 基于特征點的SfM在弱紋理場景下的表現
基于特征點的SfM在弱紋理場景下的表現
SfM是指給定一組無序圖像,恢復出相機位姿以及場景點云。通用場景下的SfM效果已經很好,而且COLMAP這類框架也很好用。但是弱紋理和無紋理場景下的SfM卻很麻煩,主要目前主流的SfM框架都是先提取圖像中的特征點,然后進行特征匹配。但是在無紋理條件下,很難提取穩定且重復的特征點,這就導致SfM恢復出的位姿和三維點云非常雜亂。
很直接的一個想法就是,如果不提取特征點,直接進行匹配呢?
最近,浙江大學就基于這種思想提出了一種弱紋理場景下的SfM框架,主要流程是首先基于LoFTR這類Detector-Free圖像匹配算法獲得粗糙位姿和點云,然后使用Transformer多視圖匹配算法優化特征點坐標,利用BA和TA進一步優化位姿和點云。這個算法獲得了2023 IMC的冠軍,整體性能很好。今天筆者就將帶領大家一起閱讀一下這項工作,當然筆者水平有限,如果有理解不當的地方歡迎大家一起討論。
1. 效果展示
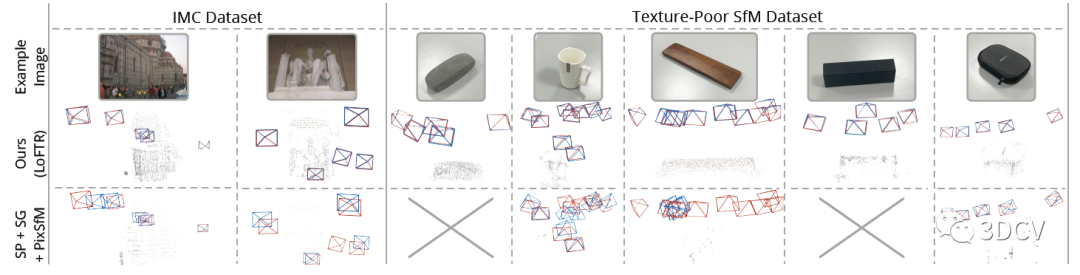
先來看一下傳統基于特征點的SfM在弱紋理場景下的表現:
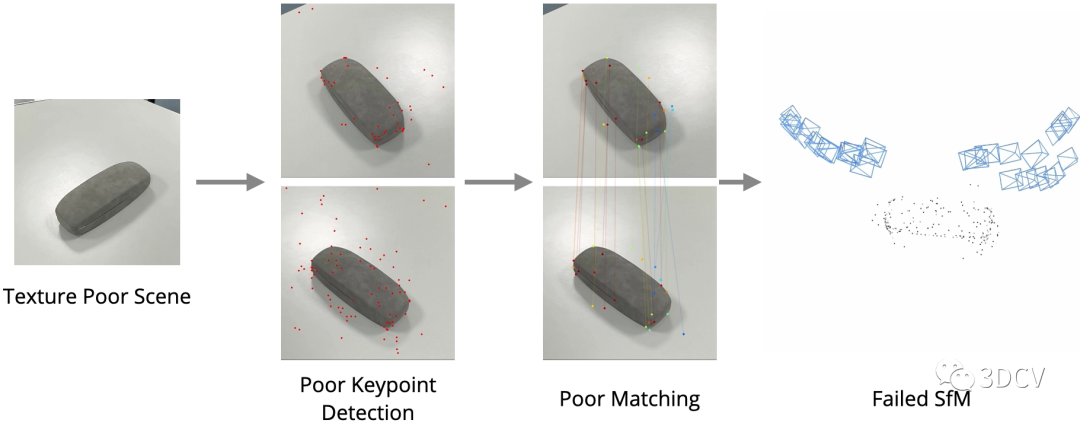
可以發現由于特征點提取的重復性差,匹配性能不好,進一步導致位姿和點云估計的結果很差。那么再來看看Detector-Free SfM這項工作,其主要目的是實現弱紋理場景下的SfM,可以發現在典型場景下運行良好,甚至海底、月球表面這種場景都可以進行定位和重建!推薦學習3D視覺工坊近期開設的課程:國內首個面向自動駕駛目標檢測領域的Transformer原理與實戰課程
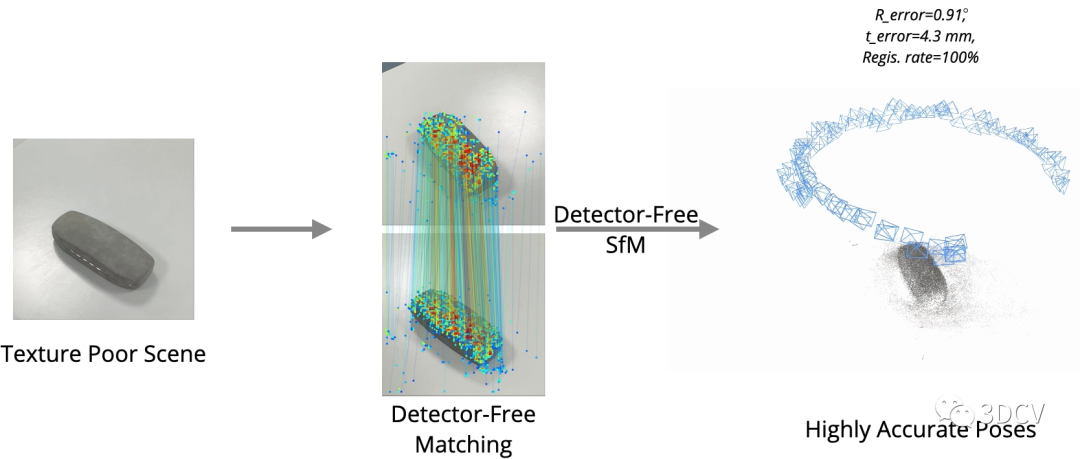

有了精確的位姿和點云,就可以進行很多SfM的下游任務,例如新視點合成和稠密重建:
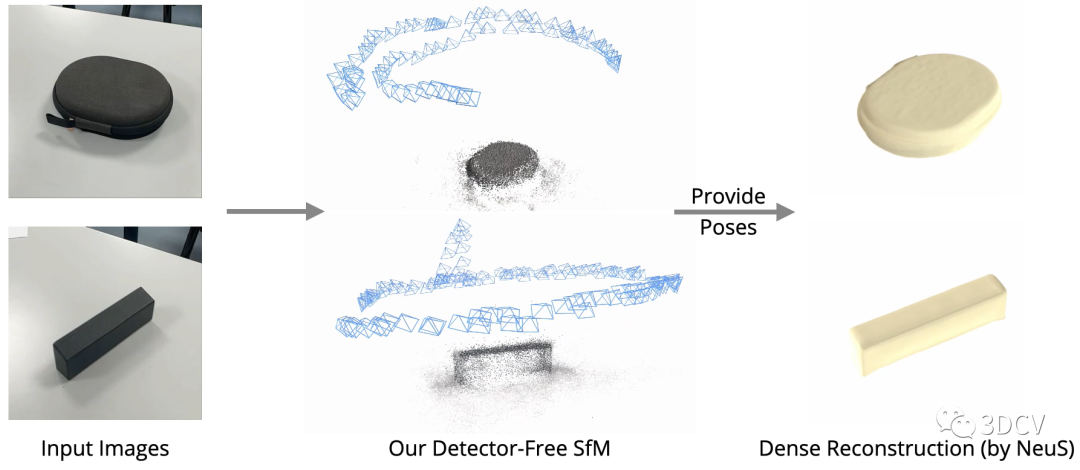
不幸的是,這個算法暫時還沒有開源,感興趣的小伙伴可以追蹤一下Github。下面來看一下論文的具體信息。
我們提出了一個新的SfM框架來從無序的圖像中恢復精確的相機姿態和點云。傳統的SfM系統通常依賴于跨多個視圖的可重復特征點的成功檢測,這對于弱紋理的場景來說是困難的,并且較差的特征點檢測可能會破壞整個SfM系統。受益于最近無檢測器匹配器的成功,我們提出了一種新的無檢測器SfM框架,避免了早期特征點的確定,同時解決了無檢測器匹配器的多視圖不一致問題。具體來說,我們的框架首先從量化的無檢測器匹配中重建一個粗略的SfM模型。然后,它通過一個新穎的迭代優化管道對模型進行細化,該管道在基于注意力的多視圖匹配模塊和幾何優化模塊之間進行迭代,以提高重建精度。實驗表明,所提框架在通用基準數據集上優于現有的基于檢測器的SfM系統。我們還收集了一個弱紋理的SfM數據集,以展示我們的框架重建弱紋理場景的能力。
2. 算法解析
算法的Pipeline非常直觀,輸入是一組無序圖像,輸出是相機位姿、內參和點云。具體的流程是一個兩階段由粗到精的策略,首先使用一個Detector-Free的特征匹配器(LoFTR)來直接進行圖像對的稠密匹配,以此來消除特征點的低重復性帶來的影響。然后量化特征位置到粗網格來提高一致性,并重建粗SfM模型,為后續優化提供初始的相機位姿和場景結構。之后,使用軌跡優化和幾何優化交替進行的聯合迭代優化pipeline,以提高位姿和點云精度。
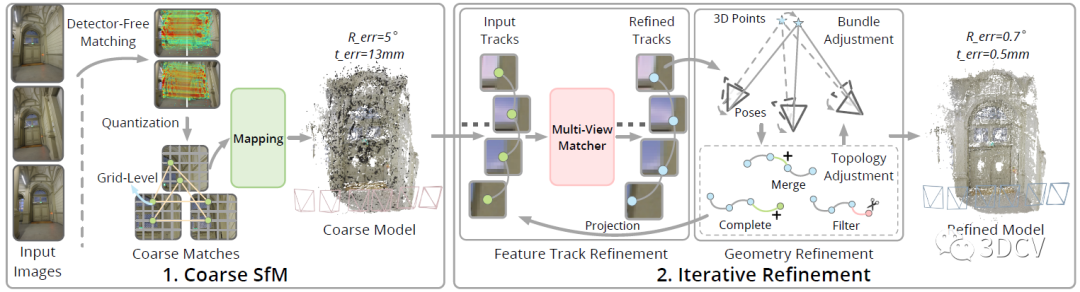
Detector-Free匹配器一般也都采用由粗到精的策略,首先在下采樣特征圖的粗網格上進行稠密匹配,然后在一幅圖像上固定粗匹配的特征位置,而在另一幅圖像上用精細的特征圖搜索它們的亞像素對應關系。理論上這種思想是可以直接應用到SfM上的,但這里有個問題,也就是在一幅圖像中產生的特征位置依賴于另一幅圖像,這樣在多個視圖進行匹配時,特征軌跡就很容易中斷!
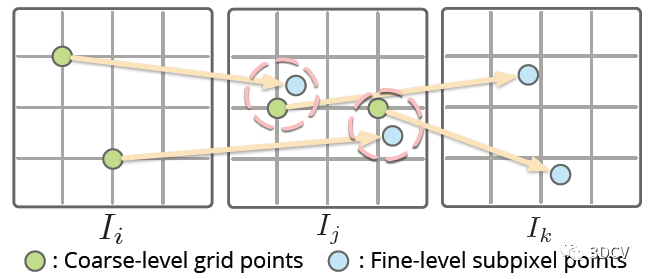
作者的具體做法是,將匹配的2D位置量化為一個網格?x / r?(r是網格大小),直接令多個相近的子像素合并為同一網格節點。實際上是以犧牲精度為代價,換取了一致性。
后續的迭代優化過程很有意思,優化的對象就是匹配點的2D坐標,主要思想還是對所有視圖中的特征點位置進行局部調整,使其特征之間的相關性最大化。
怎么做呢?直接計算所有的關聯視圖嗎?那樣計算量就太大了。
作者這里用了一個trick,就是選擇一個參考視圖,提取參考視圖中特征點處的特征,并將其與其他視圖(查詢視圖)中特征點周圍大小為p × p的局部特征圖進行關聯,得到一組p × p的熱圖,相當于特征點位置的分布。另一方面,還要計算每個熱圖上的期望和方差,方差之和也就是優化的目標函數。
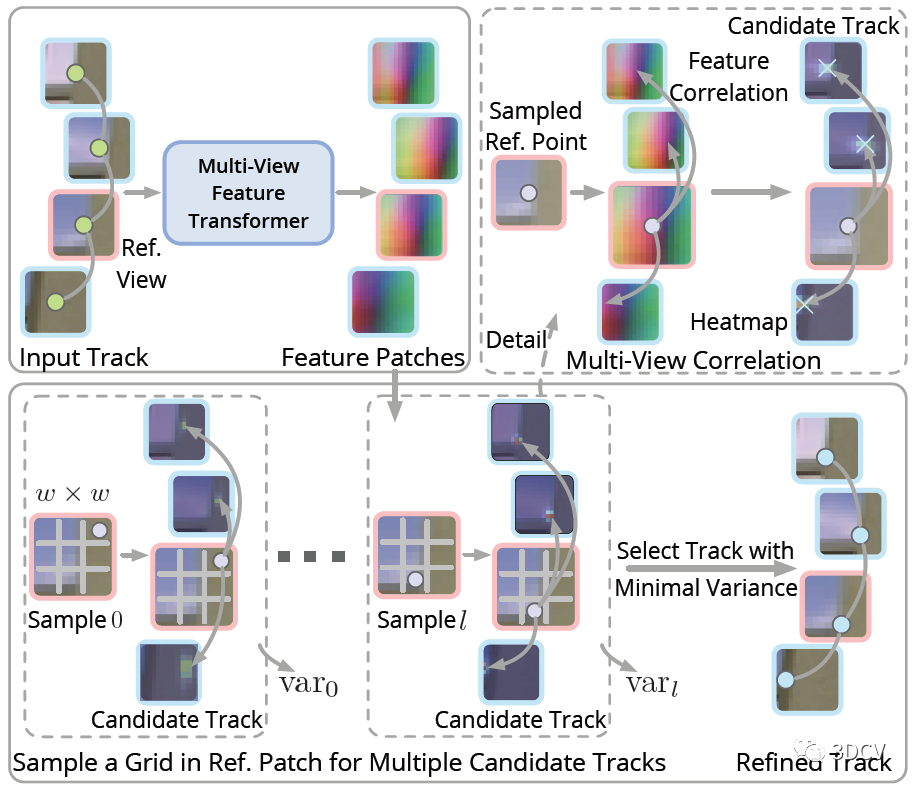
還有個問題,就是這個參考視圖怎么選擇呢?這里的準則其實是最小化參考視圖和查詢視圖之間的特征點尺度差異。具體來說,就是根據當前恢復的位姿和點云計算特征點的深度值,然后選擇中位數做為參考視圖。
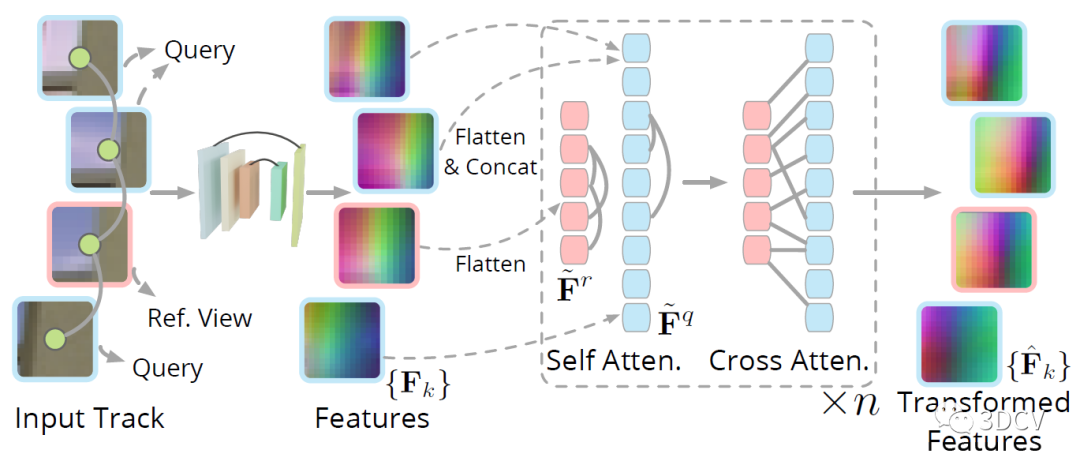
還有個細節,就是如何提取以2D特征點為中心的局部特征塊?這里是將以每個關鍵點為中心的p × p個圖像塊輸入到CNN中,得到一組特征塊,然后再利用Transformer的自注意力和交叉注意力得到最終的特征圖。
最后還有一個級聯的BA和TA(Topology Adjustment)優化的過程,來細化位姿和點云。由于經過了Transformer優化和BA,這時候整體的場景已經比較準確了,因此TA優化過程中還加入了之前未能配準的2D點。整個優化過程,也就是不停的交替進行BA和TA,再把優化后的點云投影到圖像上來更新2D位置,再進行下一次迭代優化。
3. 實驗
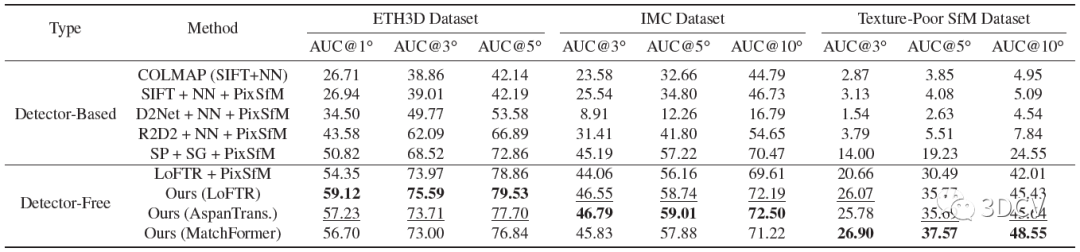
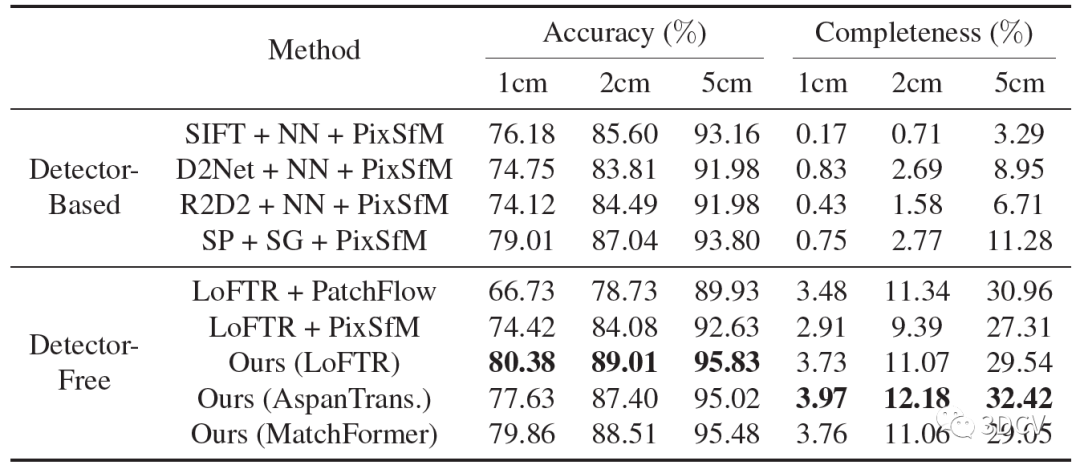
整個模型需要訓練的地方就是Detector-Free匹配器還有多視圖特征提取Transformer,訓練是再MegaDepth數據集進行,訓練思路就是最小化優化軌跡和真實軌跡之間特征點位置上的平均l2損失。對比方案還是挺全的,有SIFT這種手工特征點,也有R2D2、SuperPoint這類深度學習特征點,數據方面使用了Image Matching Challenge (IMC)、ETH3D還有他們自己采集的Texture-Poor SfM數據集。
結果顯示,這個算法搭配LoFTR可以實現比較好的性能(讀者也可嘗試和其他的匹配算法結合)。值得注意的是,SuperPoint + SuperGlue + PixSfM這個組合的性能也非常棒,也說明SP+SG在很多情況下都是通用的。
定性的對比就更直觀了,紅框代表Ground Truth,顯然在低紋理場景下這篇文章提出的算法性能更優,甚至好幾個場合SP+SG的組合直接掛掉了。
再來看看三角化的結果,可以進一步證明位姿和內參估計的準確性。同樣是基于LoFTR的組合取得了更高的精度,這里AspanTrans的配置犧牲了一點精度,但是完整性更好。
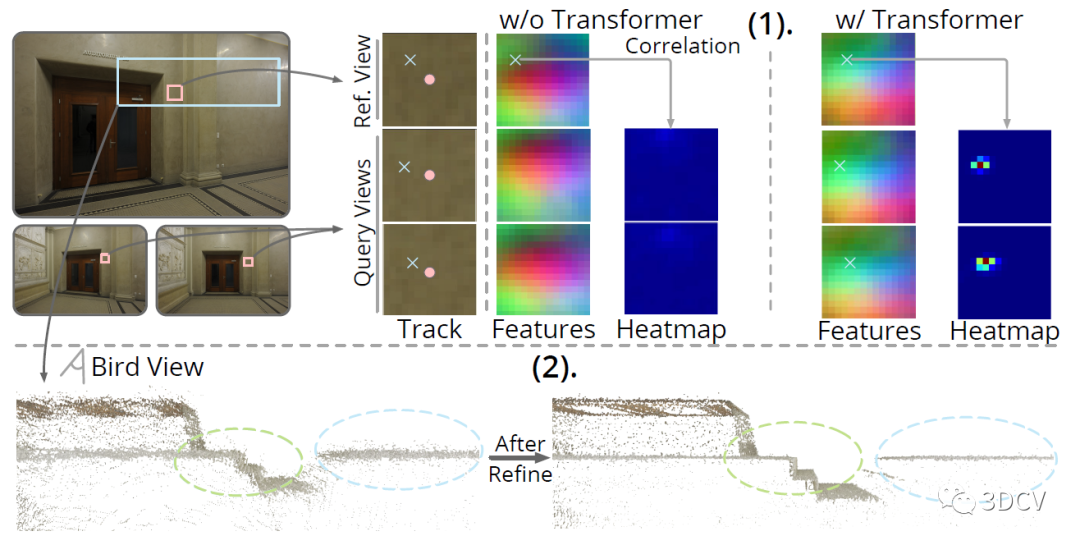
下面是一個驗證優化模塊影響的實驗,做的是熱力圖的比較,O和X分別表示粗糙和精細的特征點位置。結果顯示引入優化后,熱力圖的對比更明顯。而且優化后的點云也更精確。
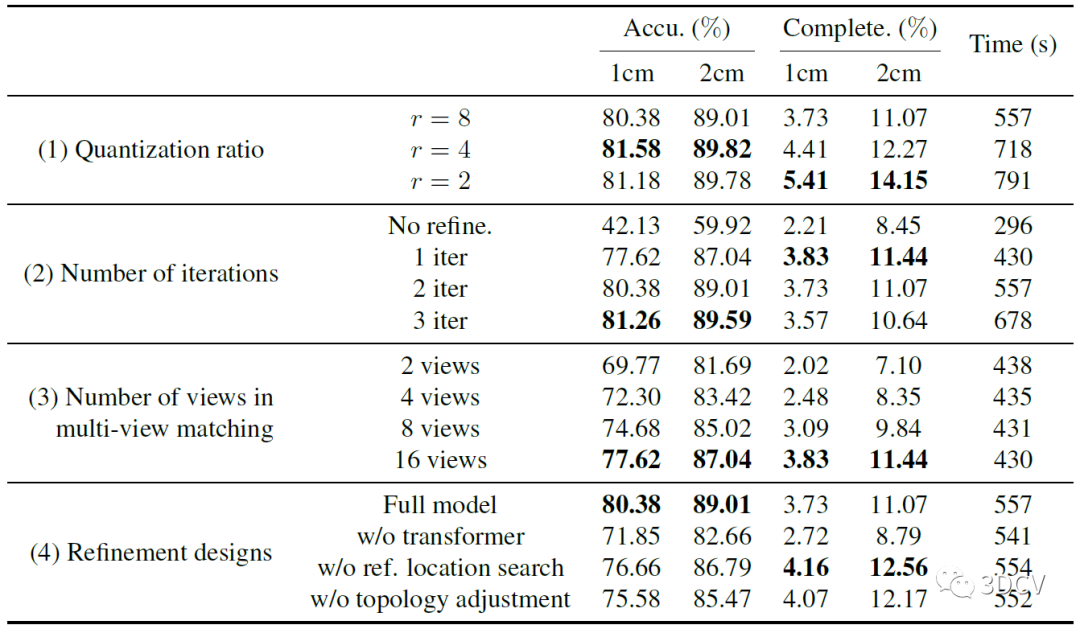
然后是一個消融實驗,分別測試的量化比值、迭代次數、視圖數量以及各部分模塊的消融實驗。主要還是通過這組實驗確定模型和迭代的最優參數。推薦學習3D視覺工坊近期開設的課程:國內首個面向自動駕駛目標檢測領域的Transformer原理與實戰課程
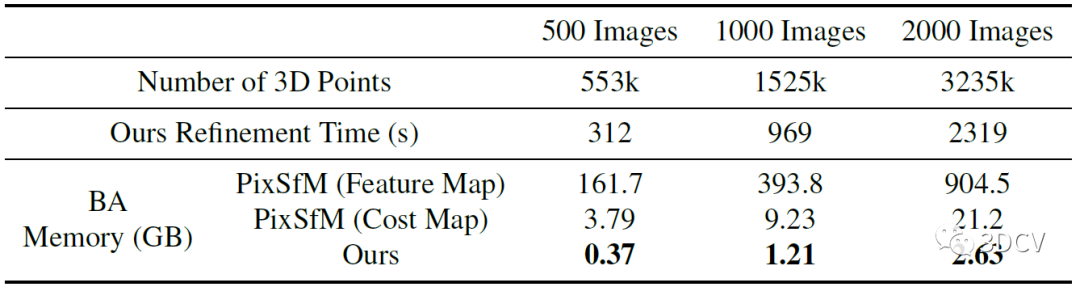
想必大家一定很關心運行的效率和耗時,作者最后做了一個在處理大規模場景時,模型的3D點數、優化時間、內存開銷的一個對比。內存占用沒有多大,這是因為算法是先進行多視圖匹配,再進行幾何優化,因此BA不需要像PixSfM那樣存儲每個2D點的特征塊或代價圖。
4. 總結
這項工作是針對弱紋理這一特定場景設計的,整體的設計思路很通順,效果也非常棒。如果要說問題,那就是計算效率了,畢竟LoFTR匹配本身就非常耗時。但本身SfM就不像SLAM那樣追求實時性,所以計算效率倒也不是什么大問題,可以嘗試通過一些并行BA的方法來優化。另一方面,作者提到可以和深度圖、IMU等多模態數據進行融合,也是很不錯的研究方向。
審核編輯:彭菁
-
相機
+關注
關注
4文章
1434瀏覽量
54480 -
圖像匹配
+關注
關注
0文章
21瀏覽量
8875 -
3D視覺
+關注
關注
4文章
447瀏覽量
28081
原文標題:2023圖像匹配挑戰冠軍方案|無需提取特征點也能進行弱紋理三維重建!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
討論紋理分析在圖像分類中的重要性及其在深度學習中使用紋理分析
基于Contourlet特征修正的紋理圖像識別算法
基于興趣點顏色及紋理特征的圖像檢索算法
基于層次匹配下多種特征融合的蕾絲花邊檢索方法
基于紋理特征匹配的快速目標分割方法





 工商網監
工商網監
評論