 Backbone之戰:計算機視覺任務模型大比較
Backbone之戰:計算機視覺任務模型大比較
要解決的問題:
距離深度學習的突破之作AlexNet已過去10年之久,期間各種網絡架構層出不窮,那么作為研究者和實踐者,該如何選擇網絡架構?
解決方案:
通過對各種預訓練模型(包括視覺-語言模型、自監督學習模型等)在多種計算機視覺任務(如分類、對象檢測等)上的性能進行大規模比較,來幫助研究者和實踐者更好地選擇合適的模型。這就像是在各種預訓練模型中進行一場“角逐”,看看哪個模型的性能最好。
結論:
1、盡管Vision Transformer(ViTs)和自監督學習(SSL)越來越受歡迎,但在大多數任務中,文章發現在大型訓練集上以監督方式預訓練的卷積神經網絡仍然表現最好。
2、在相同的架構和類似大小的預訓練數據集上進行比較,文章發現SSL BackBone具有很高的競爭力,這表明未來的工作應該使用先進的架構和更大的預訓練數據集進行SSL預訓練。
關鍵詞:
BoB:Battle of the Backbones
ID:In-Distribution
OOD:Out-of-Distribution
1. 引言
影響BackBone網絡性能的三個主要因素是其架構、預訓練算法和預訓練數據集。在這三個設計維度上,都有許多選擇,為從業者構建計算機視覺系統提供了無數的組合。盡管有這么多的選擇,但是從業者卻沒有可參考的資源,只能自己測試各個BackBone網絡。
文章在“BackBone網絡之戰”中將這些BackBone網絡進行對比。文章比較了許多流行的公開可用的預訓練模型,還有隨機初始化的基線模型,在各種下游任務上進行評估,包括圖像分類、對象檢測、圖像檢索等。為了全面考察BackBone網絡的能力,文章評估它們在不同任務上的表現,這些任務分屬以下幾大類:
分類:文章測量BackBone在各種下游分類任務上的微調和線性探測性能,包括自然圖像、醫學和衛星圖像數據集。圖像分類任務需要BackBone網絡提取識別圖像前景內容的特征,而不需要定位對象在圖像中的具體數量和位置。
對象檢測和分割:不同于圖像分類,密集預測任務需要BackBone提取包含對象精確位置的特征,在分割任務中需要像素級別定位,在檢測任務中需要足夠細致地繪制邊界框。文章在這兩個任務上評估BackBone網絡。
域外泛化:在實際應用中,計算機視覺系統通常會被部署在不同于訓練數據分布的新數據上。即使是高性能模型,在域變化下也已知會失敗。因此,文章評估模型在新下游域的泛化能力。
圖像檢索:圖像檢索需要BackBone網絡通過特征空間中的相似度來匹配相似的圖像。文章探索需要根據語義內容、視覺相似度等不同標準匹配圖像的任務。
除了協助從業者構建計算機視覺系統之外,這個基準測試的另一個核心目標是幫助引導研究界朝著尋求設計更好的BackBone網絡的有益研究方向前進。BoB揭示了預訓練例程和架構的優勢和劣勢,揭示了常見的誤解和基本限制,以及改進的有希望的方向。下面,文章總結了幾個主要的研究結果,并討論了以前比較BackBone網絡的努力。
1.1 BackBone之戰:摘要
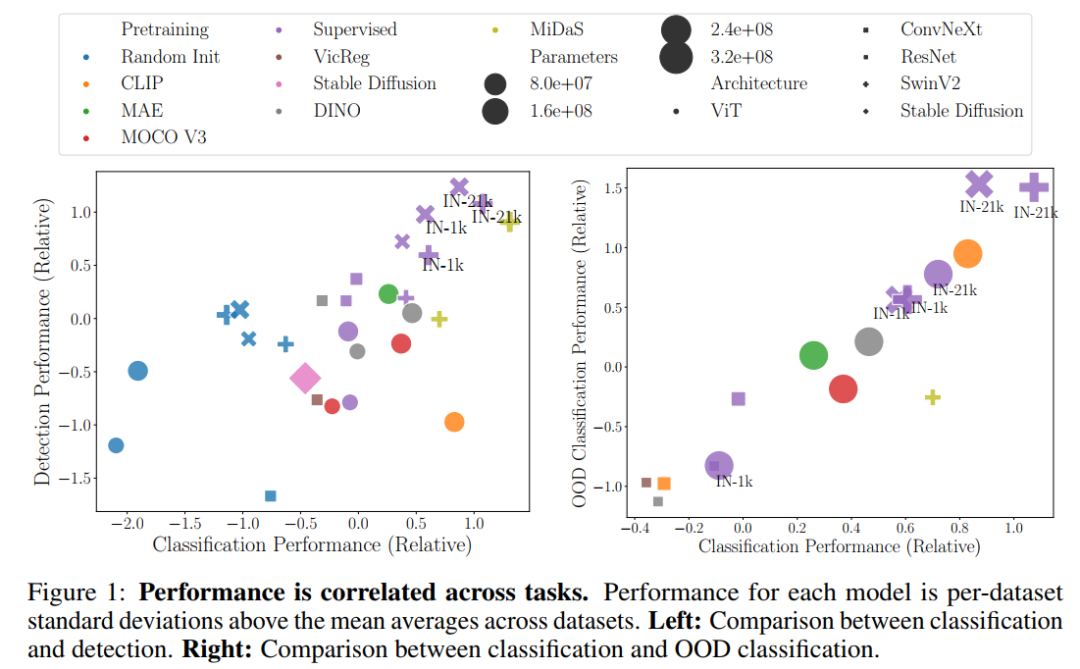
文章的后續部分包含了大量的實驗細節。因此,文章在下面提煉出幾個關鍵的發現:? 在BoB的一系列全面評估中,涵蓋了任務、數據集和設置(包括ID和OOD),在監督學習下,ConvNeXt-Base、SwinV2-Base(使用ImageNet-21k進行訓練)和CLIP ViT-Base表現最好。在較小的規模上,ConvNeXt-Tiny和SwinV2-Tiny獲勝,其次是DINO ViT-Small。? 盡管最近關注的焦點放在基于Transformer的架構和自監督學習上,但在文章考慮的大多數任務中,通過監督學習預訓練的高性能卷積網絡優于Transformer。? 觀察到監督預訓練的優越性是因為這些模型在更大的數據集上進行了訓練。在相同數據集規模上的比較中,自監督學習模型勝過其監督學習的對應模型。? ViT對預訓練數據量和參數數量的敏感性高于CNN。? 在任務間的性能存在強相關性 - 在BoB中表現最好的BackBone網絡往往在各種任務和設置中都表現出色。請參見圖1。
2. BoB指南
文章比較的BackBone之間的區別主要來自于它們的架構、預訓練算法和預訓練數據集。表1總結了文章要比較的BackBone,包括預訓練算法、粗略分類、預訓練數據集和架構。文章附錄B中詳細描述了每個算法、預訓練數據集和架構。
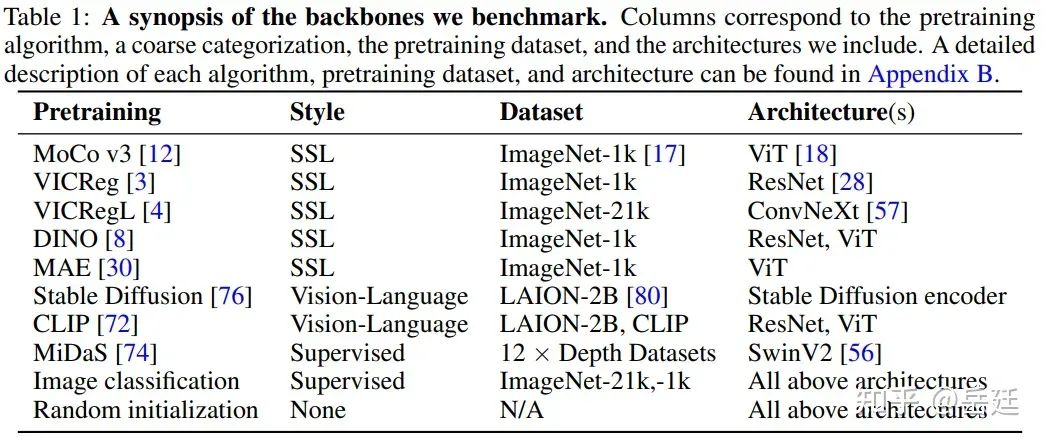
大小和公平比較的注意事項。許多從業者有限的計算資源,而且在自己的數據集上需要調優超參數而不超過計算預算。為了模擬這種場景,文章進行適度的超參數網格搜索,不允許特別長的訓練計劃,并且不考慮比ConvNeXt-Base更大的架構,除了Stable DiffusionBackBone,因為它只有一個尺寸。具體的超參數網格在后續章節詳細說明。此外,文章僅使用公開可用的checkpoint,這些checkpoint對從業者也是可訪問的。可用的checkpoint進行了不同程度的超參數調優,不同的預訓練算法在不同的數據集和架構上進行了訓練,所以精確的公平比較是不可行的。盡管如此,這種現有checkpoint的比較對從業者是相關的,因為它代表著現實的條件。文章在下游任務上為每個BackBone使用相同大小的超參數掃描。
2.1 任務
為了全面檢驗BackBone網絡的能力,文章評估它們在許多下游任務上的表現,這些任務分屬以下幾類:
分類:在3.1節中測量BackBone在各種下游分類任務上的微調和線性探測性能,包括自然圖像、醫學和衛星圖像數據集。圖像分類任務需要BackBone網絡提取識別圖像前景內容的特征,而不需要定位對象在圖像中的具體數量和位置。
對象檢測和分割:不同于圖像分類,3.2節中的密集預測任務需要BackBone提取包含對象精確位置的特征,在分割任務中需要像素級別定位,在檢測任務中需要足夠細致地繪制邊界框。文章在這兩個任務上評估BackBone網絡。
域外泛化:3.3節中,除了評估BackBone在各種下游任務上的域內性能,文章還考察這種性能如何轉換到域外設置。
圖像檢索:圖像檢索需要BackBone網絡通過特征空間中的相似度來匹配相似的圖像。在3.4節中探索需要根據語義內容、視覺相似度等不同標準匹配圖像的任務。
3. 實驗設置
文章現在描述每個任務的實驗設置。具體來說,文章列出學習方案、數據集和評估指標。完整的實驗和實現細節請見附錄C。
3.1 分類
學習方案。文章使用兩個微調方案評估預訓練BackBone在各種數據集上的性能:端到端微調(包括只使用少量標記樣本的實驗)和線性探測。在前一種情況下,文章在給定的數據集或它的一部分上端到端微調整個模型,并在測試分割上測量準確率。在線性探測場景中,文章從凍結的預訓練BackBone中提取特征,并僅在這些預訓練表示上學習一個線性分類器。這兩種方案在之前的工作中被廣泛使用來評估自監督學習等預訓練方法,如在自監督視覺表示學習[12, 30, 8, 10]和視覺語言預訓練[1, 105]中。
數據集和評估指標。文章在6個常見的圖像分類數據集上進行實驗,涵蓋自然圖像(ImageNet-1K [17], CIFAR-100 [46], Flowers-102 [64], Aircraft [60])、衛星圖像(EuroSAT [31])和醫學X射線數據(CheXpert [37]),展示預訓練BackBone的泛化性和遷移性。文章使用的所有數據集都是公開可用的,文章在附錄C中列出了它們的詳細信息,包括大小和類別數。在只使用訓練集的一部分進行微調的實驗中,文章隨機采樣1%和10%的訓練樣本進行微調。在采樣子集時,文章保持原始數據集的標簽分布。注意,文章這里只考慮域內泛化,其中訓練和測試集來自同一來源。
評估時,文章使用分類準確率和ROC曲線下面積(AUC)作為單標簽和多標簽分類任務的性能指標。除了超參數向量之間最佳的得分之外,文章還繪制前幾個時期的準確率,以顯示不同預訓練BackBone的收斂率。此外,文章在同一設備上基準測試每個BackBone的延遲和內存使用情況。
3.2 對象檢測和分割
學習方案。對于對象檢測和實例分割的評估,文章采用Cascade Mask R-CNN框架[5]。文章使用三種方案進行實驗:(1)從隨機初始化進行端到端訓練,(2)使用預訓練BackBone進行端到端微調,(3)使用凍結的BackBone進行微調。雖然用凍結的BackBone進行微調在檢測和分割中不典型,但后一種方案允許文章探測預訓練模型的特征中包含的定位信息,并與線性探測分類實驗互補。參見附錄C.1關于ViT,尤其是大型ViT,在更昂貴的訓練方案下可能超過其他模型性能的討論。
數據集和評估指標。文章在流行的COCO數據集[53]上進行對象檢測和實例分割評估。文章遵循COCO式的平均精度(AP)指標,該指標在各種Intersection over Union(IoU)閾值上進行平均。文章報告邊界框平均精度(box AP)、box AP@50和AP@75用于對象檢測,以及掩膜平均精度(mask AP)、mask AP@50和mask AP@75用于實例分割[54]。
3.3 域外泛化
盡管現代網絡在它們訓練的數據分布上可能展示出強大的性能,但大量的以前的工作[70, 32]發現,這種模型的性能在分布發生變化時可能會顯著下降。除了評估BackBone在各種下游任務上的域內性能之外,文章還研究這種性能如何轉換到域外(OOD)設置。
學習方案。幾個特定任務的數據集和基準已被提出來評估模型對其訓練分布偏差的穩健性。具體來說,文章研究經過訓練的BackBone在兩個任務上的泛化性能,即(1)圖像分類和(2)對象檢測,以及兩種類型的分布轉移,(A) ImageNet內部的結構和樣式變化以及(B) 從合成到真實的泛化。
數據集和評估指標。文章考慮以下廣泛的OOD評估基準:
(A)對結構和樣式的變化的穩健性。文章測量在ImageNet上訓練或微調的模型在以下基準上的OOD泛化:
(i) ImageNet-A [34]。ImageNet-A(dversarial)包含ImageNet測試圖像的200個類別的策略性子集,這些圖像對訓練好的深度模型具有特定挑戰性。
(ii) ImageNet-V2 [75]。ImageNet-V2是在原始數據集收集后10年按照完全相同的收集方案構建的額外的與ImageNet類似的測試集。
(iii) ImageNet-R [33]。ImageNet-R(endition)包含200個來自ImageNet的類別的藝術Rendering,包括卡通、涂鴉、刺繡、折紙、雕塑等。
(iv) ImageNet-S [92]。ImageNet-S(ketch)是從ImageNet類別中網絡爬取并人工清理的黑白素描圖像集合。
(B) 從合成到真實的泛化。文章還測量在合成數據上訓練并在真實數據上測試的模型的性能。合成數據已成為一種流行的替代方法,用于在采集真實世界中可靠注釋的數據很難或很貴的情況下。文章在以下兩個流行基準上測量從合成到真實的泛化,用于圖像分類和對象檢測:
(i) VisDA Syn→Real。VisDA分類基準由約152k張合成圖像和約55k張真實圖像組成,跨12個類別。VisDA中的合成圖像是對象從多個視點在不同照明條件下的3D渲染。真實圖像是從COCO數據集中裁剪的12個類別的作物。
(2) Sim10k→Cityscapes。對于對象檢測,文章使用Sim10k作為合成訓練數據集,使用Cityscapes作為真實評估數據集。Sim10k由來自GTAV的約10k張街景圖像組成。Cityscapes由約5k張密集注釋的街景圖像組成,這些圖像是從車輛視角拍攝的現實世界圖像。遵循以前的工作[13],文章在整個Sim10k上進行訓練,以檢測“汽車”的實例,并在Cityscapes的驗證分割上測量檢測性能。
對于圖像分類,文章報告在OOD測試集上的分類準確率;對于對象檢測,文章報告mAP@50的泛化性能。
3.4 圖像檢索
文章在各種圖像檢索數據集上進行評估,包括基于內容的圖像檢索和分類數據集,文章將它們改造為語義檢索任務。對于地理地標檢索,文章利用牛津數據集[68]和巴黎數據集[69]。為確保準確性,文章使用這些數據集的修正標簽版本[71]。INSTRE數據集[94]由放置在不同位置和條件下的玩具和形狀不規則的產品組成。為了檢驗細粒度的檢索,文章采用Caltech-UCSD Birds-200數據集(CUB-200)[90],其中包含在不同背景、姿勢和照明條件下拍攝的各種鳥類。對于多樣化的自然圖像,文章使用iNaturalist數據集[87]。這個數據集提供了一個廣泛的細粒度類別,被分類到13個超類,包括植物、昆蟲、鳥類和哺乳動物。為了評估真實場景下的檢索性能,文章采用Objectnet數據集[2]。該數據集由313個對象類組成,具有隨機變化的背景、旋轉和成像視角。對于大規模地標識別,文章利用谷歌地標V2數據集[98],其中包含約20萬個獨特地標。最后,文章采用INRIA Copydays數據集[19],其中包含一小部分度假照片。
在上述數據集中,iNaturalist、Objectnet和CUB-200可以分類為語義檢索數據集,而其余數據集屬于基于內容的檢索數據集。
文章使用平均精度或mAP[67]來評估模型性能。文章首先計算給定查詢圖像的平均精度,然后計算所有查詢的平均值以找到mAP。文章還測量Recall@k,它測量返回第一個正確匹配之前的結果數量,并計算這些未命中值的倒數的平均值MRR(平均互反等級)。對于所有指標,值越高越好。
4 從業者。應該選擇哪個BackBone網絡?
如今的從業者可以從各種大小、訓練方法和預訓練數據的大量BackBone網絡中進行選擇:從業者應該為某項特定任務或一般情況選擇哪個BackBone網絡?為了回答這個問題,在BoB中,文章系統地比較了各種公開可用的BackBone網絡(參見表1),橫跨多個任務、數據集和設置。為了進行這些比較,文章使用以下排名方案:
(1) 設置特定的Z分數。對于特定任務和設置(例如ImageNet上的Top-1分類精度),文章首先為所有正在評估的BackBone計算z分數 - 即,對于特定性能(例如準確性)值${x_i}^N_{i=1}$,z分數計算為${ (x_i - μ) / σ }^N_{i=1}$,其中μ和σ分別是樣本的平均值和標準差。這允許文章測量一個特定BackBone相對于該設置中所有BackBone的“平均”性能好多少(標準差以上或以下)。
(2) 跨設置比較。為了在不同任務和設置之間比較BackBone,文章簡單地聚合和比較之前獲得的z分數以獲得一個相對(粗略)的BackBone排名。
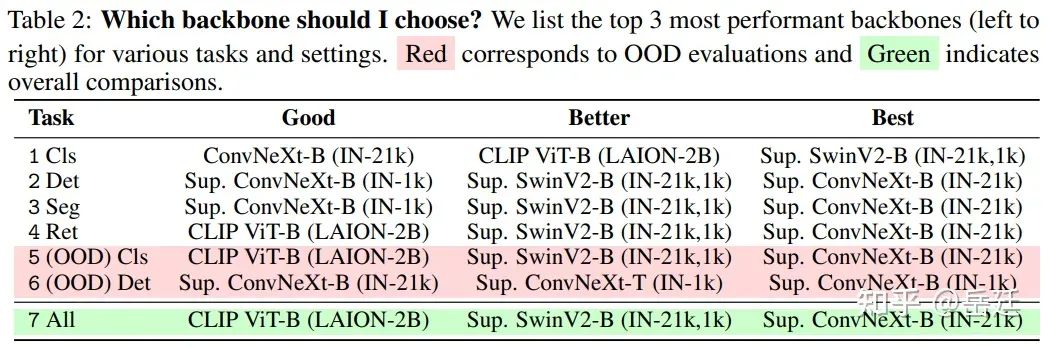
使用排名,文章不僅可以報告每個任務的最佳表現BackBone,還可以報告跨任務、數據集和設置的整體表現最佳的BackBone(見表2摘要)。
4.1 特定任務的BackBone網絡
分類。在多個數據集和實驗設置(微調、線性探測、完整和低樣本訓練)中,文章發現“在IN-21k上監督訓練的SwinV2-Base(在IN-1k上微調)”是表現最佳的BackBone網絡,其次是“CLIP ViT-Base”和“在IN-21k上監督訓練的ConvNeXt-Base”(見第1行,表2)。
對象檢測和分割。對于對象檢測和實例分割,文章發現“在IN-21K上監督訓練的ConvNeXt-Base” > “在IN-21k上監督訓練的SwinV2-Base(在IN-1k上微調)” > “在IN-1k上監督訓練的ConvNeXt-Base”。
圖像檢索。對于圖像檢索,文章發現“在IN-21k上監督訓練的ConvNeXt-Base”是最佳選擇,其次是“在IN-21k上監督訓練的SwinV2-Base(在IN-1k上微調)”和“在LAION-2B上訓練的CLIP ViT-B”。
(OOD)分類。在各種OOD評估中,文章發現“在IN-21k上監督訓練的ConvNeXt-Base” > “在IN-21k上監督訓練的SwinV2-B(在IN-1k上微調)” > “在LAION-2B上訓練的CLIP ViT-Base”。
(OOD)對象檢測。對于從合成到真實的對象檢測,文章發現“在IN-1k上監督訓練的ConvNeXt-Base”是最佳BackBone,其次是“在IN-1k上監督訓練的ConvNeXt-Tiny”和“在IN-21k上監督訓練的ConvNeXt-Base”。
4.2 整體最佳的BackBone網絡
對于沒有具體任務需求的從業者,整體表現最好的模型是“在IN-21k上監督訓練的ConvNeXt-Base”,其次是“在IN-21k上監督訓練的SwinV2-Base(在IN-1k上微調)”和“在LAION-2B上訓練的CLIP ViT-Base”。總體來說,文章注意到以監督方式訓練的BackBone(SwinV2-Base、ConvNeXt-Base)或具有視覺語言監督的BackBone(CLIP ViT-Base)優于其他BackBone。此外,文章發現CLIP ViT-Base緊隨在IN-21k上監督訓練的ViT-Base(在IN-1k上微調)之后。
4.3 預算有限的BackBone網絡
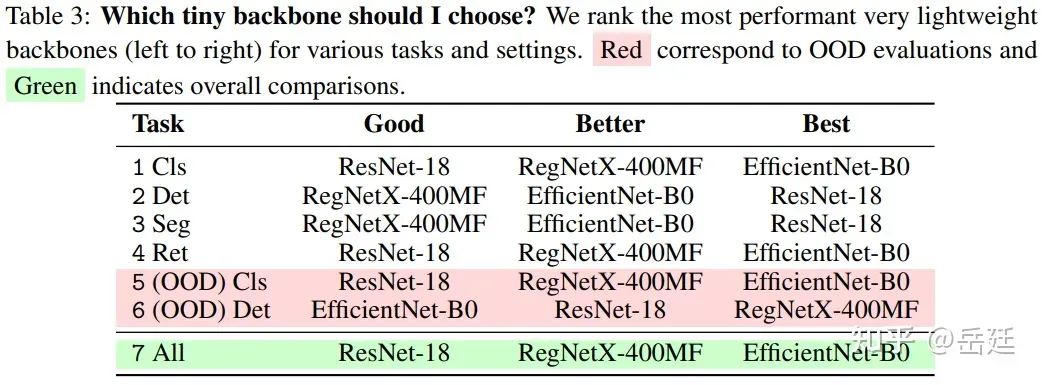
許多計算機視覺應用需要高效的BackBone網絡以實現快速或設備端推理。在這一節中,文章對三個小BackBone進行基準測試:在ImageNet-1k上以監督方式預訓練的RegNetX-400F [73]、EfficientNet-B0 [83]和ResNet-18 [28]。文章在表3中對這些小BackBone在一系列任務上的性能進行了排名。文章發現在整體和分類、檢索、OOD分類方面,EfficientNet-B0的表現最好,其次是RegNetX-400MF,然后是ResNet-18。有趣的是,在檢測和分割方面,新型高效架構仍不如ResNet。
5 觀察結果和趨勢
ViT和CNN的性能比較。現代架構明顯優于普通ViT。文章在表2中看到,最佳性能的BackBone網絡(ConvNeXt-Base)是卷積的,其次是具有分層transformer的架構(SwinV2-Base)。后者融合了強大的空間歸納偏置。這些發現表明,社區應該放棄仍在廣泛使用的普通ViT。需要說明的是,文章沒有評估非常大的模型,在更大的規模下,ViT可能會勝過其其他變體或卷積網絡。
ViT比CNN更依賴規模。對于BoB中考慮的BackBone組,文章發現參數數量的相對性能(z分數)對ViT(斯皮爾曼相關系數 = 0.58)的正相關性高于CNN(斯皮爾曼相關系數 = 0.35)。類似地,而整體相對性能與預訓練數據的規模相關,這個相關性對ViT (ρ = 0.72)也明顯高于CNN (ρ = 0.33)。這個觀察表明,基準測試更大的BackBone可能產生不同的贏家,可能是具有基于transformer的架構。
監督或不監督?監督學習BackBone占主導地位,但主要是因為它們可以在更大的數據集上預訓練。在相似大小的數據集上,SSLBackBone可以勝過其監督對手。文章得到每個預訓練方式的前3個BackBone的平均分數,即自監督、用ImageNet-1K監督和用ImageNet-21K監督(見附錄D)。在IN-21K上用監督學習預訓練的ConvNeXt和SwinV2在所有任務上都優于SSLBackBone。結果表明,文章應該嘗試將SSL方法與先進的架構相結合,并在大數據集上進行訓練以與監督學習競爭。在這些實驗中,監督預訓練的checkpoint通常可在更大的數據集(ImageNet-21k)上獲得。當比較在類似大小數據集上預訓練的模型時,SSL或視覺語言預訓練方法在分類(域內和域外)和檢索任務上獲得了更好的性能,這些任務高度依賴于學習的表示。然而,監督學習BackBone在檢測和分割方面保持決定性優勢。文章還可以比較使用相同ViT-Base架構的BackBone,發現SSL方法確實優于ImageNet-1k監督BackBone,但比ImageNet-21k訓練的BackBone差。
任務之間的性能高度相關。在文章考慮的任務對中,文章發現任務對之間的性能存在高度正相關(通常ρ> 0.8)。這一發現支持通用基礎模型在計算機視覺中的當前趨勢。此外,這一發現也支持最近的工作,該工作認為單一的歸納偏差可以解決一系列看似不同的問題[24]。然而,值得注意的是,檢索任務與分類和檢索排名之間的相關性相對較低但仍具有統計意義(ρ = 0.49)。這種較低的相關性可以歸因于MiDaS和MAE預訓練模型在檢索方面的性能限制。在刪除這兩個BackBone后,相關系數ρ增加到0.8,這進一步證明了上述模型對觀察結果的影響。
Transformer在端到端微調下表現優異,而卷積網絡在線性探測下表現優異。對于“線性探測”實驗,文章凍結預訓練BackBone,僅學習頭部。請注意,對于檢測和分割,頭部不僅是一個線性層。通過檢查兩種微調策略之間的性能差異(圖2),文章發現ViT從端到端微調中受益明顯多于CNN,無論是在監督預訓練還是自監督預訓練下。參見圖2中的在密集預測任務上的比較。
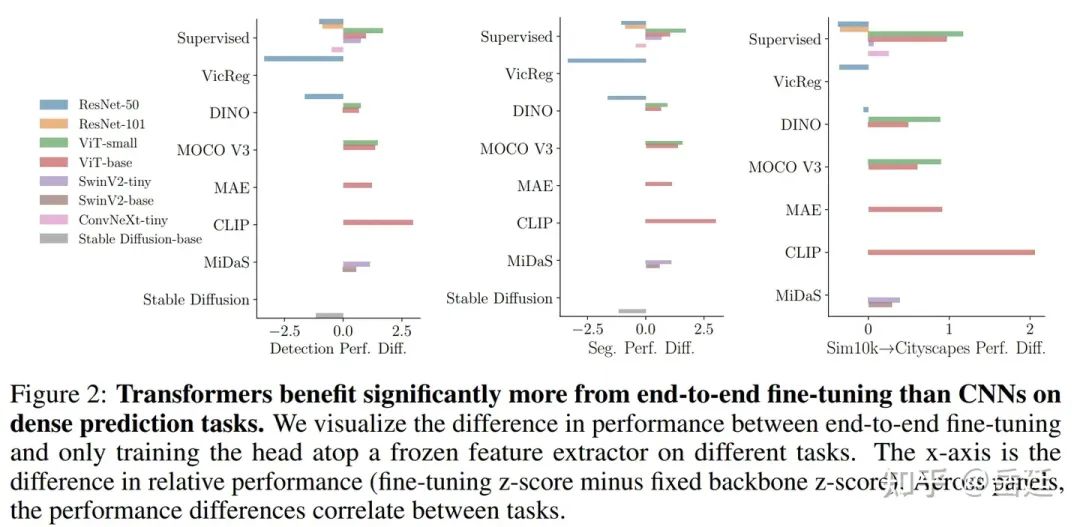
CLIP模型以及視覺語言建模中先進架構的前景。對于幾乎所有任務(OOD檢測除外),CLIP預訓練優于普通視覺transformer,即使與在ImageNet-21k上監督訓練的BackBone相比也是如此。在所有BackBone中,CLIP僅次于在IN-21k上訓練的SwinV2和ConvNeXt,這顯示了視覺語言預訓練的力量,并再次表明,在進行自監督或弱監督學習時,文章應考慮除普通ViT之外的更多BackBone架構。
生成BackBone怎么樣?與用監督或自監督方法和對比損失訓練的模型相比,用生成對抗目標訓練的BackBone,如MAE或Stable Diffusion,其性能相對較差。文章建議謹慎解釋這個結果,因為目前僅對Stable Diffusion在有限的任務上進行了評估。盡管如此,Stable Diffusion是一個更大的BackBone,并在一個非常大的數據集上訓練,但它展示了比文章考慮的其他模型差的性能。
“小”BackBone之戰。考慮到有限的資源,文章還比較了BoB中“小”BackBone的子集(參數< 30M)—— ViT-Small、ConvNeXt-Tiny、Swin-Tiny和ResNet-50架構。總體而言,文章發現在IN-1k上監督訓練的ConvNeXt-T表現最好,其次是在IN-1k上監督訓練的SwinV2-T,然后是在IN-1k上訓練的DINO ViT-S。有趣的是,監督學習在這里再次占據主導地位,而且僅在IN-1k上預訓練的BackBone勝過在考慮得多更大的數據集上訓練的BackBone(MiDaS)。
性能與速度?文章的分析顯示,在相同的NVIDIA RTX A5000上計算的吞吐量與平均性能z分數之間存在較強的負相關(ρ = -0.41)。考慮每個BackBone時,這一發現與文章之前的觀察一致,即更大的模型往往具有更優越的性能。因此,為了獲得增強的性能,可能需要犧牲速度。
單目深度估計作為通用預訓練策略。在文章的實驗中,即使在自然圖像域之外,例如在衛星圖像上,MiDaS也達到了與頂級傳統監督和自監督學習BackBone相媲美的性能,在圖像分類、對象檢測和分割方面。這個觀察表明,深度估計可以作為強大和通用的主要或輔助預訓練任務。
校準和測試似然與準確率相關。在ImageNet測試集上,文章測量了期望校準誤差(ECE)以及交叉熵損失。而測試似然與準確率高度相關(r = -0.8278),ECE的相關較弱(r = -0.4876)。在兩種情況下,文章都觀察到p值低于0.05。文章還注意到,自監督預訓練通常會導致較差的校準。
CNN和SSL對對抗攻擊更具魯棒性。文章還使用受$l_∞$約束的PGD對抗攻擊,以多個半徑(見附錄表19)測量每個BackBone在ImageNet測試集上的對抗魯棒性。對于每個架構,當文章擁有自監督學習版本時,文章看到監督預訓練的魯棒性總是較差。此外,ViT比卷積網絡更容易受到對抗示例的攻擊。值得注意的是,即使在監督訓練下,ConvNeXt的對抗魯棒性也更強。
6 接下來會發生什么?
每個計算機視覺模型的核心是一個BackBone網絡。在文章的BackBone網絡對戰中,文章比較了1500多次訓練運行,以發掘對計算機視覺從業者和研究人員有益的見解。
為指導從業者,文章分析了在廣泛任務范圍內公開可用視覺BackBone的性能,從分割和檢測到分類和檢索。文章發現監督ConvNext、監督SwinV2和CLIP模型在這一廣泛任務范圍內性能良好。對于計算資源受限的設置,在文章的“小”BackBone之戰中,文章發現較小的對應的架構監督ConvNext-T和SwinV2效果好,其次是帶小ViT的DINO。BoB為從業者提供了從令人眼花繚亂的選擇中選擇合理BackBone的指南。
對于展望未來的研究人員,文章還觀察到幾個顯著趨勢。首先,文章發現跨任務的性能高度相關,這表明從專用視覺BackBone向通用BackBone的轉變,這些通用BackBone可以在各種任務上發揮良好作用。其次,文章發現吞吐量和性能之間存在反相關,這表明擴展仍然是提高BackBone的有希望途徑。最后,文章發現雖然文章的實際建議包括許多監督模型,但在與標準監督訓練的公平比較中,自監督學習很有前景。通過發布文章所有的實驗結果以及用于測試新BackBone的代碼,文章希望BoB能成為今天的從業者和研究明天問題的研究人員的有用指南。
局限性。文章指出,從BoB獲得的見解取決于在此工作中考慮的任務詞匯、BackBone網絡和設置。文章希望通過這項研究得出的結論能夠為計算機視覺研究人員提供實際的考慮因素,同時也認識到這些見解需要隨著引入更多的BackBone網絡、任務和設置而不斷發展。最后,文章指出,BoB中的研究主要集中在與性能相關的方面,對于其他重要方面(模型中的偏見等)的探索仍然存在。
文章的基準測試不包括比ConvNext-Base更大的BackBone網絡,除了穩定擴散(Stable Diffusion),一些排名可能在大規模上發生變化。例如,雖然文章發現現代經過監督學習預訓練的卷積網絡在大多數任務上表現最好,但文章也發現Transformer在規模上更有優勢,無論是在預訓練數據還是架構規模方面。在非常大的規模上,TransformerBackBone網絡有可能超過卷積BackBone網絡。
7 計算成本和碳足跡
文章中的實驗總計消耗了127k GPU小時的NVIDIA RTX A100卡。假設GPU的平均碳效率為每千瓦時0.37公斤CO2當量,則總排放量估計為11792.36公斤CO2當量[48]。
-
神經網絡
+關注
關注
42文章
4785瀏覽量
101311 -
計算機視覺
+關注
關注
8文章
1701瀏覽量
46181 -
數據集
+關注
關注
4文章
1212瀏覽量
24895
原文標題:NeurIPS 2023 | Backbone之戰:計算機視覺任務模型大比較
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是計算機視覺?計算機視覺的三種方法

機器視覺與計算機視覺的關系簡述
自動駕駛系統要完成哪些計算機視覺任務?
谷歌推出新的移動框架MobileNetV2提高多種計算機視覺任務
workflow的任務模型


最適合AI應用的計算機視覺類型是什么?





 工商網監
工商網監
評論