") 低功耗下,高能效AI加速器如何設計?
低功耗下,高能效AI加速器如何設計?
如果在數據中心和邊緣設備中部署上人工智能(AI)加速器,那么它們將能夠快速處理PB級的數據量,還能幫助克服傳統(tǒng)的馮·諾依曼瓶頸。在Chat GPT、高級駕駛輔助系統(tǒng)(ADAS)、攝像頭和傳感器等智能邊緣設備中,我們都能看到AI加速器的身影。
在半導體領域,實現出色的性能功耗比永遠都是首要目標。AI加速器的能效比通用系統(tǒng)的能效通常會高出100倍甚至1000倍,但生成出色AI模型所需的算力資源每3.4個月就會翻一番。AI產生的能耗不容小覷,以GPT3為例,僅訓練這一個深度學習模型所產生的二氧化碳就高達500噸,相當于一輛普通燃油車行駛100多萬英里。
降低能耗不僅能夠盡量減少對環(huán)境的影響,還能降低運營成本,并在有限的功耗預算內盡可能地提高性能,緩解熱挑戰(zhàn)。
本文將進一步討論開發(fā)者們如何利用端到端功耗分析解決方案,打造新一代更高效節(jié)能的AI加速器。
為十億門級以上設計優(yōu)化功耗
AI加速器的端到端節(jié)能方法必須從設計流程的初始階段開始,涵蓋架構和微架構層面,并一直延續(xù)到簽核階段。因此,AI芯片開發(fā)者需要利用架構探索平臺,對具體訓練或推理應用的功耗、性能和面積(PPA)進行權衡分析和評估,并主動識別后續(xù)分析的關鍵矢量。
由于AI硬件通常包括多個由數千個處理單元組成的大型陣列,因此十億門級以上設計需要進行多域軟硬件功耗驗證,盡可能降低能耗和漏電。然而,要想分析關鍵功耗模塊和時間窗口,需要先進的硬件加速系統(tǒng),以便運行數十億個循環(huán)并快速精確地實現多次迭代。只有在完成這一步后,寄存器傳輸級(RTL)功耗分析和物理實現工具才能有效地優(yōu)化動態(tài)(晶體管門開關)功耗和靜態(tài)(漏電)功耗。
為了始終提供準確的結果,用于AI芯片設計的RTL功耗分析工具應具備以下功能:
時序驅動型快速綜合:內部功耗計算錯誤通常是基于扇出的快速綜合工具未能根據時序約束正確地確定單元大小。同后續(xù)的布局布線工具相同,RTL功耗分析工具中嵌入的快速綜合功能必須由時序驅動。
物理感知型快速綜合:RTL功耗分析工具應該具備“物理感知”能力,能夠通過完成一次設計單元擺放以及全局布線就可以獲得準確的連線電容值。與基于扇出的方法不同,基于物理感知的電容估算能夠為每條連線提供唯一的準確值。
簽核質量的功耗計算引擎:傳統(tǒng)的RTL功耗分析工具使用word-level邏輯推理進行快速綜合,這種方法只能采用啟發(fā)式算法來計算毛刺功耗,因此并不準確。要準確計算毛刺功耗(可能高達芯片總功耗的40%)并減少高度重復的處理單元,RTL功耗分析工具必須具備簽核質量功耗分析引擎、網表級設計表示并集成時序計算引擎。
在完成RTL功耗分析和優(yōu)化后,便可使用物理實現(綜合和布局布線)工具來進一步優(yōu)化PPA。為確保可靠性、可擴展性以及良好的用戶體驗,這些實現工具應包含統(tǒng)一的集成式數據模型架構、交錯式引擎和統(tǒng)一的命令界面。同樣重要的是,實現工具應能對先進節(jié)點效應和毛刺功耗進行精確建模,從而加速工程變更命令(ECO)和最終設計收斂。
出色的能效與性能
新思科技提供全面的端到端功耗解決方案,幫助AI芯片開發(fā)者以經濟高效的方式達成或超越充滿挑戰(zhàn)性的性能和能效目標,同時縮短產品上市時間。新思科技的Platform Architect用于設計流程的初始階段,能夠為AI芯片開發(fā)者提供SystemC事務級建模(TLM)工具和高效方法,幫助開發(fā)者快速地對復雜的芯片架構進行建模、分析和優(yōu)化。新思科技ZeBu Empower是一款快速的功耗分析工具,用于AI芯片設計流程的下一階段:基于數億個循環(huán)來分析和調試軟件實際工作負載下的能耗。
許多業(yè)內領先的半導體公司借助新思科技ZeBu Empower大幅降低了功耗,其中包括美國硅谷的AI芯片初創(chuàng)公司SiMa.ai,該公司致力于為智能邊緣設計高性能、低能耗的AI芯片。具體而言,該公司的SiMa.ai低功耗MLSoC實現了每瓦特幀率(FPS)提升2.5倍的成果。在2023年硅谷SNUG大會上,SiMa.ai公司的芯片開發(fā)總監(jiān)Sounil Biswas指出,流片后驗證結果表明,新思科技ZeBu Empower給出的數據與電路板的測量結果之間具有出色的相關性。
為了補充ZeBu Empower并助力實現低功耗RTL設計,新思科技提供了PrimePower RTL,這是一款RTL功耗分析與優(yōu)化工具,通過將時序驅動型綜合、物理感知型綜合與集成式計算引擎相結合,可以持續(xù)獲得準確的結果(與布線后實現的結果相比誤差在+/- 15%以內)。新思科技PrimePower RTL還提供分步指導,幫助AI芯片開發(fā)者進一步減少毛刺并降低總功耗。
新思科技的Fusion Compiler是一款綜合的集成式RTL-to-GDSII實現系統(tǒng),可幫助實現進一步的PPA優(yōu)化。在這之后,可以使用新思科技的黃金功耗簽核解決方案PrimePower對AI設計進行分析。新思科技的PrimePower通過了全球多家領先代工廠的認證,3nm工藝能夠在簽核時實現高精度,同SPICE的芯片測量的誤差極小。
為邊緣AI推理設計差異化芯片
AI加速器使許多熱門應用能夠在幾毫秒內快速分析海量信息并準確推斷結果。與此同時,實現出色的性能功耗比依然是芯片開發(fā)者的首要目標。這一點在邊緣領域尤為明顯,在該領域,為了縮小芯片尺寸并盡可能地降低功耗,性能通常會受到限制。
然而,這些限制也為半導體公司創(chuàng)造了新的機遇,讓半導體公司可以通過精確校準PPA來滿足低延遲、高帶寬應用的特定要求,從而設計出差異化芯片。例如,自主導航應用要求計算響應延遲時間限制在20μs以內,而語音和視頻助手則要求能夠在10μs之內理解語音關鍵詞,并在幾百毫秒內理解手勢含義。要想成功實現PPA權衡,芯片開發(fā)者應該采用整體性方法,利用端到端解決方案,從早期架構探索到最后的黃金功耗簽核,持續(xù)優(yōu)化功耗。
審核編輯:劉清
-
加速器
+關注
關注
2文章
825瀏覽量
38996 -
晶體管
+關注
關注
77文章
9995瀏覽量
141023 -
人工智能
+關注
關注
1805文章
48851瀏覽量
247595 -
RTL
+關注
關注
1文章
389瀏覽量
60828 -
AI芯片
+關注
關注
17文章
1973瀏覽量
35753
原文標題:邊緣端也要跑大模型:低功耗下,高能效AI加速器如何設計?
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
粒子加速器?——?科技前沿的核心裝置

Analog Devices / Maxim Integrated MAX78002人工智能微控制器數據手冊
能效比達2TOPS/W!解密邊緣AI芯片低功耗設計之法
MAX78000采用超低功耗卷積神經網絡加速度計的人工智能微控制器技術手冊
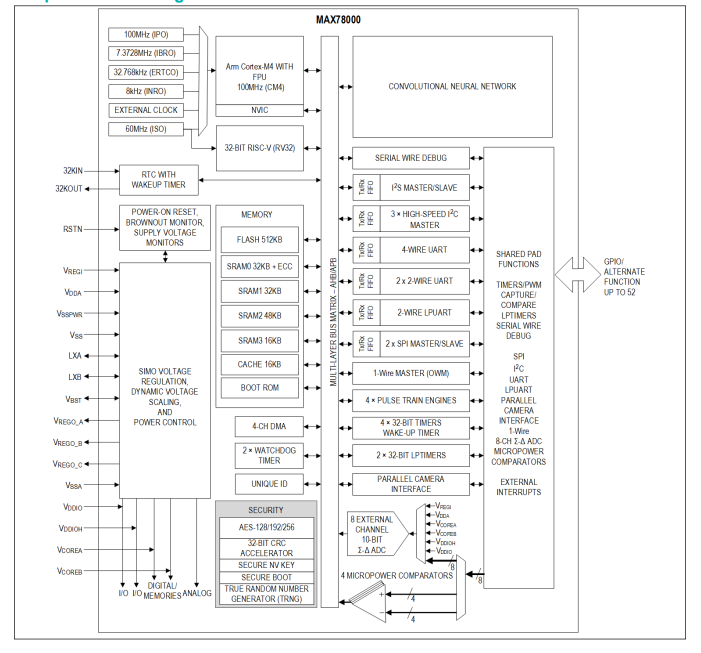
MAX78002帶有低功耗卷積神經網絡加速器的人工智能微控制器技術手冊
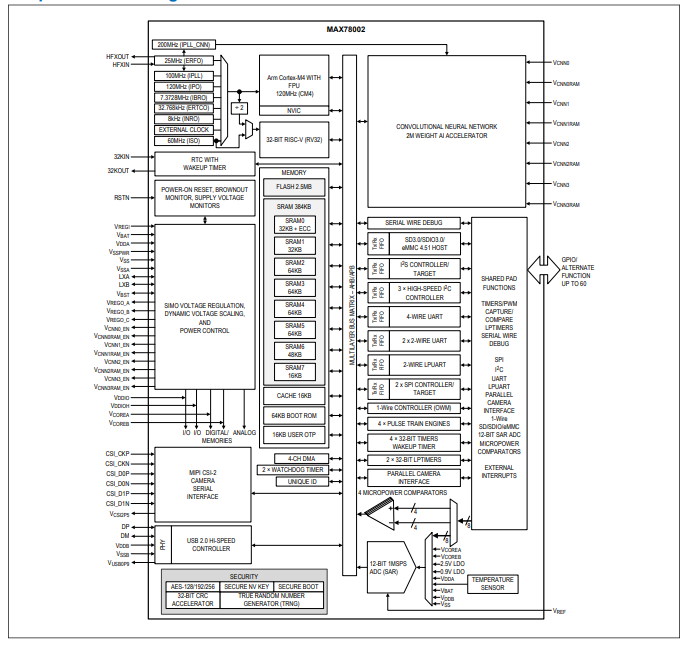
嵌入式AI加速器DRP-AI 詳細介紹
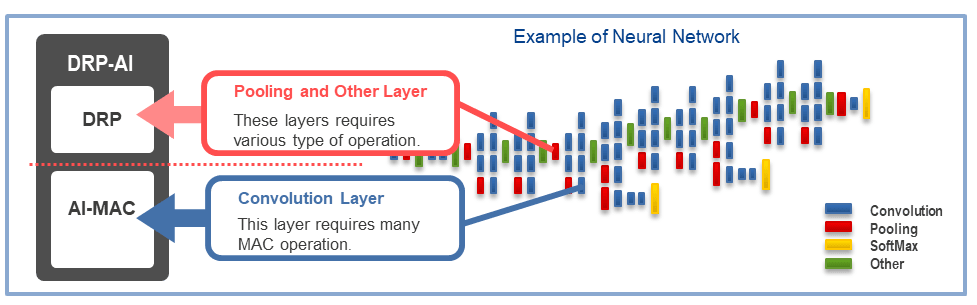
Arm 推出 Armv9 邊緣 AI 計算平臺,以超高能效與先進 AI 能力賦能物聯網革新
當我問DeepSeek AI爆發(fā)時代的FPGA是否重要?答案是......
ADI 新型AI微控制器 # MAX78000 數據手冊和芯片介紹






 工商網監(jiān)
工商網監(jiān)
評論