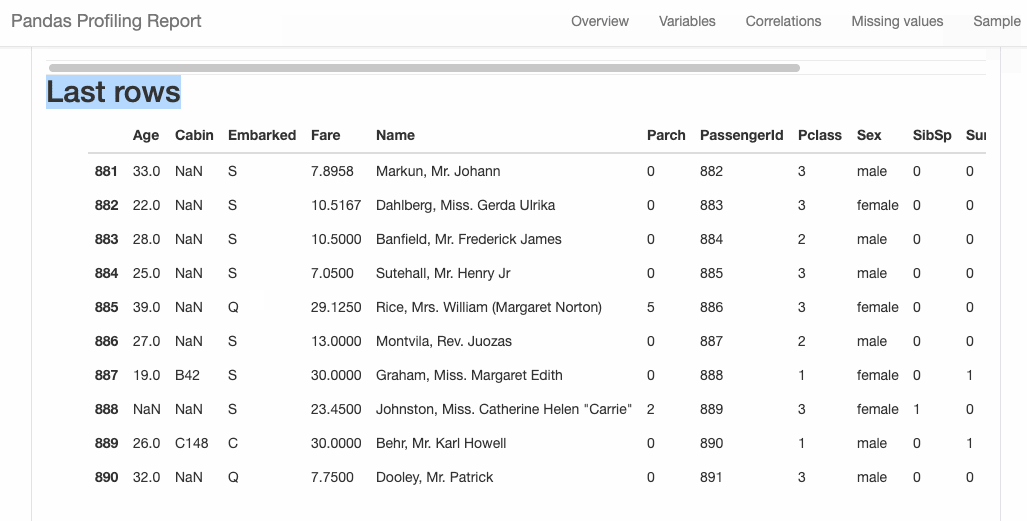
D-Tale庫用一行代碼就可以生成一個(gè)報(bào)告,其中包含數(shù)據(jù)集、相關(guān)性、圖表和熱圖的總體總結(jié),并突出顯示缺失的值等。D-Tale還可以為報(bào)告中的每個(gè)圖表進(jìn)行分析,上面截圖中我們可以看到圖表是可以進(jìn)行交互操作的。 2、Pandas-Profiling Pandas-Profiling可以生成Pandas DataFrame的概要報(bào)告。panda-profiling擴(kuò)展了pandas DataFrame df.profile_report(),并且在大型數(shù)據(jù)集上工作得非常好,它可以在幾秒鐘內(nèi)創(chuàng)建報(bào)告。#Installthebelowlibariesbeforeimporting importpandasaspd frompandas_profilingimportProfileReport #EDAusingpandas-profiling profile=ProfileReport(pd.read_csv('titanic.csv'),explorative=True) #SavingresultstoaHTMLfile profile.to_file("output.html")
3、Sweetviz Sweetviz是一個(gè)開源的Python庫,只需要兩行Python代碼就可以生成漂亮的可視化圖,將EDA(探索性數(shù)據(jù)分析)作為一個(gè)HTML應(yīng)用程序啟動(dòng)。Sweetviz包是圍繞快速可視化目標(biāo)值和比較數(shù)據(jù)集構(gòu)建的。
importpandasaspd importsweetvizassv #EDAusingAutoviz sweet_report=sv.analyze(pd.read_csv("titanic.csv")) #SavingresultstoHTMLfile sweet_report.show_html('sweet_report.html') Sweetviz庫生成的報(bào)告包含數(shù)據(jù)集、相關(guān)性、分類和數(shù)字特征關(guān)聯(lián)等的總體總結(jié)。

4、AutoViz
Autoviz包可以用一行代碼自動(dòng)可視化任何大小的數(shù)據(jù)集,并自動(dòng)生成HTML、bokeh等報(bào)告。用戶可以與AutoViz包生成的HTML報(bào)告進(jìn)行交互。importpandasaspd fromautoviz.AutoViz_ClassimportAutoViz_Class #EDAusingAutoviz autoviz=AutoViz_Class().AutoViz('train.csv')
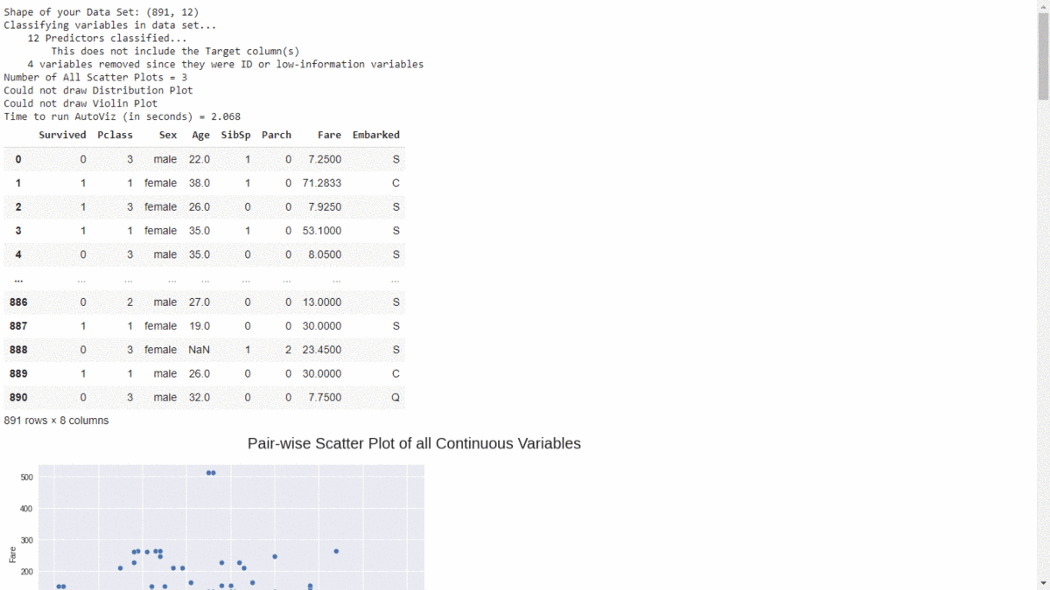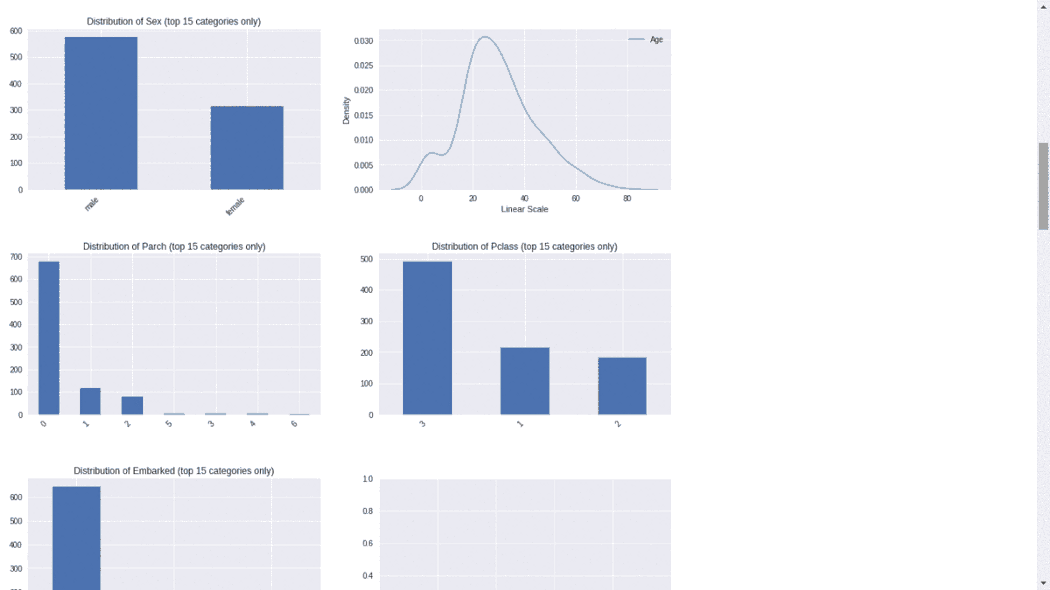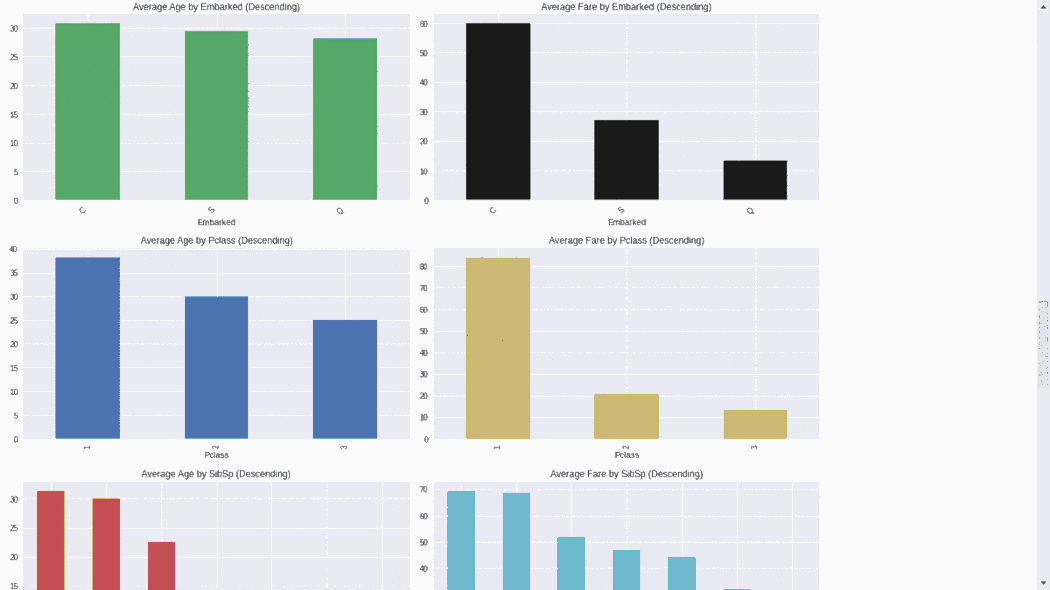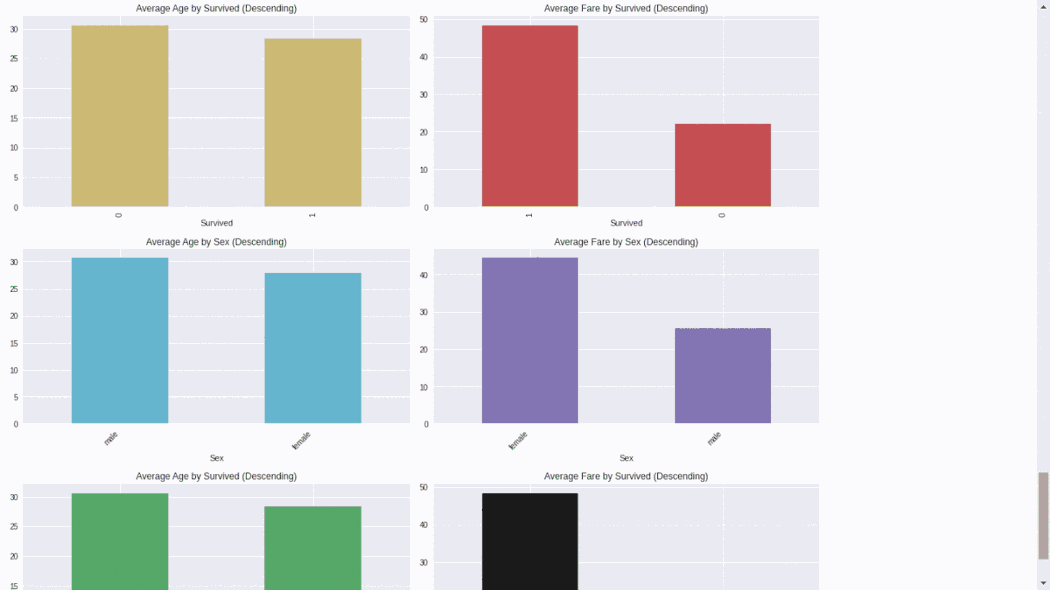
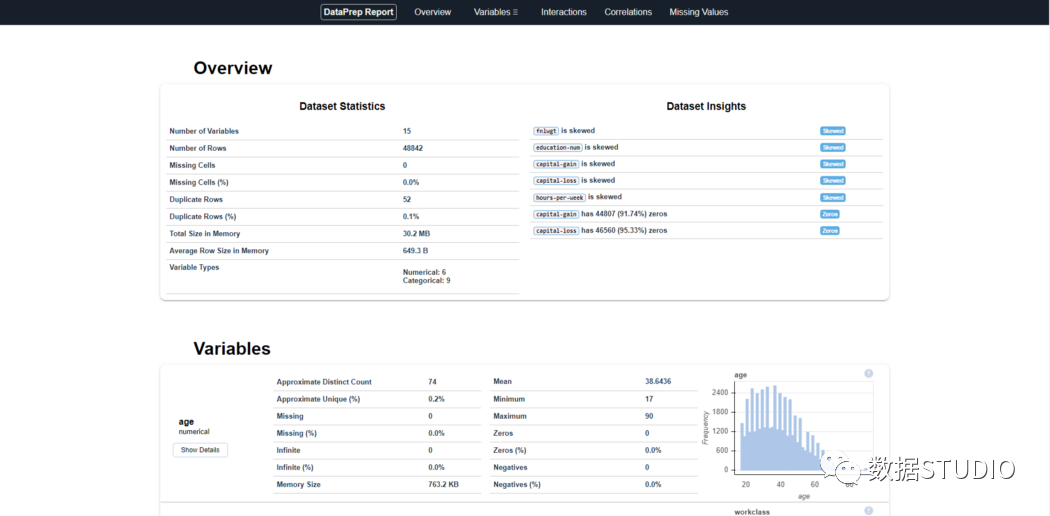
5、Dataprep Dataprep是一個(gè)用于分析、準(zhǔn)備和處理數(shù)據(jù)的開源Python包。DataPrep構(gòu)建在Pandas和Dask DataFrame之上,可以很容易地與其他Python庫集成。 DataPrep的運(yùn)行速度這10個(gè)包中最快的,他在幾秒鐘內(nèi)就可以為Pandas/Dask DataFrame生成報(bào)告。
fromdataprep.datasetsimportload_dataset fromdataprep.edaimportcreate_report df=load_dataset("titanic.csv") create_report(df).show_browser()
6、Klib
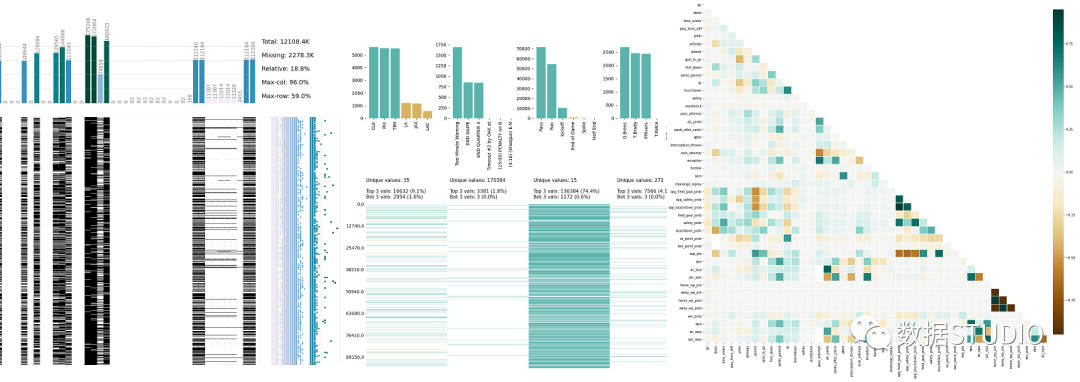
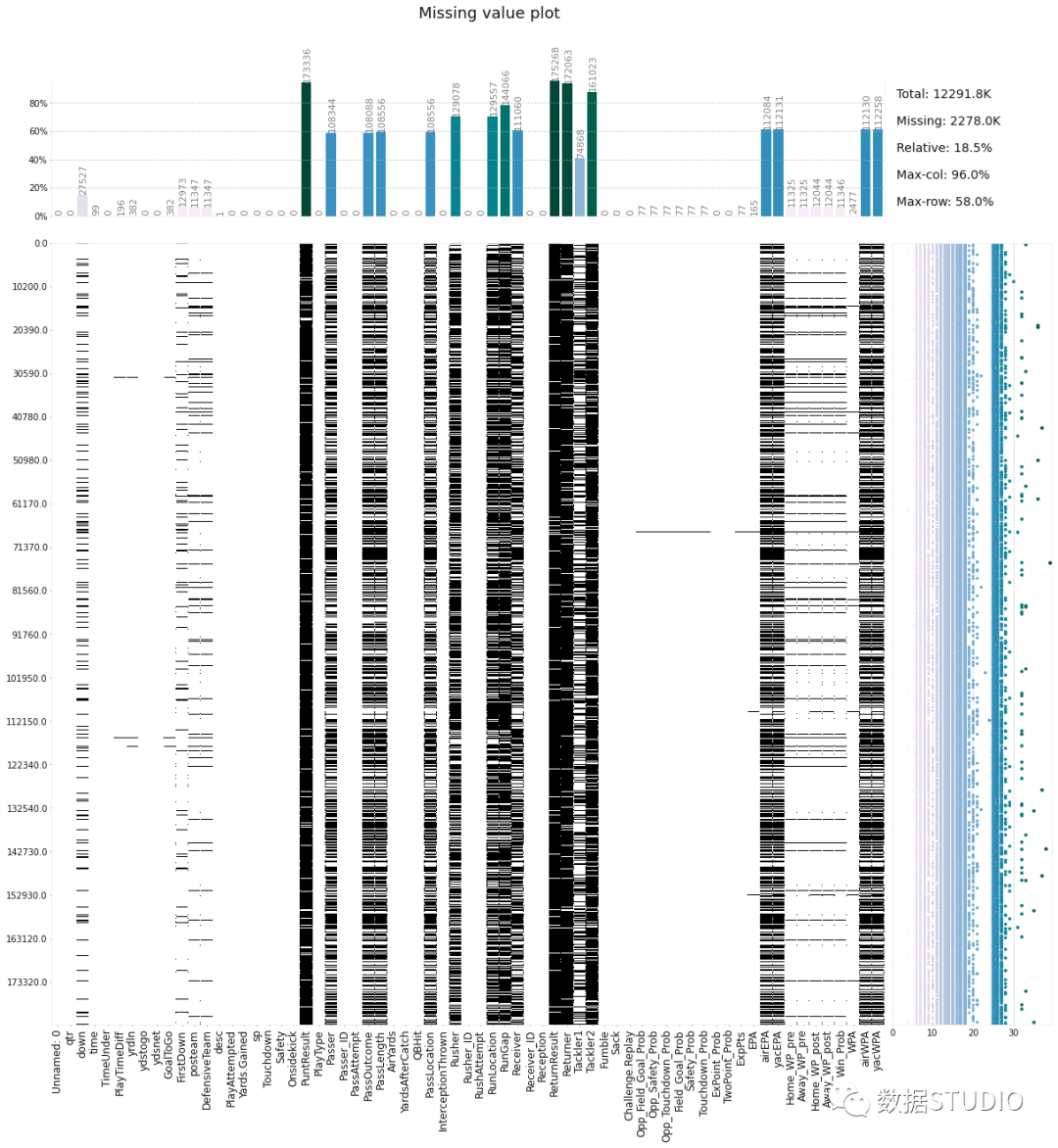
klib是一個(gè)用于導(dǎo)入、清理、分析和預(yù)處理數(shù)據(jù)的Python庫。importklib importpandasaspd df=pd.read_csv('DATASET.csv') klib.missingval_plot(df)
klib.corr_plot(df_cleaned,annot=False)
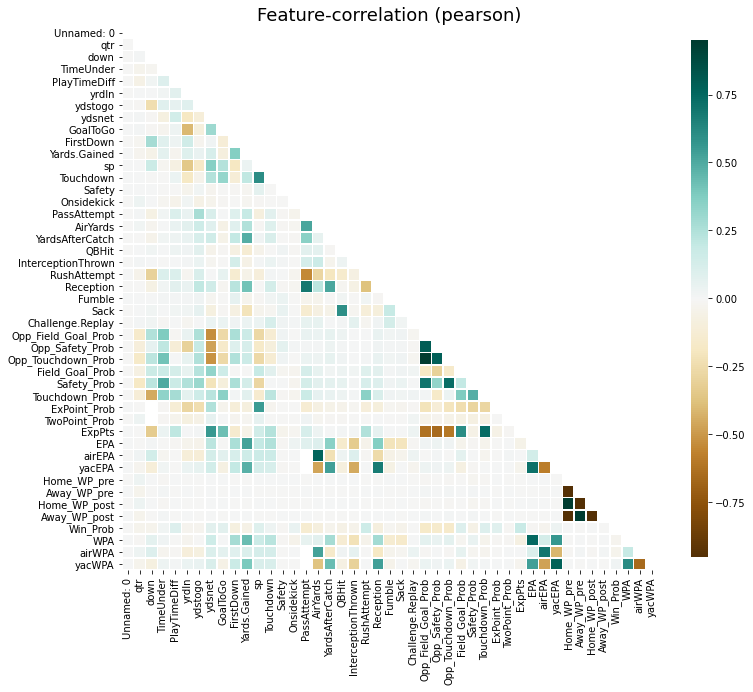
klib.dist_plot(df_cleaned['Win_Prob'])

klib.cat_plot(df,figsize=(50,15))
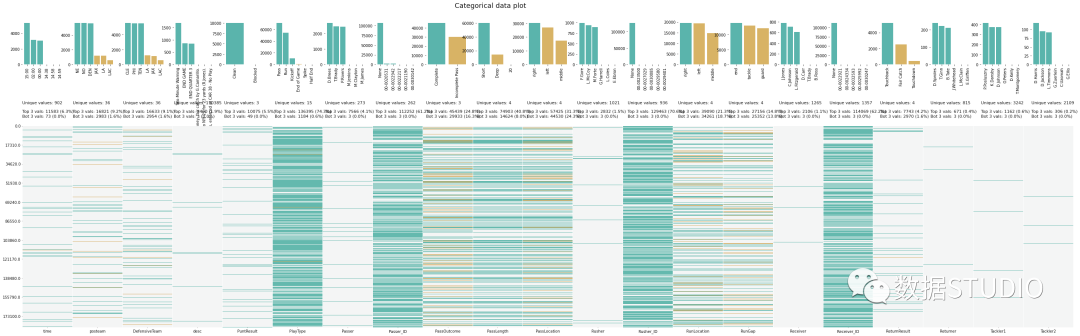
klibe雖然提供了很多的分析函數(shù),但是對(duì)于每一個(gè)分析需要我們手動(dòng)的編寫代碼,所以只能說是半自動(dòng)化的操作,但是如果我們需要更定制化的分析,他是非常方便的。
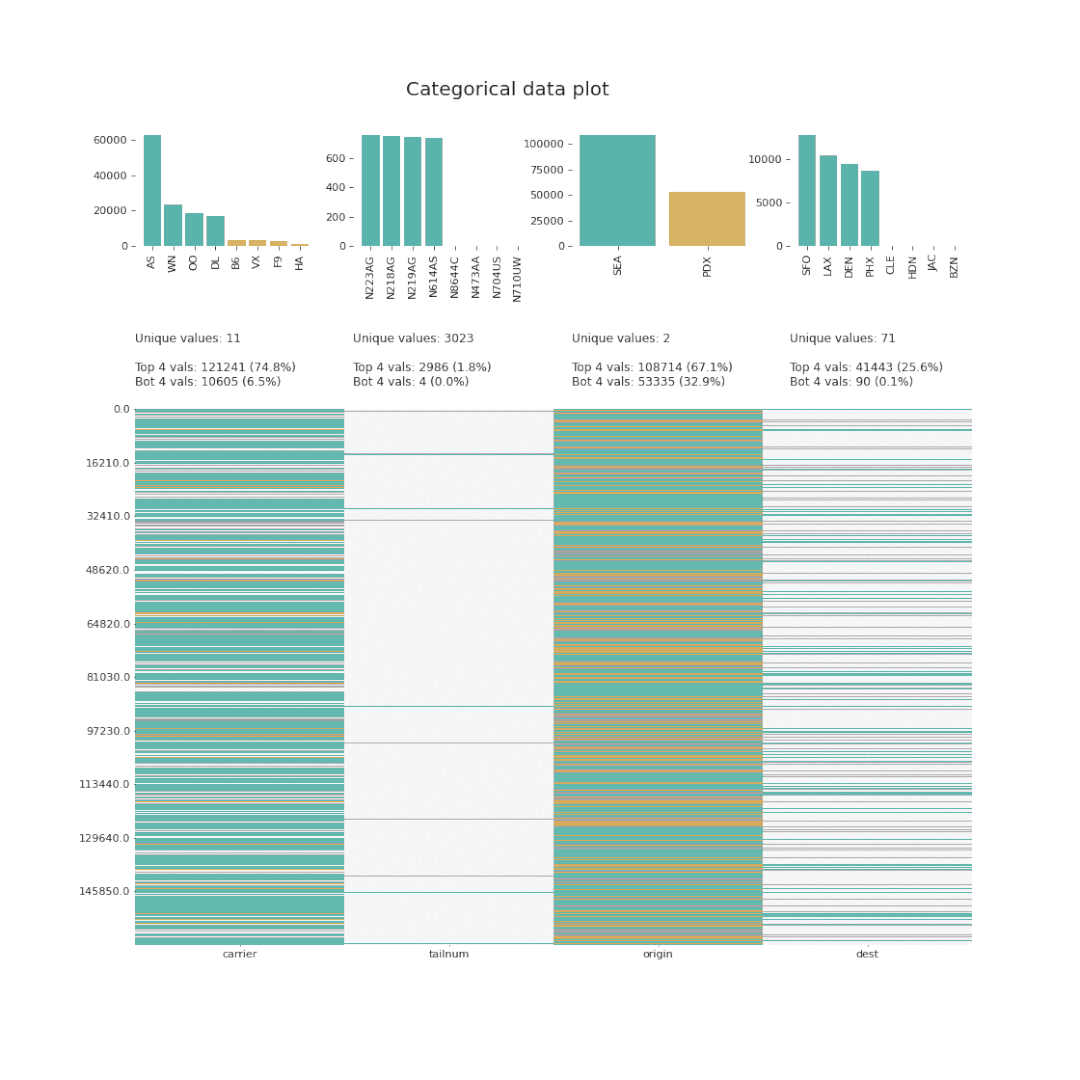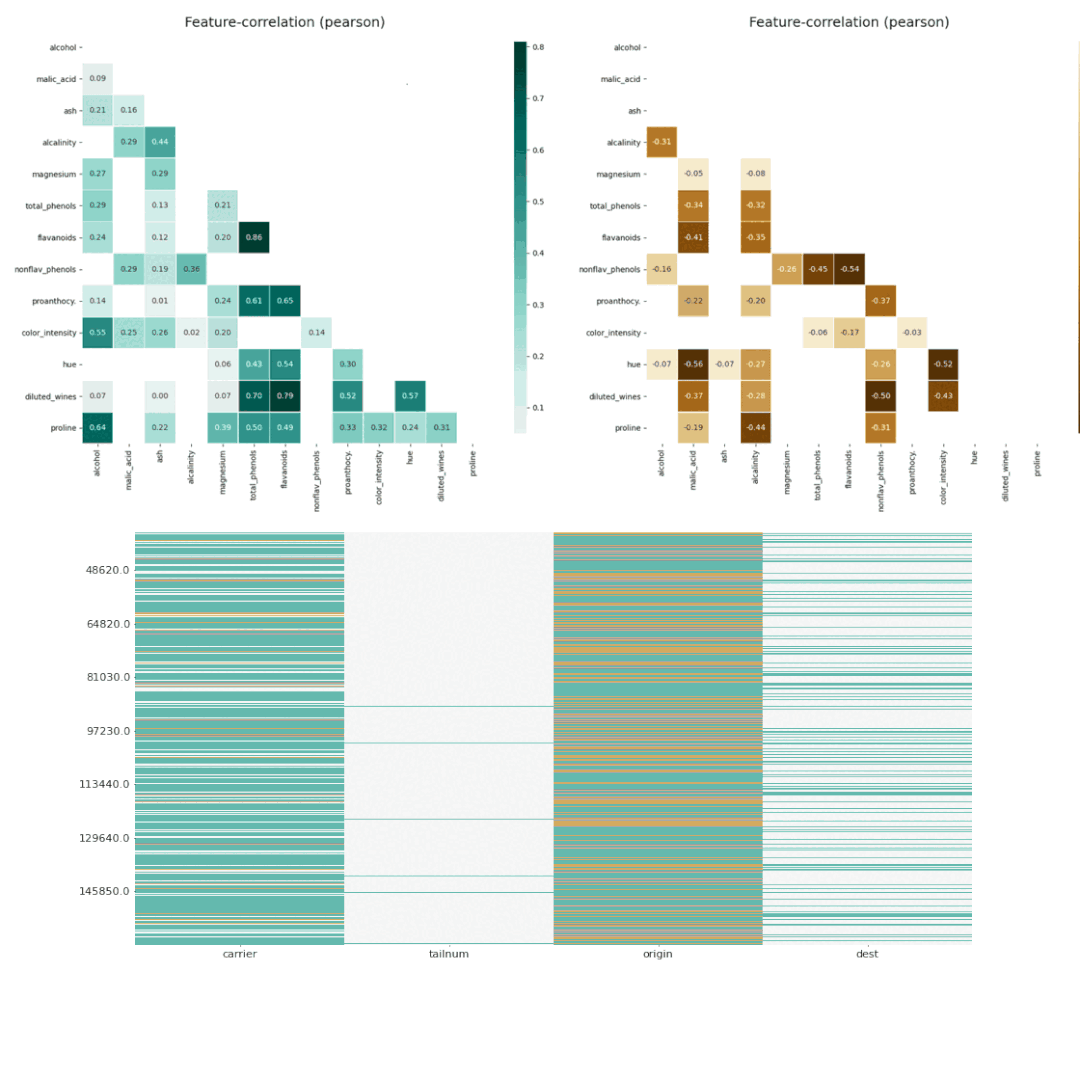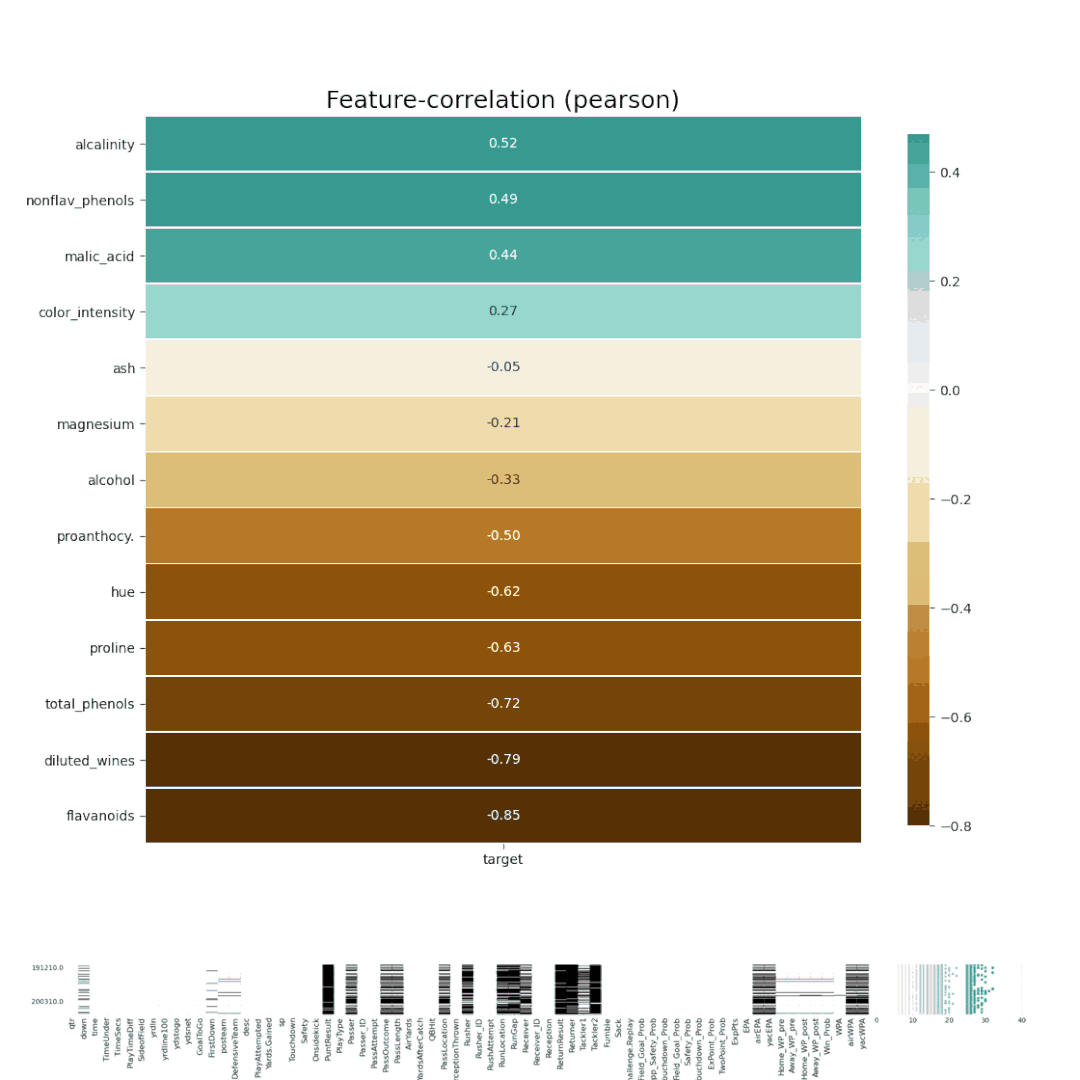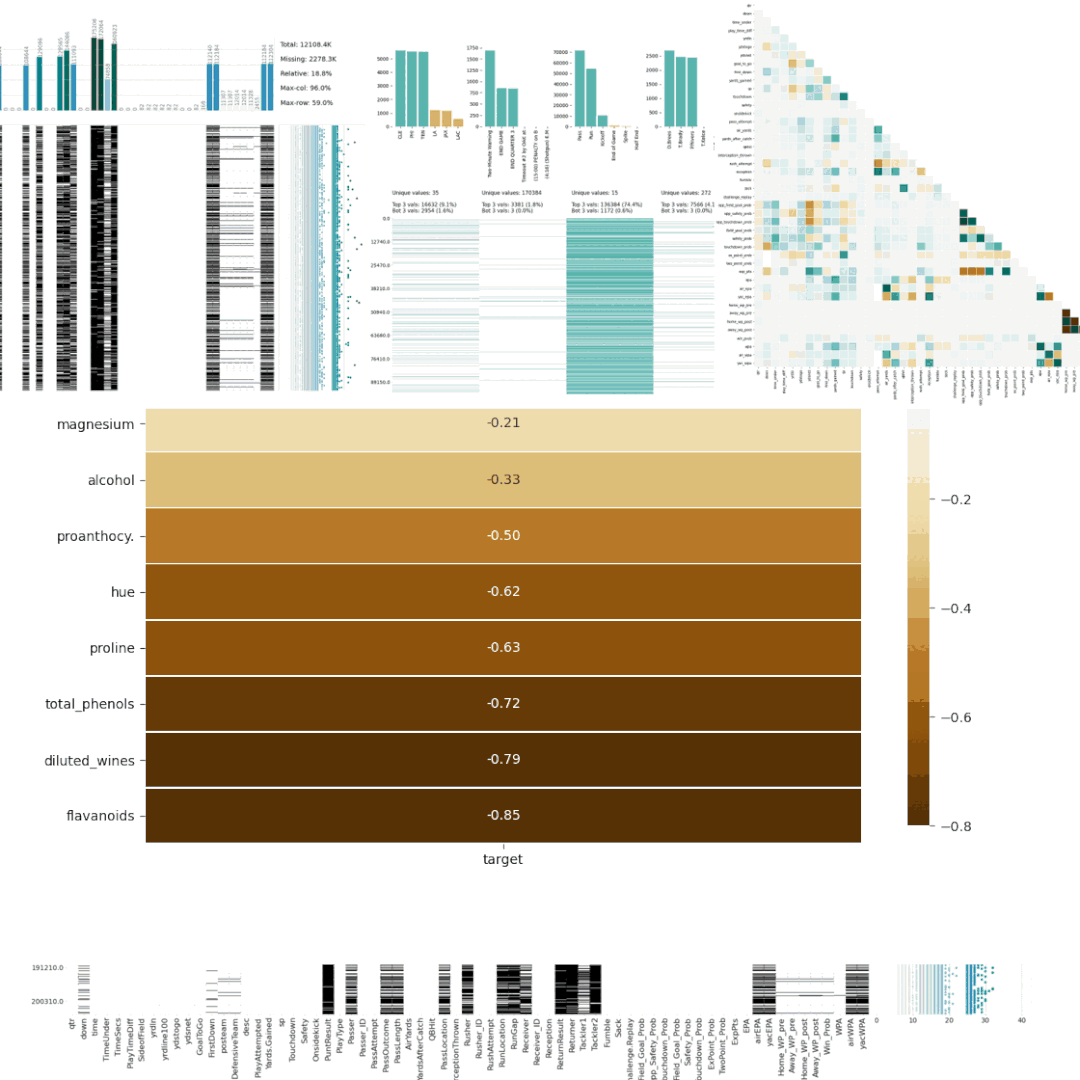
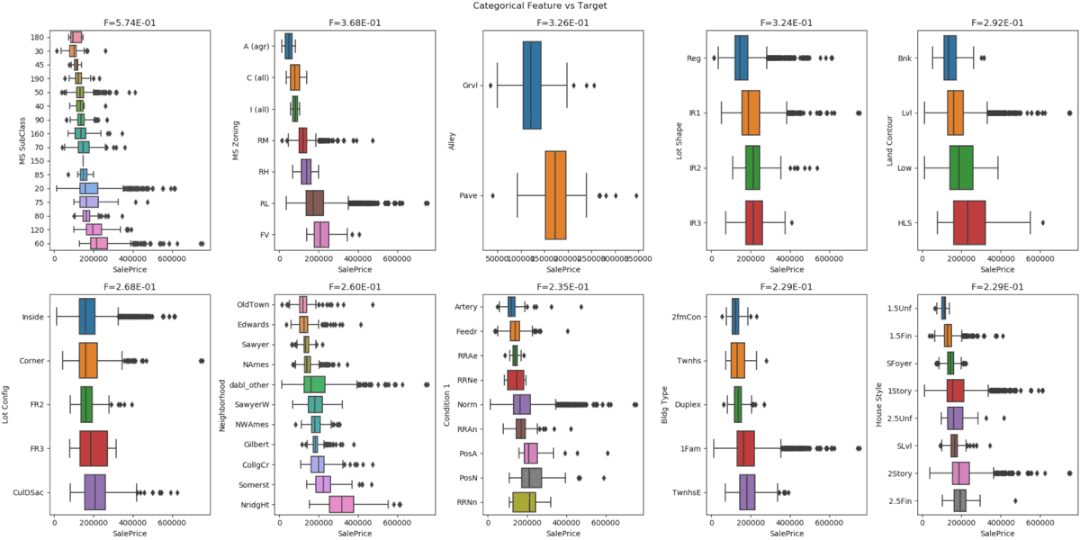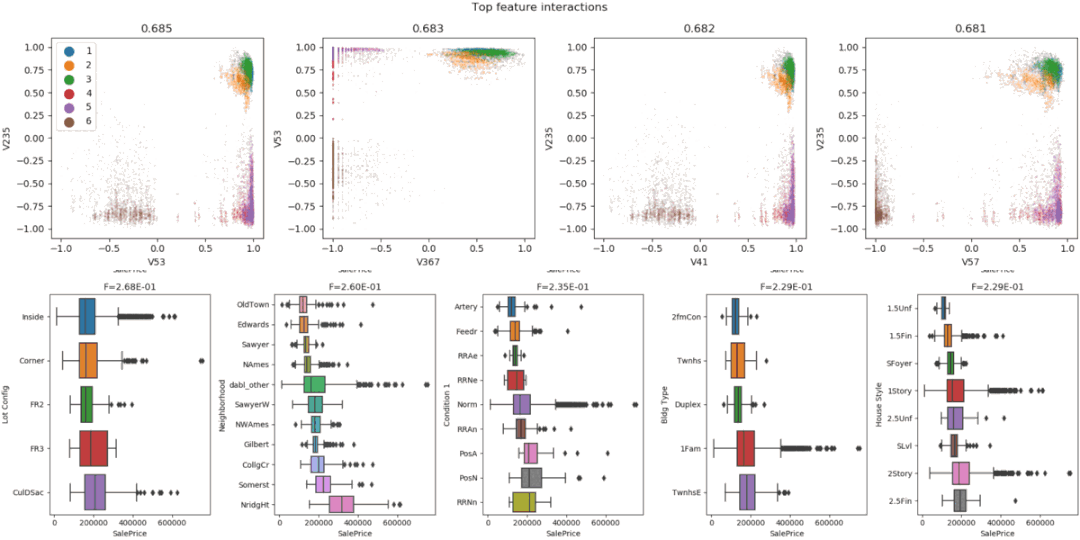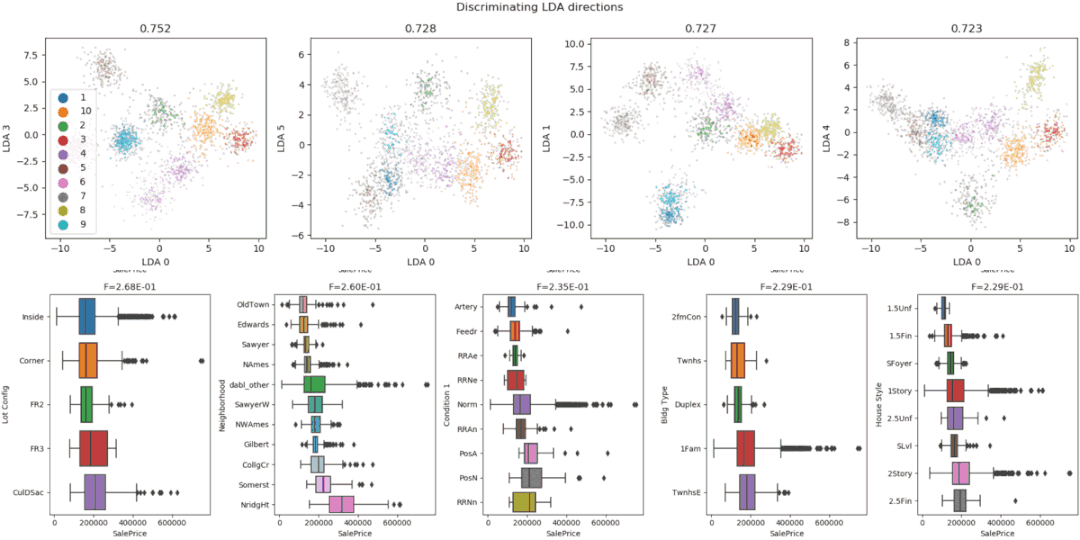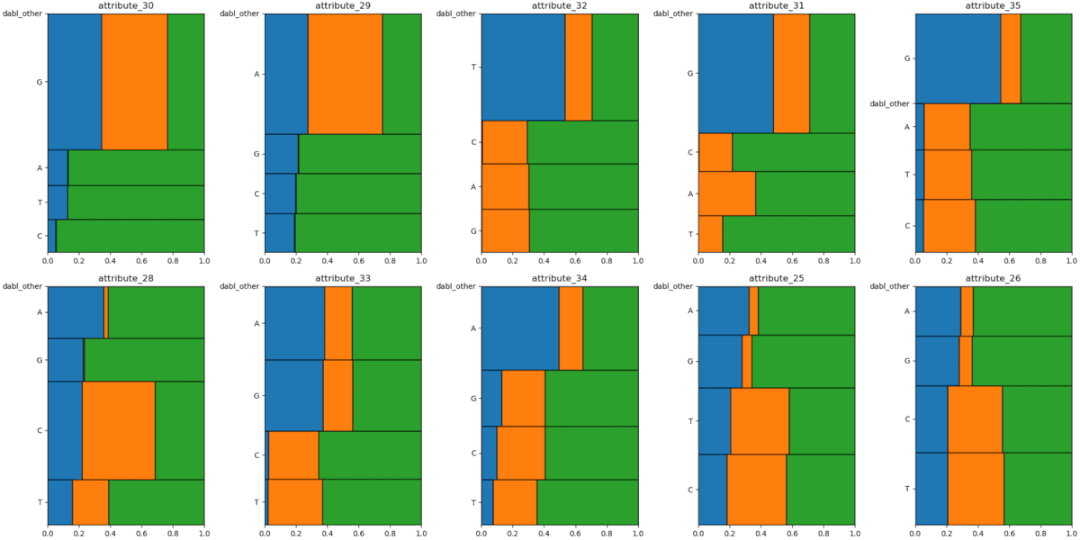
7、Dabl
Dabl不太關(guān)注單個(gè)列的統(tǒng)計(jì)度量,而是更多地關(guān)注通過可視化提供快速概述,以及方便的機(jī)器學(xué)習(xí)預(yù)處理和模型搜索。
dabl中的Plot()函數(shù)可以通過繪制各種圖來實(shí)現(xiàn)可視化,包括:
目標(biāo)分布圖
散點(diǎn)圖
線性判別分析
importpandasaspd importdabl df=pd.read_csv("titanic.csv") dabl.plot(df,target_col="Survived")
8、Speedml
SpeedML是用于快速啟動(dòng)機(jī)器學(xué)習(xí)管道的Python包。SpeedML整合了一些常用的ML包,包括 Pandas,Numpy,Sklearn,Xgboost 和 Matplotlib,所以說其實(shí)SpeedML不僅僅包含自動(dòng)化EDA的功能。 SpeedML官方說,使用它可以基于迭代進(jìn)行開發(fā),將編碼時(shí)間縮短了70%。
fromspeedmlimportSpeedml sml=Speedml('../input/train.csv','../input/test.csv', target='Survived',uid='PassengerId') sml.train.head()
sml.plot.correlate()
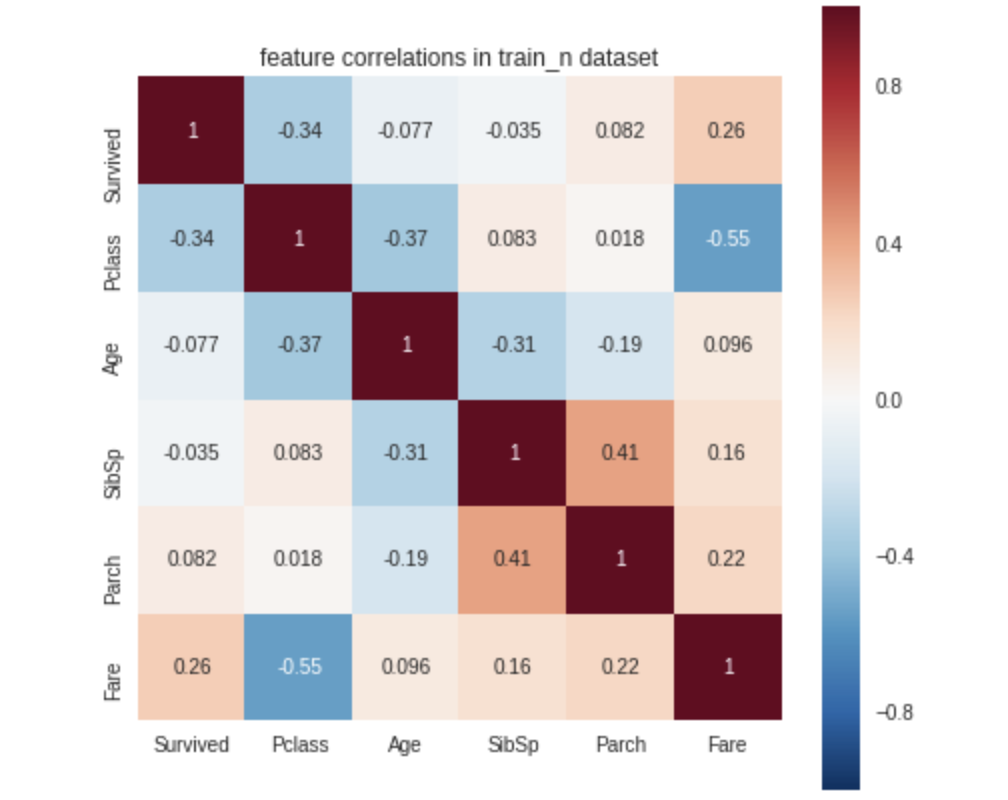
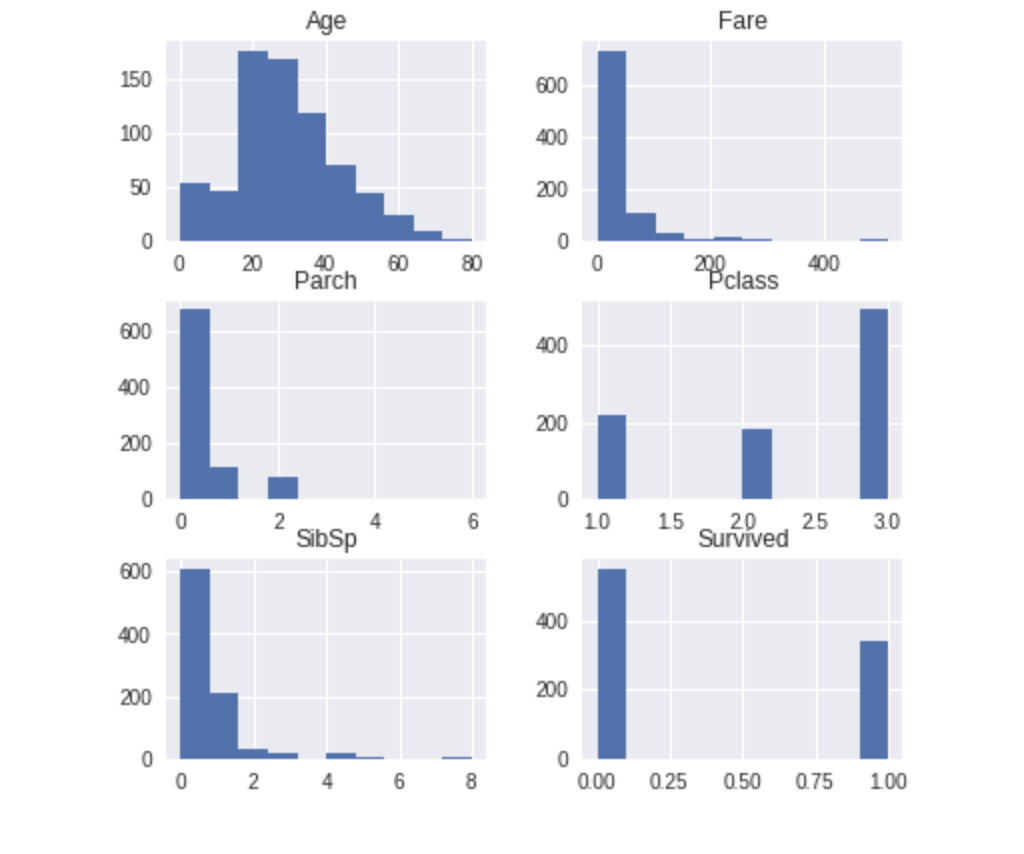
sml.plot.distribute()
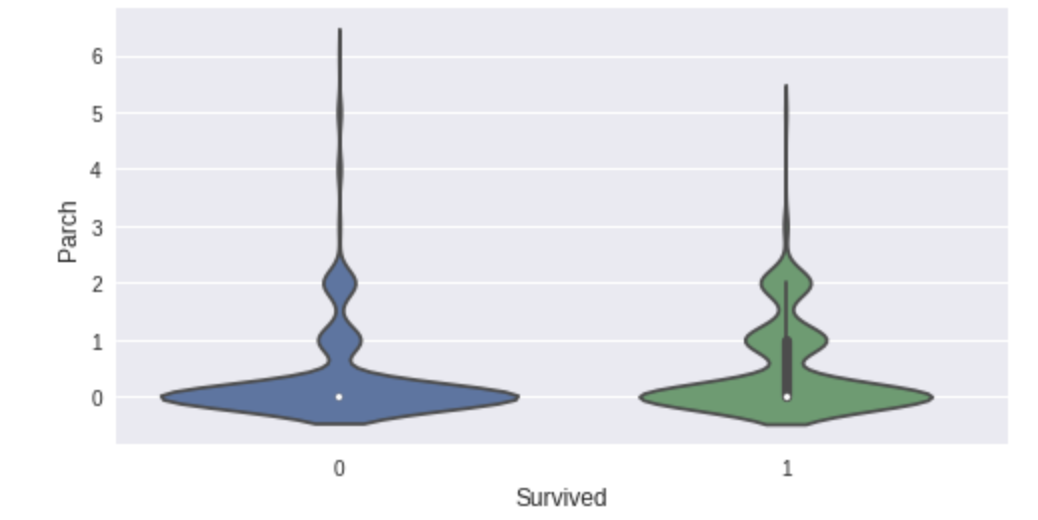
sml.plot.ordinal('Parch')
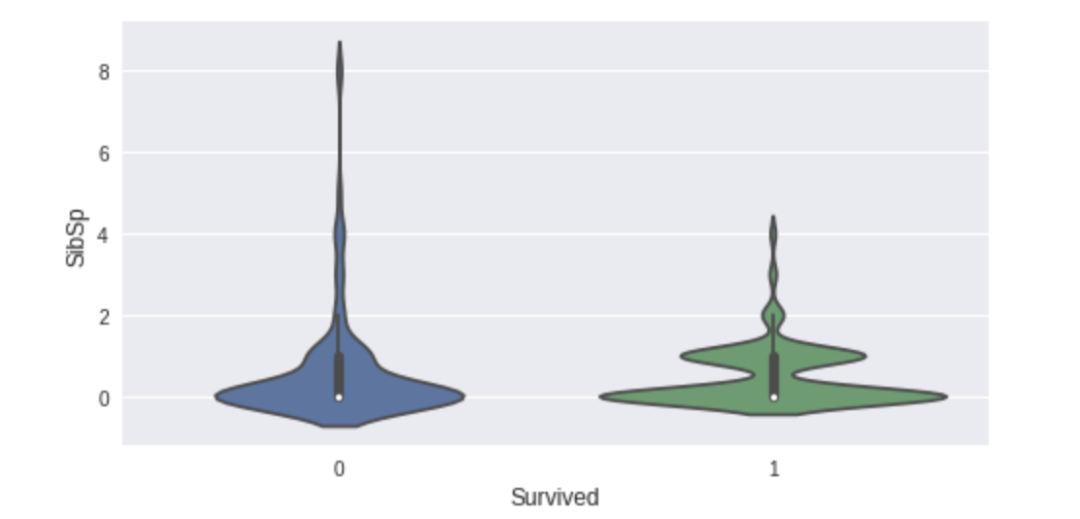
sml.plot.ordinal('SibSp')
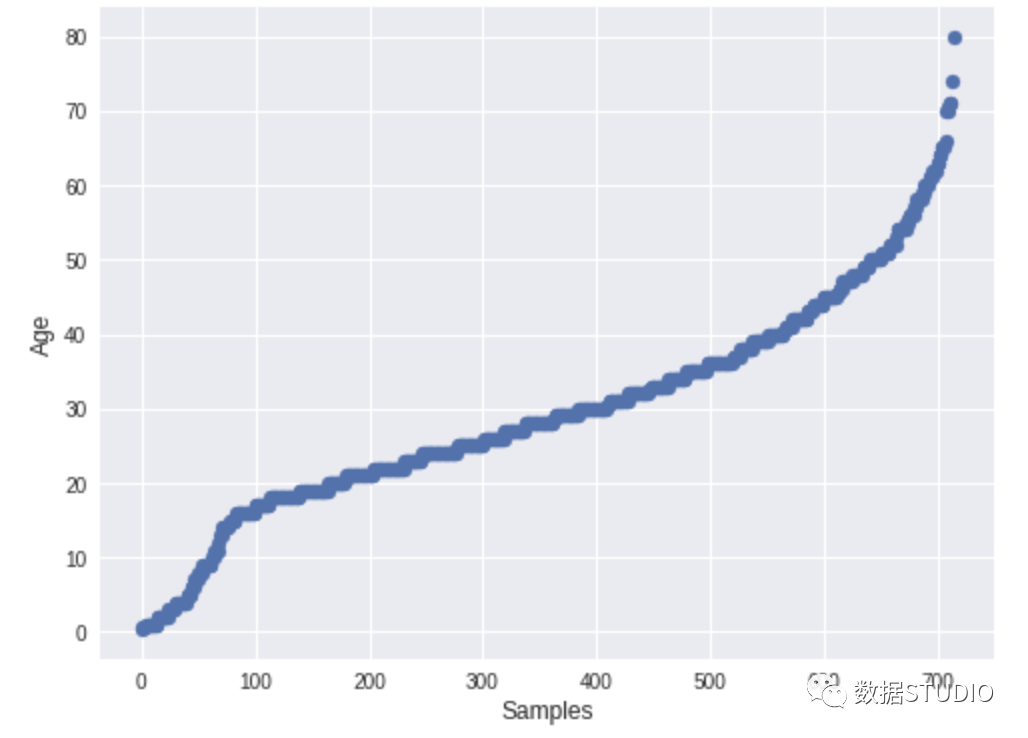
sml.plot.continuous('Age')
9、DataTile
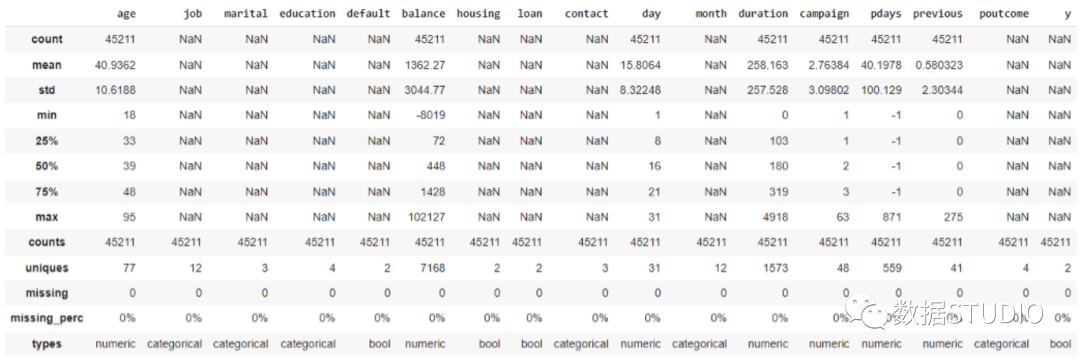
DataTile(以前稱為Pandas-Summary)是一個(gè)開源的Python軟件包,負(fù)責(zé)管理,匯總和可視化數(shù)據(jù)。DataTile基本上是PANDAS DataFrame describe()函數(shù)的擴(kuò)展。
importpandasaspd fromdatatile.summary.dfimportDataFrameSummary df=pd.read_csv('titanic.csv') dfs=DataFrameSummary(df) dfs.summary()
10、edaviz
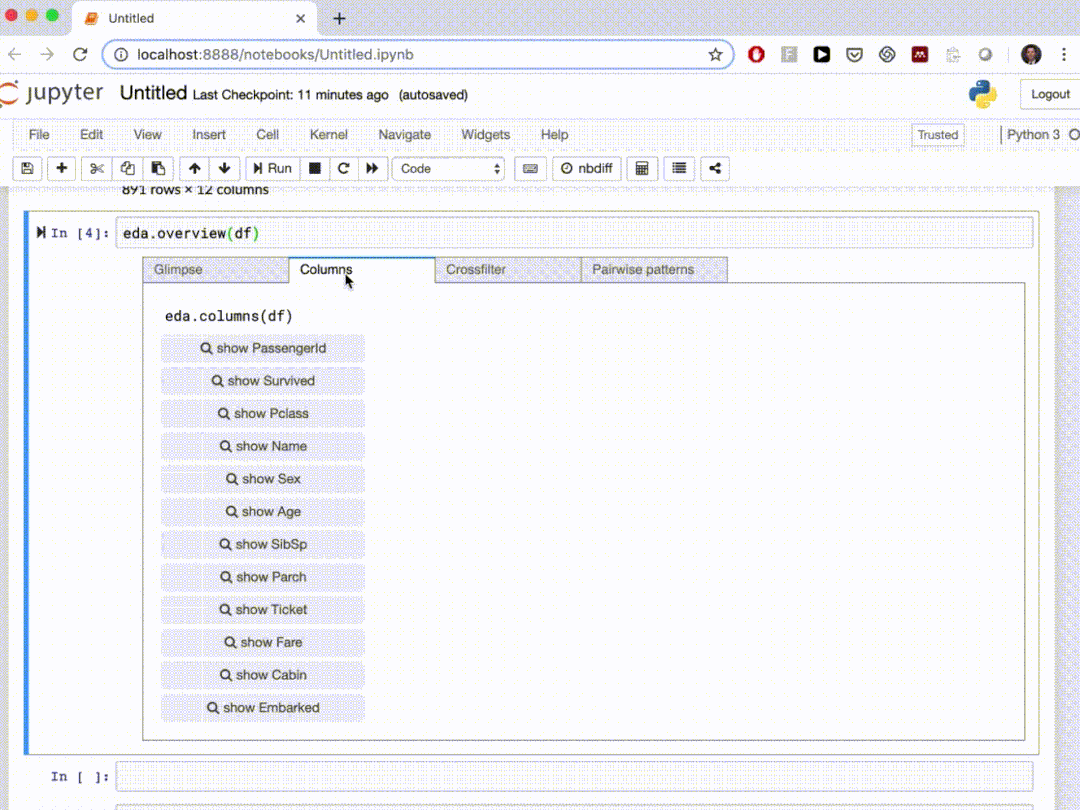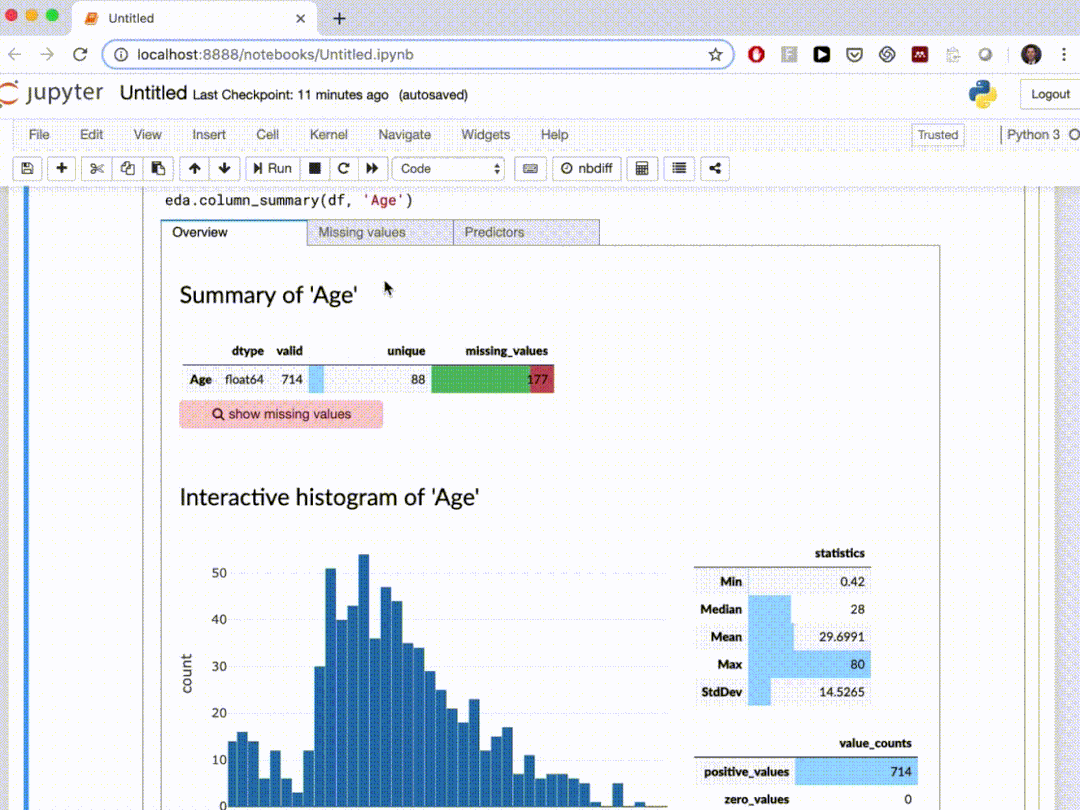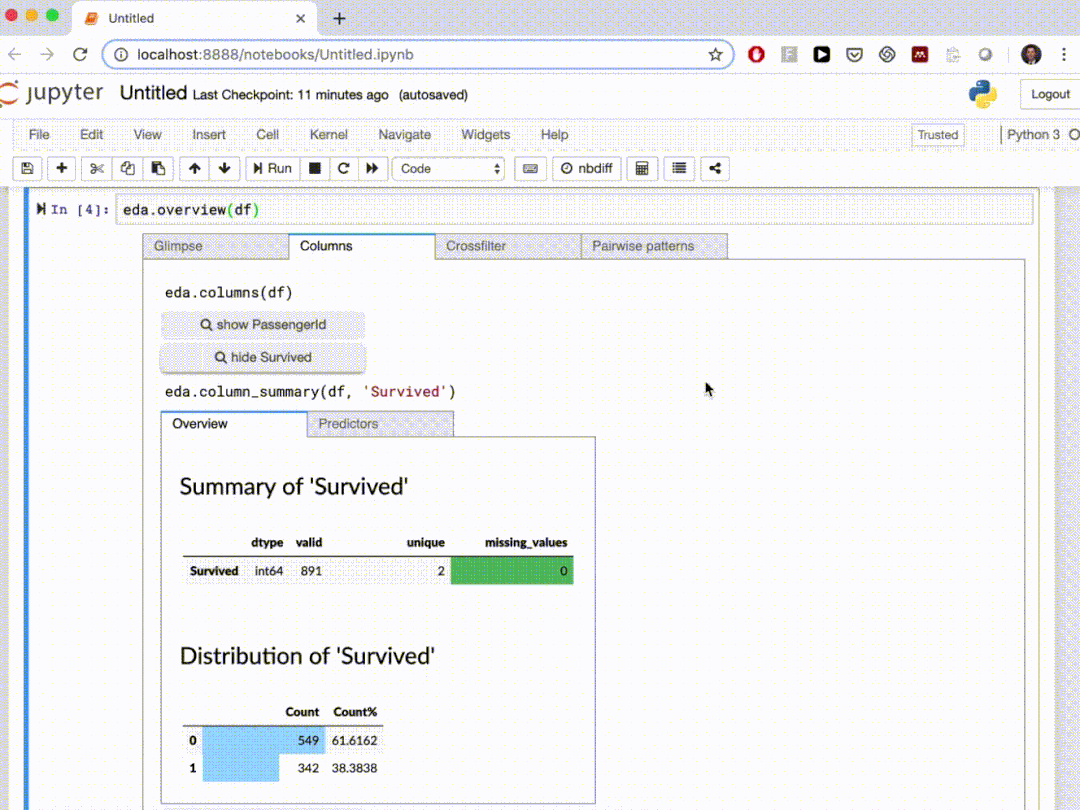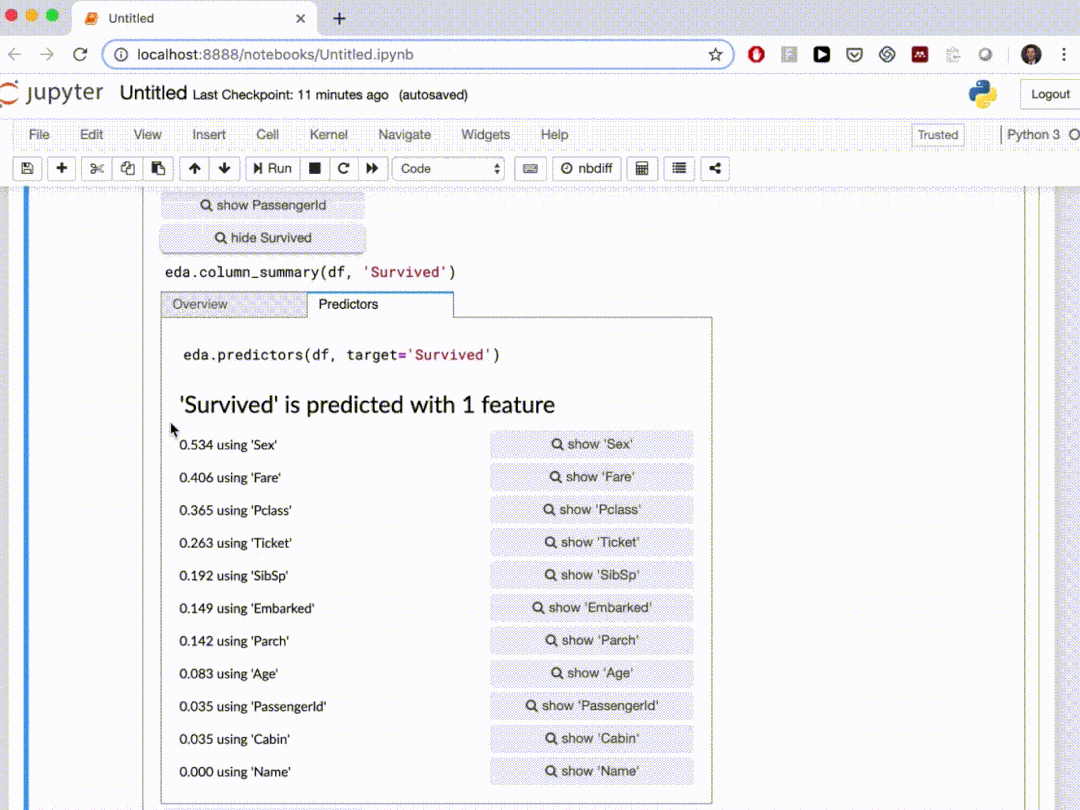
edaviz是一個(gè)可以在Jupyter Notebook和Jupyter Lab中進(jìn)行數(shù)據(jù)探索和可視化的python庫,他本來是非常好用的,但是后來被磚廠(Databricks)收購(gòu)并且整合到bamboolib 中,所以這里就簡(jiǎn)單的給個(gè)演示。
總結(jié) 在本文中,我們介紹了10個(gè)自動(dòng)探索性數(shù)據(jù)分析Python軟件包,這些軟件包可以在幾行Python代碼中生成數(shù)據(jù)摘要并進(jìn)行可視化。通過自動(dòng)化的工作可以節(jié)省我們的很多時(shí)間。 Dataprep是我最常用的EDA包,AutoViz和D-table也是不錯(cuò)的選擇,如果你需要定制化分析可以使用Klib,SpeedML整合的東西比較多,單獨(dú)使用它啊進(jìn)行EDA分析不是特別的適用,其他的包可以根據(jù)個(gè)人喜好選擇,其實(shí)都還是很好用的,最后edaviz就不要考慮了,因?yàn)橐呀?jīng)不開源了。
-
eda
+關(guān)注
關(guān)注
71文章
2900瀏覽量
176592 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1470瀏覽量
34827 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86268
原文標(biāo)題:10 個(gè) Python 自動(dòng)探索性數(shù)據(jù)分析神庫!
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Mathematica 在數(shù)據(jù)分析中的應(yīng)用
數(shù)據(jù)可視化與數(shù)據(jù)分析的關(guān)系
如何使用SQL進(jìn)行數(shù)據(jù)分析
eda分析中的數(shù)據(jù)清洗步驟
eda的常見誤區(qū)和解決方案
eda與傳統(tǒng)數(shù)據(jù)分析的區(qū)別
如何進(jìn)行有效的eda分析
為什么選擇eda進(jìn)行數(shù)據(jù)分析
raid 在大數(shù)據(jù)分析中的應(yīng)用
SLM片內(nèi)監(jiān)控IP數(shù)據(jù)分析顯著減少測(cè)試成本






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論