 NNI:自動幫你做機器學習調參的神器
NNI:自動幫你做機器學習調參的神器
NNI 自動機器學習調參,是微軟開源的又一個神器,它能幫助你找到最好的神經網絡架構或超參數,支持 各種訓練環境 。
它常用的使用場景如下:
- 想要在自己的代碼、模型中試驗 不同的機器學習算法 。
- 想要在不同的環境中加速運行機器學習。
- 想要更容易實現或試驗新的機器學習算法的研究員或數據科學家,包括:超參調優算法,神經網絡搜索算法以及模型壓縮算法。
它支持的框架有:
- PyTorch
- Keras
- TensorFlow
- MXNet
- Caffe2
- Scikit-learn
- XGBoost
- LightGBM
基本上市面上所有的深度學習和機器學習的框架它都支持。
下面就來看看怎么使用這個工具。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
**(可選1) **如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
**(可選2) **此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請選擇以下任一種方式輸入命令安裝依賴 :
- Windows 環境 打開 Cmd (開始-運行-CMD)。
- MacOS 環境 打開 Terminal (command+空格輸入Terminal)。
- 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install nni
2.運行示例
讓我們運行一個示例來驗證是否安裝成功,首先克隆項目:
git clone -b v2.6 https://github.com/Microsoft/nni.git
如果你無法成功克隆項目,請在Python實用寶典后臺回復 **nni **下載項目。
運行 MNIST-PYTORCH 示例, Linux/macOS :
nnictl create --config nni/examples/trials/mnist-pytorch/config.yml
Windows :
nnictl create --config nniexamplestrialsmnist-pytorchconfig_windows.yml
出現這樣的界面就說明安裝成功,示例運行正常:

訪問 http://127.0.0.1:8080 可以配置運行時間、實驗次數等:
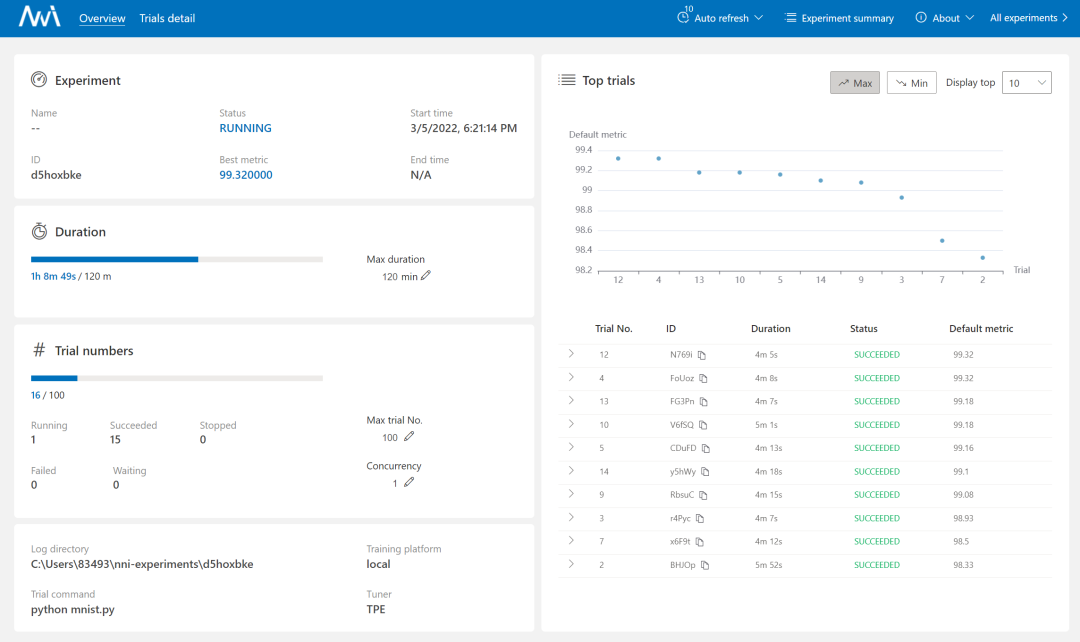
3.模型自動調參配置
那么如何讓 NNI 和我們自己的模型適配呢?
觀察 config_windows.yaml 會發現:
searchSpaceFile: search_space.json
trialCommand: python mnist.py
trialGpuNumber: 0
trialConcurrency: 1
tuner:
name: TPE
classArgs:
optimize_mode: maximize
trainingService:
platform: local
我們先看看 trialCommand, 這很明顯是訓練使用的命令,訓練代碼位于 mnist.py,其中有部分代碼如下:
def get_params():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument("--data_dir", type=str,
default='./data', help="data directory")
parser.add_argument('--batch_size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument("--batch_num", type=int, default=None)
parser.add_argument("--hidden_size", type=int, default=512, metavar='N',
help='hidden layer size (default: 512)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--no_cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--log_interval', type=int, default=1000, metavar='N',
help='how many batches to wait before logging training status')
args, _ = parser.parse_known_args()
return args
如上所示,這個模型里提供了 10 個參數選擇。也就是說 NNI 可以幫我們自動測試這10個參數。
那么這些參數在哪里設定?答案是在 searchSpaceFile 中,對應的值也就是 search_space.json:
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}
這里有4個選項,NNI 是怎么組合這些參數的呢?這是 tuner 參數干的事,為了讓機器學習和深度學習模型適應不同的任務和問題,我們需要進行超參數調優,而自動化調優依賴于優秀的調優算法。NNI 內置了先進的調優算法,并且提供了易于使用的 API。
在 NNI 中,Tuner 向 trial 發送超參數,接收運行結果從而評估這組超參的性能,然后將下一組超參發送給新的 trial。
下表簡要介紹了 NNI 內置的調優算法。
| Tuner | 算法簡介 |
|---|---|
| TPE | Tree-structured Parzen Estimator (TPE) 是一種基于序列模型的優化方法。SMBO方法根據歷史數據來順序地構造模型,從而預估超參性能,并基于此模型來選擇新的超參。 |
| Random Search (隨機搜索) | 隨機搜索在超算優化中表現出了令人意外的性能。如果沒有對超參分布的先驗知識,我們推薦使用隨機搜索作為基線方法。 |
| Anneal (退火) | 樸素退火算法首先基于先驗進行采樣,然后逐漸逼近實際性能較好的采樣點。該算法是隨即搜索的變體,利用了反應曲面的平滑性。該實現中退火率不是自適應的。 |
| Naive Evolution(樸素進化) | 樸素進化算法來自于 Large-Scale Evolution of Image Classifiers。它基于搜索空間隨機生成一個種群,在每一代中選擇較好的結果,并對其下一代進行變異。樸素進化算法需要很多 Trial 才能取得最優效果,但它也非常簡單,易于擴展。 |
| SMAC | SMAC 是基于序列模型的優化方法 (SMBO)。它利用使用過的最突出的模型(高斯隨機過程模型),并將隨機森林引入到SMBO中,來處理分類參數。NNI 的 SMAC tuner 封裝了 GitHub 上的 SMAC3。參考論文注意:SMAC 算法需要使用pip install nni[SMAC]安裝依賴,暫不支持 Windows 操作系統。 |
| Batch(批處理) | 批處理允許用戶直接提供若干組配置,為每種配置運行一個 trial。 |
| Grid Search(網格遍歷) | 網格遍歷會窮舉搜索空間中的所有超參組合。 |
| Hyperband | Hyperband 試圖用有限的資源探索盡可能多的超參組合。該算法的思路是,首先生成大量超參配置,將每組超參運行較短的一段時間,隨后拋棄其中效果較差的一半,讓較好的超參繼續運行,如此重復多輪。參考論文 |
| Metis | 大多數調參工具僅僅預測最優配置,而 Metis 的優勢在于它有兩個輸出:(a) 最優配置的當前預測結果, 以及 (b) 下一次 trial 的建議。大多數工具假設訓練集沒有噪聲數據,但 Metis 會知道是否需要對某個超參重新采樣。參考論文 |
| BOHB | BOHB 是 Hyperband 算法的后續工作。Hyperband 在生成新的配置時,沒有利用已有的 trial 結果,而本算法利用了 trial 結果。BOHB 中,HB 表示 Hyperband,BO 表示貝葉斯優化(Byesian Optimization)。BOHB 會建立多個 TPE 模型,從而利用已完成的 Trial 生成新的配置。參考論文 |
| GP (高斯過程) | GP Tuner 是基于序列模型的優化方法 (SMBO),使用高斯過程進行 surrogate。參考論文 |
| PBT | PBT Tuner 是一種簡單的異步優化算法,在固定的計算資源下,它能有效的聯合優化一組模型及其超參來最優化性能。參考論文 |
| DNGO | DNGO 是基于序列模型的優化方法 (SMBO),該算法使用神經網絡(而不是高斯過程)去建模貝葉斯優化中所需要的函數分布。 |
可以看到本示例中,選擇的是TPE tuner.
其他的參數比如 trialGpuNumber,指的是使用的gpu數量,trialConcurrency 指的是并發數。trainingService 中 platform 為 local,指的是本地訓練。
當然,還有許多參數可以選,比如:
trialConcurrency: 2 # 同時運行 2 個 trial
maxTrialNumber: 10 # 最多生成 10 個 trial
maxExperimentDuration: 1h # 1 小時后停止生成 trial
不過這些參數在調優開始時的web頁面上是可以進行調整的。
所以其實NNI干的事情就很清楚了,也很簡單。你只需要在你的模型訓練文件中增加你想要調優的參數作為輸入,就能使用NNI內置的調優算法對不同的參數進行調優,而且允許從頁面UI上觀察調優的整個過程,相對而言還是很方便的。
不過,NNI可能不太適用一些數據量極大或模型比較復雜的情況。比如基于DDP開發的模型,在NNI中可能無法實現大型的分布式計算。
-
微軟
+關注
關注
4文章
6676瀏覽量
105447 -
神經網絡
+關注
關注
42文章
4811瀏覽量
102998 -
NNI
+關注
關注
0文章
3瀏覽量
6411 -
機器學習
+關注
關注
66文章
8496瀏覽量
134207
發布評論請先 登錄
阿里巴巴大數據產品最新特性介紹--機器學習PAI
PID調參的相關資料分享
針對PID調參進行詳細的講解
NNI
深度學習和機器學習深度的不同之處 淺談深度學習的訓練和調參
深度學習的調參經驗
結機器學習的模型評估與調參大法 想學的快上車







 工商網監
工商網監
評論