") 算力不足和能效過低,有什么方法提高AI芯片的算力呢?
算力不足和能效過低,有什么方法提高AI芯片的算力呢?
隨著ChatGPT強勢來襲,AI人工智能應(yīng)用層出不窮。智能化時代,數(shù)據(jù)量指數(shù)型增長,摩爾定律已經(jīng)不能滿足當前的數(shù)據(jù)處理需求,元器件的物理尺寸已經(jīng)接近極限。人工智能的硬件平臺面臨兩大艱巨挑戰(zhàn):算力不足和能效過低。那么,有什么方法提高芯片的算力呢?
其實關(guān)鍵還是在于系統(tǒng)設(shè)計和芯片加工。系統(tǒng)設(shè)計,重在高性能微架構(gòu)和先進算術(shù)運算,芯片加工則有賴于先進工藝制程和先進封裝制備。今年9月份的時候,EETOP曾從運算機制的角度,探討了計算芯片算力的提升。本期,我們試著從芯片架構(gòu)方面,繼續(xù)探討芯片算力提升的話題。
計算芯片架構(gòu)趨勢:存算一體
現(xiàn)在,無論是CPU還是GPU,采用的都是70年前的馮.諾伊曼體系架構(gòu)。馮諾依曼體系結(jié)構(gòu)是現(xiàn)代計算機的基礎(chǔ)。在馮諾依曼架構(gòu)中,計算和存儲功能分別由中央處理器和存儲器完成。計算機的 CPU 和存儲器是相互獨立發(fā)展的,也就是CPU和內(nèi)存是在不同芯片上的,它們之間的通信要通過總線來進行。數(shù)據(jù)量少的時候沒問題,但一旦數(shù)據(jù)變多,總線本身就會擁擠成為瓶頸。而現(xiàn)在的GPU,并行處理能力越來越強。當數(shù)據(jù)傳輸速度不夠時,就會限制算力的天花板, 嚴重影響目標應(yīng)用程序的功率和性能。
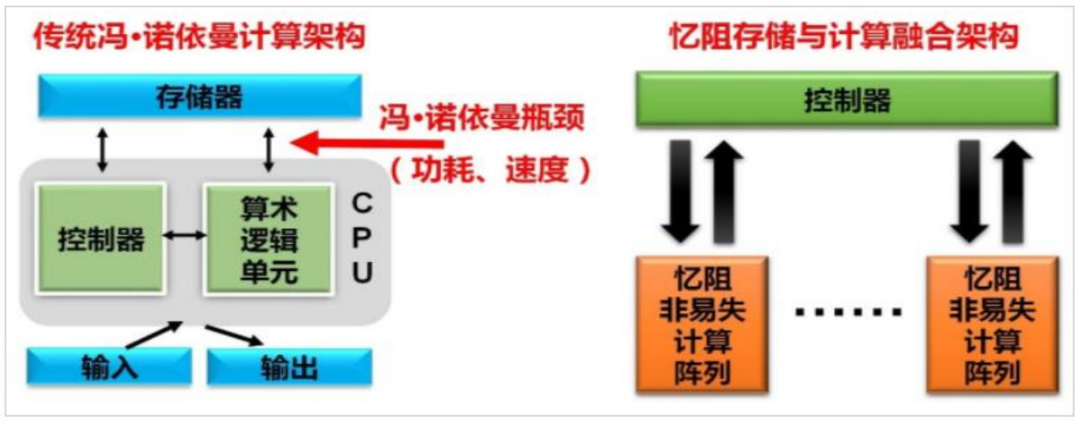
業(yè)界很多也都在研究相關(guān)的解決方案,以實現(xiàn)更為有效的數(shù)據(jù)運算和更大的數(shù)據(jù)吞吐量,其中“存算一體”被認為是未來計算芯片的架構(gòu)趨勢。它是把之前集中存儲在外面的數(shù)據(jù)改為存在GPU的每個計算單元內(nèi),每個計算單元既負責存儲數(shù)據(jù),又負責數(shù)據(jù)計算。
這幾天,清華大學研制出全球首顆全系統(tǒng)集成的、支持高效片上學習(機器學習能在硬件端直接完成)的憶阻器存算一體芯片,可謂刷爆行業(yè)媒體圈。這項最新的研究證明了在全集成憶阻器存算一體系統(tǒng)上實現(xiàn)矩陣向量乘法的可行性。據(jù)了解,清華大學的研究團隊對芯片算法、系統(tǒng)、架構(gòu)、電路與器件進行了全層次協(xié)同優(yōu)化設(shè)計:
器件層面,實現(xiàn)300萬個具有高模擬可編程性的憶阻器與CMOS電路的單片集成;
電路層面,提出電壓模神經(jīng)元電路,支持可變精度計算、激活操作、低功耗模數(shù)轉(zhuǎn)換;
架構(gòu)層面,提出雙向TNSA(transposable neurosynaptic array)架構(gòu),以最小的面積、能耗開銷實現(xiàn)靈活的數(shù)據(jù)流重構(gòu);
系統(tǒng)層面,48個CIM核心支持多種權(quán)重映射方案,提高推理任務(wù)并行度;算法層面,利用多種硬件-算法協(xié)同優(yōu)化方案,降低硬件非理想特性對準確率的影響。
傳統(tǒng)計算系統(tǒng),其計算器件用的是場效應(yīng)晶體管,計算范式是布爾邏輯數(shù)字計算,架構(gòu)采用的是存算分離;而存算一體計算系統(tǒng)的計算器件是憶阻器,計算范式用的是物理定律模擬計算,架構(gòu)是存算一體。存算一體架構(gòu)徹底消除了數(shù)據(jù)在邏輯處理器與存儲芯片之間的搬遷問題,減少能量消耗及延遲。據(jù)公開資料顯示,相同任務(wù)下,該芯片實現(xiàn)片上學習的能耗僅為先進工藝下專用集成電路(ASIC)系統(tǒng)的1/35,同時有望實現(xiàn)75倍的能效提升。
摩爾定律很好的歸納了信息技術(shù)進步的速度,但隨著半導(dǎo)體芯片技術(shù)的快速發(fā)展,摩爾定律已經(jīng)不太適用于現(xiàn)在的半導(dǎo)體芯片發(fā)展規(guī)律了。馮諾依曼架構(gòu)遇到了瓶頸,這時便需要憶阻器的魔力,來實現(xiàn)存算一體,打破傳統(tǒng)的馮諾依曼架構(gòu),開拓新的存儲器道路。談到這里,我們就必須來認識認識憶阻器這個非線性電路元件了。
憶阻器的發(fā)展
憶阻器英文名為memristor,也被稱為阻變存儲器(RRAM),用符號M表示,與電阻R,電容C,電感L構(gòu)成四種基本無源電路器件。它是連接磁通量與電荷之間關(guān)系的紐帶,同時具備電阻和存儲的性能,是一種新一代高速存儲單元。其功耗,讀寫速度都要比傳統(tǒng)的隨機存儲器優(yōu)越,是硬件實現(xiàn)人工神經(jīng)網(wǎng)絡(luò)突觸的最好方式,主要應(yīng)用于非易失存儲、邏輯運算以及類腦神經(jīng)形態(tài)計算。
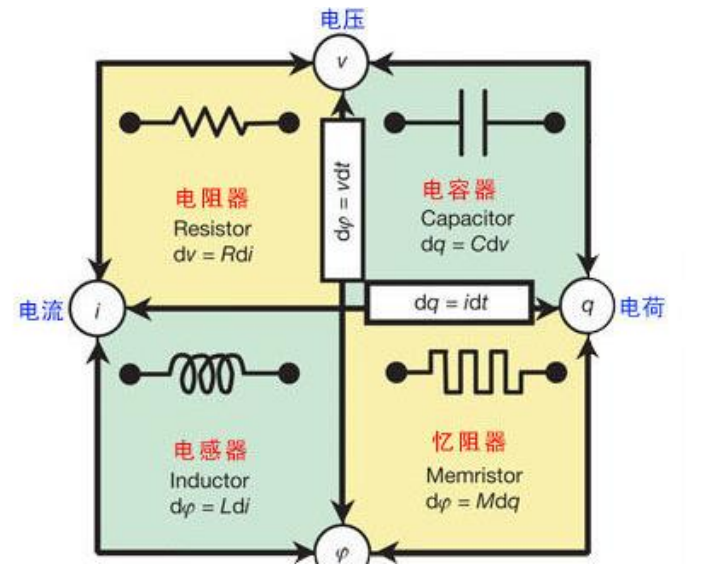
憶阻器全稱記憶電阻,是一種具有電荷記憶功能的非線性電阻,于1971年,由加州大學伯克利分校的華裔科學家蔡少棠教授提出。蔡教授從電路完整性角度出發(fā),從數(shù)學上推導(dǎo)出憶阻器的概念。不過,由于缺乏實驗的支撐,而且傳統(tǒng)存儲器在工藝上和摩爾定律契合的很好,一直在刷新著自己的存儲極限,所以在那之后的很長一段時間,人們認為沒有必要花費時間和金錢去研究憶阻器。
憶阻器發(fā)展的拐點,發(fā)生在2000年之后。2000-2008年,A Beck等人在Cr摻雜的SrZrO3中觀察到憶阻器滯回曲線,并指出器件具有存儲功能,2006年HP實驗室證明了Crossbar RRAM,并于2008年在《Nature》發(fā)表了“下落不明的憶阻器找到了”的相關(guān)文章,同年,HP公司制備出憶阻器。科學家們開始意識到憶阻器的優(yōu)勢和作用,全世界相關(guān)科學家都紛紛參與到憶阻器的研究中來,憶阻器研究高潮就此到來。
類腦計算及神經(jīng)形態(tài)計算是當今科研熱點之一,憶阻器是神經(jīng)元網(wǎng)絡(luò)的核心器件,它為發(fā)展信息存儲與處理融合的新型計算體系架構(gòu),突破傳統(tǒng)馮·諾伊曼架構(gòu)瓶頸,提供了可行的路線,其性能直接影響神經(jīng)元網(wǎng)絡(luò)的計算能力。
下面為大家分享一段教學視頻,是清華大學高濱教授主講的“憶阻器存算一體芯片與類腦計算”。高濱老師表示,現(xiàn)有計算系統(tǒng)普遍采用存儲和運算分離的架構(gòu),存在存儲墻與功耗墻瓶頸,嚴重制約了系統(tǒng)算力和能效的提升。存算合一的電子突觸就是憶阻器。不過,憶阻器也面臨著嚴峻的挑戰(zhàn)。核心挑戰(zhàn)之一是器件非理想特性,即憶阻器件性能存在離散性和不穩(wěn)定性,嚴重影響計算精度;另一個關(guān)鍵挑戰(zhàn)就是模擬計算的誤差累積。
清華大學高濱教授的教學視頻
高濱教授介紹,解決的辦法就是存算一體芯片的協(xié)同設(shè)計。存算一體芯片急需跨層次的協(xié)同優(yōu)化方案,單一層面的優(yōu)化已經(jīng)難以達到高性能。其實憶阻器研究的每一次推進和成功,都離不開測試設(shè)備提供的數(shù)據(jù)支持。高濱表示:“測試設(shè)備的進步,為憶阻器的研發(fā)做出了重要的貢獻!”
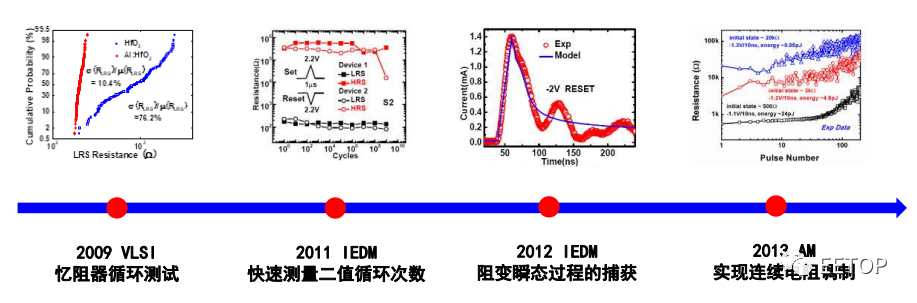
高濱教授關(guān)于憶阻器研究的幾個關(guān)鍵時間點
憶阻器電學測試現(xiàn)狀與展望
存算一體技術(shù)對憶阻器特性要求非常高,測試難度也很大。通常,憶阻器的測試可分為三大類,即:
憶阻器基礎(chǔ)研究測試,包括憶阻器參數(shù)表征、分類及測試流程,以及分析器件在相應(yīng)的交流、直流、脈沖電信號作用下的憶阻特性;
憶阻器性能研究特性,旨在提高憶阻器存儲性能和模擬神經(jīng)元的性能,如功耗、擦寫速度、集成度和可靠性等各方面;
最后是憶阻器集成及應(yīng)用研究測試,憶阻器單元集成結(jié)構(gòu)是實現(xiàn)陣列憶阻器的關(guān)鍵,如1T1R、1TNR等cell及陣列結(jié)構(gòu)的測試。
如果憶阻器被用于神經(jīng)元方面的研究,其性能測試除了擦寫次數(shù)和數(shù)據(jù)保留時間外,還需要進行神經(jīng)突觸阻變動力學測試。
結(jié)束語
在 AI 算力需求暴漲下,存算一體被認為是突破算力瓶頸最有前景的新賽道。目前,國內(nèi)外很多科技企業(yè)及初創(chuàng)公司都在積極開展相關(guān)的研發(fā)。據(jù)相關(guān)預(yù)測數(shù)據(jù)顯示,到 2030 年,基于存算一體技術(shù)的芯片市場規(guī)模有望超過千億人民幣。憶阻器在數(shù)據(jù)存儲、存算一體、類腦計算等領(lǐng)域?qū)l(fā)揮越來越重要的作用。目前,憶阻器已經(jīng)具備在先進CMOS工藝平臺集成的能力。不過,憶阻器依然面臨著嚴峻的挑戰(zhàn),核心挑戰(zhàn)之一是器件非理想特性,即憶阻器件性能存在離散性和不穩(wěn)定性,嚴重影響計算精度;另一個關(guān)鍵挑戰(zhàn)就是模擬計算的誤差累積。
基于憶阻器的存算一體變革性技術(shù)正成為學術(shù)界和產(chǎn)業(yè)界關(guān)注的前沿熱點。未來仍期待在多通道快切換、高時間分辨等方面取得更大進步。期待***走的更遠、更高、更好!
審核編輯:劉清
-
場效應(yīng)晶體管
+關(guān)注
關(guān)注
6文章
394瀏覽量
19924 -
人工智能
+關(guān)注
關(guān)注
1804文章
48750瀏覽量
246702 -
憶阻器
+關(guān)注
關(guān)注
8文章
75瀏覽量
20307 -
CMOS電路
+關(guān)注
關(guān)注
0文章
49瀏覽量
11778 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1588瀏覽量
8811
發(fā)布評論請先 登錄
大算力芯片的生態(tài)突圍與算力革命
DeepSeek推動AI算力需求:800G光模塊的關(guān)鍵作用
GPU算力租用平臺有什么好處
DeepSeek對芯片算力的影響


算智算中心的算力如何衡量?

科技云報到:要算力更要“算利”,“精裝算力”觸發(fā)大模型產(chǎn)業(yè)新變局?
智算中心會取代通用算力中心嗎?
企業(yè)AI算力租賃模式的好處
企業(yè)AI算力租賃是什么
GPU算力開發(fā)平臺是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】--全書概覽
大模型時代的算力需求

算力基礎(chǔ)設(shè)施的風險與挑戰(zhàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論