") 基于視覺的機器人抓取系統(tǒng)設計
基于視覺的機器人抓取系統(tǒng)設計
作者 |ljc_coder@CSDN
0導讀
抓取綜合方法是機器人抓取問題的核心,本文從抓取檢測、視覺伺服和動態(tài)抓取等角度進行討論,提出了多種抓取方法。各位對機器人識別抓取感興趣的小伙伴,一定要來看一看!千萬別錯過~
1引言
找到理想抓取配置的抓取假設的子集包括:機器人將執(zhí)行的任務類型、目標物體的特征、關于物體的先驗知識類型、機械爪類型,以及最后的抓取合成。
注:從本文中可以學習到視覺伺服的相關內容,用于對動態(tài)目標的跟蹤抓取或自動調整觀察姿態(tài)。因為觀察的角度不同,預測的抓取框位置也不同:抓取物品離相機位置越近,抓取預測越準。
1.1抓取綜合方法
抓取綜合方法是機器人抓取問題的核心,因為它涉及到在物體中尋找最佳抓取點的任務。這些是夾持器必須與物體接觸的點,以確保外力的作用不會導致物體不穩(wěn)定,并滿足一組抓取任務的相關標準。
抓取綜合方法通常可分為分析法和基于數(shù)據(jù)的方法。
分析法是指使用具有特定動力學行為的靈巧且穩(wěn)定的多指手構造力閉合
基于數(shù)據(jù)的方法指建立在按某種標準的條件下,對抓取候選對象的搜索和對象分類的基礎上。(這一過程往往需要一些先驗經驗)
1.2基于視覺的機器人抓取系統(tǒng)
基于視覺的機器人抓取系統(tǒng)一般由四個主要步驟組成,即目標物體定位、物體姿態(tài)估計、抓取檢測(合成)和抓取規(guī)劃。
一個基于卷積神經網(wǎng)絡的系統(tǒng),一般可以同時執(zhí)行前三個步驟,該系統(tǒng)接收對象的圖像作為輸入,并預測抓取矩形作為輸出。
而抓取規(guī)劃階段,即機械手找到目標的最佳路徑。它應該能夠適應工作空間的變化,并考慮動態(tài)對象,使用視覺反饋。
目前大多數(shù)機器人抓取任務的方法執(zhí)行一次性抓取檢測,無法響應環(huán)境的變化。因此,在抓取系統(tǒng)中插入視覺反饋是可取的,因為它使抓取系統(tǒng)對感知噪聲、物體運動和運動學誤差具有魯棒性。
2抓取檢測、視覺伺服和動態(tài)抓取
抓取計劃分兩步執(zhí)行:
首先作為一個視覺伺服控制器,以反應性地適應對象姿勢的變化。
其次,作為機器人逆運動學的一個內部問題,除了與奇異性相關的限制外,機器人對物體的運動沒有任何限制。
2.1抓取檢測
早期的抓取檢測方法一般為分析法,依賴于被抓取物體的幾何結構,在執(zhí)行時間和力估計方面存在許多問題。
此外,它們在許多方面都不同于基于數(shù)據(jù)的方法。
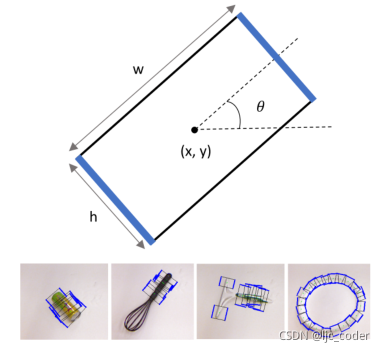
基于數(shù)據(jù)的方法:Jiang、Moseson和Saxena等人僅使用圖像,從五個維度提出了機器人抓取器閉合前的位置和方向表示。
如下圖,該五維表示足以對抓取姿勢的七維表示進行編碼[16],因為假定圖像平面的法線近似。因此,三維方向僅由給出。
本文的工作重點是開發(fā)一種簡單高效的CNN,用于預測抓取矩形。
在訓練和測試步驟中,所提出的網(wǎng)絡足夠輕,可以聯(lián)合應用第二個CNN,解決視覺伺服控制任務。因此,整個系統(tǒng)可以在機器人應用中實時執(zhí)行,而不會降低兩項任務的精度。
2.2視覺伺服控制
經典的視覺伺服(VS)策略要求提取視覺特征作為控制律的輸入。我們必須正確選擇這些特征,因為控制的魯棒性與此選擇直接相關。
最新的VS技術探索了深度學習算法,以同時克服特征提取和跟蹤、泛化、系統(tǒng)的先驗知識以及在某些情況下處理時間等問題。
Zhang等人開發(fā)了第一項工作,證明了在沒有任何配置先驗知識的情況下,從原始像素圖像生成控制器的可能性。作者使用Deep Q-Network ,通過深度視覺運動策略控制機器人的3個關節(jié),執(zhí)行到達目標的任務。訓練是在模擬中進行的,沒有遇到真實的圖像。
遵循強化學習方法的工作使用確定性策略梯度設計新的基于圖像的VS或Fuzzy Q-Learning,依靠特征提取,控制多轉子空中機器人。
在另一種方法中,一些研究視覺伺服深度學習的工作是通過卷積神經網(wǎng)絡進行的。CNN的泛化能力優(yōu)于RL,因為RL學習的參數(shù)是特定于環(huán)境和任務的。
本文設計了四種卷積神經網(wǎng)絡模型作為端到端視覺伺服控制器的潛在候選。網(wǎng)絡不使用參考圖像和當前圖像以外的任何類型的附加信息來回歸控制信號。
因此,所提出的網(wǎng)絡作為實際上的控制器工作,預測速度信號,而不是相對姿態(tài)。
2.3動態(tài)抓取
學習感知行為的視覺表征,遵循反應范式,直接從感覺輸入生成控制信號,無需高級推理,有助于動態(tài)抓取。
強化學習方法適用于特定類型的對象,并且仍然依賴于某種先驗知識,因此,最近大量研究探索了將深度學習作為解決閉環(huán)抓取問題的方法。
Levine等人提出了一種基于兩個組件的抓取系統(tǒng)。第一部分是預測CNN,其接收圖像和運動命令作為輸入,并輸出通過執(zhí)行這樣的命令,所產生的抓取將是令人滿意的概率。第二個部分是視覺伺服功能。這將使用預測CNN來選擇將持續(xù)控制機器人成功抓取的命令。這稱為是深度強化學習,需要很久的訓練時間。
2019年,Morrison, Corke 和 Leitner 開發(fā)了一種閉環(huán)抓取系統(tǒng),在這種系統(tǒng)中,抓取檢測和視覺伺服不是同時學習的。作者使用完全CNN獲取抓取點,并應用基于位置的視覺伺服,使抓取器的姿勢與預測的抓取姿勢相匹配。
3本文實現(xiàn)的方法
VS的目的是通過將相機連續(xù)獲得的圖像與參考圖像進行比較,引導操縱器到達機器人能夠完全看到物體的位置,從而滿足抓取檢測條件。因此,該方法的應用涵蓋了所有情況,其中機器人操作器(相機安裝在手眼模式下)必須跟蹤和抓取對象。
該系統(tǒng)包括三個階段:設計階段、測試階段和運行階段。第一個是基于CNN架構的設計和訓練,以及數(shù)據(jù)集的收集和處理。在第二階段,使用驗證集獲得離線結果,并根據(jù)其準確性、速度和應用領域進行評估。第三階段涉及在機器人上測試經過訓練的網(wǎng)絡,以評估其在實時和現(xiàn)實應用中的充分性。
在運行階段,系統(tǒng)運行的要求是事先獲得目標對象的圖像,該圖像將被VS用作設定點。只要控制信號的L1范數(shù)大于某個閾值,則執(zhí)行控制回路。
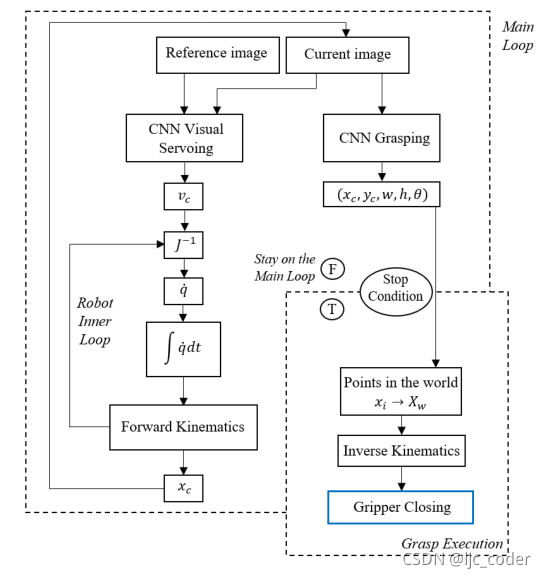
單個參考圖像作為視覺伺服CNN的輸入之一呈現(xiàn)給系統(tǒng)。相機當前獲取的圖像作為該網(wǎng)絡的第二個輸入,并作為抓取CNN的輸入。這兩個網(wǎng)絡都連續(xù)運行,因為抓取CNN實時預測矩形以進行監(jiān)控,VS網(wǎng)絡執(zhí)行機器人姿勢的實時控制。
VS CNN預測一個速度信號,該信號乘以比例增益,以應用于相機中。機器人的內部控制器尋找保證相機中預測速度的關節(jié)速度。在每次循環(huán)執(zhí)行時,根據(jù)機器人的當前位置更新當前圖像,只要控制信號不收斂,該循環(huán)就會重復。
當滿足停止條件時,抓取網(wǎng)絡的預測映射到世界坐標系。機器人通過逆運動學得到并到達預測點,然后關閉夾持器。
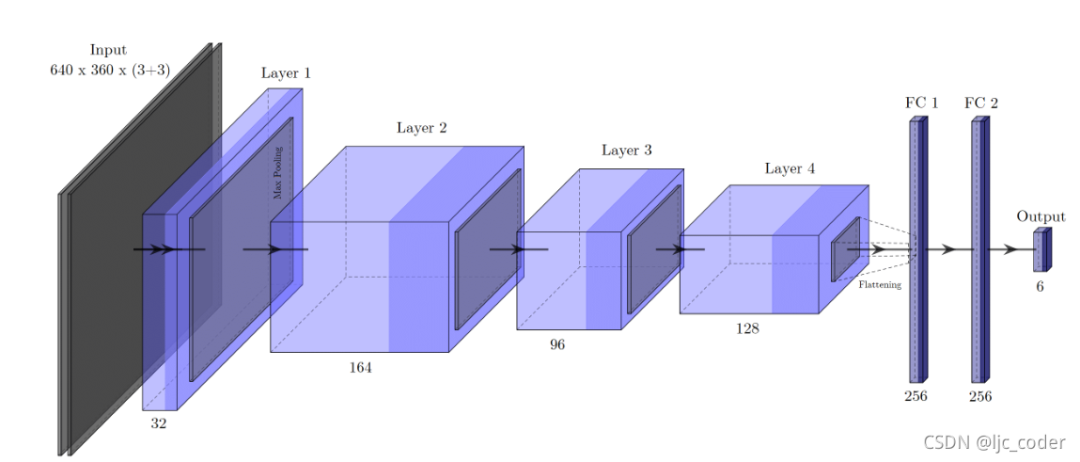
3.1網(wǎng)絡體系結構
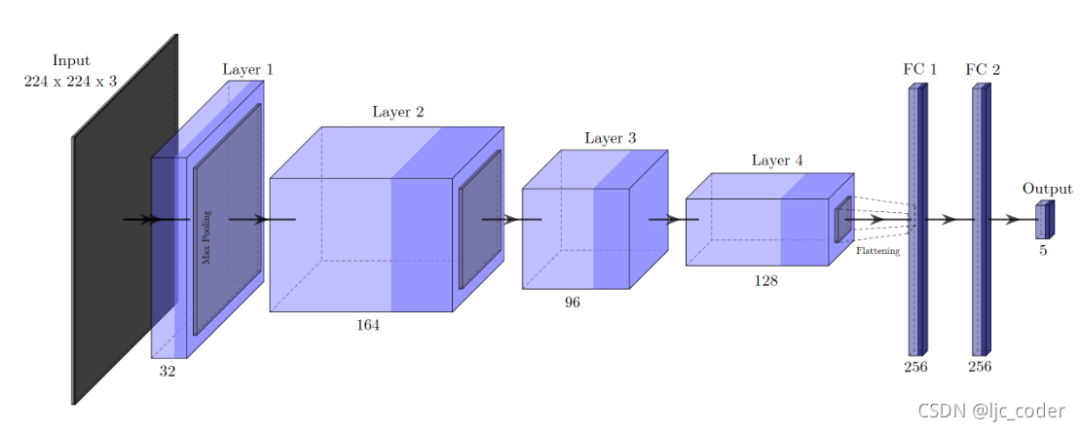
該卷積網(wǎng)絡架構被用于抓取檢測。網(wǎng)絡接收224×224×3的RGB圖像作為輸入,無深度信息。
layer 1 由32個3×3卷積組成,layer 2 包含164個卷積。在這兩種情況下,卷積運算都是通過步長2和零填充(zero-padding)執(zhí)行的,然后是批標準化(batch normalization)和2×2最大池化。layer 3 包含96個卷積,其中卷積使用步長1和零填充執(zhí)行,然后僅執(zhí)行批標準化。layer 4 ,也是最后一層,卷積層由128個卷積組成,以步長1執(zhí)行,然后是2×2最大池化。
在最后一層卷積之后,生成的特征映射在包含4608個元素的一維向量中被展開,進一步傳遞到兩個全連接(FC)層,每個層有256個神經元。在這些層次之間,訓練期間考慮50%的dropout rate。
最后,輸出層由5個神經元組成,對應于編碼抓取矩形的**值。在所有層中,使用的激活函數(shù)都是ReLU**,但在輸出層中使用線性函數(shù)的情況除外。
3.2Cornell 抓取數(shù)據(jù)集
為了對數(shù)據(jù)集真值進行編碼,使用四個頂點的和坐標編譯抓取矩形。
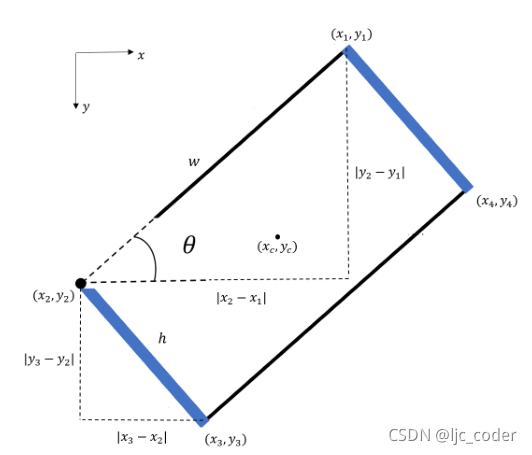
和參數(shù)分別表示矩形中心點的和坐標,可從以下公式獲得:

計算夾持器開口和高度,同樣根據(jù)四個頂點計算:
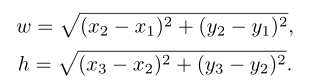
最后,表示夾持器相對于水平軸方向的由下式給出:
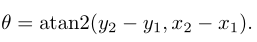
3.3結果評估
預測矩形()和真值矩形()之間的角度差必須在30度以內。
雅卡爾指數(shù)(交并比)需要大于0.25,而不是像一般那樣“達到0.25即可”。
3.4視覺伺服網(wǎng)絡體系結構
與抓取不同,設計用于執(zhí)行機械手視覺伺服控制的網(wǎng)絡接收兩個圖像作為輸入,并且必須回歸六個值,考慮到線性和角度相機速度。
這些值也可以分為兩個輸出,共有四個模型處理VS任務。
模型1-直接回歸(最終實驗效果最佳)。它基本上與抓取網(wǎng)絡相同,除了在第三卷積層中包含最大池化和不同的輸入維度,這導致特征圖上的比例差異相同。
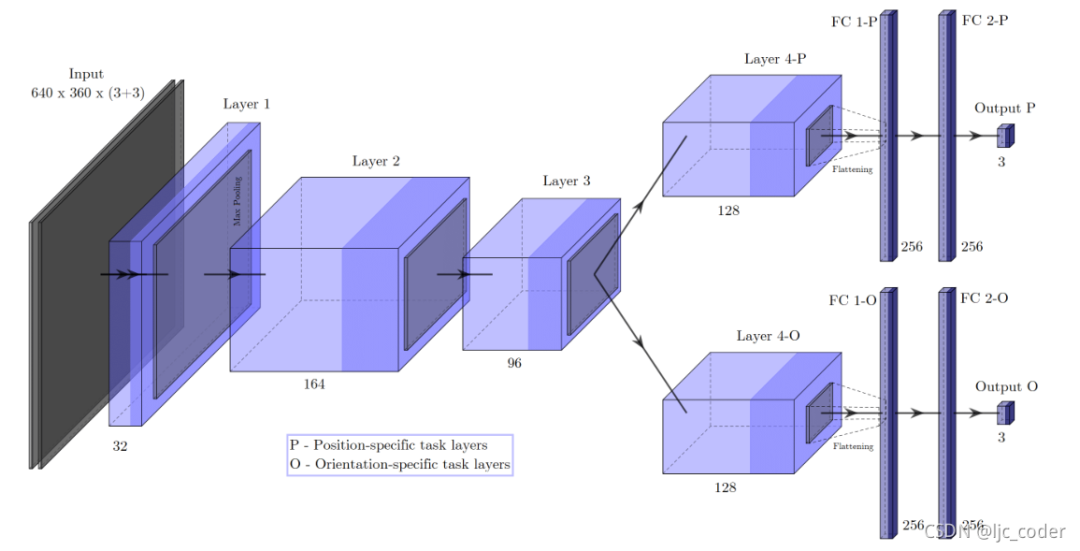
模型2-任務特定回歸。網(wǎng)絡輸入被串聯(lián),第三組特征圖由兩個獨立的層序列處理(多任務網(wǎng)絡)。因此,網(wǎng)絡以兩個3D矢量的形式預測6D速度矢量。具體來說,該結構由一個共享編碼器和兩個特定解碼器組成 - 一個用于線速度,另一個用于角速度。
模型3-串聯(lián)特征的直接回歸和模型4-相關特征的直接回歸,兩個模型的結構類似,通過關聯(lián)運算符()區(qū)分。
模型3簡單連接;模型4使用相關層。
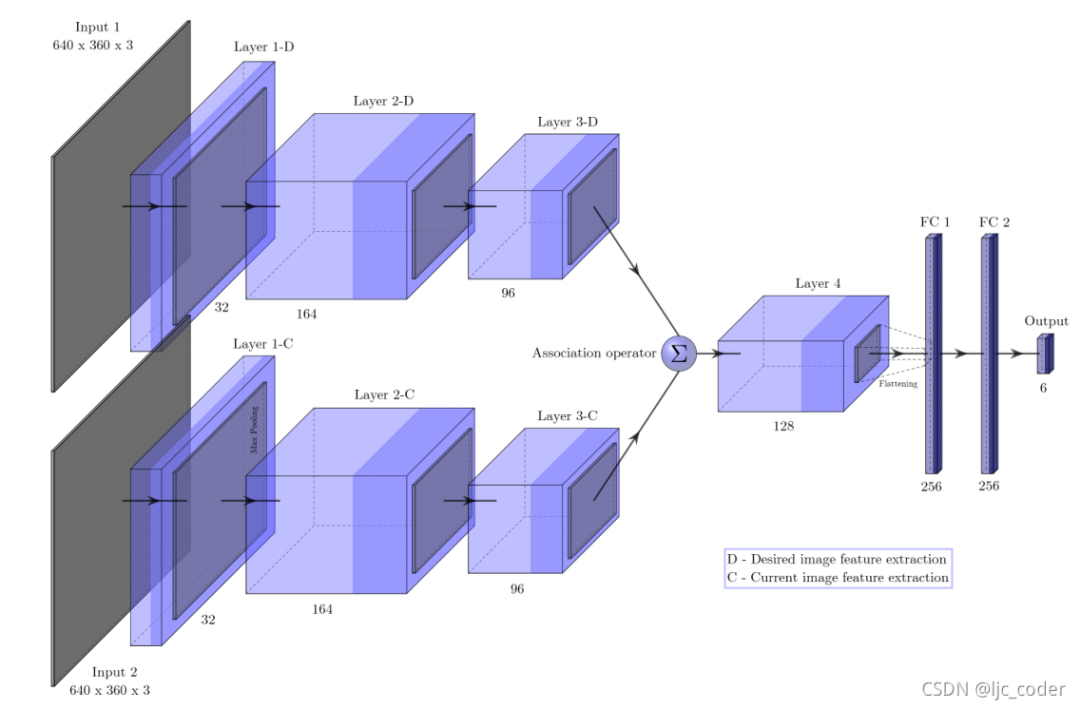
模型3簡單地由第三個卷積層產生的特征映射連接,因此第四個層的輸入深度是原來的兩倍。而模型4有一個相關層,幫助網(wǎng)絡找到每個圖像的特征表示之間的對應關系。原始相關層是flow network FlowNet的結構單元。
3.5VS數(shù)據(jù)集
該數(shù)據(jù)集能夠有效地捕獲機器人操作環(huán)境的屬性,具有足夠的多樣性,以確保泛化。
機器人以參考姿態(tài)為中心的高斯分布的不同姿態(tài),具有不同的標準偏差(SD)。
下表為參考姿勢(分布的平均值)和機器人假設的標準偏差集(SD)。
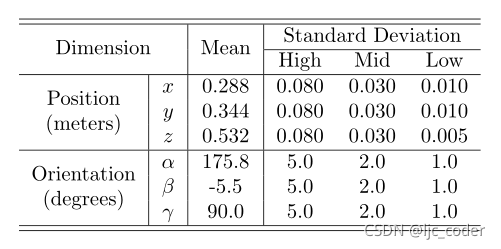
SD選擇考慮了機器人在VS期間必須執(zhí)行的預期位移值。
從高SD獲得的圖像有助于網(wǎng)絡了解機器人產生大位移時圖像空間中產生的變化。
當參考圖像和當前圖像非常接近時,從低SD獲得的實例能夠減少參考圖像和當前圖像之間的誤差,從而在穩(wěn)態(tài)下獲得良好的精度。
平均SD值有助于網(wǎng)絡在大部分VS執(zhí)行期間進行預測。
獲得數(shù)據(jù)后,數(shù)據(jù)集以**的形式構造,其中圖像為I**,****是拍攝該圖像時對應的相機姿態(tài)。
為泰特-布萊恩角內旋(按照變換)
已處理數(shù)據(jù)集的每個實例都采用()表示。是選擇作為所需圖像的隨機實例;選擇另一個實例作為當前圖像;是二者的變換。
通過齊次變換矩陣形式表示每個姿勢(由平移和歐拉角表示)來實現(xiàn)(和),然后獲得
最后,對于實際上是控制器的網(wǎng)絡,其目的是其預測相機的速度信號,即:E控制信號。 被轉化為
是比例相機速度。由于在確定標記比例速度時不考慮增益,因此使用了周期性項,并且在控制執(zhí)行期間必須對增益進行后驗調整。
速度由表示:
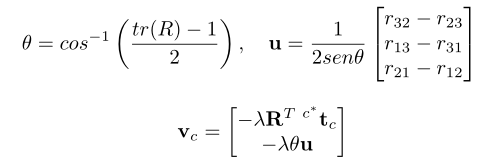
其中,是旋轉矩陣;****同一矩陣第i行和第j列的元素;是與當前相機位置到期望相機位置的平移向量;是比例增益(初始設置為1)。
總市值達到了67.05億元
-
機器人
+關注
關注
213文章
29533瀏覽量
211731 -
神經網(wǎng)絡
+關注
關注
42文章
4810瀏覽量
102918 -
視覺伺服
+關注
關注
0文章
11瀏覽量
7935
原文標題:【機器人識別抓取綜述】基于視覺的機器人抓取—從物體定位、物體姿態(tài)估計到平行抓取器抓取估計
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
機器人視覺——機器人的“眼睛”
【MYD-CZU3EG開發(fā)板試用申請】基于機器視覺的工業(yè)機器人抓取工作站
【瑞芯微RK1808計算棒試用申請】基于機器視覺的工業(yè)機器人抓取工作站
基于圖像的機器人視覺伺服系統(tǒng)該怎么設計?
服務機器人的視覺系統(tǒng)怎么設計?
四元數(shù)數(shù)控:工業(yè)機器人使用機器視覺系統(tǒng)的原因
工業(yè)機器人與視覺實訓平臺介紹
工業(yè)機器人與智能視覺系統(tǒng)應用實訓平臺介紹
ZN-1AI工業(yè)機器人與智能視覺系統(tǒng)應用實訓平臺介紹
機器人視覺系統(tǒng)研究
抓取作業(yè)機器人3D視覺系統(tǒng)的設計
基于視覺的機器人抓取系統(tǒng)
淺談機器人視覺抓取的目的
基于視覺的自主導航移動抓取機器人搭建方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論