") 內(nèi)存池主要解決的問題
內(nèi)存池主要解決的問題
內(nèi)存池的定義
1.池化技術(shù)
池 是在計算機技術(shù)中經(jīng)常使用的一種設(shè)計模式,其內(nèi)涵在于:將程序中需要經(jīng)常使用的核心資源
先申請出來,放到一個池內(nèi),由程序自己管理,這樣可以提高資源的使用效率,也可以保證本程
序占有的資源數(shù)量。 經(jīng)常使用的池技術(shù)包括內(nèi)存池、線程池和連接池等,其中尤以內(nèi)存池和線程
池使用最多。
2.內(nèi)存池
內(nèi)存池是指程序預(yù)先從操作系統(tǒng)申請一塊足夠大內(nèi)存,此后,當程序中需要申請內(nèi)存的時候,不是直接 向操作系統(tǒng)申請,而是直接從內(nèi)存池中獲取;同理,當程序釋放內(nèi)存的時候,并不真正將內(nèi)存返回給操作系統(tǒng),而是返回內(nèi)存池。當程序退出( 或者特定時間 ) 時,內(nèi)存池才將之前申請的內(nèi)存真正釋放。
3.內(nèi)存池主要解決的問題
內(nèi)存池主要解決的當然是效率的問題,其次如果作為系統(tǒng)的內(nèi)存分配器的角度,還需要解決一下內(nèi)存碎片的問題。那么什么是內(nèi)存碎片呢?
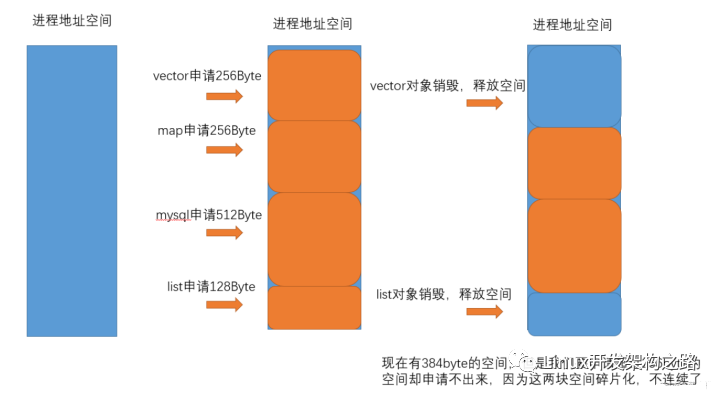
再需要補充說明的是內(nèi)存碎片分為外碎片和內(nèi)碎片,上面我們講的外碎片問題。外部碎片是一些空閑的連續(xù)內(nèi)存區(qū)域太小,這些內(nèi)存空間不連續(xù),以至于合計的內(nèi)存足夠,但是不能滿足一些的內(nèi)存分配申請需求。內(nèi)部碎片是由于一些對齊的需求,導(dǎo)致分配出去的空間中一些內(nèi)存無法被利用。內(nèi)碎片問題,我們后面項目就會看到,那會再進行更準確的理解。
4.malloc
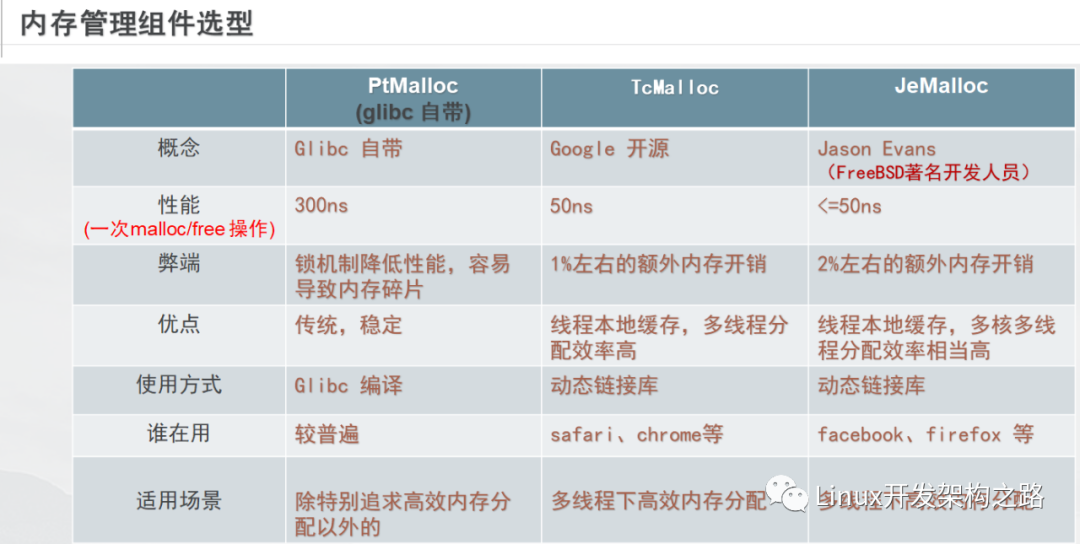
C/C++ 中我們要動態(tài)申請內(nèi)存都是通過 malloc 去申請內(nèi)存,但是我們要知道,實際我們不是直接去堆獲取內(nèi)存的,而malloc 就是一個內(nèi)存池。 malloc() 相當于向操作系統(tǒng) “ 批發(fā) ” 了一塊較大的內(nèi)存空間,然后 “ 零售 ” 給程序用。當全部“ 售完 ” 或程序有大量的內(nèi)存需求時,再根據(jù)實際需求向操作系統(tǒng) “ 進貨 ” 。 malloc 的實現(xiàn)方式有很多種,一般不同編譯器平臺用的都是不同的。比如windows 的 vs 系列用的微軟自己寫的一套,linux gcc用的 glibc 中的 ptmalloc 。

定長內(nèi)存池
作為程序員 (C/C++) 我們知道申請內(nèi)存使用的是 malloc , malloc 其實就是一個通用的大眾貨,什么場景下都可以用,但是什么場景下都可以用就意味著什么場景下都不會有很高的性能 ,下面我們就先來設(shè)計一個定長內(nèi)存池做個開胃菜,當然這個定長內(nèi)存池在我們后面的高并發(fā)內(nèi)存池中也是有價值的,所以學(xué)習(xí)他目的有兩層,先熟悉一下簡單內(nèi)存池是如何控制的,第二他會作為我們后面內(nèi)存池的一個基礎(chǔ)組件。
什么是定長內(nèi)存池?
我們設(shè)計這個內(nèi)存池之前,我們先來設(shè)計一個定長的內(nèi)存池,什么是定長內(nèi)存池呢,它就像new 一個對象一樣,每次new的時候?qū)ο蟮拇笮∈枪潭ǖ摹R簿褪钦f申請內(nèi)存的大小是已經(jīng)創(chuàng)建出的類的對象固定大小,這個時候相當于我們?yōu)檫@個類創(chuàng)建一個內(nèi)存池,每次申請的都是這個類的對象大小,為一個確定的值。
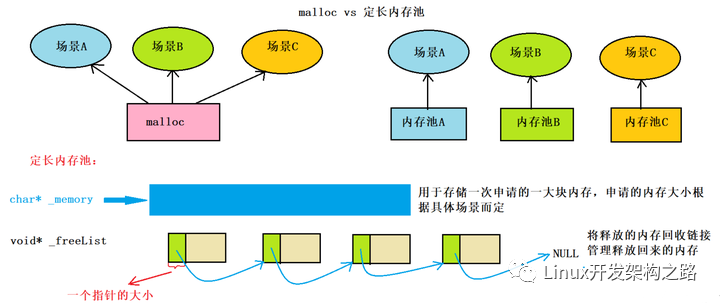
定長內(nèi)存池變量介紹
template< class T >
class ObjectPool
{
private:
char* _memory = nullptr; // 指向大塊內(nèi)存的指針
size_t _remainBytes = 0; // 大塊內(nèi)存在切分過程中剩余字節(jié)數(shù)
void* _freeList = nullptr; // 還回來過程中鏈接的自由鏈表的頭指針
};

因此,定長內(nèi)存池當中包含三個成員變量:
- _memory:指向大塊內(nèi)存的指針。
- _remainBytes:大塊內(nèi)存切分過程中剩余字節(jié)數(shù)。
- _freeList:還回來過程中鏈接的自由鏈表的頭指針。
定長內(nèi)存池申請一個對象大小空間實現(xiàn)
template< class T >
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
// 優(yōu)先把還回來內(nèi)存塊對象,再次重復(fù)利用
if (_freeList)
{
void* next = *((void**)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
// 剩余內(nèi)存不夠一個對象大小時,則重新開大塊空間
if (_remainBytes < sizeof(T))
{
_remainBytes = 128 * 1024;
_memory = (char*)malloc(_remainBytes);
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
obj = (T*)_memory;
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += objSize;
_remainBytes -= objSize;
}
// 定位new,顯示調(diào)用T的構(gòu)造函數(shù)初始化
new(obj)T;
return obj;
}
這里有一個很巧妙的構(gòu)造,為了讓釋放后的內(nèi)存塊在freelist中鏈接起來,由于32位下,一個指針的大小是4字節(jié),所以我們可以取這個對象的頭四個字節(jié)的內(nèi)容填充下一個回收對象的首地址,這樣就實現(xiàn)了把他們鏈接起來。
還有一處很好的設(shè)計,就是我們在32位下指針是4個字節(jié),但是在64位下,指針就是8個字節(jié),我們應(yīng)該如何來做呢?
(void)在這里就是一個很好的設(shè)計,當在64位下的時候,void是指針類型8字節(jié),void也是指針類型,8字節(jié),我對void解引用,得到的是void*8字節(jié),這個時候,我們就可以在64位下拿到前8個字節(jié),而32位下,就void照樣是4個字節(jié)。這樣就使得了void在32位和64位下都適用了。
總結(jié)申請步驟:先看回收鏈表中有沒有剩余,如果有的話,將剩余鏈表中頭刪一個對象,然后給obj。如果沒有了,就看下現(xiàn)在的剩余內(nèi)存池夠不夠創(chuàng)建一個對象的,如果不夠的話,找系統(tǒng)申請一個128K的空間,然后在新申請的內(nèi)存空間中切一個obj給他,當然還有一種情況,就是確實有剩余,但是對象本身不夠一個指針大小(32位下4字節(jié)),這個時候我們就可以直接給他一個指針大小就可以了。
定長內(nèi)存池釋放一個對象大小空間
void Delete(T* obj)
{
// 顯示調(diào)用析構(gòu)函數(shù)清理對象
obj- >~T();
// 頭插
*(void**)obj = _freeList;
_freeList = obj;
}
就是一個簡單的頭插即可,但是這個地方要注意的是我們在申請和釋放的時候都需要顯示的調(diào)用我們的構(gòu)造函數(shù)和析構(gòu)函數(shù),因為在這里創(chuàng)建對象和刪除對象的操作都是我們自己寫的接口,一旦我們自己寫了,系統(tǒng)就不會進行自動調(diào)用,我們就必須顯示的調(diào)用構(gòu)造函數(shù)和析構(gòu)函數(shù)來進行該類的初始化和清理工作,因為構(gòu)造函數(shù)和析構(gòu)函數(shù)的作用并不是僅僅開辟空間和銷毀空間,他們也有可能在其中做了很多其他的操作,所以我們必須進行顯示調(diào)用。
高并發(fā)內(nèi)存池整體框架設(shè)計
現(xiàn)代很多的開發(fā)環(huán)境都是多核多線程,在申請內(nèi)存的場景下,必然存在激烈的鎖競爭問題。 malloc 本身其實已經(jīng)很優(yōu)秀,那么我們項目的原型tcmalloc 就是在多線程高并發(fā)的場景下更勝一籌,所以這次我們
實現(xiàn)的 內(nèi)存池需要考慮以下幾方面的問題 。
- 性能問題。
- 多線程環(huán)境下,鎖競爭問題。
- 內(nèi)存碎片問題。
concurrent memory pool 主要由以下 3 個部分構(gòu)成:
- thread cache :線程緩存是每個線程獨有的,用于小于 256KB 的內(nèi)存的分配, 線程從這里申請內(nèi) 存不需要加鎖,每個線程獨享一個 cache ,這也就是這個并發(fā)線程池高效的地方 。
- central cache :中心緩存是所有線程所共享, thread cache 是 按需從 central cache 中獲取 的對象。central cache 合適的時機回收 thread cache 中的對象,避免一個線程占用了太多的內(nèi)存,而
其他線程的內(nèi)存吃緊, 達到內(nèi)存分配在多個線程中更均衡的按需調(diào)度的目的 。 central cache 是存
在競爭的,所以從這里取內(nèi)存對象是需要加鎖, 首先這里用的是桶鎖,其次只有 thread cache 的
沒有內(nèi)存對象時才會找 central cache ,所以這里競爭不會很激烈 。
- page cache :頁緩存是在 central cache 緩存上面的一層緩存,存儲的內(nèi)存是以頁為單位存儲及分配的,central cache 沒有內(nèi)存對象時,從 page cache 分配出一定數(shù)量的 page ,并切割成定長大小的小塊內(nèi)存,分配給central cache 。 當一個 span 的幾個跨度頁的對象都回收以后, page cache 會回收 central cache 滿足條件的 span 對象,并且合并相鄰的頁,組成更大的頁,緩解內(nèi)存碎片 的問題
Threadcache
Threadcache設(shè)計框架
之前我們實現(xiàn)定長內(nèi)存池的時候是一個永遠申請一個固定字節(jié)的大小,現(xiàn)在我們想要申請隨機空間的大小,那么這個時候我們可以采取一個類似于哈希桶的結(jié)構(gòu),當我們想要開辟某個大小空間的時候,我們就從對應(yīng)的下標的桶中取出一個對象大小。
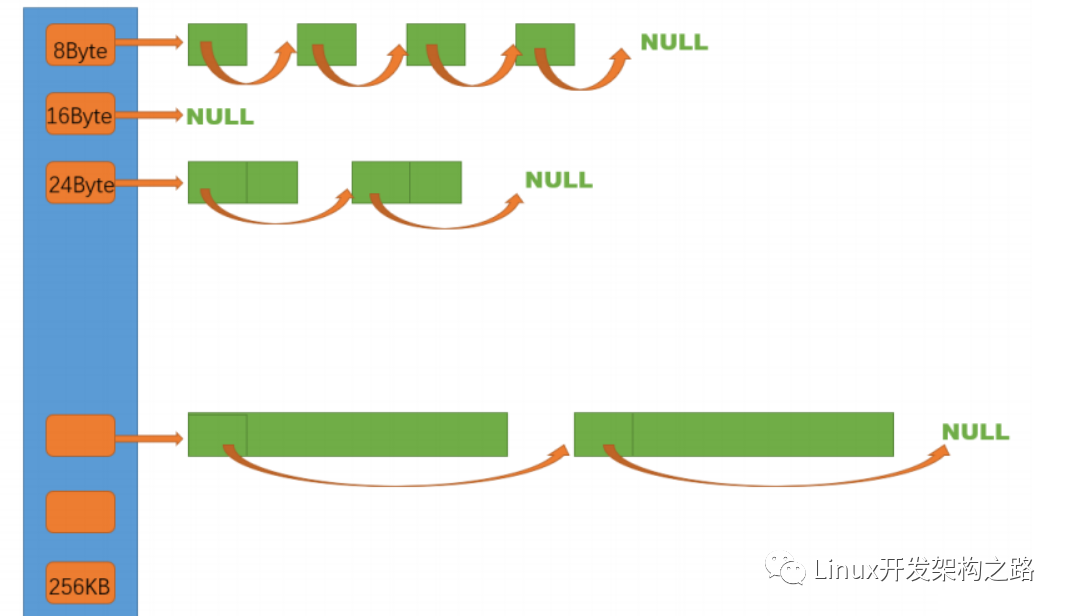
內(nèi)存碎片問題
那么現(xiàn)在問題又來了,我們需要開辟一個多大的哈希桶呢來存儲呢?我們這里可以定義最大一次性申請128K的空間,一次性申請超過128K的情況我們后邊再說。現(xiàn)在我們是想把這128K劃分成不同的情況,因為我們不可能開辟128*1024大小數(shù)組,開銷太大了,在每次申請的時候,我們都給它申請差不多的空間。
這個時候我們就需要做一個平衡了,就是說我們?nèi)绻o的空間與實際要的空間差距很小的話,那么證明我們需要開辟數(shù)組的大小更大(因為精確度提高,單位密度劃線就更大),如果我們開辟的空間與實際需求空間太小,我們就會造成空間的浪費,所以這里我們引入一個機制,就是內(nèi)存對齊的機制。
那么我們需要開辟多大的空間呢,如果都按照8字節(jié)來進行對齊的話,那么就要128*1024/8=32768,所以我們就引入了下面這個機制。

我們計算一下空間的利用率
根據(jù)上面的公式,我們要得到某個區(qū)間的最大浪費率,就應(yīng)該讓分子取到最大,讓分母取到最小。比如129~1024這個區(qū)間,該區(qū)域的對齊數(shù)是16,那么最大浪費的字節(jié)數(shù)就是15,而最小對齊后的字節(jié)數(shù)就是這個區(qū)間內(nèi)的前16個數(shù)所對齊到的字節(jié)數(shù),也就是144,那么該區(qū)間的最大浪費率也就是15 ÷ 144 ≈ 10.42 %左右,而1025+128=1052,而最大浪費空間就是127,這個是最小對齊數(shù)是127÷1152≈11.02%,同理1023÷9216≈11.10%。也就是說,我們可以把空間碎片率控制在百分之11左右。
FreeList的結(jié)構(gòu)
static void*& NextObj(void* obj)
{
return *(void**)obj;
}
class FreeList
{
public:
void Push(void* obj)
{
assert(obj);
// 頭插
//*(void**)obj = _freeList;
NextObj(obj) = _freeList;
_freeList = obj;
++_size;
}
void PushRange(void* start, void* end, size_t n)
{
NextObj(end) = _freeList;
_freeList = start;
_size += n;
}
void PopRange(void*& start, void*& end, size_t n)
{
assert(n <= _size);
start = _freeList;
end = start;
for (size_t i = 0; i < n - 1; ++i)
{
end = NextObj(end);
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
_size -= n;
}
void* Pop()
{
assert(_freeList);
// 頭刪
void* obj = _freeList;
_freeList = NextObj(obj);
--_size;
return obj;
}
bool Empty()
{
return _freeList == nullptr;
}
size_t& MaxSize()
{
return _maxSize;
}
size_t Size()
{
return _size;
}
private:
void* _freeList = nullptr;
size_t _maxSize = 1;
size_t _size = 0;
};
這里就與前面的定長內(nèi)存池實現(xiàn)就差不多了,size記錄freelist的個數(shù),這里統(tǒng)一用Nextobj來直接去這個對象的前四個字節(jié)。
根據(jù)申請大小計算對齊數(shù)及桶號
計算對齊數(shù)
static inline size_t RoundUp(size_t bytes)
{
if (bytes <= 128)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 1024)
{
return _RoundUp(bytes, 16);
}
else if (bytes <= 8 * 1024)
{
return _RoundUp(bytes, 128);
}
else if (bytes <= 64 * 1024)
{
return _RoundUp(bytes, 1024);
}
else if (bytes <= 256 * 1024)
{
return _RoundUp(bytes, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
size_t alignSize = 0;
if (bytes%alignNum != 0)
{
alignSize = (bytes / alignNum + 1)*alignNum;
}
else
{
alignSize = bytes;
}
return alignSize;
}
我們可以通過這種方式在計算其對齊數(shù)的大小,相當于對于一個非對齊數(shù)的值,往下加一個對應(yīng)區(qū)間內(nèi)的對齊數(shù),就是該對齊數(shù)的值,比較通俗易懂,而其實谷歌的大佬也為我們提供了另一種寫法,是這個樣子的,兩種達到的效果是一樣的。
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
二、計算對應(yīng)的哈希桶桶號
size_t _Index(size_t bytes, size_t alignNum)
{
if (bytes % alignNum == 0)
{
return bytes / alignNum - 1;
}
else
{
return bytes / alignNum;
}
}
// 計算映射的哪一個自由鏈表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每個區(qū)間有多少個鏈
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 8);
}
else if (bytes <= 1024){
return _Index(bytes - 128, 16) + group_array[0];
}
else if (bytes <= 8 * 1024){
return _Index(bytes - 1024, 128) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024){
return _Index(bytes - 8 * 1024, 1024) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024){
return _Index(bytes - 64 * 1024, 8*1024) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else{
assert(false);
}
return -1;
}
原理也是顯而易見的,我們先計算他在這個區(qū)間排在第幾個位置,再加上這個區(qū)間之前的全部的桶號就是這個申請大小鎖要去找的桶號,就是這個桶號的下標。
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 < < align_shift) - 1) > > align_shift) - 1;
}
當然,谷歌程序員也給我們提供了一種更高效的算法,其效果與我們之前實現(xiàn)的是一樣的。
static const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREELIST = 208;
按照剛才的設(shè)計,計算出來一共是208個桶,我們定義最大申請大小是256K,這樣的話就把剛才的內(nèi)容和現(xiàn)在的聯(lián)系起來了。
Threadcache類的設(shè)計
class ThreadCache
{
public:
// 申請和釋放內(nèi)存對象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 從中心緩存獲取對象
void* FetchFromCentralCache(size_t index, size_t size);
// 釋放對象時,鏈表過長時,回收內(nèi)存回到中心緩存
void ListTooLong(FreeList& list, size_t size);
private:
FreeList _freeLists[NFREELIST];
};
// TLS thread local storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
TLS無鎖獲取機制
我們設(shè)計的目的是想讓每一個線程都可以拿到自己獨有的 threadcache,而想要在一個線程中獲取到屬于自己的資源就必須加鎖進行保護,而加鎖必定會浪費時間資源,這個地方我們可以使用TLS機制來進行訪問。
一、申請內(nèi)存對象
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty())
{
return _freeLists[index].Pop();
}
else
{
return FetchFromCentralCache(index, alignSize);
}
}
原理很簡單,就是先判斷是否小于256K,然后計算字節(jié)對齊數(shù)和桶號,在到對應(yīng)的哈希桶下面去彈出一個桶大小的對象給它,但是如果對應(yīng)表沒有了,那么這個時候我們就需要到對應(yīng)的下一層centralcache去拿數(shù)據(jù)了。
二、向中心緩存獲取對象
這個時候問題就來了,我們一次向中心緩存獲取多少個對象比較好呢,如果一次申請?zhí)伲竺嫖覀冃枰@個空間大小的對象申請很多的話,那么就會造成頻繁向中心緩存申請的問題,造成效率下降,但是如果一次性申請?zhí)嗟脑挘貌涣司涂赡茉斐少Y源的浪費,所以我們這里可以用一個慢增長的機制。
什么是慢增長機制呢?
就是在申請對象的時候,剛剛開始給1,往后再申請的時候,我們讓最大值+1,當然也不能一直加下去,我們可以設(shè)定一個最高值,就是用最大申請大小/這個申請大小,來表示這個大小一次性申請的最大上限,然后最終兩者取小即可。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 慢開始反饋調(diào)節(jié)算法
// 1、最開始不會一次向central cache一次批量要太多,因為要太多了可能用不完
// 2、如果你不要這個size大小內(nèi)存需求,那么batchNum就會不斷增長,直到上限
// 3、size越大,一次向central cache要的batchNum就越小
// 4、size越小,一次向central cache要的batchNum就越大
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()- >FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
_freeLists[index].PushRange(NextObj(start), end, actualNum-1);
return start;
}
}
三、釋放內(nèi)存對象
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
// 找對映射的自由鏈表桶,對象插入進入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 當鏈表長度大于一次批量申請的內(nèi)存時就開始還一段list給central cache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize())
{
ListTooLong(_freeLists[index], size);
}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRange(start, end, list.MaxSize());
CentralCache::GetInstance()- >ReleaseListToSpans(start, size);
}
我們先斷言一下是否歸還的大小大于最大值,然后計算桶號,把歸還回來的插入對應(yīng)的桶,插入桶之后,桶里的對象就增加了,當增加到一定程度的時候我們就應(yīng)該把一部分對象歸還給該對象。
Centralache
Centralache的整體設(shè)計
我們在這里選擇與threadache哈希桶一一對應(yīng)的模式,只不過這次掛的并不是一個一個對象了,而是一個又一個span,span塊的大小是以頁為單位的(這里頁我們設(shè)計成8K的大小),每一個span都按照對應(yīng)桶號的字節(jié)對齊大小且成了一個又一個的小對象,然后span與span之間的關(guān)系我們不再用頭四個字節(jié)存地址了(因為存的是下一個小對象的地址),我們用雙向鏈表來維護他們之間的關(guān)系。
span的結(jié)構(gòu)設(shè)計
struct Span
{
PAGE_ID _pageId = 0; // 大塊內(nèi)存起始頁的頁號
size_t _n = 0; // 頁的數(shù)量
Span* _next = nullptr; // 雙向鏈表的結(jié)構(gòu)
Span* _prev = nullptr;
size_t _useCount = 0; // 切好小塊內(nèi)存,被分配給thread cache的計數(shù)
void* _freeList = nullptr; // 切好的小塊內(nèi)存的自由鏈表
bool _isUse = false; // 是否在被使用
};
由于是雙向循環(huán)的鏈表,我們就按照之前的雙向鏈表來定義前后指針,以及這個span是否正在被使用,以及_usecount來表示用了多少塊了,如果usecount=0,就證明全部的內(nèi)存塊都還回來了。以及freelist,就是span下面切的小對象的鏈表。
在這里我們詳細談一下頁號,當我們在32位系統(tǒng)下,我們有2的32次方個地址空間,而64位系統(tǒng)下,有2的64次方個地址空間。我們以8K作為1頁的大小,那么32位系統(tǒng)下就有2的19次方頁,而64位系統(tǒng)下,就有2的51次方頁,這里我們?nèi)绾蝸肀硎卷撎柲兀涂梢允褂胹ize_t來表示32位的大小,用longlong來表示64位下的大小。
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
// linux
#endif
另外64位下也是可以識別32位的,所以要先把64位下的情況寫在前面。
SpanList結(jié)構(gòu)設(shè)計
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head- >_next = _head;
_head- >_prev = _head;
}
Span* Begin()
{
return _head- >_next;
}
Span* End()
{
return _head;
}
bool Empty()
{
return _head- >_next == _head;
}
void PushFront(Span* span)
{
Insert(Begin(), span);
}
Span* PopFront()
{
Span* front = _head- >_next;
Erase(front);
return front;
}
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos- >_prev;
// prev newspan pos
prev- >_next = newSpan;
newSpan- >_prev = prev;
newSpan- >_next = pos;
pos- >_prev = newSpan;
}
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head);
Span* prev = pos- >_prev;
Span* next = pos- >_next;
prev- >_next = next;
next- >_prev = prev;
}
private:
Span* _head;
public:
std::mutex _mtx; // 桶鎖
};
這里就是一個簡單的雙向鏈表的各種操作,但是唯一與雙向鏈表不同的是,在這里我們定義了一個桶鎖,當兩個線程需要訪問同一個桶的時候,這個時候我們就需要進行加鎖了。
Centralache類的設(shè)計
class CentralCache
{
public:
static CentralCache* GetInstance()
{
return &_sInst;
}
// 獲取一個非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 從中心緩存獲取一定數(shù)量的對象給thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
// 將一定數(shù)量的對象釋放到span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
};
由于這里不再是單個線程獨有的部分了,而是被所有線程共用一個的裝置,所以我們需要在這里設(shè)計成單例模式,其實不需要設(shè)計成餓漢模式,那樣的話就比較復(fù)雜,在這里設(shè)計成懶漢模式就夠了。
獲取一個新的Span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 查看當前的spanlist中是否有還有未分配對象的span
Span* it = list.Begin();
while (it != list.End())
{
if (it- >_freeList != nullptr)
{
return it;
}
else
{
it = it- >_next;
}
}
// 先把central cache的桶鎖解掉,這樣如果其他線程釋放內(nèi)存對象回來,不會阻塞
list._mtx.unlock();
// 走到這里說沒有空閑span了,只能找page cache要
PageCache::GetInstance()- >_pageMtx.lock();
Span* span = PageCache::GetInstance()- >NewSpan(SizeClass::NumMovePage(size));
span- >_isUse = true;
PageCache::GetInstance()- >_pageMtx.unlock();
// 對獲取span進行切分,不需要加鎖,因為這會其他線程訪問不到這個span
// 計算span的大塊內(nèi)存的起始地址和大塊內(nèi)存的大小(字節(jié)數(shù))
char* start = (char*)(span- >_pageId < < PAGE_SHIFT);
size_t bytes = span- >_n < < PAGE_SHIFT;
char* end = start + bytes;
// 把大塊內(nèi)存切成自由鏈表鏈接起來
// 1、先切一塊下來去做頭,方便尾插
span- >_freeList = start;
start += size;
void* tail = span- >_freeList;
int i = 1;
while (start < end)
{
++i;
NextObj(tail) = start;
tail = NextObj(tail); // tail = start;
start += size;
}
// 切好span以后,需要把span掛到桶里面去的時候,再加鎖
list._mtx.lock();
list.PushFront(span);
return span;
}
獲取一個非空的span,注意span并不是像obj一樣分發(fā)完了就不存在了,它的結(jié)構(gòu)是一個固定的結(jié)構(gòu),所以我們每次都要遍歷一遍在這個桶的spanlist的鏈表,看是否有空的span。
如果沒有的話我們就應(yīng)該往下一層pageache中去獲取span,獲取完成以后,把span的使用設(shè)置成正在被使用的狀態(tài),這個時候問題又來了,我們獲取一個幾頁的span比較合適呢?
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size);
size_t npage = num*size;
npage > >= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
}
我們可以先找到對應(yīng)的申請大小一次往centralache一次最多拿多少個對象,然后用最大申請的對象*每個對象的大小,得到的是threadache一次向centralache最多獲取的字節(jié)數(shù),然后÷8K就是我們要申請多少頁的span。
然后把頁號轉(zhuǎn)化為地址,然后把頁號*頁字節(jié)數(shù)(8K),就是這個span一共有多少個字節(jié),用本頁的起始地址+字節(jié)數(shù)就是這個span結(jié)尾地址,這個時候我們就拿到了span的兩端,即start和end。把一個span切成對應(yīng)對象的大小(先切下一個頭節(jié)點方便尾插)前4個字節(jié)存下一個的地址。
關(guān)于鎖的問題
我們這里的加鎖是以桶為單位的,只有兩個線程訪問到了同一個桶的時候,我們這個時候才需要加鎖,當centralache不夠的時候,需要往pageache中拿而這個時候就可以把桶鎖釋放掉,因為我們現(xiàn)在是要到pageache中進行操作,而有可能其他線程這個時候正想把一些對象還回來,所以我們這里的操作就是把桶鎖放開。
而我們向pageache拿到一個span后,需要把大鎖放開,因為這個span是我們新申請的,其他的線程就算是再去pageache中申請,也不可能拿到當前已經(jīng)申請完成的span,所以這里我們可以把大鎖放開,然后再進行span的切分操作。
還有一個問題就是,當切分好了對象的span插入到對應(yīng)的桶的時候,這個時候的在對應(yīng)的桶里進行插入操作,需要把桶鎖加回來,有可能會造成一個線程在插入,另一個線程在獲取,兩個線程就可能對同一個桶同時進行操作,線程就不安全了。
從中心緩存獲取一定數(shù)量的對象給thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span- >_freeList);
// 從span中獲取batchNum個對象
// 如果不夠batchNum個,有多少拿多少
start = span- >_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
while ( i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
++i;
++actualNum;
}
span- >_freeList = NextObj(end);
NextObj(end) = nullptr;
span- >_useCount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
當上層threadache中的對象不夠的時候,此時就向中心緩存centralache中的對應(yīng)位置的哈希桶內(nèi)獲取一個span(剛剛已經(jīng)寫了獲取span的函數(shù)),在這里定義start和end為輸出型參數(shù),把span的頭節(jié)點給start,因為span已經(jīng)執(zhí)行完了切對象的操作(把每個對象個大小的內(nèi)存塊的),所以我們直接通過前4個字節(jié)遍歷對應(yīng)span下的_freelist的內(nèi)存塊,獲取對應(yīng)的對象個數(shù),并把獲取的結(jié)尾位置給end。
當然,有可能因為span中的對象個數(shù)不足我們想要獲取的,這個時候有多少拿多少,然后每獲取一個實際對象,使用塊計數(shù)++(方便判斷都還回來的時候,那時usecount==0,此時就可以歸還這個span給pageache),完成操作之后把鎖解開。
【誤區(qū):這個時候不要擔(dān)心一次性獲取不完足夠的對象,然后再去找pageache中獲取新的span再拿沒獲取完的對象,沒有必要,因為我們每次申請空間實際上只需要彈出一個對象就夠了(因為那1個對象的大小就是經(jīng)過計算、對齊之后的本次申請大小,大小必然是大于等于我們的申請空間),所以說只要span不為空,只要還有一次對象,相當于就滿足了這次的申請空間的需求,而下次再申請的時候,如果對應(yīng)spanlist中一個對象都沒有的話,Getonespan函數(shù)就會到對應(yīng)的pageache獲取,所以這里不夠時,就多少拿多少就行。】
把threadache中的對象還給span
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
while (start)
{
void* next = NextObj(start);
Span* span = PageCache::GetInstance()- >MapObjectToSpan(start);
NextObj(start) = span- >_freeList;
span- >_freeList = start;
span- >_useCount--;
// 說明span的切分出去的所有小塊內(nèi)存都回來了
// 這個span就可以再回收給page cache,pagecache可以再嘗試去做前后頁的合并
if (span- >_useCount == 0)
{
_spanLists[index].Erase(span);
span- >_freeList = nullptr;
span- >_next = nullptr;
span- >_prev = nullptr;
// 釋放span給page cache時,使用page cache的鎖就可以了
// 這時把桶鎖解掉
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()- >_pageMtx.lock();
PageCache::GetInstance()- >ReleaseSpanToPageCache(span);
PageCache::GetInstance()- >_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRange(start, end, list.MaxSize());
CentralCache::GetInstance()- >ReleaseListToSpans(start, size);
}
當threadache中的freelist長度超過一次性申請的最大長度MaxSize的時候,我們就可以把threadahche中的MaxSize對象還給centralache,可以利用popRange先把MaxSize對象在threadache中刪去,又因為popRange的start與end是輸出型參數(shù),我們可以拿到刪除部分的頭節(jié)點,popRange可以把結(jié)尾部分的對象的下一個節(jié)點是空,所以回收這些對象的時候可以順著start一直訪問到空的時候就可以了。
我們傳入size,先計算這個對象在對應(yīng)的哪一個桶,加上桶鎖,然后找到一個對應(yīng)span(具體怎么對應(yīng),后面講),找出其下面的freelist往里面一個對象一個對象進行頭插,每插入一個對象,相當于換回來一個切分塊,所以usecount需要進行減一的操作。
當usecount減到0的時候,說明這一個span全部還回來了,這個時候我們就把span繼續(xù)還給下一層的pageache,然后再把start=next插入下一個對象,直到全部插入完成。
接著來說到鎖的問題,當span的usecount==0即都還回來的時候,我們先把span的刪除,然后再把這個桶鎖放開,因為現(xiàn)在span已經(jīng)刪除,不在鏈表中,所以其他線程訪問不到span,這個時候加大鎖去pageache中歸還這個span即可。
歸還完成之后放開大鎖,再把桶鎖加上,因為歸還的每一個對象不一定來自同一個span,所以下一個對象可能是這個桶中別的span,此時還未歸還完,所以要加上再桶鎖,具體如何找到對應(yīng)的span,后面講。
Pageache
Pageache的整體設(shè)計框架
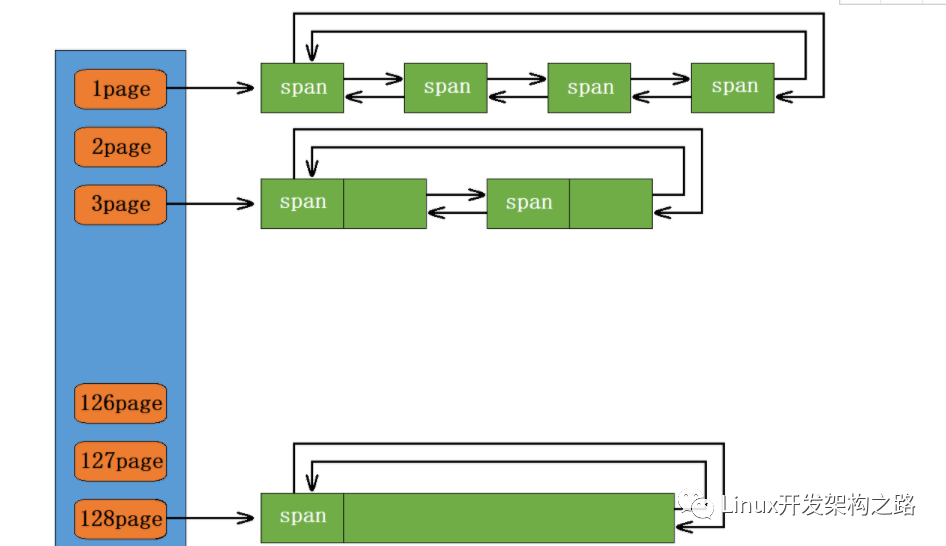
與threadache和centralache不同的是,Pageache的基本單位是span,而其哈希桶下標所對應(yīng)的下標是表示這個哈希桶掛著的是一個幾頁的span,這也是方便了centralache向pageache中獲取的時候直接以n頁的span為目的獲取。
Pageache類的設(shè)計
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
// 獲取從對象到span的映射
Span* MapObjectToSpan(void* obj);
// 釋放空閑span回到Pagecache,并合并相鄰的span
void ReleaseSpanToPageCache(Span* span);
// 獲取一個K頁的span
Span* NewSpan(size_t k);
std::mutex _pageMtx;
private:
SpanList _spanLists[NPAGES];
std::unordered_map< PAGE_ID, Span* > _idSpanMap;
PageCache()
{}
PageCache(const PageCache&) = delete;
static PageCache _sInst;
};
(難點)兩個關(guān)系的轉(zhuǎn)化與映射
頁號與地址的對應(yīng)

由于我們剛開始的時候需要向系統(tǒng)申請一塊256K的空間 ,這個空間的地址必然是連續(xù)的,既然是連續(xù)的,我們的地址其實可以看作16進制,我們把轉(zhuǎn)成十進制后依然是連續(xù)的,我們除以每頁的大小,就是這個頁的頁號,然后通過頁號1頁的大小(這里是4K,41024),就可以找到本頁的首地址。
頁號與span的對應(yīng)關(guān)系
這個時候重點的來了,我使用的時候拿到的是threadache給我提供的一個個對象,而這一個個對象必然是來自某些span,然后這些對象用完了會隨機釋放到freelist的中,freelist達到Maxsize個對象就把一些對象還回centralache中的span,現(xiàn)在問題是我怎么知道這些對象之前來自哪個span?
我們退一步說,我們?yōu)槭裁匆肋@個對象來自哪個span?或者說我們?yōu)槭裁匆pan和頁號的對應(yīng)關(guān)系?原因有兩個:
1.我們當時申請內(nèi)存是申請一大塊連續(xù)內(nèi)存,為了高效,我們釋放的時候也需要釋放一大塊連續(xù)內(nèi)存,而申請上來的連續(xù)內(nèi)存又被切分成了一個個span,而span是如何表示其內(nèi)存的連續(xù)關(guān)系呢?是通過頁號,一個span中有n頁,我們通過找到最前面的頁和最后面頁的頁號,將他們轉(zhuǎn)化為地址,來找到當時申請時前后的連續(xù)空間的地址對應(yīng)的span。以實現(xiàn)前后頁的合并,最終將一大塊連續(xù)內(nèi)存還給操作系統(tǒng)。
2.當span被切分之后,就成了一個又一個的小對象,而剛開始還未使用的span中每一個對象空間地址必然是連續(xù)的,切分之后我們需要讓他們找到曾經(jīng)被切分的span,當usecount減到0的時候,說明所有的span中所有的切的小對象大小都回來了,這個時候可能freelist中的所有對象塊不是連續(xù)的(因為回來的時間可能不是按序到達,只是來一個頭插一個)這都無所謂,但是假設(shè)可以把他們排列組合,就會發(fā)現(xiàn)就是我們曾經(jīng)申請的span的那一個地址區(qū)間。這樣一個span找好了,就可以完成剛剛說的合并了。而一個對象的查找所屬span,我們可以通過對象的地址,來找到其所屬頁,再通過頁號與span的映射關(guān)系來完成。
問題來啦,我們怎么實現(xiàn)頁表與span的映射呢,我們可以用哈希map來實現(xiàn),我們通過了解“獲取一個K頁的span來深度解析一下這個過程”。
獲取一個K頁的span
在之前我們說到,當centralache中span沒有對象的時候,就會根據(jù)Maxsize()×一個對象空間的字節(jié)數(shù)除以一頁的大小,計算出獲取一個K頁的span找pageache進行獲取。
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
// 先檢查第k個桶里面有沒有span
if (!_spanLists[k].Empty())
{
Span* kSpan = _spanLists- >PopFront();
for (PAGE_ID i = 0; i < kSpan- >_n; ++i)
{
//_idSpanMap[kSpan- >_pageId + i] = kSpan;
_idSpanMap.set(kSpan- >_pageId + i, kSpan);
}
return kspan;
}
// 檢查一下后面的桶里面有沒有span,如果有可以把他它進行切分
for (size_t i = k+1; i < NPAGES; ++i)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
Span* kSpan = new Span;
// 在nSpan的頭部切一個k頁下來
// k頁span返回
// nSpan再掛到對應(yīng)映射的位置
kSpan- >_pageId = nSpan- >_pageId;
kSpan- >_n = k;
nSpan- >_pageId += k;
nSpan- >_n -= k;
_spanLists[nSpan- >_n].PushFront(nSpan);
// 存儲nSpan的首位頁號跟nSpan映射,方便page cache回收內(nèi)存時
// 進行的合并查找
_idSpanMap[nSpan- >_pageId] = nSpan;
_idSpanMap[nSpan- >_pageId + nSpan- >_n - 1] = nSpan;
// 建立id和span的映射,方便central cache回收小塊內(nèi)存時,查找對應(yīng)的span
for (PAGE_ID i = 0; i < kSpan- >_n; ++i)
{
_idSpanMap[kSpan- >_pageId + i] = kSpan;
}
return kSpan;
}
// 走到這個位置就說明后面沒有大頁的span了
// 這時就去找堆要一個128頁的span
//Span* bigSpan = new Span;
Span* bigSpan = _spanPool.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan- >_pageId = (PAGE_ID)ptr > > PAGE_SHIFT;
bigSpan- >_n = NPAGES - 1;
_spanLists[bigSpan- >_n].PushFront(bigSpan);
return NewSpan(k);
}
拿到k頁請求之后,先進行一下斷言,看下是否符合在1-128頁的span范圍之內(nèi),,然后看對應(yīng)K頁span的桶是否有對象,如果有,就開始從這個span的開始頁 建立每一頁和span的映射關(guān)系,因為這個span需要去切成小對象,小對象通過自己的地址找到首頁頁號,這個頁號因為必然建立過與span的映射,所以可以找到span。
而如果一個span沒有的話,那么我們不是直接向系統(tǒng)申請,而是順著向后面的桶尋找,如果后面的某個桶中有的話,那么就從這個span中切下K頁大小,然后把剩下的N頁掛到第N號桶上去。并把span的頁數(shù),首頁頁號等進行一下修改。
切之后的span也是需要建立頁號與span的映射的,但是這里不用把每一頁都建立,因為如果后面使用到這個span(這里是指把這個span拿到centralache中)那個時候我們自然會建立每頁與span的映射,而此時暫時用不到它,這時建立映射的目的只是為了后面實現(xiàn)span與span的合并,而合并的時候,我們是查找對應(yīng)span相鄰的頁,我們只需要把這個span的首頁和尾頁與span建立起聯(lián)系即可。
如果后面的桶中一個對象都沒用,這個時候直接找系統(tǒng)要一個128頁的span,然后把這個大span插入到128號桶上,再重復(fù)調(diào)用一下這個函數(shù),這個時候128頁的span不為空,所以就可以切下K頁,把128-K頁掛到對應(yīng)的桶上去。
映射函數(shù)設(shè)計
Span* PageCache::MapObjectToSpan(void* obj)
{
PAGE_ID id = ((PAGE_ID)obj > > PAGE_SHIFT);
std::unique_lock< std::mutex > lock(_pageMtx);
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end())
{
return ret- >second;
}
else
{
assert(false);
return nullptr;
}
}
這里是已知對象首地址,來查找span,我們先把地址轉(zhuǎn)化成頁號,然后再從map中查找對應(yīng)頁號映射的*span。并把對應(yīng)的span返回,如果沒有,就報錯。
這里是要加鎖的,因為我們在訪問map的時候,其他線程可能在執(zhí)行插入的操作,如果插入滿了就可能會造成unordered_map的擴容,熟悉unordered_map都知道,擴容后所有數(shù)據(jù)要根據(jù)數(shù)組進行重新映射,這個時候有線程讀,就會造成數(shù)據(jù)和錯亂的問題,所以一定要加上鎖。
模擬原來儲存的形式:
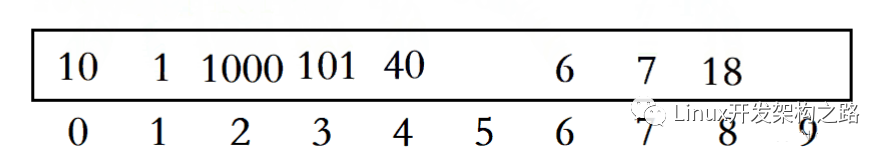
若有線程插入數(shù)據(jù)導(dǎo)致擴容后的儲存形式:

發(fā)現(xiàn)此時儲存形式發(fā)生了改變,為了防止一個線程正在讀,另一個線程正在建立映射造成這種問題。所以說是需要加鎖的。
pageache回收span
當一個span的usecount--到0的時候,說明span里面的小對象已經(jīng)全部還回來了,這個時候我們就可以把這個span還給pageache了。
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 大于128 page的直接還給堆
if (span- >_n > NPAGES-1)
{
void* ptr = (void*)(span- >_pageId < < PAGE_SHIFT);
SystemFree(ptr);
//delete span;
_spanPool.Delete(span);
return;
}
// 對span前后的頁,嘗試進行合并,緩解內(nèi)存碎片問題
while (1)
{
PAGE_ID prevId = span- >_pageId - 1;
auto ret = _idSpanMap.find(prevId);
// 前面的頁號沒有,不合并了
if (ret == _idSpanMap.end())
{
break;
}
// 前面相鄰頁的span在使用,不合并了
Span* prevSpan = ret- >second;
if (prevSpan- >_isUse == true)
{
break;
}
// 合并出超過128頁的span沒辦法管理,不合并了
if (prevSpan- >_n + span- >_n > NPAGES-1)
{
break;
}
span- >_pageId = prevSpan- >_pageId;
span- >_n += prevSpan- >_n;
_spanLists[prevSpan- >_n].Erase(prevSpan);
//delete prevSpan;
_spanPool.Delete(prevSpan);
}
// 向后合并
while (1)
{
PAGE_ID nextId = span- >_pageId + span- >_n;
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}
Span* nextSpan = ret- >second;
if (nextSpan- >_isUse == true)
{
break;
}
if (nextSpan- >_n + span- >_n > NPAGES-1)
{
break;
}
span- >_n += nextSpan- >_n;
_spanLists[nextSpan- >_n].Erase(nextSpan);
//delete nextSpan;
_spanPool.Delete(nextSpan);
}
_spanLists[span- >_n].PushFront(span);
span- >_isUse = false;
_idSpanMap[span- >_pageId] = span;
_idSpanMap[span- >_pageId+span- >_n-1] = span;
}
先判斷這個span是否大于128,如果大于128,則直接還給堆。
我們分別向前向后進行合并頁面,只要碰到一下的情況,就不再合并了:
1.前后頁還沒有開辟出來(沒有出現(xiàn)再映射關(guān)系中)。
2.前后頁的span正在使用中。
3.合并頁數(shù)超過128,就不在往后合并了。
符合合并條件之后,把span的頁數(shù)加上新合并的頁數(shù),再把之前合并前的那個span刪去,并把合并后的大span插入到對應(yīng)頁數(shù)的哈希桶上,并把前后頁加入映射關(guān)系中,方便下一次的合并。
項目優(yōu)化與測試
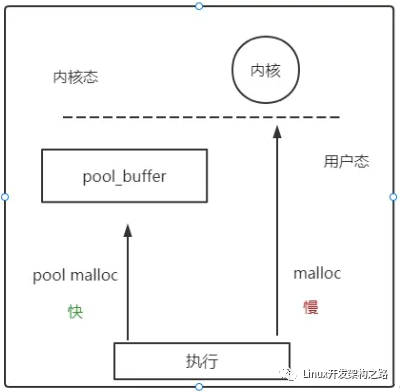
優(yōu)化一 利用定長內(nèi)存池代替new
我們在前面已經(jīng)實現(xiàn)了一個定長的內(nèi)存池,我們經(jīng)過測試,發(fā)現(xiàn)效率是要比new和delete高的,所以我們在這里把new和delete代替。
//單例模式
class PageCache
{
public:
//...
private:
ObjectPool _spanPool;
};
//申請span對象
Span* span = _spanPool.New();
//釋放span對象
_spanPool.Delete(span);
//通過TLS,每個線程無鎖的獲取自己專屬的ThreadCache對象
if (pTLSThreadCache == nullptr)
{
static std::mutex tcMtx;
static ObjectPool< ThreadCache > tcPool;
tcMtx.lock();
pTLSThreadCache = tcPool.New();
tcMtx.unlock();
}
//帶頭雙向循環(huán)鏈表
class SpanList
{
public:
SpanList()
{
_head = _spanPool.New();
_head- >_next = _head;
_head- >_prev = _head;
}
private:
Span* _head;
static ObjectPool _spanPool;
};
優(yōu)化二 釋放對象時不傳對象大小
我們銷毀對象的時候,必須要傳入size來計算其桶號,然后找到對應(yīng)的桶進行釋放,其實可以不傳入size,只需要在span中加入一個objsize,下次獲取span時候同時在span上記錄下size的值,銷毀的時候只需要用對象的地址找到對應(yīng)的頁號,在利用頁號在map中映射到對應(yīng)的span,獲取objsize(
PageCache::MapObjectToSpan函數(shù))即可
//管理以頁為單位的大塊內(nèi)存
struct Span
{
PAGE_ID _pageId = 0; //大塊內(nèi)存起始頁的頁號
size_t _n = 0; //頁的數(shù)量
Span* _next = nullptr; //雙鏈表結(jié)構(gòu)
Span* _prev = nullptr;
size_t _objSize = 0; //切好的小對象的大小
size_t _useCount = 0; //切好的小塊內(nèi)存,被分配給thread cache的計數(shù)
void* _freeList = nullptr; //切好的小塊內(nèi)存的自由鏈表
bool _isUse = false; //是否在被使用
};
Span* span = PageCache::GetInstance()- >NewSpan(SizeClass::NumMovePage(size));
span- >_objSize = size;
static void ConcurrentFree(void* ptr)
{
Span* span = PageCache::GetInstance()- >MapObjectToSpan(ptr);
size_t size = span- >_objSize;
if (size > MAX_BYTES) //大于256KB的內(nèi)存釋放
{
PageCache::GetInstance()- >_pageMtx.lock();
PageCache::GetInstance()- >ReleaseSpanToPageCache(span);
PageCache::GetInstance()- >_pageMtx.unlock();
}
else
{
assert(pTLSThreadCache);
pTLSThreadCache- >Deallocate(ptr, size);
}
}
優(yōu)化三 利用基數(shù)樹代替unordered_map優(yōu)化

通過調(diào)試發(fā)現(xiàn),最消耗效率的是map中的鎖,因為每次頁號查找span的時候我們都需要進行加鎖解鎖操作耗費了大量的時間。
在這里我們需要仔細想一想,就是說我們加鎖的目的之前已經(jīng)說過,就是為了防止一邊在讀,另一邊在插入導(dǎo)致unordered_map擴容,數(shù)據(jù)與內(nèi)存不匹配的問題,要想解決這個問題,我們主要的方法就是防止擴容。
怎么才能防止擴容,其核心策略就是把所有頁號個數(shù)的數(shù)組開辟出來,這樣我們就引入了基數(shù)樹。
基數(shù)數(shù)是直接開辟所有可能的頁下標數(shù)組,是一個固定的結(jié)構(gòu),數(shù)據(jù)只有存在和不存在兩種狀態(tài),而且因為頁號固定屬于一個span,所以不可能存在更改映射關(guān)系的可能,只能在新的span被使用的時候往里面不斷寫入映射,而上層使用映射來做什么的時候,使用的必定是已經(jīng)建立好映射的關(guān)系。
那么我們這個樹需要開辟多大呢,在32位下,一頁8K的話,我們2的32次方÷2的13次方是2的19次方,我們一個數(shù)組的一個元素需要存一個span的指針,也就是4個字節(jié),算下來需要開辟2的19次方4字節(jié)=2M大小,是可以的,但是在64位,下,2的64次方÷2的13次方是2的51次方,一個指針8字節(jié),2的51次方×8大概是2的24次方G,絕對是行不通的,所以這里我們要引入3層基數(shù)樹。

我們以32位下,一頁8K為例,需要表示頁號大概是要19和比特位,我們把這19個比特位進行拆分映射,第一次先拿5個比特位,然后再拿后面5個比特位進行二次映射,最后拿剩下的比特位找到對應(yīng)的span指針。
其三層的好處是,我們不需要一上來就把2M的空間開辟出來,我們當用到某一個區(qū)域的地址頁號映射要求的時候,我們才開辟對應(yīng)的空間,這樣又進一步提高了效率。
基數(shù)樹代碼:
//二層基數(shù)樹
template < int BITS >
class TCMalloc_PageMap2
{
private:
static const int ROOT_BITS = 5; //第一層對應(yīng)頁號的前5個比特位
static const int ROOT_LENGTH = 1 < < ROOT_BITS; //第一層存儲元素的個數(shù)
static const int LEAF_BITS = BITS - ROOT_BITS; //第二層對應(yīng)頁號的其余比特位
static const int LEAF_LENGTH = 1 < < LEAF_BITS; //第二層存儲元素的個數(shù)
//第一層數(shù)組中存儲的元素類型
struct Leaf
{
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; //第一層數(shù)組
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap2()
{
memset(root_, 0, sizeof(root_)); //將第一層的空間進行清理
PreallocateMoreMemory(); //直接將第二層全部開辟
}
void* get(Number k) const
{
const Number i1 = k > > LEAF_BITS; //第一層對應(yīng)的下標
const Number i2 = k & (LEAF_LENGTH - 1); //第二層對應(yīng)的下標
if ((k > > BITS) > 0 || root_[i1] == NULL) //頁號值不在范圍或沒有建立過映射
{
return NULL;
}
return root_[i1]- >values[i2]; //返回該頁號對應(yīng)span的指針
}
void set(Number k, void* v)
{
const Number i1 = k > > LEAF_BITS; //第一層對應(yīng)的下標
const Number i2 = k & (LEAF_LENGTH - 1); //第二層對應(yīng)的下標
assert(i1 < ROOT_LENGTH);
root_[i1]- >values[i2] = v; //建立該頁號與對應(yīng)span的映射
}
//確保映射[start,start_n-1]頁號的空間是開辟好了的
bool Ensure(Number start, size_t n)
{
for (Number key = start; key <= start + n - 1;)
{
const Number i1 = key > > LEAF_BITS;
if (i1 >= ROOT_LENGTH) //頁號超出范圍
return false;
if (root_[i1] == NULL) //第一層i1下標指向的空間未開辟
{
//開辟對應(yīng)空間
static ObjectPool< Leaf > leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
key = ((key > > LEAF_BITS) + 1) < < LEAF_BITS; //繼續(xù)后續(xù)檢查
}
return true;
}
void PreallocateMoreMemory()
{
Ensure(0, 1 < < BITS); //將第二層的空間全部開辟好
}
};
測試與總結(jié)
以下是測試代碼,來對比我們寫的內(nèi)存池與malloc和free的效率
// ntimes 一輪申請和釋放內(nèi)存的次數(shù)
// rounds 輪次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector< std::thread > vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector< void* > v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u個線程并發(fā)執(zhí)行%u輪次,每輪次malloc %u次: 花費:%u msn",
nworks, rounds, ntimes, malloc_costtime);
printf("%u個線程并發(fā)執(zhí)行%u輪次,每輪次free %u次: 花費:%u msn",
nworks, rounds, ntimes, free_costtime);
printf("%u個線程并發(fā)malloc&free %u次,總計花費:%u msn",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
// 單輪次申請釋放次數(shù) 線程數(shù) 輪次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector< std::thread > vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector< void* > v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(ConcurrentAlloc(16));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u個線程并發(fā)執(zhí)行%u輪次,每輪次concurrent alloc %u次: 花費:%u msn",
nworks, rounds, ntimes, malloc_costtime);
printf("%u個線程并發(fā)執(zhí)行%u輪次,每輪次concurrent dealloc %u次: 花費:%u msn",
nworks, rounds, ntimes, free_costtime);
printf("%u個線程并發(fā)concurrent alloc&dealloc %u次,總計花費:%u msn",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
int main()
{
size_t n = 10000;
cout < < "==========================================================" < < endl;
BenchmarkConcurrentMalloc(n, 4, 10);
cout < < endl < < endl;
BenchmarkMalloc(n, 4, 10);
cout < < "==========================================================" < < endl;
return 0;
}
測試中遇到的問題
1.總結(jié)一下測試過程中的一些問題,剛開始我們是以指定的一個固定大小進行不斷的測試,發(fā)現(xiàn)效率很低,其根本原因是因為我們指定了固定大小,每次都往那一個桶里拿數(shù)據(jù),釋放數(shù)據(jù),不停的加鎖與解鎖,影響了效率。
2.我們沒有考慮一種情況,當內(nèi)存大于128K的時候,我們此時應(yīng)該給它進行一步優(yōu)化。
//不再申請threadache,直接找pageache,讓它向系統(tǒng)申請
static void* ConcurrentAlloc(size_t size)
{
if (size > MAX_BYTES) //大于256KB的內(nèi)存申請
{
//計算出對齊后需要申請的頁數(shù)
size_t alignSize = SizeClass::RoundUp(size);
size_t kPage = alignSize > > PAGE_SHIFT;
//向page cache申請kPage頁的span
PageCache::GetInstance()- >_pageMtx.lock();
Span* span = PageCache::GetInstance()- >NewSpan(kPage);
PageCache::GetInstance()- >_pageMtx.unlock();
void* ptr = (void*)(span- >_pageId < < PAGE_SHIFT);
return ptr;
}
else
{
//通過TLS,每個線程無鎖的獲取自己專屬的ThreadCache對象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
cout < < std::this_thread::get_id() < < ":" < < pTLSThreadCache < < endl;
return pTLSThreadCache- >Allocate(size);
}
}
//獲取向上對齊后的字節(jié)數(shù)
static inline size_t RoundUp(size_t bytes)
{
if (bytes <= 128)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 1024)
{
return _RoundUp(bytes, 16);
}
else if (bytes <= 8 * 1024)
{
return _RoundUp(bytes, 128);
}
else if (bytes <= 64 * 1024)
{
return _RoundUp(bytes, 1024);
}
else if (bytes <= 256 * 1024)
{
return _RoundUp(bytes, 8 * 1024);
}
else
{
//大于256KB的按頁對齊
return _RoundUp(bytes, 1 < < PAGE_SHIFT);
}
}
//pageage 直接找堆申請
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0);
if (k > NPAGES - 1) //大于128頁直接找堆申請
{
void* ptr = SystemAlloc(k);
Span* span = new Span;
span- >_pageId = (PAGE_ID)ptr > > PAGE_SHIFT;
span- >_n = k;
//建立頁號與span之間的映射
_idSpanMap[span- >_pageId] = span;
return span;
}
}
//釋放
static void ConcurrentFree(void* ptr, size_t size)
{
if (size > MAX_BYTES) //大于256KB的內(nèi)存釋放
{
Span* span = PageCache::GetInstance()- >MapObjectToSpan(ptr);
PageCache::GetInstance()- >_pageMtx.lock();
PageCache::GetInstance()- >ReleaseSpanToPageCache(span);
PageCache::GetInstance()- >_pageMtx.unlock();
}
//....
}
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 大于128 page的直接還給堆
if (span- >_n > NPAGES-1)
{
void* ptr = (void*)(span- >_pageId < < PAGE_SHIFT);
SystemFree(ptr);
//delete span;
_spanPool.Delete(span);
return;
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32
VirtualFree(ptr, 0, MEM_RELEASE);
#else
// sbrk unmmap等
#endif
}
我們可以看到,經(jīng)過上面10輪的申請釋放內(nèi)存,我們寫的內(nèi)存池要比free和malloc的效率更加高。

-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3115瀏覽量
75053 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
7109瀏覽量
125096 -
程序
+關(guān)注
關(guān)注
117文章
3825瀏覽量
82544 -
計算機技術(shù)
+關(guān)注
關(guān)注
1文章
104瀏覽量
13537
發(fā)布評論請先 登錄
C++內(nèi)存池的設(shè)計與實現(xiàn)
【每日一練】第十六節(jié):內(nèi)存池的使用
內(nèi)存池可以調(diào)節(jié)內(nèi)存的大小嗎
內(nèi)存池的概念和實現(xiàn)原理概述
關(guān)于RT-Thread內(nèi)存管理的內(nèi)存池簡析
RT-Thread內(nèi)存管理之內(nèi)存池實現(xiàn)分析
刪除靜態(tài)內(nèi)存池是用rt_mp_detach還是rt_mp_delete
Linux 內(nèi)存池源碼淺析
LibTorch-based推理引擎優(yōu)化內(nèi)存使用和線程池
什么是內(nèi)存池

高并發(fā)內(nèi)存池項目實現(xiàn)
了解連接池、線程池、內(nèi)存池、異步請求池
如何實現(xiàn)一個高性能內(nèi)存池
內(nèi)存池的使用場景
nginx內(nèi)存池源碼設(shè)計





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論