 學習村上春樹、史蒂芬·金盜版書,AI巨頭的數據訓練能否被信任?
學習村上春樹、史蒂芬·金盜版書,AI巨頭的數據訓練能否被信任?

導語:AI的狂飆突進,背后站著“數據原罪”的幽靈。
為了訓練大型語言模型,OpenAI、Meta、谷歌、微軟等公司未經許可,從互聯網上收割了數百萬受版權保護的作品,在版權法的灰色地帶中游弋。
如今,OpenAI目前正面臨大量的官司,原告稱該公司訓練數據集中的大多數書籍來自盜版來源和非授權網站。一旦被判侵權,公司有可能將面臨巨額罰款或重構算法的局面。這也導致,如今AI公司越來越不愿意分享AI訓練數據的詳細信息。
但一些公開的盜版語料庫已經被盯上。
近日,有人發現一個叫Books3的數據集,包含近20萬本書籍,囊括村上春樹、史蒂芬·金等暢銷書作家的著作,這個數據集被用在了訓練AI模型上,最近遭到反盜版組織的反復攻擊。
版權問題這把利刃,正懸在AI公司們的頭上,有搖搖欲墜之勢。
Books3,AI公司的秘密
一直以來,對于AI模型的訓練數據并不完全透明。今年,多名美國作家針對OpenAI提起了集體訴訟,指控其使用盜版書籍來訓練其語言模型,侵犯版權并違反了多項法律。
這些作家主張的證據很簡單,因為些他們從未同意OpenAI使用他們的作品,然而ChatGPT卻能提供他們作品的準確摘要,這讓他們認為這些信息肯定是從某個地方獲取的。
根據早期GPT版本的研究論文,其訓練數據集有部分來自于“兩個基于互聯網的書籍語料庫”,它們被簡單地稱為“Books1”和“Books2”,這些數據集具體包含哪些作品比較含糊。
Books1似乎是bookcorpus,里面有數百本書明確聲明“不得以商業或非商業目的復制和分發”。Books2則成為一個謎團,大多人猜測它們來自于“臭名昭著的影子圖書館網站”,如Library Genesis、Z-Library、Sci-Hub和Bibliotik。
其中,Z-Library成立于2008年,是互聯網最大的盜版電子書庫之一。2022年11月,美國政府起訴兩名運營該網站的俄羅斯公民,這兩人在阿根廷被逮捕。
至于GPT-4的45TB訓練數據,其中包含什么內容的信息更加有限,OpenAI多年來逐漸減少了其訓練數據的披露。
盡管目前沒有直接證據表明OpenAI使用盜版網站來培訓ChatGPT,但一些AI模型此前已經明確在盜版書籍上進行了訓練,包括使用“Books3”數據集的AI模型。
EleutherAI的Pythia研究論文中提到,Pythia是使用Pile數據集進行訓練的,而Pile數據集包含多個英語文本集,其中之一就是名為“Books3”的數據集。
Books3是用于訓練AI的最著名的盜版書籍庫之一,最初是由AI開發人員和知名開源AI支持者Shawn Presser于2020年上傳。它包含37 GB的文本,包括196640本純文本格式的書籍,并在盜版網站bibliotik上托管。
“假設你想訓練一個世界級的GPT模型,就像OpenAI一樣。怎么做?你沒有數據。現在你可以做到,現在每個人都這樣做。為你呈現‘books3’,又名‘all of bibliotik’。”Shawn Presser最早在社交平臺上寫道。
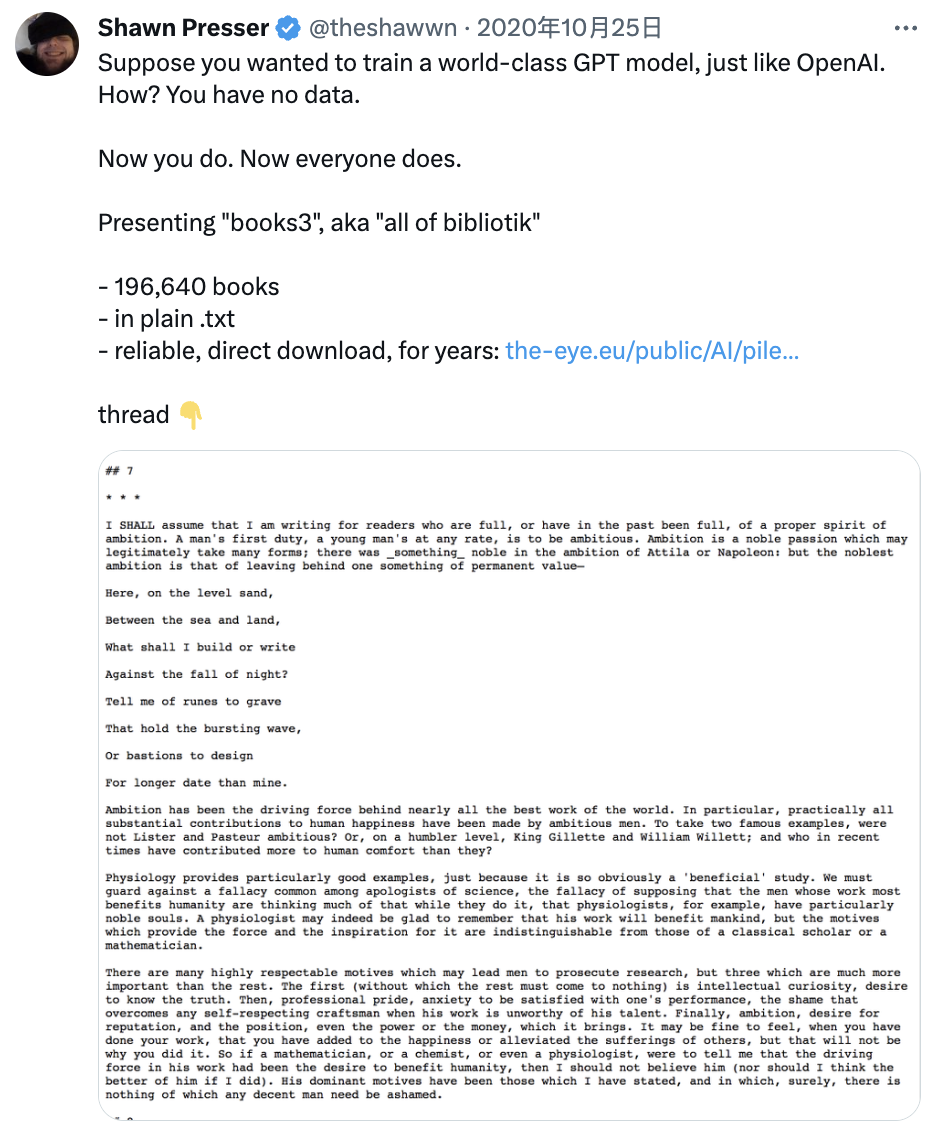
開源AI支持者Shawn Presser于2020年上傳“books3”,圖片來源:X
然而,反盜版組織也在采取行動,代表相關利益群體,試圖限制未經授權的AI訓練數據的使用。
這段時間,反盜版組織Rights Alliance向相關站點發送刪除通知后,相關站點已將Books3數據集下線,導致嘗試訪問該數據集的用戶會看到404錯誤。
Rights Alliance還聯系了AI模型托管平臺Hugging Face(該站點托管了Books3下載鏈接)以及EleutherAI。然而,盡管一些鏈接被下架,該數據集的副本并未消失,仍然在其他地方出現。
遭到針對后,Shawn Presser繼續發布新的下載鏈接,他稱,除非反對者打算讓ChatGPT下線,或者通過訴訟將其告到滅亡,否則,他希望每個人都能夠制作自己的ChatGPT,他還稱自己“很樂意入獄10個月(海盜灣創始人服過的最高刑期),因為我推動了科學進步并賦予了你們復制ChatGPT的能力。”
“復制ChatGPT這樣的模型的唯一方法,是創建像Books3這樣的數據集。”Shawn Presser稱:“每個營利性公司都會秘密地這樣做,不會將數據集發布給公眾。”
“沒有Books3,我們就生活在一個只有OpenAI和其他億萬美元公司才能訪問這些書籍的世界中,這意味著你不能制作自己的ChatGPT。沒有人能。只有億萬美元的公司才有資源做到這一點。”
包括Meta在內的一些公司曾經使用過Books3,另外,Meta、谷歌都使用過的C4訓練數據集也被詬病過,現在這些公司對其語言模型中的內容更為保密。
Meta的Llama 2增加了40%的數據,但在其白皮書中,該公司對其最新的 大語言模型使用了什么數據更為猶豫,唯一提到的是“一個新的混合的公開可用在線數據”。隨著AI和版權之間的摩擦升溫,公司越來越不愿意分享AI訓練數據的詳細信息。
萬名作家聯名反對
超一萬名作家敦促AI公司停止使用其作品。他們不希望AI模仿其作品并學會寫作,除非科技公司為此付費。
美國的作家協會已經向巨頭們發了一封公開信,包括OpenAI、谷歌、Meta、Stability AI、IBM和微軟公司的各大CEO,要求他們停止未經許可使用他們的作品,或對使用作品進行補償。
其中包括《達芬奇密碼》作者丹·布朗、《饑餓游戲》作者蘇珊·柯林斯、《使女的故事》作者瑪格麗特·阿特伍德、《自由》作者喬納森·弗蘭岑等人都簽署了這封公開信,簽署的作家名單長達100多頁。
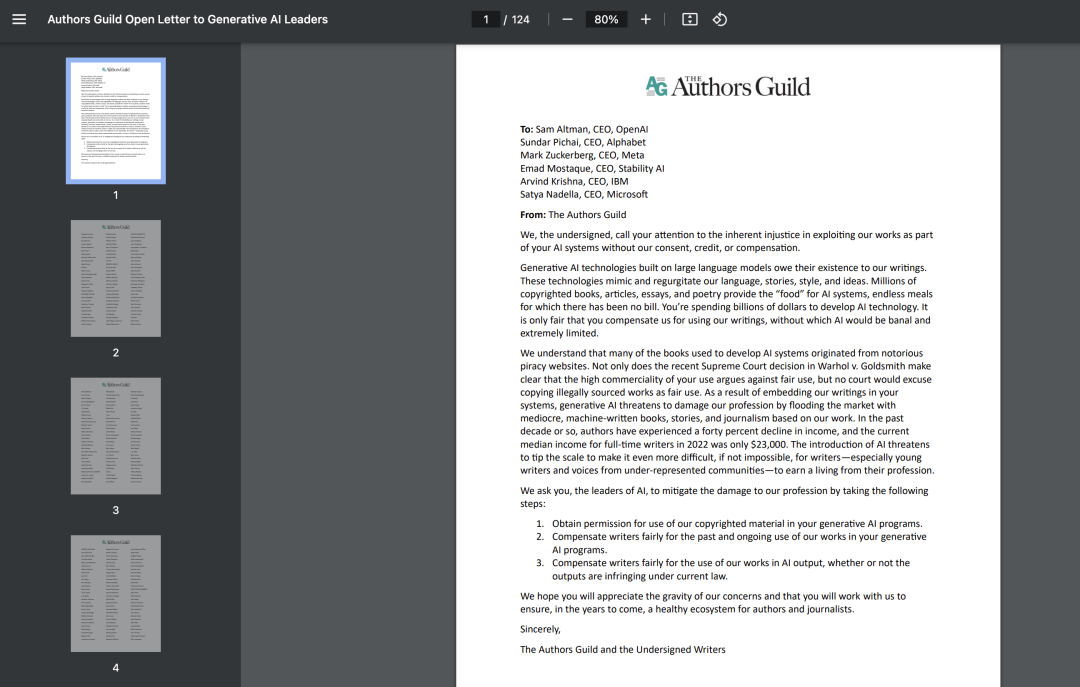
一萬名作家簽署公開信 ,圖片來源:美國作家協會
目前,該作家協會正嘗試先在不提起訴訟的情況下解決爭端,因為“訴訟需要大量的資金,而且需要很長時間。”
但也有一些文學界人士愿意直接在法庭上與科技公司對抗,控訴Meta或OpenAI等使用盜版來訓練他們的AI。此外,文學經紀人們正在與出版商商討,要更新出版合同條款,禁止未經授權的AI訓練用途,大部分出版商都愿意限制AI使用他們的出版物。
根據美國作家協會的調查,90%的作家認為,作家應該獲得對其作品用于訓練生成式人工智能的補償,65%的作家支持建立一個集體授權制度,以補償作者的作品被用于訓練生成式AI。
此外,69%的作家認為他們的職業受到生成式AI的威脅,70%的作家認為出版商將開始使用AI來完全或部分生成書籍,取代人類作者。
除了發公開信、打官司、完善合同,出版業還在進一步尋求立法。
美國作家協會的人正在游說制定相關法律、法規和政策:在同意方面,要求在生成式人工智能中使用作家作品時獲得許可;在補償方面,為那些希望允許其作品用于生成式人工智能培訓的作家提供補償;在透明度方面,要求人工智能開發者透明披露他們用于培訓其人工智能的作品。
他們也期望,生成式AI的輸出使用到作家的作品時,要獲得許可并建立相應的補償機制,或者當在提示中使用作家的姓名、身份或作品標題時,也應獲得許可。此外,他們要求作者、出版商、平臺和市場標明AI生成的作品,并在作品很大一部分(例如超過10-20%)由AI生成時進行標識。
“我們需要確保人類創作者得到補償,這不僅是為了創作者本身,而是為了確保我們的書籍和藝術繼續反映出我們的真實和想象的經驗,開拓我們的思維方式,教導我們新的思維方式,并推動我們社會的發展,而不是重復舊觀念。”該作家協會在官方聲明中稱。
NYT VS OpenAI
除了作家和藝術家,其他類型的內容創作者,也紛紛加入起訴 AI 公司的行列,一些新聞機構批評科技公司未經授權或補償就使用他們的內容。
比如,紐約時報正在考慮對OpenAI提起訴訟,稱OpenAI的ChatGPT使用了該報的數據進行訓練,而未經紐約時報許可。在過去的幾個月里,OpenAI和紐約時報一直在試圖達成一項有關紐約時報內容的許可協議。但談判還未有結果,存在破裂的可能。
在最近對其服務條款政策的更改中,紐約時報明確禁止將其龐大的媒體檔案用于訓練“任何軟件程序,包括但不限于訓練機器學習或人工智能(AI)系統”的目的。該政策適用于紐約時報的文本內容、照片、視頻和元數據,并明確禁止網絡爬蟲訪問這些數據來訓練專有產品。
這里做一個假設,如果法院判定OpenAI等AI公司的訓練行為屬于侵權,OpenAI可能會被迫停止使用受版權保護的數據,并在不使用受版權保護的數據的前提下,重新構建其算法,這會引發多大的麻煩?
科技公司也試圖與新聞媒體建立關系。谷歌曾試圖爭取像紐約時報、華盛頓郵報等新聞機構的支持,試圖向他們推銷AI工具。還有AI公司向新聞非營利機構提供微薄的慈善捐款。
期間,也有新聞機構不那么強硬。美聯社今年就與OpenAI達成了一項為期兩年的許可協議,同意將美聯社的內容授權給OpenAI使用訓練。作為回報,OpenAI提供了美聯社訪問“OpenAI的技術和產品專業知識”的權利。
懸在AI公司頭上的“達摩克利斯之劍”
AI公司抓取海量互聯網數據,已經導致法律問題的出現,起訴AI公司的人正在變得越來越多。
今年,美國一律所相繼對OpenAI、Meta等巨頭提起訴訟,指控他們未經同意、未經授權或未經補償地占用成千上萬名作家的作品,來訓練他們的大語言模型。行業預計訴訟規模將很龐大,因為其他內容創作者也有可能受此啟發采取法律行動。
其他生成AI公司,如AI圖像生成工具Stable Diffusion背后的Stability AI,也惹上版權官司。Stable Diffusion是在LAION-5B數據集上進行訓練的,數據集包含58.5億個圖像文本對,大多數都受版權保護。Getty Images正在起訴Stability AI,指控其未經授權在超過1200萬張Getty Images上訓練AI圖像生成模型。
許多藝術家和利益相關者也表示不滿,對Stability AI、DeviantArt和Midjourney等公司提起訴訟,指控他們侵犯版權、侵犯肖像權、不正當競爭和不正當獲利,尋求賠償和禁令。
微軟推出的編程工具Copilot也面臨集體訴訟。Copilot是GitHub與OpenAI合作開發的基于人工智能的自動編程產品,主要利用GitHub上的公共代碼庫,在數十億行公開可用的代碼上進行了訓練,能通過簡單提示替用戶編寫代碼。開源程序員和律師指控他們從事開源軟件盜版,被告包括GitHub、微軟及其人工智能技術合作伙伴OpenAI。
如果要打官司,AI公司可能會援引所謂的“公平使用原則”來為其辯護,該原則允許在某些情況下無需許可即可使用作品,包括教學、批評、研究和新聞報道。問題是,AI訓練是否適用“公平使用原則”。
幾年前,美國作家協會也曾起訴谷歌,理由是谷歌未購買其圖書館項目中收錄的書籍,當時,聯邦上訴法院判決認為,谷歌為其圖書館項目掃描了數百萬本書的數字副本是合法的“公平使用”,而非侵犯版權。關鍵在于,谷歌的數字圖書館并沒有為這些書創造出“重大市場替代品”,這意味著它與原作并無競爭關系。
目前,各國政府正努力將生成式AI納入立法范疇。歐盟也在制定一項AI法案,該法案將迫使公司將訓練模型信息透明化。上半年,美國作家協會已兩次訪問國會山,討論生成式AI和作家保護措施的問題,涉及的問題包括集體授權和版權保護、反壟斷豁免權以及AI標簽和透明度要求。
“除非國會采取干預措施,以確保生成式人工智能技術的開發和使用受到監管,否則驅動原創表達并豐富我們文化交流的重要版權激勵將變得毫無意義。”該作家協會在官方聲明中稱。
從現有輿論看,雖然一些人擔心訓練AI可能會引發版權問題,但也有人認為,OpenAI等AI公司不需要特別的許可協議來訓練模型,版權擔憂不利于AI發展進步;有人則認為,取得作者的同意是至關重要的,創作者應該有拒絕的權利,或者,AI公司至少應該購買訓練數據的書籍。
技術正在做人類歷史上從未發生過的事情,AI訓練數據方面的開源精神應該有底線嗎?未來的法律是掣肘還是保護?如何平衡AI的發展與尊重人類創作權益,可能是和“通用人工智能何時到來”同樣重要的問題。
-
人工智能
+關注
關注
1806文章
48972瀏覽量
248732 -
模型
+關注
關注
1文章
3513瀏覽量
50324 -
數據集
+關注
關注
4文章
1223瀏覽量
25396
原文標題:學習村上春樹、史蒂芬·金盜版書,AI巨頭的數據訓練能否被信任?
文章出處:【微信號:alpworks,微信公眾號:阿爾法工場研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論