 為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
有理論基礎,我們就可以進行深度優化了。為什么 transformer 性能這么好?它給眾多大語言模型帶來的上下文學習 (In-Context Learning) 能力是從何而來?在人工智能領域里,transformer 已成為深度學習中的主導模型,但人們對于它卓越性能的理論基礎卻一直研究不足。 最近,來自 Google AI、蘇黎世聯邦理工學院、Google DeepMind 研究人員的新研究嘗試為我們揭開謎底。在新研究中,他們對 transformer 進行了逆向工程,尋找到了一些優化方法。論文《Uncovering mesa-optimization algorithms in Transformers》:
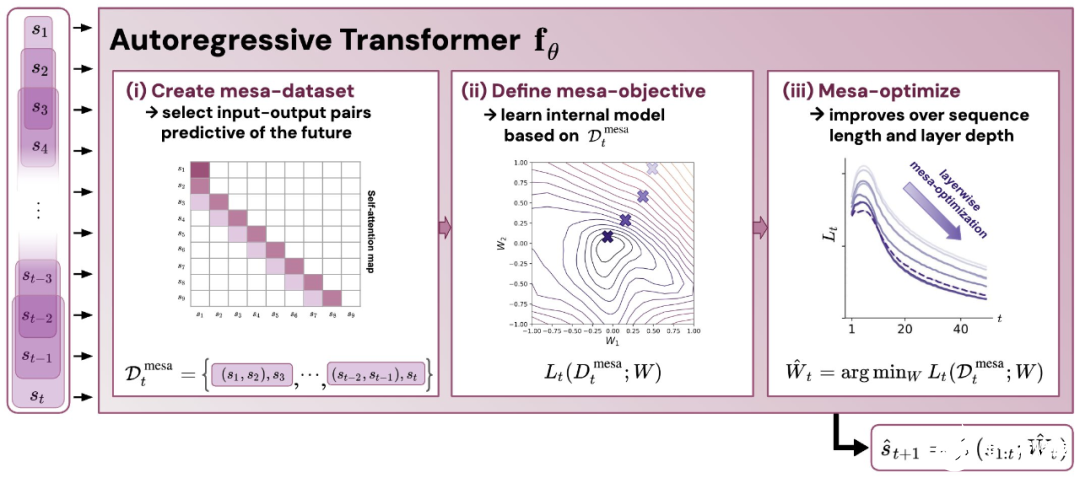
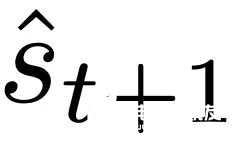 。 該研究的貢獻包括:
。 該研究的貢獻包括:
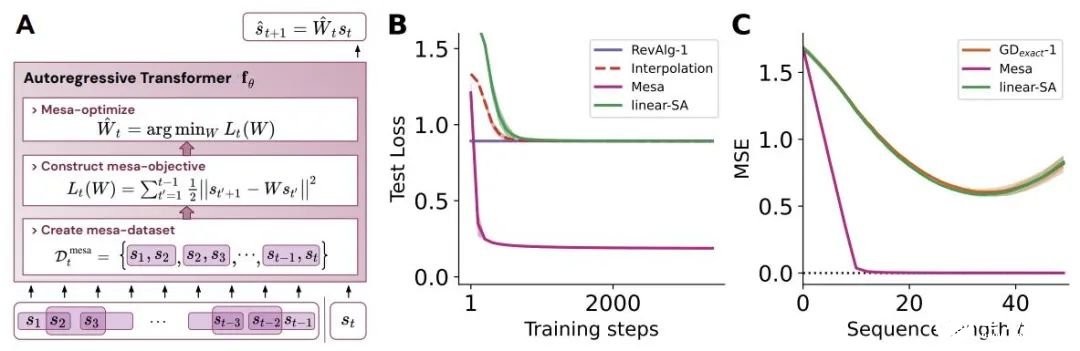
- 概括了 von Oswald 等人的理論,并展示了從理論上,Transformers 是如何通過使用基于梯度的方法優化內部構建的目標來自回歸預測序列下一個元素的。
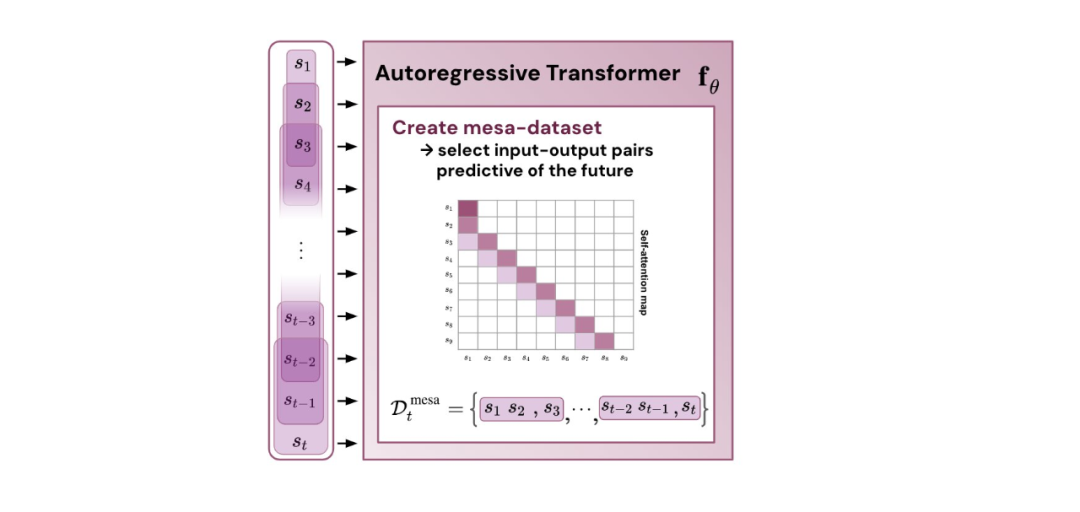
- 通過實驗對在簡單序列建模任務上訓練的 Transformer 進行了逆向工程,并發現強有力的證據表明它們的前向傳遞實現了兩步算法:(i) 早期自注意力層通過分組和復制標記構建內部訓練數據集,因此隱式地構建內部訓練數據集。定義內部目標函數,(ii) 更深層次優化這些目標以生成預測。
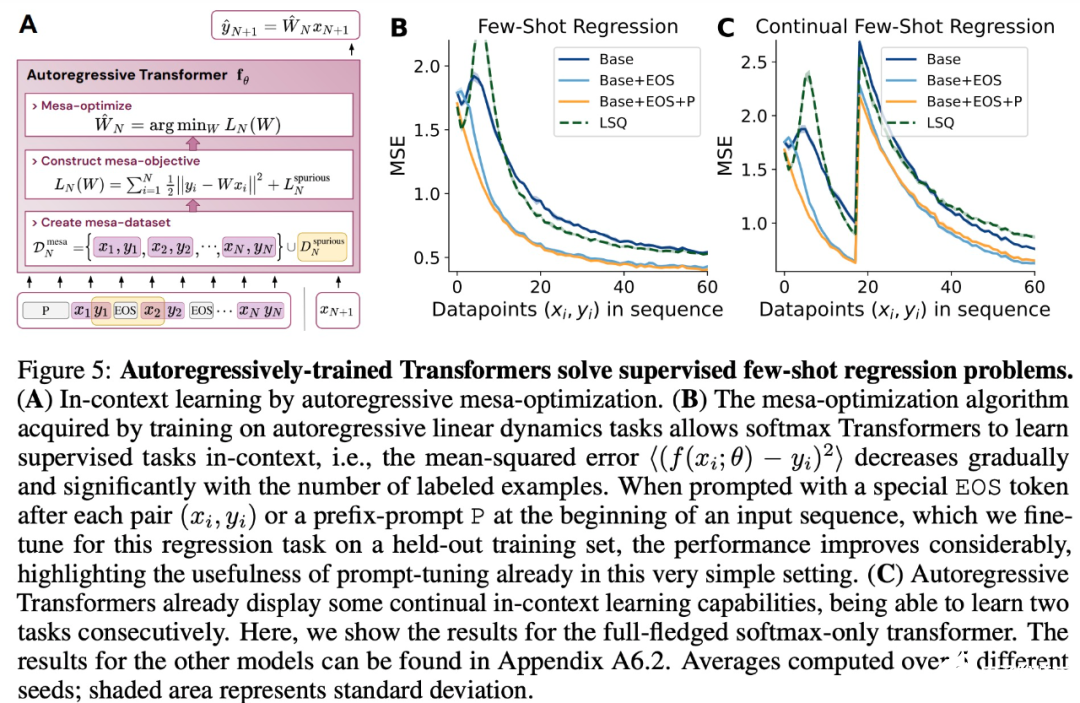
- 與 LLM 類似,實驗表明簡單的自回歸訓練模型也可以成為上下文學習者,而即時調整對于改善 LLM 的上下文學習至關重要,也可以提高特定環境中的表現。
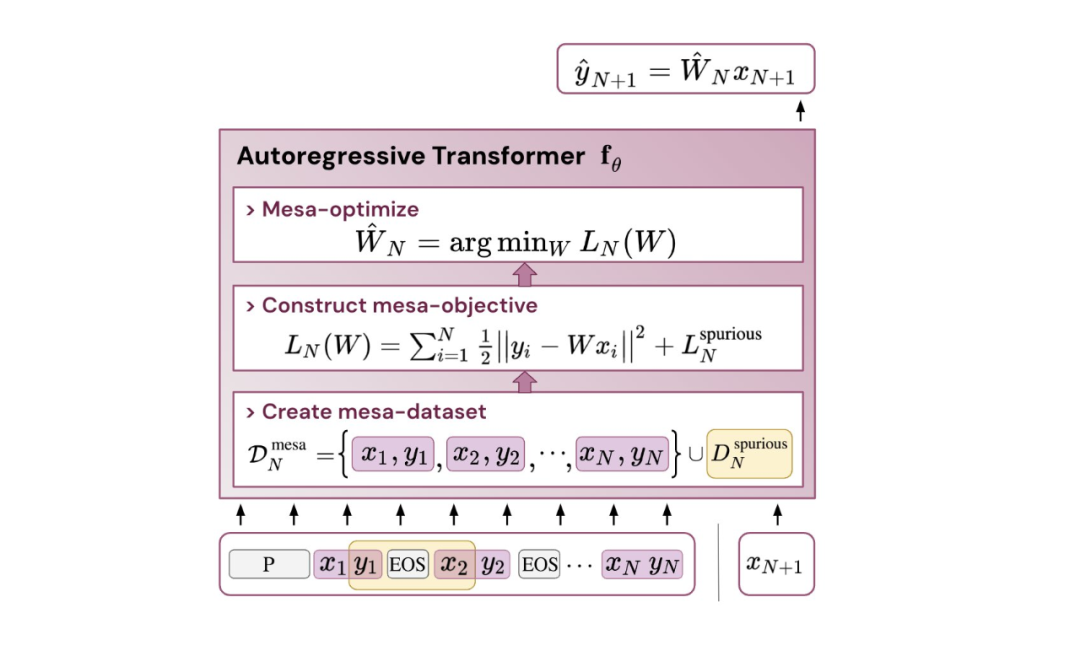
- 受發現注意力層試圖隱式優化內部目標函數的啟發,作者引入了 mesa 層,這是一種新型注意力層,可以有效地解決最小二乘優化問題,而不是僅采取單個梯度步驟來實現最優。實驗證明單個 mesa 層在簡單的順序任務上優于深度線性和 softmax 自注意力 Transformer,同時提供更多的可解釋性。

- 在初步的語言建模實驗后發現,用 mesa 層替換標準的自注意力層獲得了有希望的結果,證明了該層具有強大的上下文學習能力。
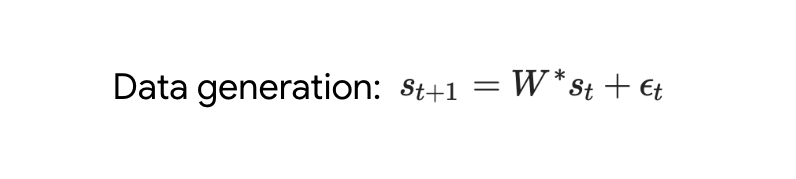
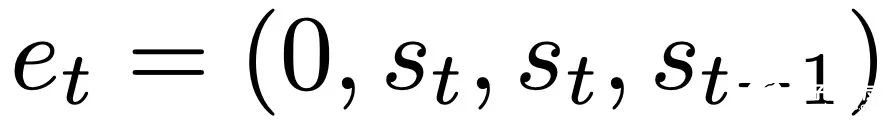 ,這對應于選擇 W_0 = 0。
,這對應于選擇 W_0 = 0。
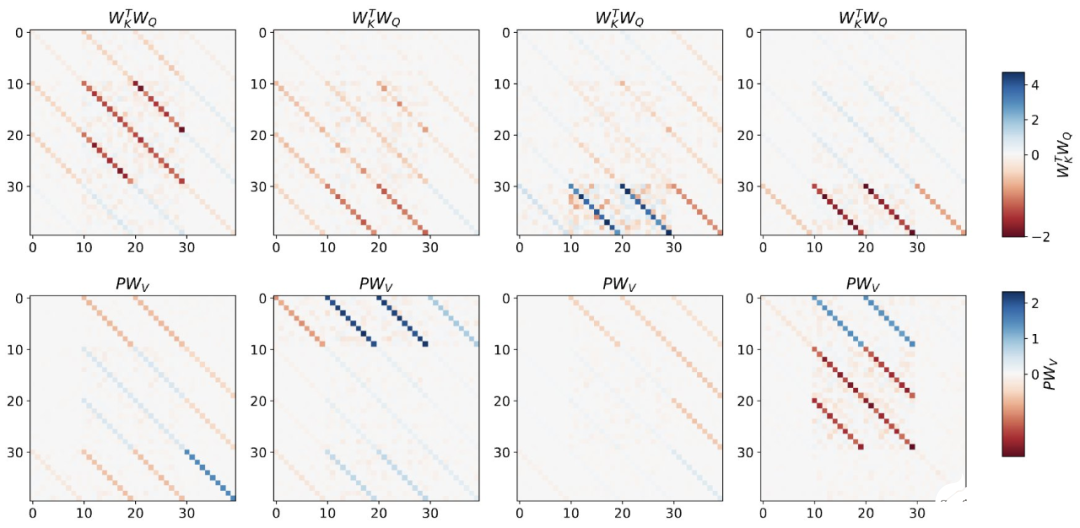
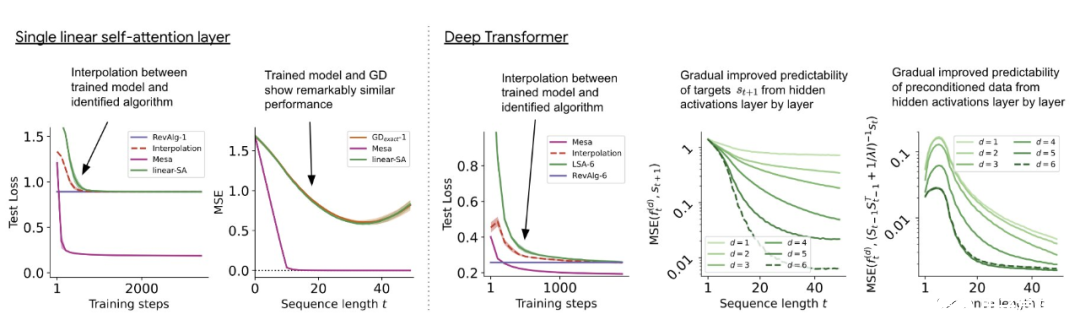
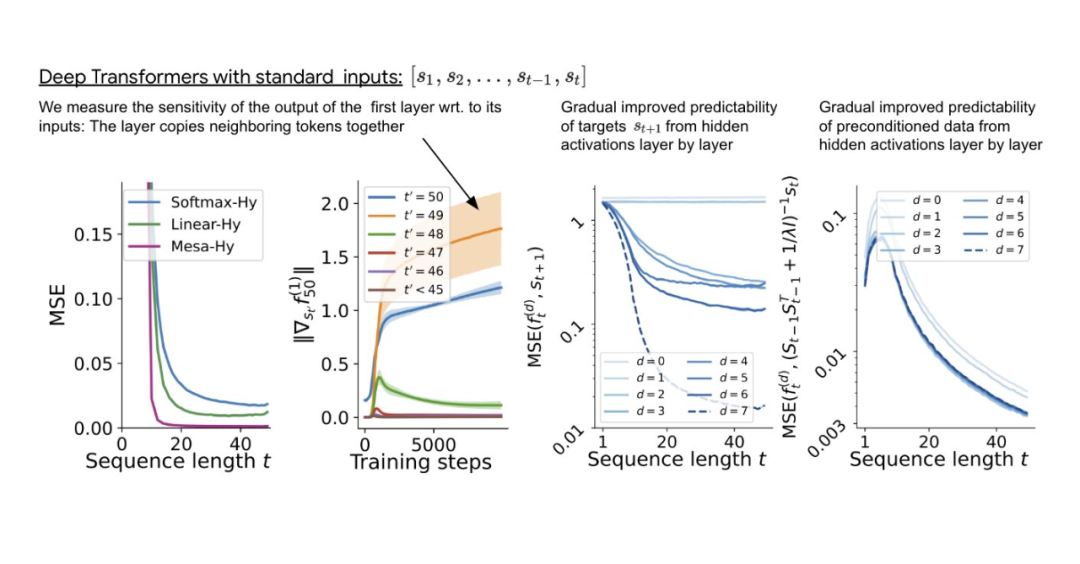
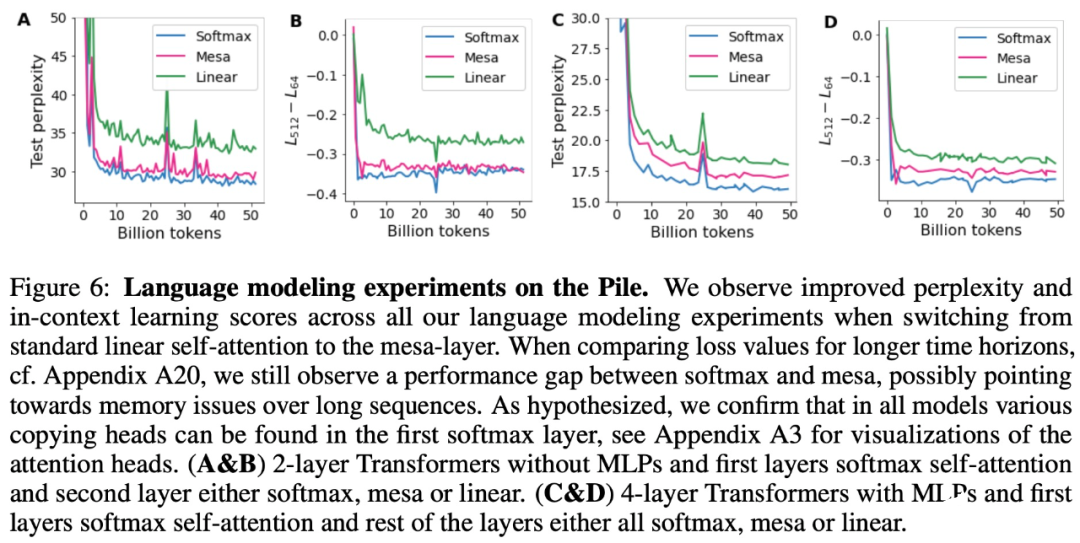
與單層模型一樣,作者在訓練模型的權重中看到了清晰的結構。作為第一個逆向工程分析,該研究利用這個結構并構建一個算法(RevAlg-d,其中 d 表示層數),每個層頭包含 16 個參數(而不是 3200 個)。作者發現這種壓縮但復雜的表達式可以描述經過訓練的模型。特別是,它允許以幾乎無損的方式在實際 Transformer 和 RevAlg-d 權重之間進行插值。 雖然 RevAlg-d 表達式解釋了具有少量自由參數的經過訓練的多層 Transformer,但很難將其解釋為 mesa 優化算法。因此,作者采用線性回歸探測分析(Alain & Bengio,2017;Akyürek et al.,2023)來尋找假設的 mesa 優化算法的特征。 在圖 3 所示的深度線性自注意力 Transformer 上,我們可以看到兩個探針都可以線性解碼,解碼性能隨著序列長度和網絡深度的增加而增加。因此,基礎優化發現了一種混合算法,該算法在原始 mesa-objective Lt (W) 的基礎上逐層下降,同時改進 mesa 優化問題的條件數。這導致 mesa-objective Lt (W) 快速下降。此外可以看到性能隨著深度的增加而顯著提高。 因此可以認為自回歸 mesa-objective Lt (W) 的快速下降是通過對更好的預處理數據進行逐步(跨層)mesa 優化來實現的。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
人工智能
+關注
關注
1804文章
48449瀏覽量
245058 -
深度學習
+關注
關注
73文章
5547瀏覽量
122315 -
DeepMind
+關注
關注
0文章
131瀏覽量
11235 -
Transformer
+關注
關注
0文章
148瀏覽量
6327 -
大模型
+關注
關注
2文章
2941瀏覽量
3685
原文標題:Transformer的上下文學習能力是哪來的?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
DeepSeek推出NSA機制,加速長上下文訓練與推理
的特性,專為超快速的長上下文訓練和推理而設計。 NSA通過針對現代硬件的優化設計,顯著加快了推理速度,并大幅度降低了預訓練成本,同時保持了卓越的性能表現。這一機制在確保效率的同時,并未犧牲模型的準確性或功能。 在廣泛的基準測試、涉及長上
如何使用MATLAB構建Transformer模型
Transformer 模型在 2017 年由 Vaswani 等人在論文《Attentionis All You Need》中首次提出。其設計初衷是為了解決自然語言處理(Nature

transformer專用ASIC芯片Sohu說明
2022年,我們打賭說transformer會統治世界。 我們花了兩年時間打造Sohu,這是世界上第一個用于transformer(ChatGPT中的“T”)的專用芯片。 將transformer

《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
方法
元學習+GPICL方法
零樣本能力
提供高性能,無需任務特定微調即可推廣到新任務。
零樣本性能較差,專注于通過上下文學習適應任務。
可
發表于 12-24 15:03

SystemView上下文統計窗口識別阻塞原因
SystemView工具可以記錄嵌入式系統的運行時行為,實現可視化的深入分析。在新發布的v3.54版本中,增加了一項新功能:上下文統計窗口,提供了對任務運行時統計信息的深入分析,使用戶能夠徹底檢查每個任務,幫助開發人員識別阻塞原因。
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
的信息,提供更全面的上下文理解。這使得模型能夠更準確地理解復雜問題中的多個層面和隱含意義。
2. 語義分析
模型通過訓練學習到語言的語義特征,能夠識別文本中的命名實體、句法結構和語義關系等信息。這些
發表于 08-02 11:03
Transformer能代替圖神經網絡嗎
Transformer作為一種在處理序列數據方面表現出色的深度學習模型,自其提出以來,已經在自然語言處理(NLP)、時間序列分析等領域取得了顯著的成果。然而,關于Transformer是否能完全代替圖神經網絡(GNN)的問題,需
Transformer語言模型簡介與實現過程
在自然語言處理(NLP)領域,Transformer模型以其卓越的性能和廣泛的應用前景,成為了近年來最引人注目的技術之一。Transformer模型由谷歌在2017年提出,并首次應用于神經機器翻譯
使用PyTorch搭建Transformer模型
Transformer模型自其問世以來,在自然語言處理(NLP)領域取得了巨大的成功,并成為了許多先進模型(如BERT、GPT等)的基礎。本文將深入解讀如何使用PyTorch框架搭建Transformer模型,包括模型的結構、訓練過程、關鍵組件以及實現細節。
鴻蒙Ability Kit(程序框架服務)【應用上下文Context】
[Context]是應用中對象的上下文,其提供了應用的一些基礎信息,例如resourceManager(資源管理)、applicationInfo(當前應用信息)、dir(應用文件路徑)、area
編寫一個任務調度程序,在上下文切換后遇到了一些問題求解
大家好,
我正在編寫一個任務調度程序,在上下文切換后遇到了一些問題。
為下一個任務恢復上下文后:
__builtin_tricore_mtcr_by_name(\"pcxi\"
發表于 05-22 07:50
微信大模型擴容并開源,推出首個中英雙語文生圖模型,參數規模達15億
基于Diffusion Transformer的混元DiT是一種文本到圖像生成模塊,具備中英細粒度理解能力,能與用戶進行多輪對話,根據上下文生成并完善圖像。
【大語言模型:原理與工程實踐】大語言模型的基礎技術
Transformer有效避免了CNN中的梯度消失和梯度爆炸問題,同時提高了處理長文本序列的效率。此外,模型編碼器可以運用更多層,以捕獲輸入序列中元素間的深層關系,并學習更全面的上下文向量表示。
預訓練語言模型
發表于 05-05 12:17





 工商網監
工商網監
評論