 北大&華為提出:多模態基礎大模型的高效微調
北大&華為提出:多模態基礎大模型的高效微調
很榮幸我們近期的工作Parameter-efficient Tuning of Large-scaleMultimodal Foundation Model被NeurIPS2023錄用!

https://arxiv.org/abs/2305.08381
這是我們第一篇拓展至多模態領域的高效微調的工作,在該工作中我們首次采用模式逼近(mode apprximation)的方法來進行大模型的輕量化高效微調,僅需訓練預訓練大模型0.04%的參數。同時我們設計了兩個啟發性模塊來增強高效微調時極低參數條件下的模態對齊。實驗上,我們在六大跨模態基準測試集上進行全面評估顯示,我們的方法不僅超越當前的sota, 還在一些任務上優于全量微調方法。
論文的相關代碼也會開源在這個GitHub項目:
github.com/WillDreamer/Aurora
大模型的高效微調是一個非常新且日漸繁榮的task,歡迎小伙伴們一起學習交流~
一、背景
深度學習的大模型時代已經來臨,越來越多的大規模預訓練模型在文本、視覺和多模態領域展示出杰出的生成和推理能力。然而大模型巨大的參數量有兩個明顯缺點。第一,它帶來巨大的計算和物理存儲成本,使預訓練和遷移變得非常昂貴。第二,微調限制了預訓練知識在小規模數據量的下游任務中的應用效果。這兩點阻礙了大模型從特定數據集擴展到更廣泛場景。
為緩解預訓練大模型的高昂成本,一系列參數高效微調方法相繼提出。其通用范式是凍結大模型的骨干網絡,并引入少量額外參數。最近,一些工作開始關注多模態領域的高效微調任務,例如UniAdapter、VL-Adapter和MAPLE。但是,它們的通用思路是將自然語言處理領域的現有架構用于多模態模型并組合使用,然后直接在單模態和多模態分支的骨干網絡中插入可訓練參數以獲得良好表現。直接、簡單的設計無法將參數高效遷移的精髓融入多模態模型。此外,還有兩個主要挑戰需要面對: (1)如何在極輕量級高效微調框架下進行知識遷移;(2)在極低參數環境下如何提高各模態間的對齊程度。

圖1:與現有主流的高效微調方法的對比
在這篇文章中,我們嘗試解決這兩種挑戰,貢獻可以總結為:
介紹了名為Aurora的多模態基礎大模型高效微調框架,它解決了當前大規模預訓練和微調策略的局限性。
提出了模式近似(mode approximation)方法來生成輕量級可學習參數,并提出了兩個啟發性模塊來更好地增強模態融合。
通過六個跨模態任務和兩個零樣本任務進行實驗驗證,結果顯示Aurora相比其他方法取得了最先進的性能,同時也只使用最少的可學習參數。
二、高效微調的輕量化架構的設計

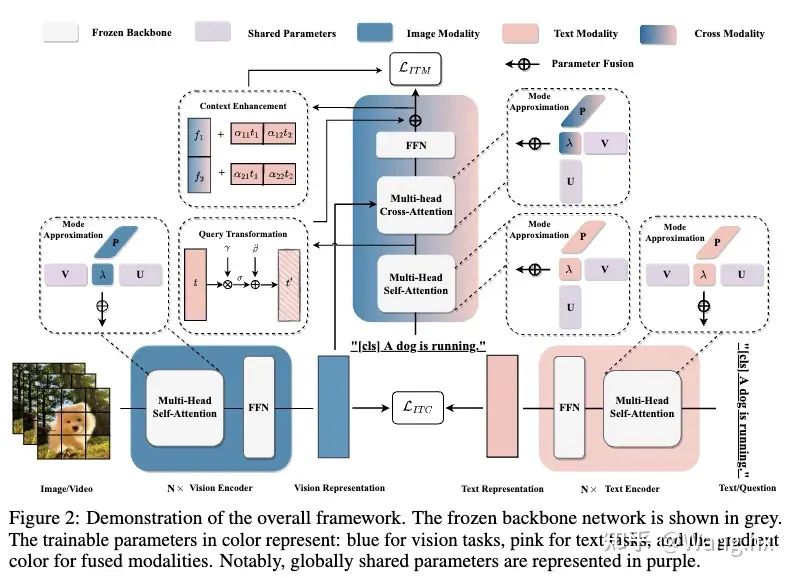
Aurora的整體過程示意圖。
三、高效微調的模態對齊的設計
3.1 Informative Context Enhancement
該模塊的目標是為了實現更好的模態對齊,在交叉注意力模塊后的融合特征中提供提示文本來更好的激活。受“上下文學習”這一領域的進步啟發,我們意識到為提示詞提供示范模板是很重要的。最直觀的方法是對圖像與文本對進行對齊,以獲得更多跨模態上下文信息。但是,即使與相關圖像區域匹配,描述這些區域的文本可能還是有多個選擇。一些文本可能準確概括圖像內容,而另一些可能不行。在沒有事先匹配文本信息的先驗情況下,我們決定引入上下文增強模塊來涵蓋各個方面的可能的文本信息。

四、實驗結果
4.1 實驗設置
數據集與基準比較。我們在六個跨模態任務領域的benchmark上評估了Aurora,這些任務包括圖片文本檢索、問答(QA)、視頻文本檢索和視頻QA。我們將Aurora與兩類方法進行比較:完全微調后的SOTA方法以及Frozen重要部分的LoRA和UniAdapter方法。更多細節請參閱附錄。
實現細節。我們的實現基于Salesforce開源代碼庫。與UniAdapter一致,我們使用BLIP-base作為所有多模態下游任務的視覺語言初始化權重。我們使用PyTorch在8臺NVIDIA V100 GPU(32G)設備上實現所有實驗。我們使用AdamW優化器,設置權重衰減為0.05,學習率通過網格搜索得到為1e-4。需要注意的是,在微調過程中,參數組只更新交叉注意模塊的權重, backbone初始化權重不更新。
4.2 實驗結果
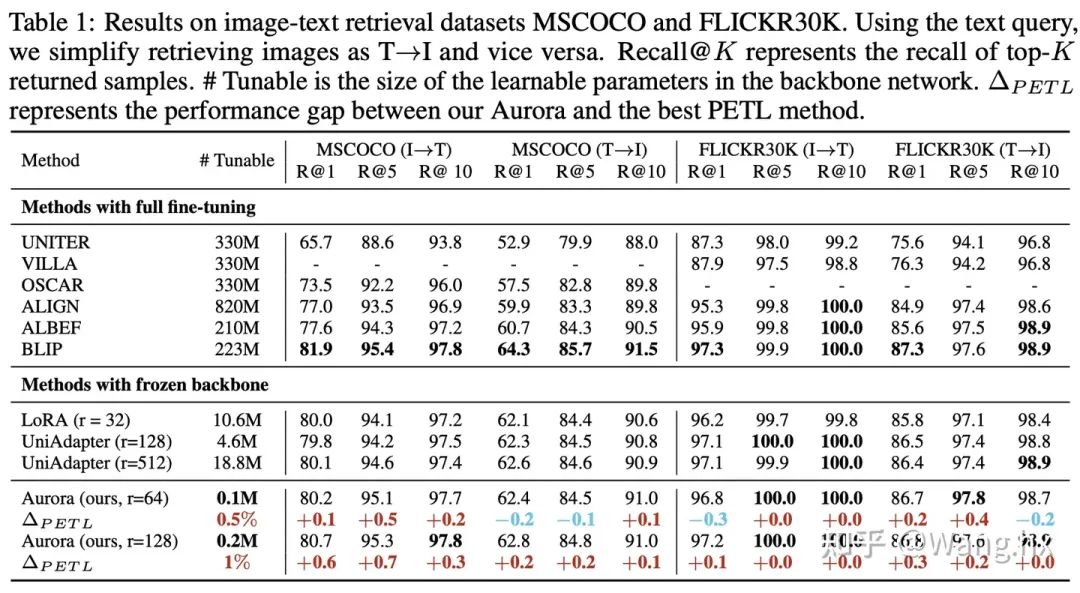
Image-Text Retrieval
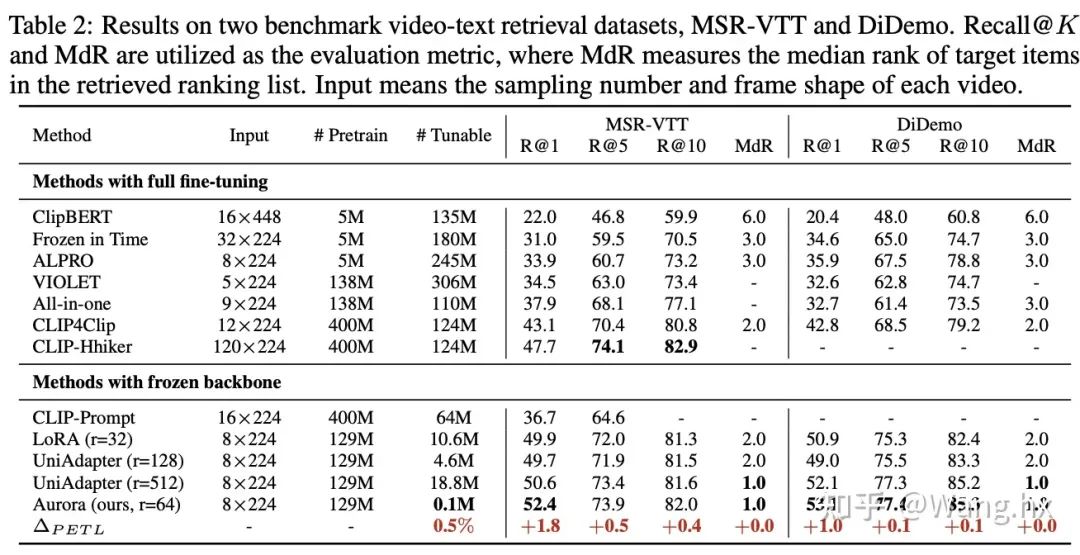
Video-Text Retrieval
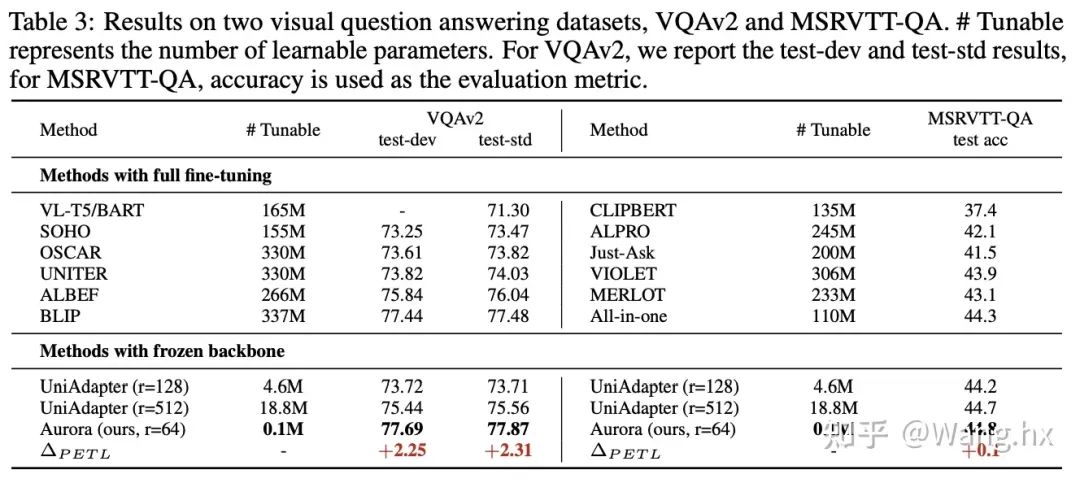
VQA
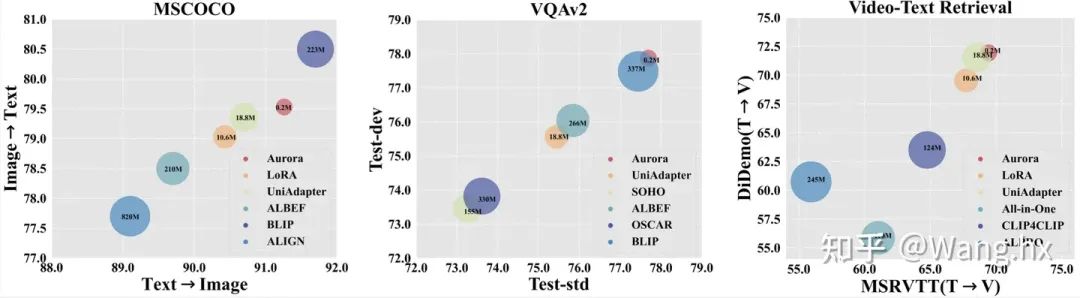
實驗氣泡圖
4.3 消融實驗
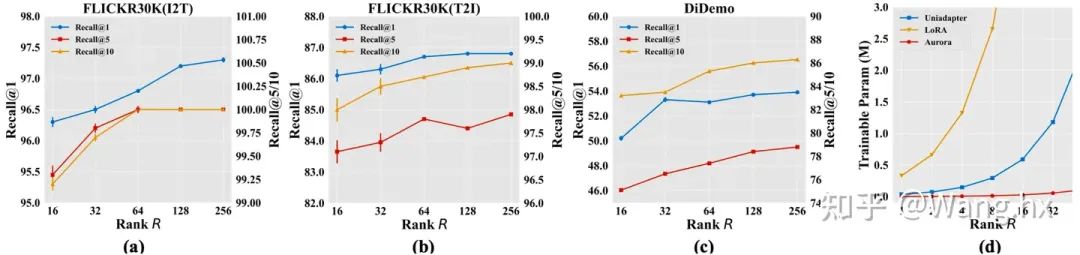
How Rank of CP Decomposition Affects Aurora?
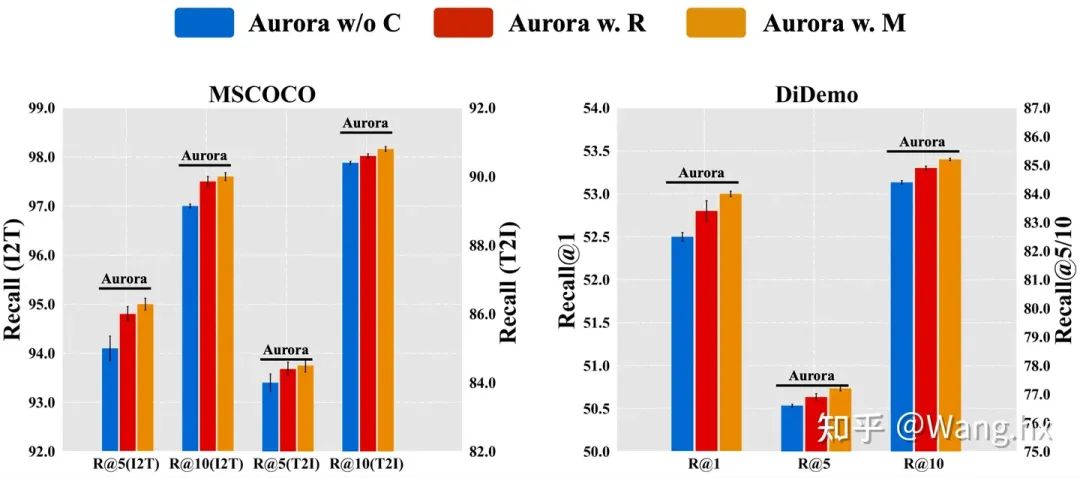
How Does Aurora Benefit from Informative Context Enhancement
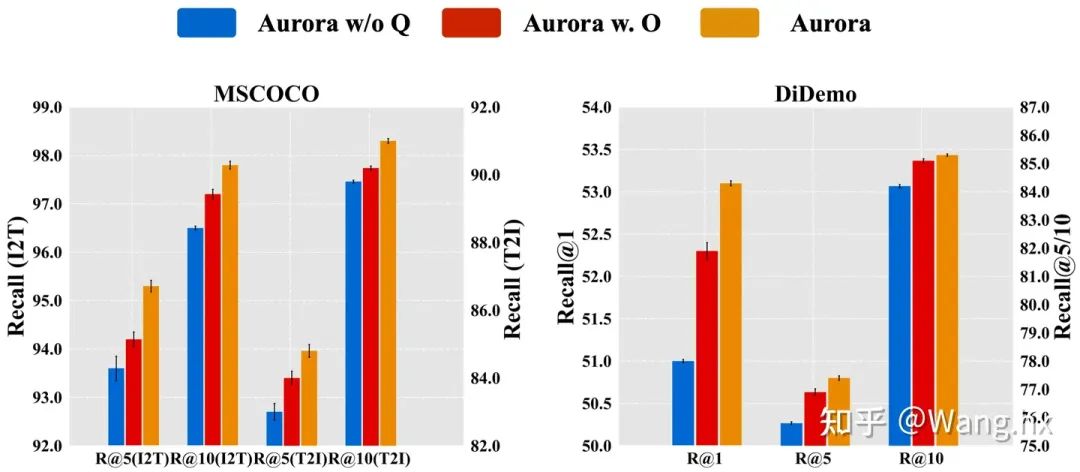
How Does Aurora Benefit from Gated Query Transformation?

How Does Aurora Benefit from Parameter Sharing?
4.4 可視化分析
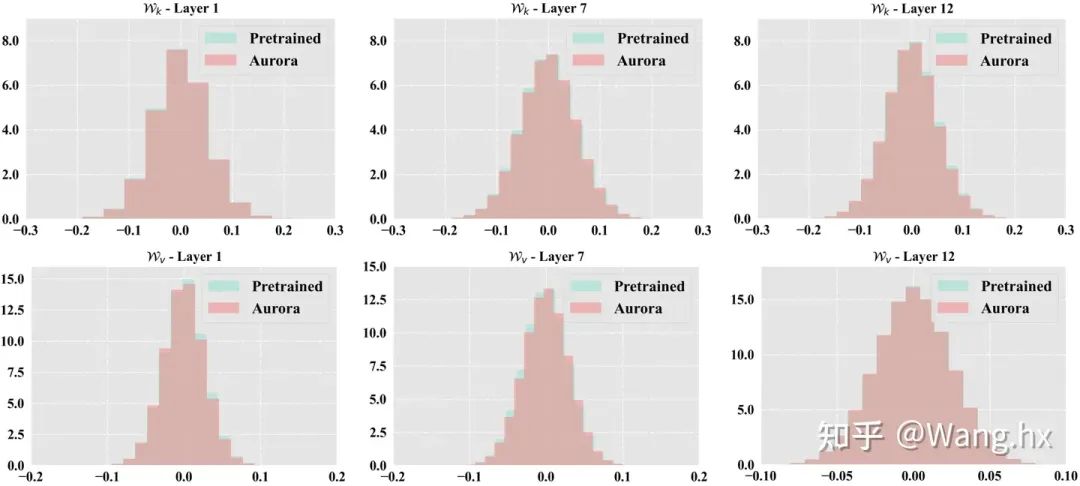
參數分布可視化

Video-Text retrieval cases on MSRVTT

Video Question Answering cases on MSRVTT-QA
-
框架
+關注
關注
0文章
404瀏覽量
17811 -
深度學習
+關注
關注
73文章
5555瀏覽量
122537 -
大模型
+關注
關注
2文章
3046瀏覽量
3862
原文標題:NeurIPS 2023 | 北大&華為提出:多模態基礎大模型的高效微調
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀

單張消費級顯卡微調多模態大模型

更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

中科大&amp;字節提出UniDoc:統一的面向文字場景的多模態大模型
用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單

基于AX650N芯片部署MiniCPM-V 2.0高效端側多模態大模型






 工商網監
工商網監
評論