") 工程師說(shuō) | 面向AD/ADAS的SoC的AI性能優(yōu)化
工程師說(shuō) | 面向AD/ADAS的SoC的AI性能優(yōu)化
摘要
本文介紹了瑞薩在早期設(shè)計(jì)階段針對(duì)自動(dòng)駕駛(AD)和高級(jí)駕駛輔助系統(tǒng)(ADAS)的SoC中用于AI處理的深度神經(jīng)網(wǎng)絡(luò)(DNN)加速器的性能、電路尺寸和功耗的工作內(nèi)容。
Yuji Obayashi
Principal Software Engineer
背景
近年,隨著深度學(xué)習(xí)(DeepLearning)人工智能(AI)技術(shù)的進(jìn)步,我們的生活中出現(xiàn)了許多直接有益的應(yīng)用場(chǎng)景,例如自動(dòng)翻譯精度的提升和根據(jù)消費(fèi)者喜好的個(gè)性化推薦。截至2023年,AI在某些領(lǐng)域已經(jīng)成為產(chǎn)品和服務(wù)中不可或缺的應(yīng)用,其中之一就是自動(dòng)駕駛(AD)和先進(jìn)駕駛輔助系統(tǒng)(ADAS)。
以深度神經(jīng)網(wǎng)絡(luò)(DNN)為代表的最新人工智能模型的處理需要大規(guī)模的并行計(jì)算,因此在PC開(kāi)發(fā)中通常使用通用的GPU進(jìn)行并行計(jì)算。另一方面,用于AD和ADAS的SoC多數(shù)搭載了專用電路(以下簡(jiǎn)稱加速器),實(shí)現(xiàn)了低功耗和高性能的DNN處理。然而,在SoC開(kāi)發(fā)的早期階段,確認(rèn)搭載的加速器能否在實(shí)際所需的DNN中提供足夠的性能通常并不容易。性能比較的指標(biāo)常常使用加速器設(shè)計(jì)上的最大計(jì)算性能TOPS(Tera Operations Per Second)值,或者其與運(yùn)行時(shí)消耗的功率相除得到的TOPS/W值。然而,由于加速器是針對(duì)特定處理的專用設(shè)計(jì)(*1),即使TOPS值足夠高,在實(shí)際所需的DNN中也可能由于存在無(wú)法高效處理的計(jì)算或數(shù)據(jù)傳輸帶寬不足等問(wèn)題而無(wú)法提供足夠的性能。此外,加速器的功率增加可能導(dǎo)致整個(gè)SoC的功耗超過(guò)可接受的范圍。
(*1)專用設(shè)計(jì):雖然使用通用GPU作為加速器也是可能的,但處理特定任務(wù)的硬件,可以在較小的電路規(guī)模和功耗下獲得更高的處理性能。例如瑞薩的車載SoC R-Car V3H、R-Car V3M和R-Car V4H搭載的加速器具有專為處理DNN中使用卷積操作進(jìn)行特征提取的卷積神經(jīng)網(wǎng)絡(luò)(CNN)任務(wù)而設(shè)計(jì)的結(jié)構(gòu)。
隨著SoC開(kāi)發(fā)的深入,由于性能不足或功耗過(guò)大等原因而進(jìn)行設(shè)計(jì)變更的難度普遍增加,對(duì)SoC開(kāi)發(fā)進(jìn)度和開(kāi)發(fā)成本的影響也隨之增加。因此,在開(kāi)發(fā)面向車載AI設(shè)備的SoC時(shí),確認(rèn)搭載的加速器能否在實(shí)際顧客產(chǎn)品中所需的DNN中提供足夠的性能,并且功耗是否在可接受范圍內(nèi),已成為迫切的問(wèn)題。
面向AD/ADAS的一般AI開(kāi)發(fā)流程
在解釋如何解決上述問(wèn)題之前,先簡(jiǎn)單介紹一下AD/ADAS的AI開(kāi)發(fā)流程。下面的圖1展示了在AD/ADAS中以軟件為核心,并包括部分SoC開(kāi)發(fā)的AI開(kāi)發(fā)流程的示例。
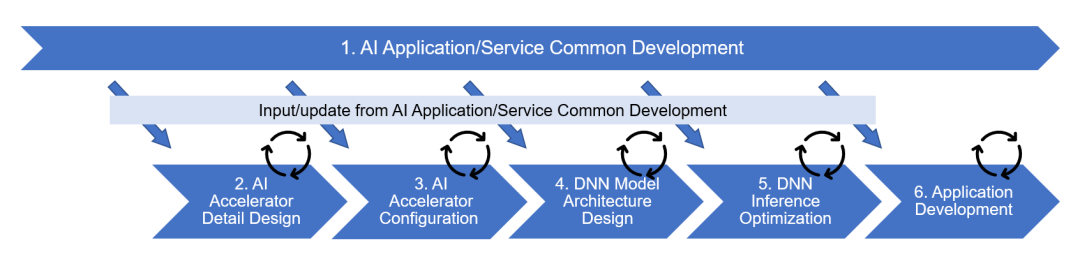
圖1:AD/ADAS中AI開(kāi)發(fā)流程的例子
圖1將整個(gè)開(kāi)發(fā)工作分為六個(gè)階段,其中第2和第3階段為SoC電路設(shè)計(jì),其他第1和第4-6階段為軟件開(kāi)發(fā)。下面給出了每個(gè)階段的工作概述。
第一階段 AI Application/Service Common Development
利用PC和云環(huán)境,以應(yīng)對(duì)市場(chǎng)需求和技術(shù)趨勢(shì),開(kāi)發(fā)面向AD/ADAS的AI應(yīng)用程序和服務(wù)。
第二階段 AI Accelerator Detail Design
涵蓋了構(gòu)成加速器硬件的部件設(shè)計(jì),如計(jì)算單元、內(nèi)部存儲(chǔ)器和數(shù)據(jù)傳輸單元。
第三階段 AI Accelerator Configuration
在第三階段中,第二階段中設(shè)計(jì)的組件被組合起來(lái),以優(yōu)化面積、功率和性能之間的權(quán)衡,同時(shí)確定加速器在SoC中的配置以實(shí)現(xiàn)各自的設(shè)計(jì)目標(biāo)。
第四階段 DNN Model Architecture Design
在第三階段中確定的加速器配置被用來(lái)優(yōu)化每個(gè)用于客戶產(chǎn)品的DNN網(wǎng)絡(luò)的結(jié)構(gòu)。
第五階段 DNN Inference Optimization
將針對(duì)經(jīng)過(guò)第四階段結(jié)構(gòu)優(yōu)化的每個(gè)網(wǎng)絡(luò)進(jìn)行適用于加速器的代碼生成,并進(jìn)行精度和處理時(shí)間的詳細(xì)評(píng)估。同時(shí),將對(duì)代碼和模型數(shù)據(jù)進(jìn)行優(yōu)化,以提高性能。
第六階段 Application Development
將使用第五階段中優(yōu)化的代碼和模型數(shù)據(jù),將AI處理部分嵌入到實(shí)際的自動(dòng)駕駛等處理中,并進(jìn)行應(yīng)用的實(shí)現(xiàn)和評(píng)估。
瑞薩的工作
在上一節(jié)所示的AD/ADAS中的AI開(kāi)發(fā)流程中,判斷實(shí)際使用的DNN是否能夠在所配備的加速器上提供足夠的性能,通常需要在決定加速器配置的第三階段AI Accelerator Configuration中進(jìn)行決策。
傳統(tǒng)上,在這一階段的決策是通過(guò)使用類似加速器的現(xiàn)有SoC進(jìn)行的基準(zhǔn)測(cè)試結(jié)果來(lái)估計(jì)的,但對(duì)于因增加或改變功能而與現(xiàn)有SoC規(guī)格不同的部分,無(wú)法獲得基準(zhǔn)測(cè)試結(jié)果,因此無(wú)法通過(guò)高度精確的估計(jì)來(lái)確定是否能達(dá)到設(shè)計(jì)目標(biāo)。
瑞薩通過(guò)使用PPA Estimator(PPA:Performance,Power,Area)而不是現(xiàn)有的SoC基準(zhǔn)測(cè)試來(lái)解決這個(gè)課題。PPA Estimator通過(guò)使用反映加速器每個(gè)組件設(shè)計(jì)的性能和功率計(jì)算模型,使性能和功耗在加速器配置最終確定之前得到估算。具體來(lái)說(shuō),列出可能的加速器配置(可改變的加速器參數(shù)的組合,如處理單元的數(shù)量和內(nèi)部存儲(chǔ)器的容量)進(jìn)行評(píng)估,選擇其中一個(gè)配置并與要評(píng)估的一個(gè)DNN一起輸入PPA Estimator中,以獲得所需的執(zhí)行時(shí)間和功耗。然后,可以針對(duì)所需評(píng)估的加速器配置和DNN的數(shù)量進(jìn)行重復(fù)操作,收集數(shù)據(jù),并找到最佳的加速器配置。如此,不僅可以確定一個(gè)特定的加速器配置和DNN組合是否有足夠的性能,而且還可以收集廣泛的數(shù)據(jù)并從中選擇最佳加速器配置。
此外,為了使第三階段AI Accelerator Configuration更加有效,瑞薩還通過(guò)將從PPA Estimator執(zhí)行結(jié)果中獲得的信息反饋給目標(biāo)DNN的網(wǎng)絡(luò)模型,并行改進(jìn)軟件方面的工作,也就是進(jìn)行硬件-軟件聯(lián)合設(shè)計(jì)(co-design)。AI Accelerator Configuration階段的工作流程如下圖2所示。
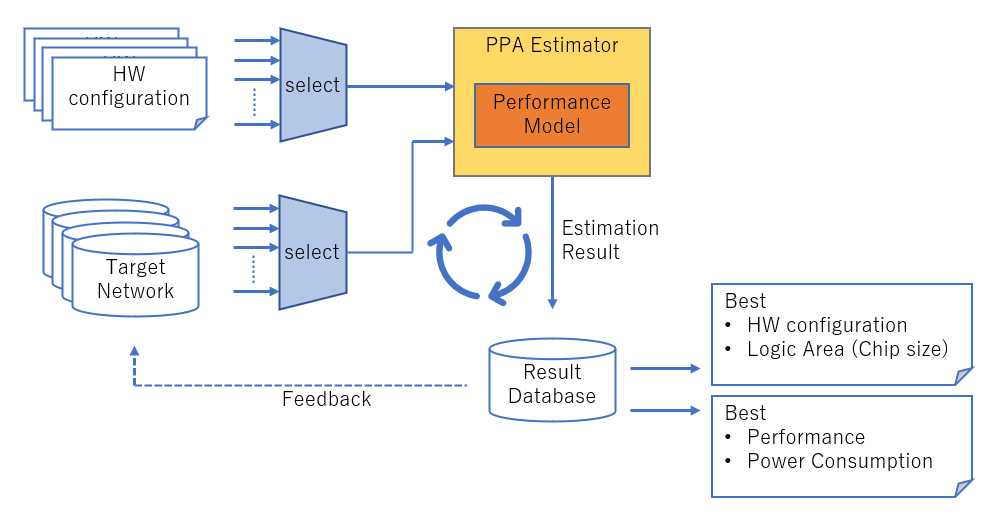
圖2:AI Accelerator Configuration工作流程
瑞薩已開(kāi)始將PPA Estimator應(yīng)用于從2023年開(kāi)始的一些帶有AI處理加速器的AD/ADAS的SoC的開(kāi)發(fā)中,并計(jì)劃逐步擴(kuò)大應(yīng)用范圍。瑞薩將利用PPA Estimator的高度精確性能尋找最佳配置以開(kāi)發(fā)高性能、低功耗的車載AI加速器。
點(diǎn)擊文末閱讀原文獲取更多有關(guān)瑞薩當(dāng)前和最新的車載AI SoC產(chǎn)品的信息。
1
END
1
瑞薩電子 (TSE: 6723)
科技讓生活更輕松,致力于打造更安全、更智能、可持續(xù)發(fā)展的未來(lái)。作為全球微控制器供應(yīng)商,瑞薩電子融合了在嵌入式處理、模擬、電源及連接方面的專業(yè)知識(shí),提供完整的半導(dǎo)體解決方案。成功產(chǎn)品組合加速汽車、工業(yè)、基礎(chǔ)設(shè)施及物聯(lián)網(wǎng)應(yīng)用上市,賦能數(shù)十億聯(lián)網(wǎng)智能設(shè)備改善人們的工作和生活方式。更多信息,敬請(qǐng)?jiān)L問(wèn)renesas.com
原文標(biāo)題:工程師說(shuō) | 面向AD/ADAS的SoC的AI性能優(yōu)化
文章出處:【微信公眾號(hào):瑞薩電子】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
瑞薩
+關(guān)注
關(guān)注
36文章
22375瀏覽量
87842
原文標(biāo)題:工程師說(shuō) | 面向AD/ADAS的SoC的AI性能優(yōu)化
文章出處:【微信號(hào):瑞薩電子,微信公眾號(hào):瑞薩電子】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
智能駕駛核心器件:三星ADAS SoC高性能MLCC解決方案

芯馳科技D9-Max:面向具身智能應(yīng)用的高性能邊緣AI SoC

面向AI與機(jī)器學(xué)習(xí)應(yīng)用的開(kāi)發(fā)平臺(tái) AMD/Xilinx Versal? AI Edge VEK280
AI眼鏡的未來(lái):SoC芯片與SD NAND的協(xié)同優(yōu)化


電子工程師如何利用AI革新設(shè)計(jì)范式
FPGA+AI王炸組合如何重塑未來(lái)世界:看看DeepSeek東方神秘力量如何預(yù)測(cè)......
如何優(yōu)化SOC芯片性能
AI大模型的性能優(yōu)化方法
康謀分享 | AD/ADAS的性能概覽:在AD/ADAS的開(kāi)發(fā)與驗(yàn)證中“大海撈針”!

FPGA算法工程師、邏輯工程師、原型驗(yàn)證工程師有什么區(qū)別?
使用邏輯和轉(zhuǎn)換優(yōu)化ADAS域控制器

微軟GitHub推出Models服務(wù),賦能AI工程師







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論