 基于高度感知的鳥瞰圖分割和神經地圖的重定位
基于高度感知的鳥瞰圖分割和神經地圖的重定位
ICCV2023 SOTA U-BEV:基于高度感知的鳥瞰圖分割和神經地圖的重定位
論文標題:U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
論文鏈接:https://arxiv.org/abs/2310.13766
1. 本文概覽
高效的重定位對于GPS信號不佳或基于傳感器的定位失敗的智能車輛至關重要。最近,Bird’s-Eye-View (BEV) 分割的進展使得能夠準確地估計局部場景的外觀,從而有利于車輛的重定位。然而,BEV方法的一個缺點是利用幾何約束需要大量的計算。本文提出了U-BEV,一種受U-Net啟發的架構,通過在拉平BEV特征之前對多個高度層進行推理,擴展了當前的最先進水平。我們證明了這種擴展可以提高U-BEV的性能高達4.11%的IoU。此外,我們將編碼的神經BEV與可微分的模板匹配器相結合,在神經SD地圖數據集上執行重定位。所提出的模型可以完全端到端地進行訓練,并在nuScenes數據集上優于具有相似計算復雜度的基于Transformer的BEV方法1.7到2.8%的mIoU,以及基于BEV的重定位超過26%的召回率。
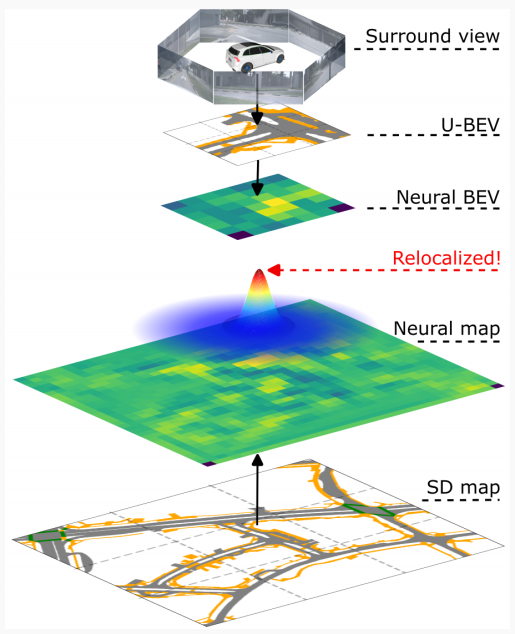
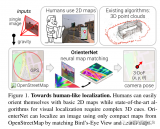
圖1:,U-BEV 提出了一種新的環境圖像 BEV 表示方法,在 SD 地圖數據中實現了高效的神經重定位。
2. 方法詳解
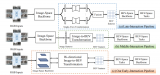
本方案的完整算法是在SD地圖中定位一組環視圖像。它從環視圖像生成本地BEV表示,并從給定粗略3D位置先驗的SD地圖tile中生成神經地圖編碼(例如來自航海設備的嘈雜GPS信號和指南針)。深度模板匹配器然后在神經BEV上滑動全局神經地圖,產生相似度圖。最后,定位通過返回相似度圖的Soft-Argmax來完成。我們的方法概述如圖2所示。
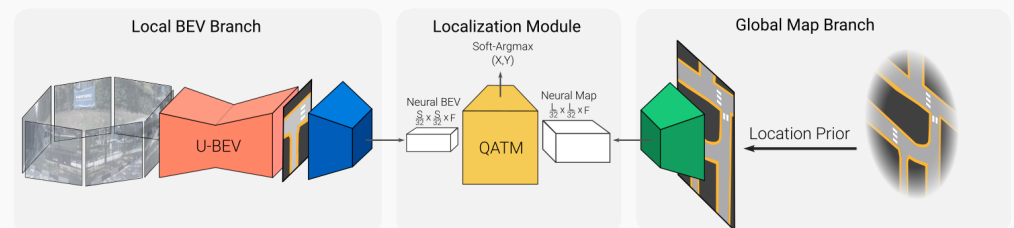
圖2:U-BEV神經重定位模型概述。U-BEV從一組環視攝像頭預測局部BEV(左)。地圖編碼器從根據位置先驗裁剪的全局SD地圖中提取特征(右)以構建神經地圖表示。QATM匹配模塊(中心)計算最佳匹配位置。
A. Bird眼視角重建
我們提出了一種新穎的輕量級且準確的BEV架構U-BEV,用于從一組環視圖像重建汽車周圍環境。我們的模型受計算機視覺分割任務中廣泛使用的架構U-Net的啟發。概述如圖4所示。
給定一組6張圖像及其內參和外參,我們預測一個BEV ,其中S是BEV的像素大小,N是地圖中可用標簽的數量。我們遵循nuScenes數據集中的約定,使用后軸心中心作為我們的原點。
特征提取:我們使用輕量級的預訓練EfficientNet backbone從所有6張圖像中提取不同分辨率的特征,這在較小的模型中是常見的方法。具體來說,我們以步長2、4、8、16提取特征,并為計算原因刪除最后一個步長。提取的特征在整個架構中用作跳過連接。(圖4中的藍色框)
高度預測: U-BEV的一個關鍵貢獻是從地面估計高度以在3D空間進行推理。我們利用提取的特征和輕量級解碼器對每個像素執行此像素式操作(圖4中的橙色部分)。與BEV文獻中廣泛預測隱式或顯式深度的做法相反,我們認為從地面到觀察到的每個像素的高度是一種更有效的表示。這主要基于以下觀察:對于駕駛應用程序,需要在x、y地面平面上進行高分辨率,而垂直軸可以更粗略地離散化。此外,如圖3所示,深度通常分布在更長的范圍上,例如[0-50]米,這需要大量的離散間隔。可以有意義地將高度離散化在較低范圍內,例如[0-5]米來解釋周圍環境。較少的bin數量對模型有直接影響:它顯著降低了投影的復雜性(在我們的例子中20),并降低了內存占用。最后,最相關的信息,即路面、標記、路緣等集中在該范圍的下部。
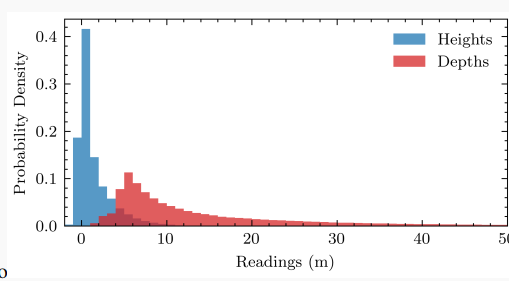
圖3:當車輛坐標系中點離地面的高度和作為點離攝像頭的距離時,重新投影到圖像平面上的激光雷達讀數分布,來自nuScenes。
因此,我們將高度預測任務設置為分類問題,僅使用作為bin。更具體地說,我們的解碼器輸出預測,其中 是輸入圖像的形狀。通過以下方式可以獲得特定像素在索引處的實際高度預測:
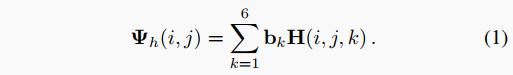
我們利用這個離散化的高度預測根據在每個bin中的可能性對每個特征進行加權。
投影:我們將更深層的特征投影到更粗糙的BEV中,將更早期的高分辨率特征投影到更高分辨率的BEV中。這允許我們以經典的編碼器-解碼器方式上采樣BEV,其中更詳細的BEV充當跳過連接(圖4中的綠色部分)。
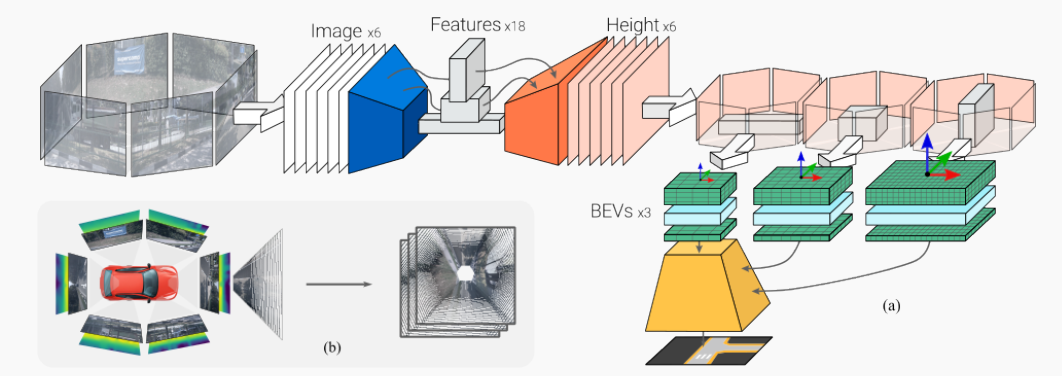
圖4:U-BEV模型架構。(a)預訓練的backbone(藍色)從汽車周圍的所有6個攝像頭中提取特征。第一個解碼器(橙色)預測每個輸入圖像上的每個像素的高度。這個高度用于將每個攝像頭的特征投影到3D空間的單個BEV中(綠色)。更深層的特征被投影到較低分辨率的BEV中,然后以編碼器-解碼器方式上采樣(黃色),具有跳躍連接。(b)說明從環視圖像和高度到不同BEV層的投影操作。
我們應用經修改的逆投影映射(IPM)將圖像坐標中的特征展開到BEV坐標中(參見圖4 b)。要從像素投影每個特征,我們使用已知的外在投影矩陣和相機的內在參數。要在高度處投影,我們利用矩陣形式的翻譯變換將參考系統提升到所需高度,并在處執行標準IPM。
IPM公式將這些變量相關聯為:
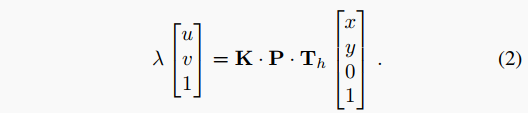
這種形式方便地允許刪除矩陣的第三列,這使我們能夠對其進行求逆并求出。該操作可以在GPU上對所有特征并行化,并在所有高度上執行,從而產生一個占用體積。
BEV解碼:最后,我們用兩個卷積層擠壓高度維度的每個BEV。通過保持分辨率和通道的比率不變,我們可以將它們與跳過連接一起插入經典的解碼器樣式,產生最終的BEV輸出(圖4中的黃色部分)。
B. 地圖編碼
地圖以布爾型通道離散化表面柵格化的形式輸入到我們的系統中,其中是類的數量,即每個語義類被分配一個獨立的通道。在多邊形表示的情況下,如自動駕駛SD地圖中的常見情況,我們通過將每個類的多邊形柵格化到通道來預處理地圖。
C. 定位
為了進行定位,我們利用本地BEV 和給定粗略位置先驗裁剪的全局地圖平鋪。
給定擬議的U-BEV模型重建的BEV與地圖平鋪在比例上相符合,定位通過模板匹配來實現。為了補償本地BEV重建的不完美,定位模塊從地圖平鋪和本地BEV中提取神經表示,并在地圖平鋪上構建概率圖。
在特征空間匹配神經BEV預測和神經地圖增強了定位模塊對本地BEV中的錯誤和不完美的魯棒性,這可能是由于遮擋或者在定位場景中感知降級(例如,照明不足或惡劣天氣)引起的,以犧牲分辨率為代價。
我們應用二維softmax $ ilde{M} = ext{softmax}{2D}(M{prob}) xy$方向上執行soft-argmax提取預測,其中
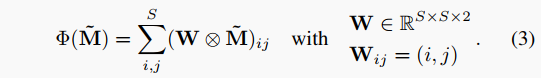
3. 實驗結果
本文的實驗結果主要涉及BEV分割和重定位的性能比較。在BEV方面,作者使用了U-BEV和CVT兩種方法進行比較,通過計算IoU來評估兩種方法在不同類別的地面、路面和十字路口上的表現。實驗結果顯示,U-BEV在所有類別上的IoU表現均優于CVT,并且在路面和人行道分割上的表現提升尤為明顯。此外,U-BEV相較于CVT具有更低的計算復雜度,可實現相當的性能提升。在重定位方面,作者通過比較不同方法在不同距離的召回準確率(1m, 2m, 5m, 10m)上的表現,發現U-BEV相較于其他基于BEV的方法和當代基于BEV的重定位方法,在10m上的召回準確率提高了26.4%。總的來說,實驗結果證明了U-BEV方法在BEV分割和重定位方面取得了更好的性能表現。

表1:以1米,2米,5米,10米處的召回準確率為指標的定位結果。
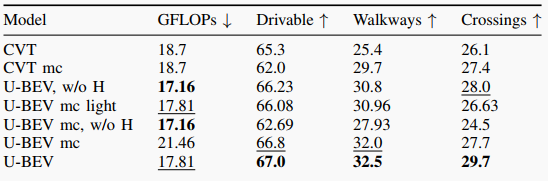
表2: U-BEV和CVT的BEV性能IoU。mc表示多類模型,w/o H表示不帶高度的模型。
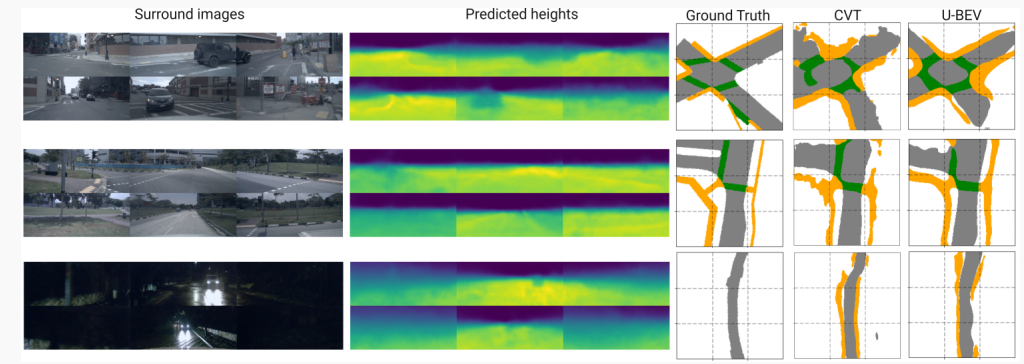
圖5:U-BEV的輸入和輸出示例,包括環視圖像,預測高度和預測和真值BEV。與CVT相比,U-BEV更準確地重建了可駕駛表面和人行道。
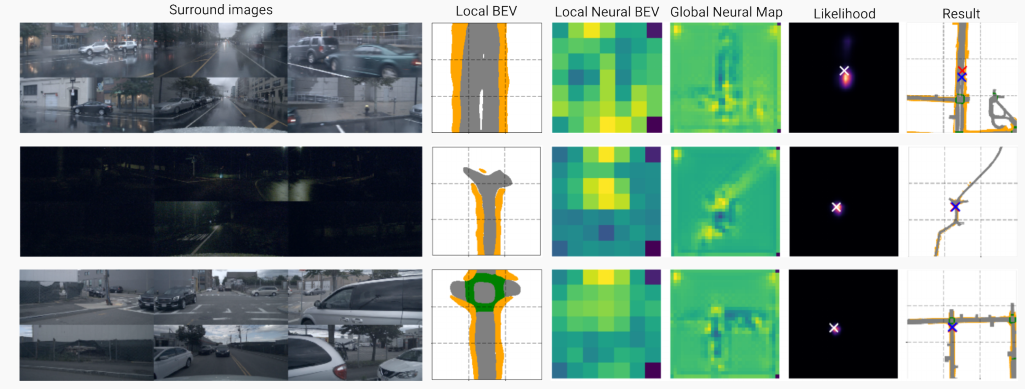
圖6 定位過程的輸入和輸出示例,包括環繞圖像、局部BEV、局部BEV和地圖塊的神經編碼、預測的可能性以及結果的可視化。在可視化中,藍十字為地面真實姿態,紅十字為預測姿態。
4. 結論
本文提出了一種新的U-Net啟發的BEV架構“U-BEV”,它利用多個高度層的中間分割。該架構在分割性能上優于現有的基于Transformer的BEV架構1.7到2.8%的IoU。此外,我們提出了一種新穎的重定位方法,利用擬議的U-BEV與神經編碼的SD地圖進行匹配。重定位擴展顯著優于相關方法,在10米內的召回率提高了26.4%以上。值得注意的是,僅需要地圖數據的幾個類別,特別是道路表面,為在無特征環境中重定位鋪平了道路。
-
傳感器
+關注
關注
2564文章
52668瀏覽量
764320 -
模板
+關注
關注
0文章
109瀏覽量
20831 -
模型
+關注
關注
1文章
3499瀏覽量
50078
原文標題:ICCV2023 SOTA U-BEV:基于高度感知的鳥瞰圖分割和神經地圖的重定位
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
《炬豐科技-半導體工藝》在硅上生長的 InGaN 基激光二極管的腔鏡的晶圓制造
什么是高精度地圖
基于改進深度信息的手勢分割與定位
Apollo定位、感知、規劃模塊的基礎-高精地圖
特斯拉完全自動駕駛套件車輛新增“向量空間鳥瞰圖“功能
利用激光雷達探測車輛路徑上的障礙物
介紹一種對標Tesla Occupancy的開源3D語義場景補全?法
基于神經匹配的二維地圖視覺定位
基于純視覺的感知方法
高德地圖公布“奇境”引擎,應用神經渲染等前沿技術打造“時空地圖”

智行者科技發布基于***的“重感知、輕地圖”智駕解決方案
基于毫米波雷達和多視角相機鳥瞰圖融合的3D感知方法





 工商網監
工商網監
評論