 自動駕駛環境感知——激光雷達物體檢測(chapter4)
自動駕駛環境感知——激光雷達物體檢測(chapter4)
1. 基本概念
相比于視覺間接地獲取3D信息,激光雷達可以直接獲取目標及場景的3D信息,但是激光雷達不能獲取紋理、顏色等特征,因此激光雷達和相機是互補的

調頻連續波是毫米波雷達測距的原理。
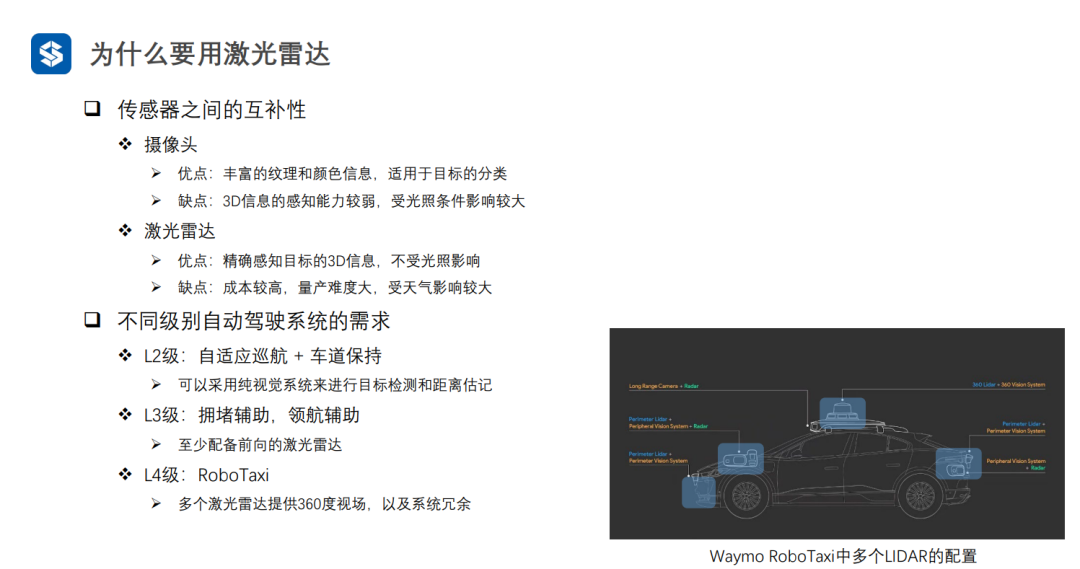
隨著自動駕駛級別的提高,對于激光雷達的需求也逐漸提高。


激光雷達不僅可以做到多視圖融合,還能進行多傳感器融合(此時是一個狀態估計問題,將不同傳感器的感知結果看成是觀測)。
2. 點云數據庫
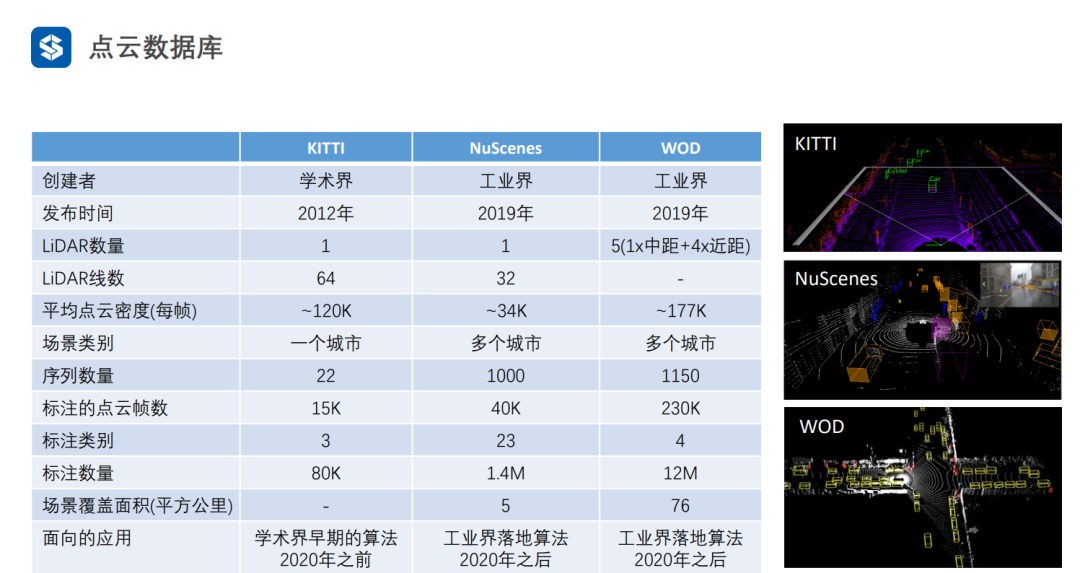
隨著工業界落地需求的增加,數據集的規模也越來越大。
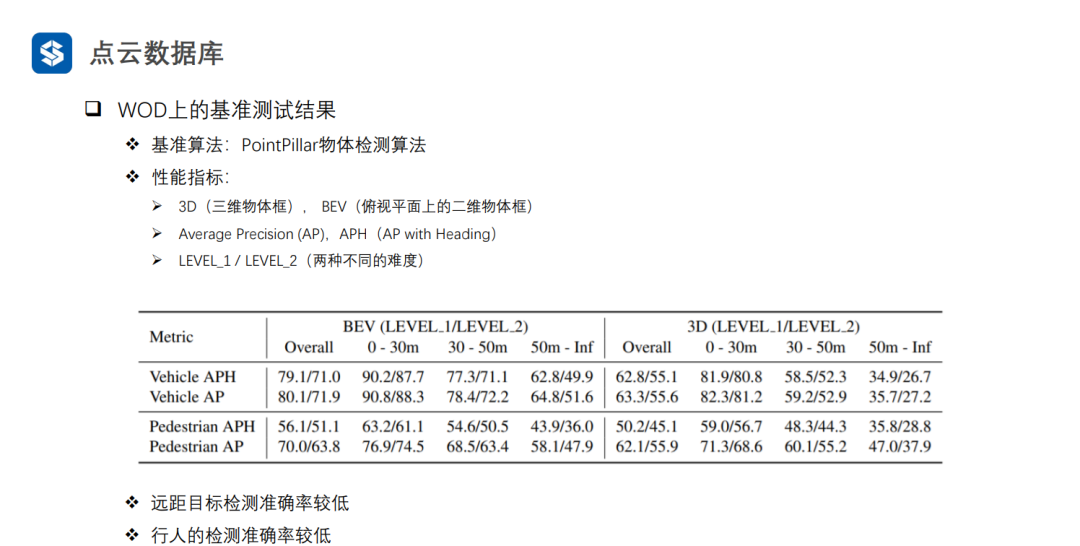
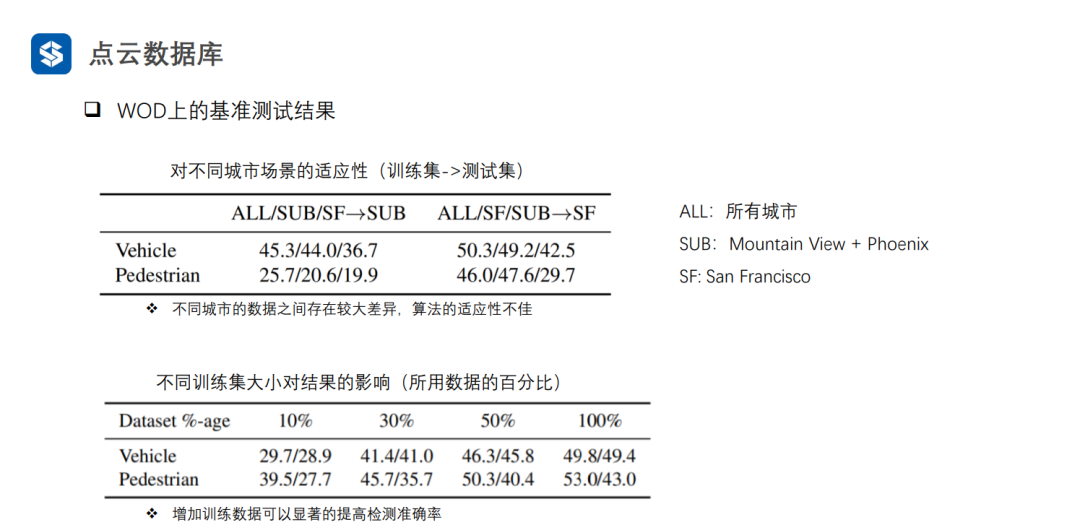
3. 物體檢測算法

3.1點視圖
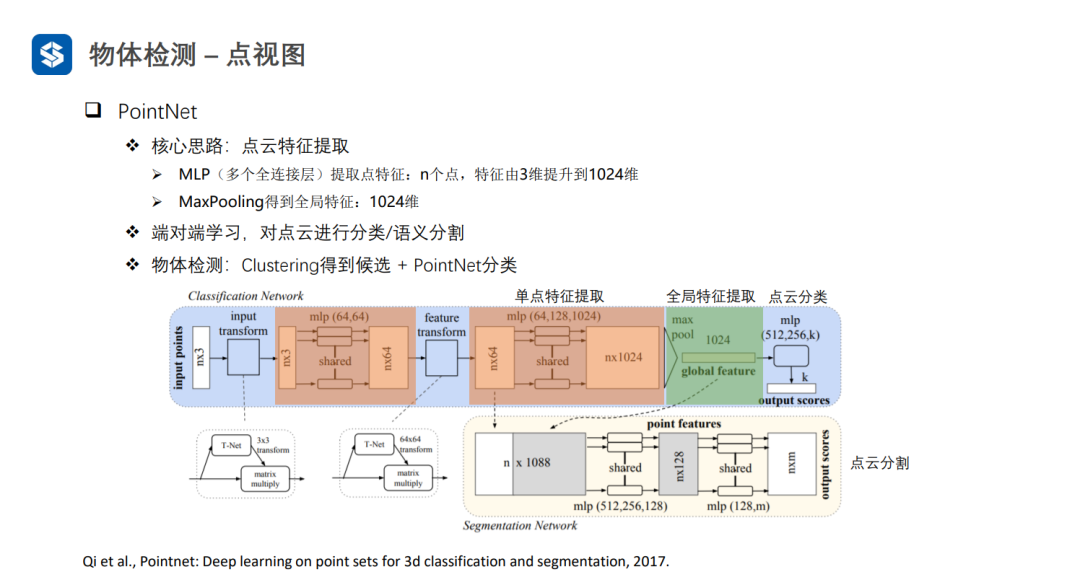

PointNet直接處理無序點云,因此在最后需要借助一個操作(例如max_poolingaverage_pooling)來消除最終的結果與點云輸入順序間的關聯
PointNet++逐層提取特征擴大感受野。PointNet++可以將聚類結果作為候選框生成的依據:對聚類結果中的每個點關聯一組錨框,并且進行分類與回歸的操作(類似RPN網絡)

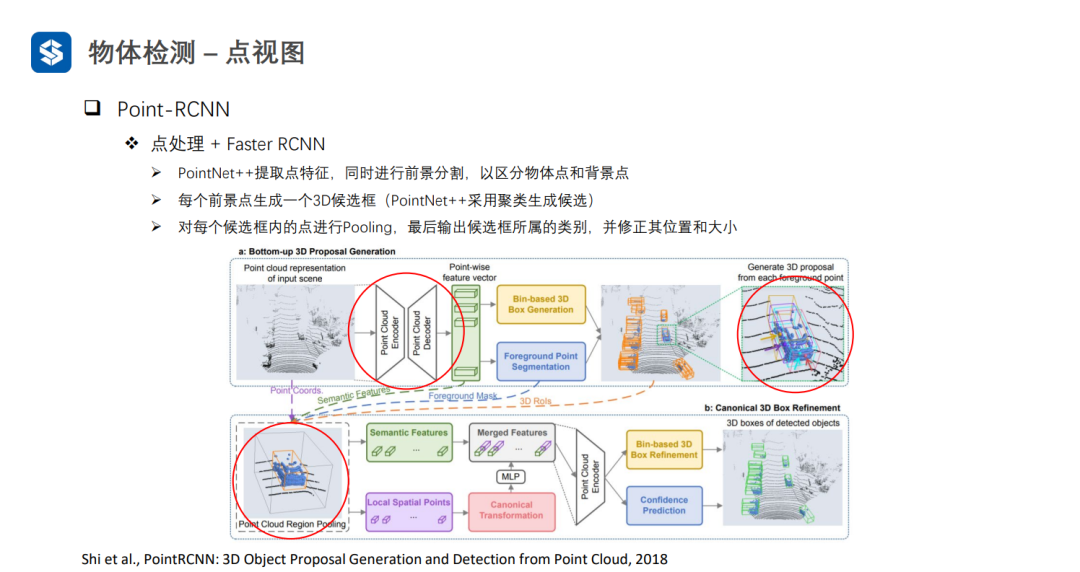
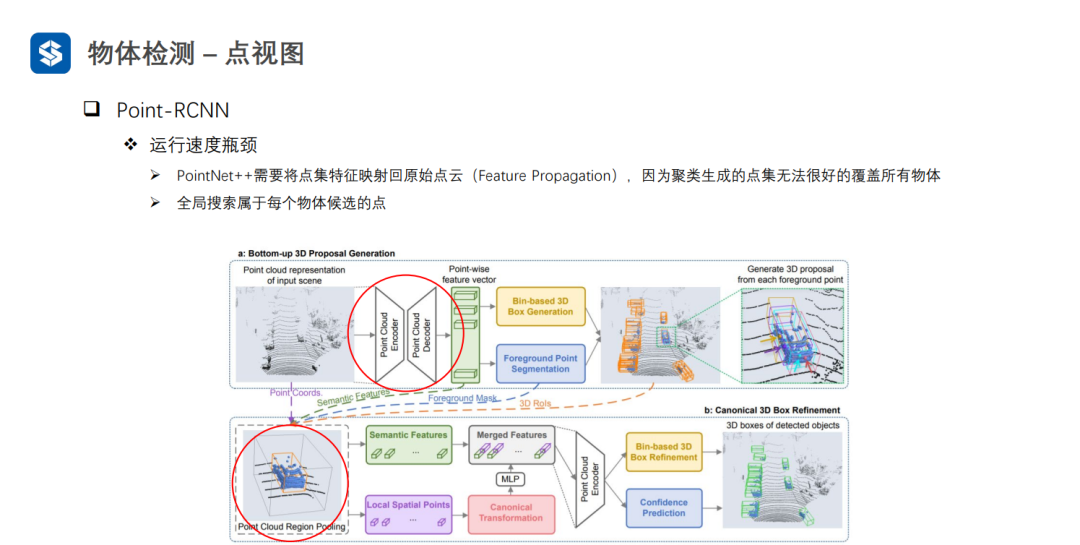
Point-RCNN通過前景分割的方式來避免耗時的聚類過程,但是也會存在較為耗時的全局搜索過程。

3D-SSD通過改進聚類的質量,直接在聚類結果上生成候選框。
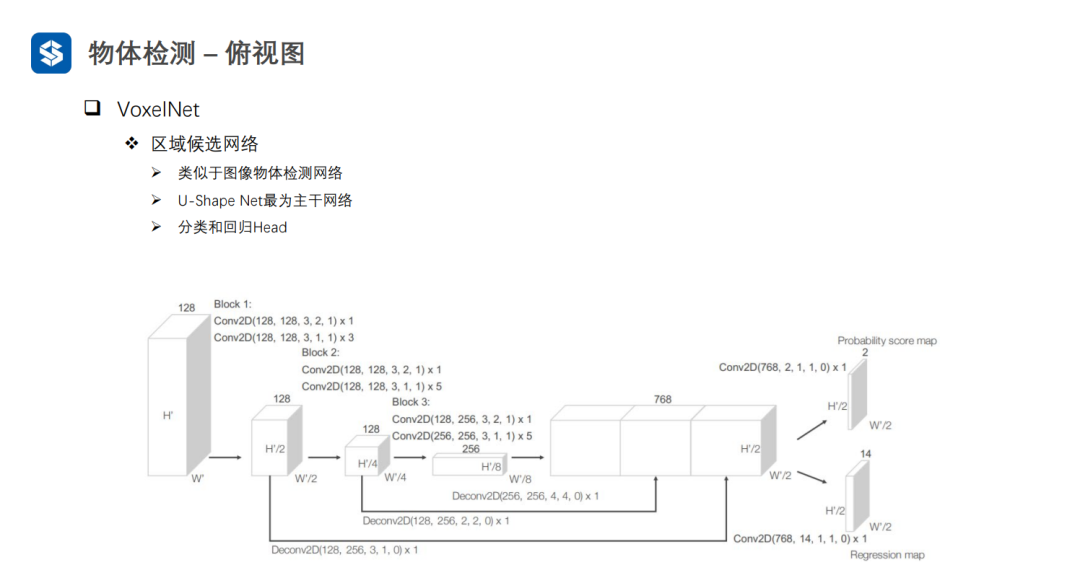
3.2俯視圖
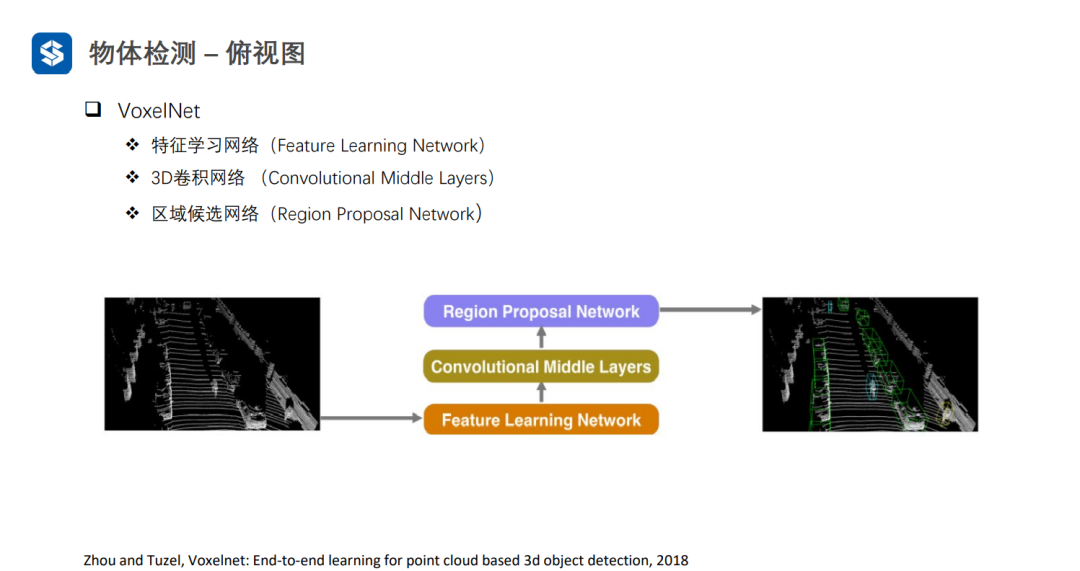
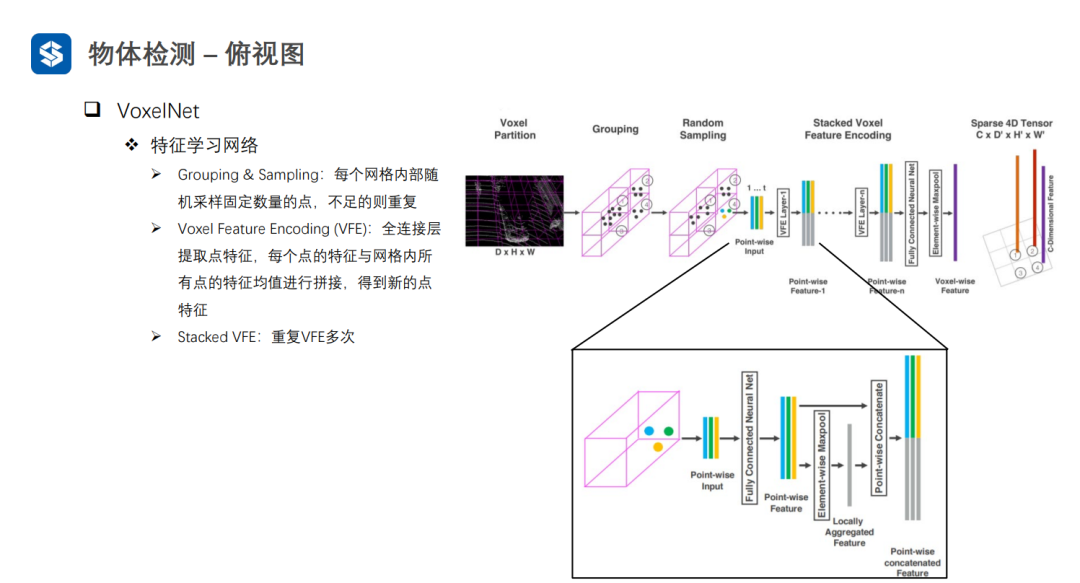
VoxelNet通過將三維空間劃分成體素,并在每個體素內進行特征提取,形成四維張量(D, H, W, C)。
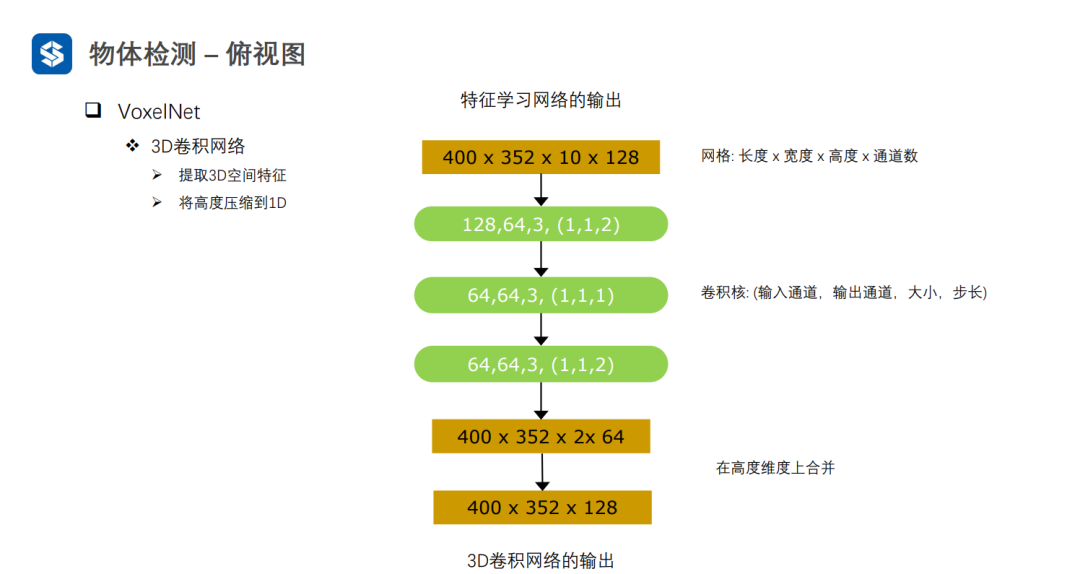
利用3D-CNN對四維張量進行特征提取,并將高度方向上壓縮為1D,得到三維張量(H', W', C')。最后,利用2D視覺感知算法進行檢測任務。

VoxelNet在劃分體素時,由于點云是稀疏的,會導致大量體素是空白的,這樣在進行3D卷積時會造成很多無效計算。
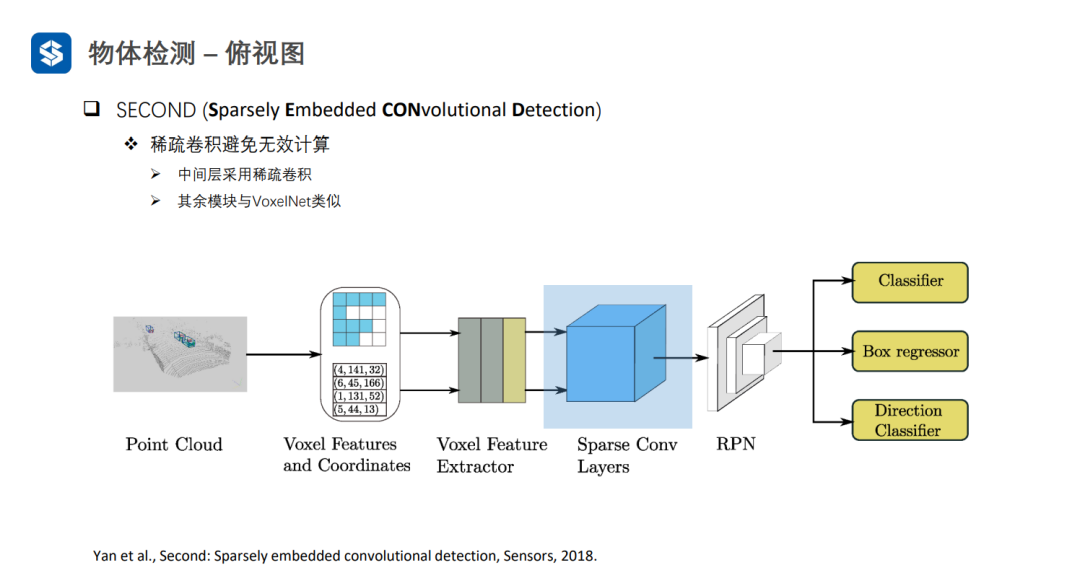
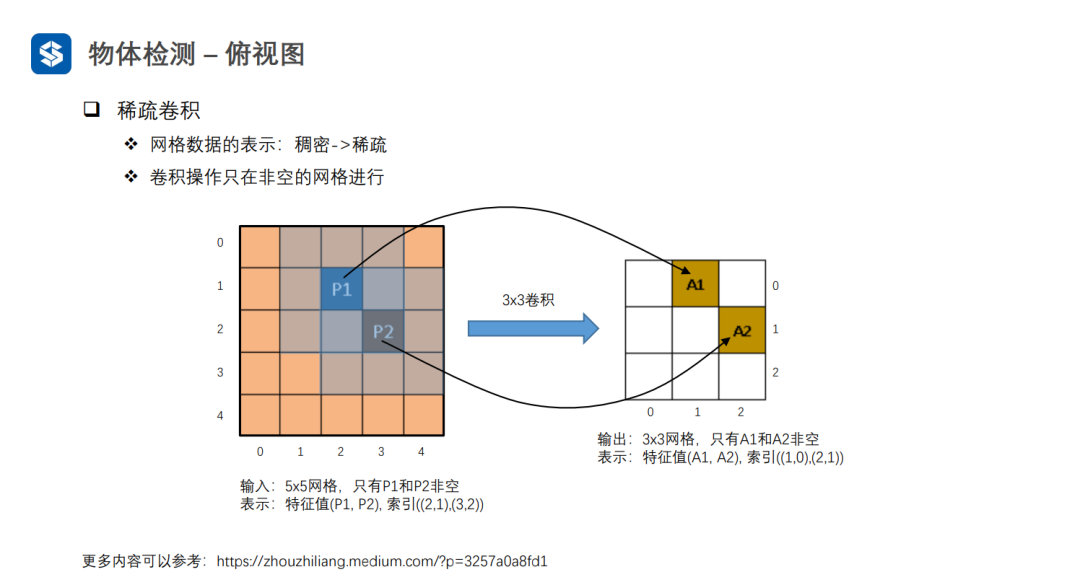
SECOND采用稀疏卷積避免空白體素區域的無效計算
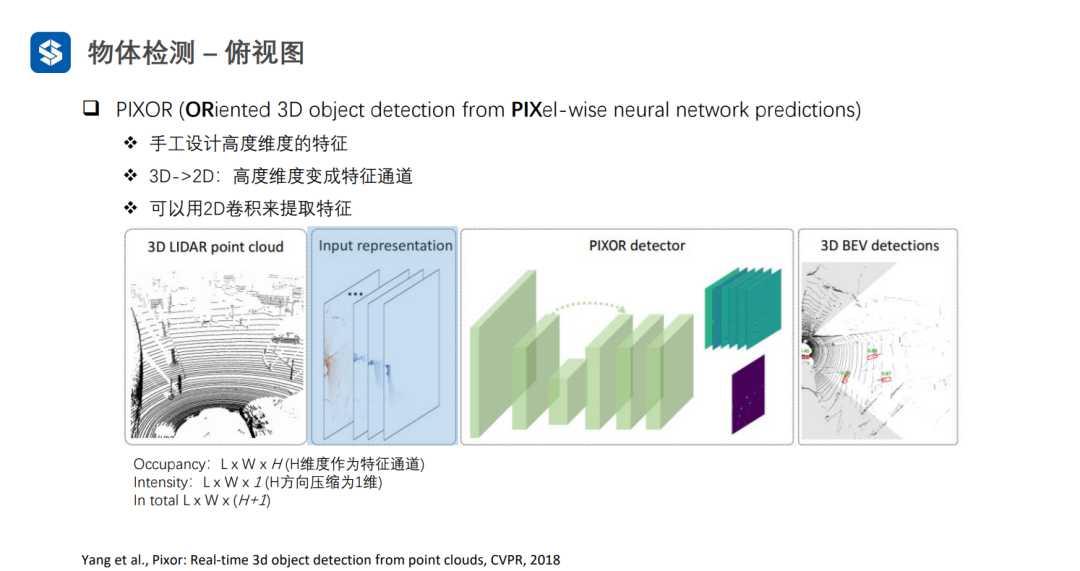
PIXOR將高度方向劃分為H個等級,如果有點云落在某個格子里,此處的Occupancy為1,且Intensity為格子里點云強度的均值。
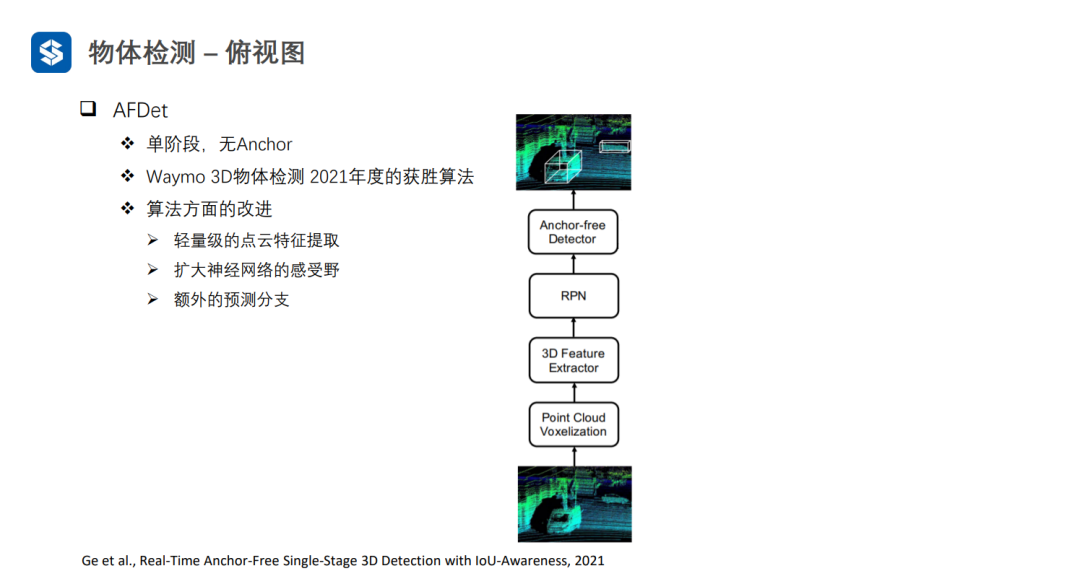
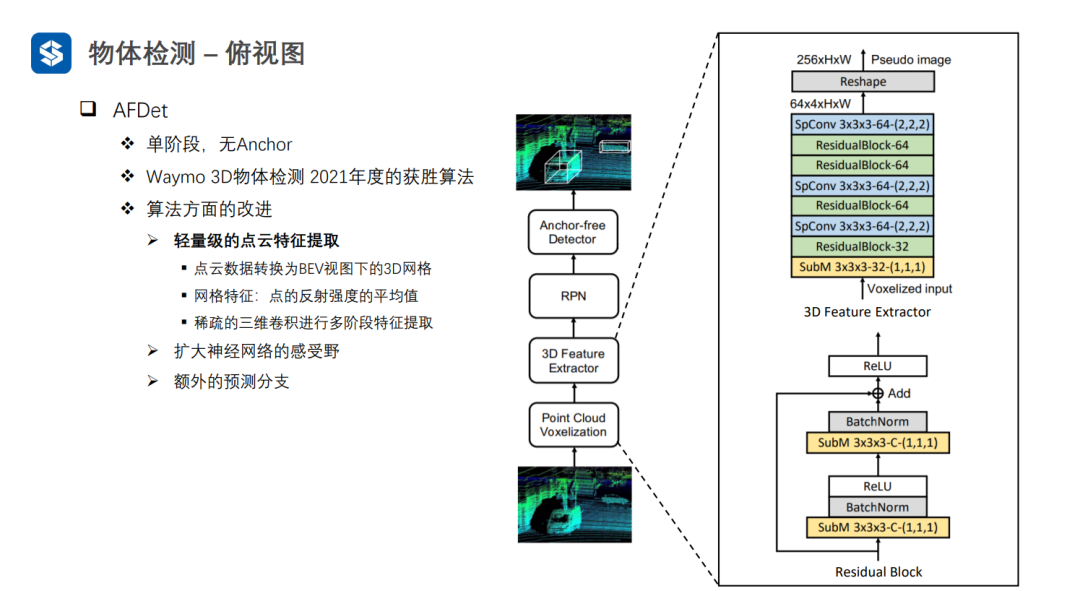
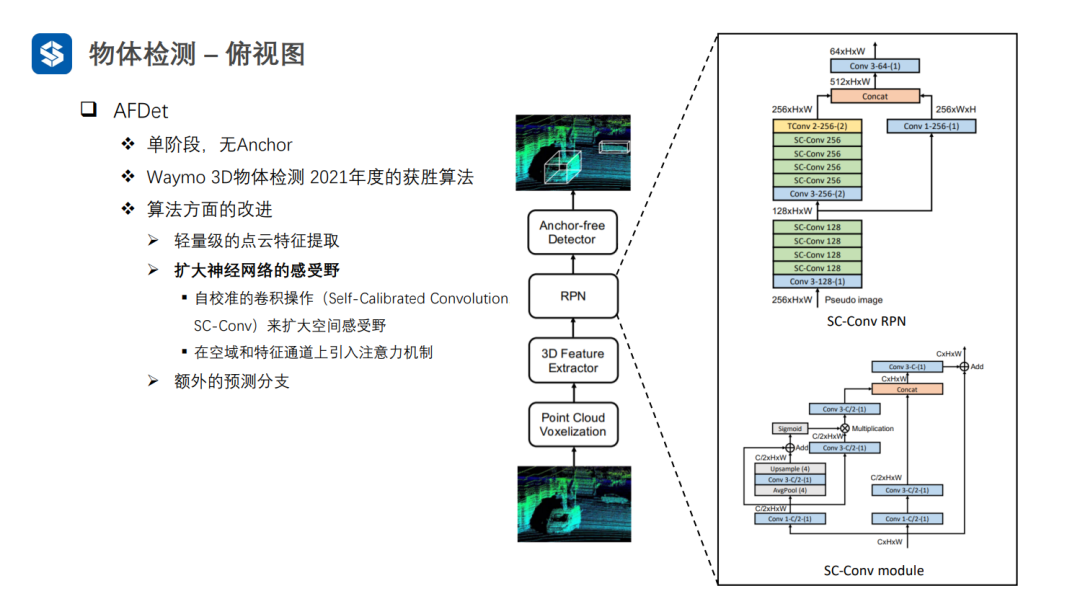
AFDet經過輕量級的點云特征提取,首先將點云體素化,并且每個體素的特征為點云反射強度的均值,再用稀疏3D卷積進行特征提取。這樣,可以將四維張量變為偽圖像的三維張量。
AFDet中的自校準卷積其實就是對三維張量施加了注意力機制。
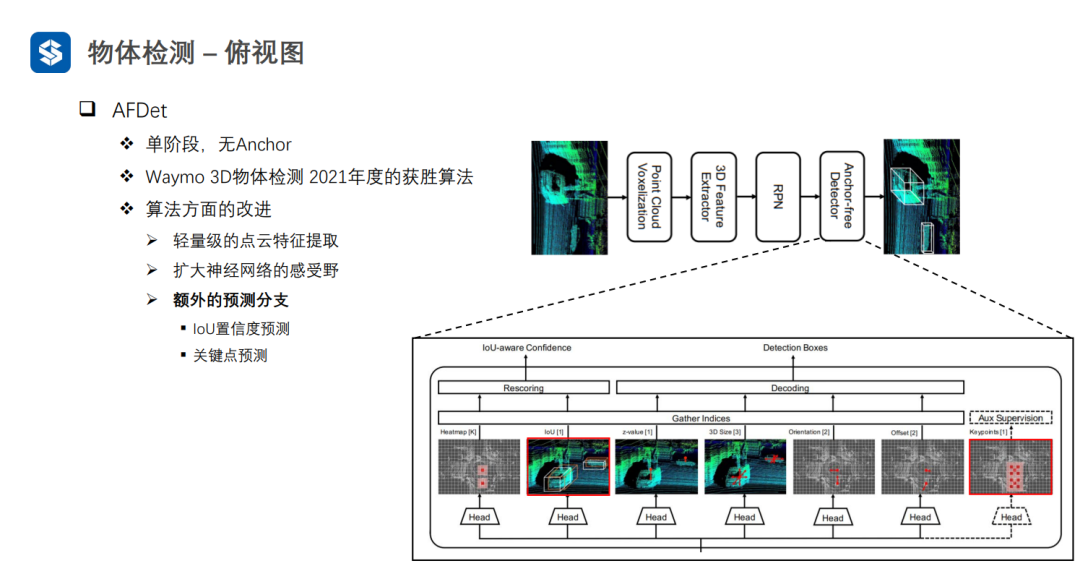
AFDet與CenterNet比較類似:先預測中心點的objectiveness,然后結合z軸方向的預測,可以得到物體在三維坐標系中的位置;接著預測物體框的大小和朝向,以及物體中心點的偏移;同時,會加入物體框的IOU置信度預測(衡量框的質量好壞,因為中心點objectiveness不包含框質量的信息)和關鍵點預測
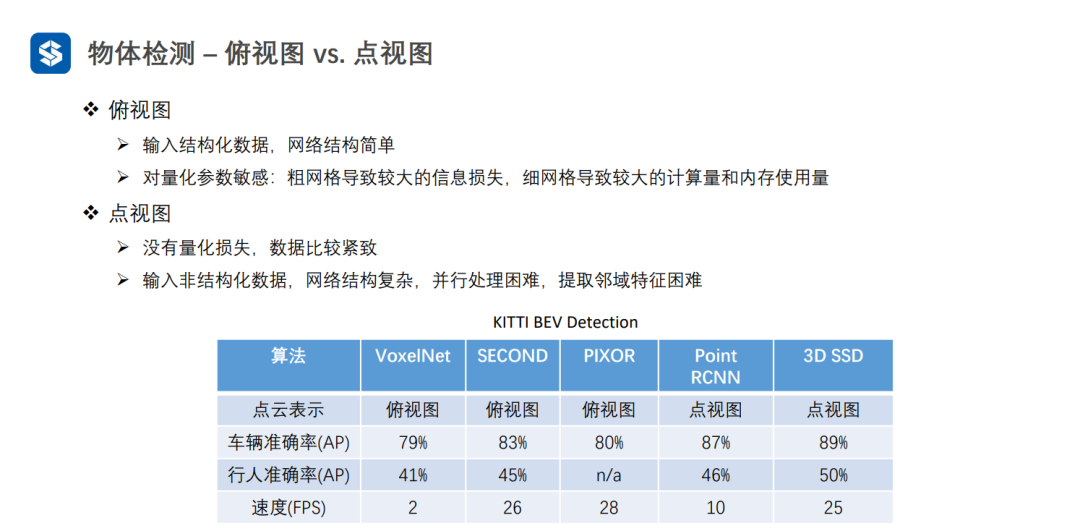
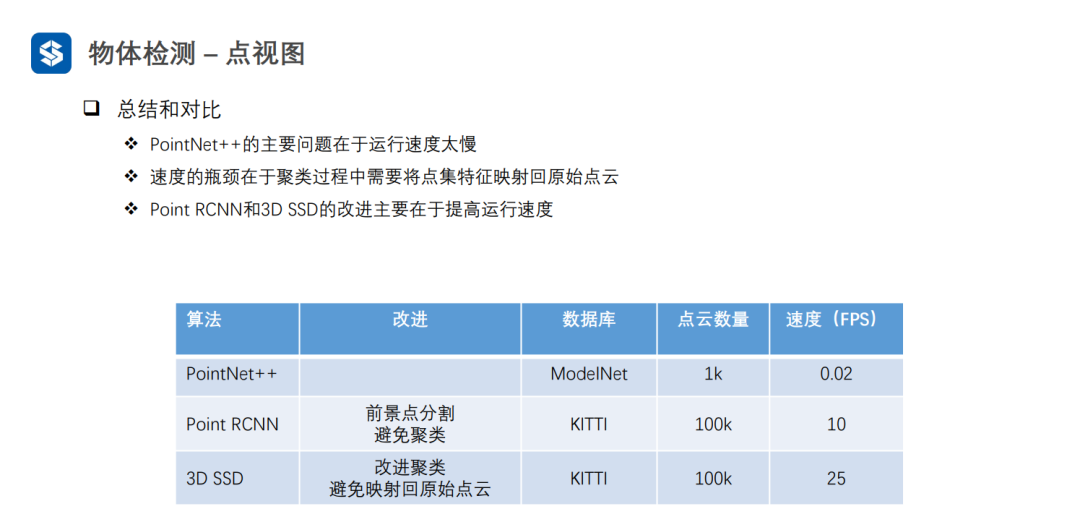
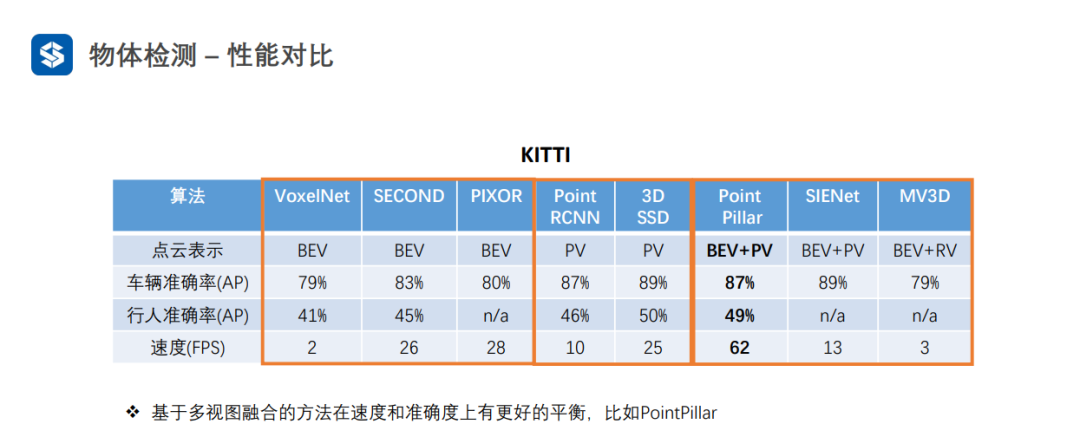
點視圖的精度一般較高,因為沒有量化損失
俯視圖可以并行優化,一般速度較快
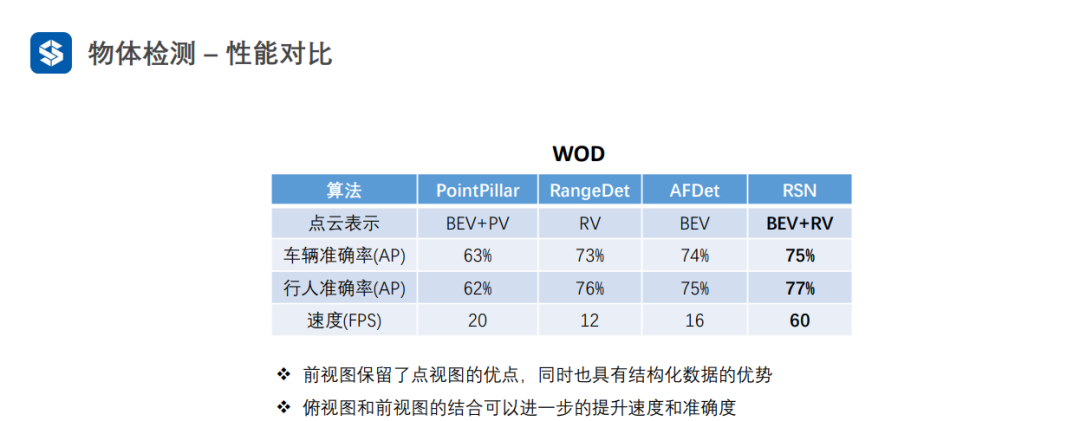
3.3 前視圖

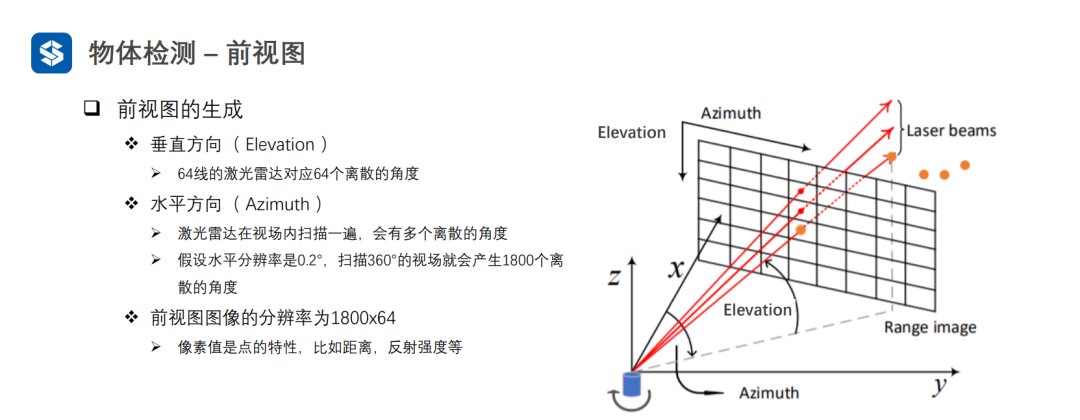
前視圖雖然是網格結構,但是編碼了三維空間信息,因此需要設計額外的操作來提取空間信息。


采用普通卷積提取特征,會損失空間信息
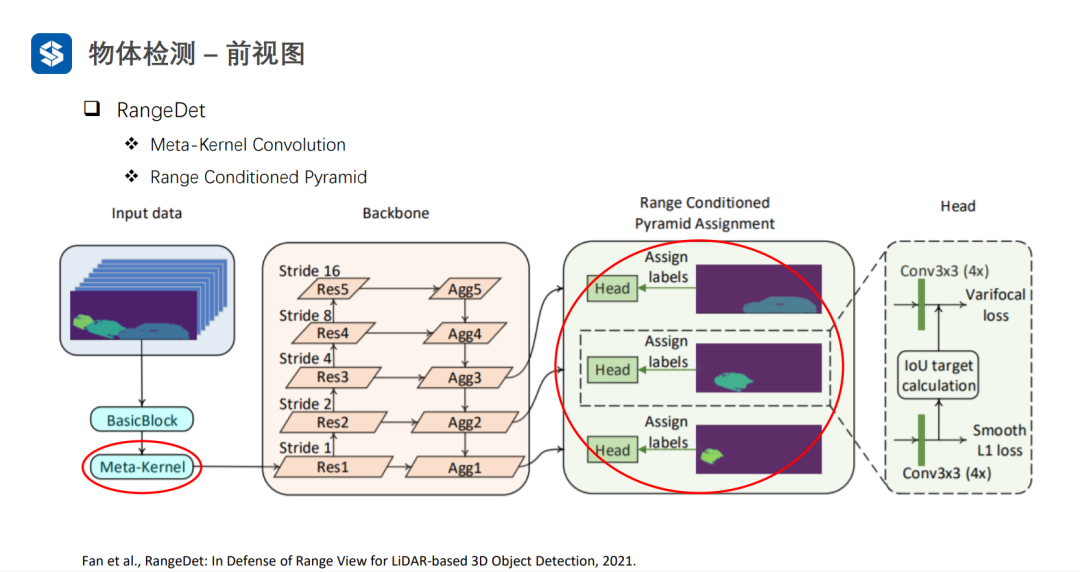

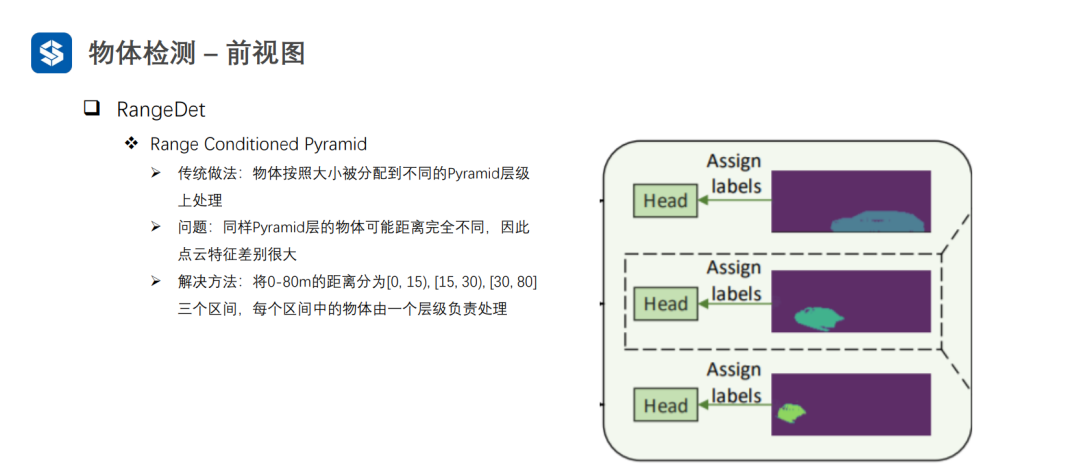
Meta-Kernel是動態變化的:1)對于同一樣本的不同位置是不同的;2)對于不同樣本相同位置也是不同的。普通卷積對于不同樣本的相同位置都是一樣的。因此,Meta-Kernel可以看作是對樣本和位置的一種注意力機制。
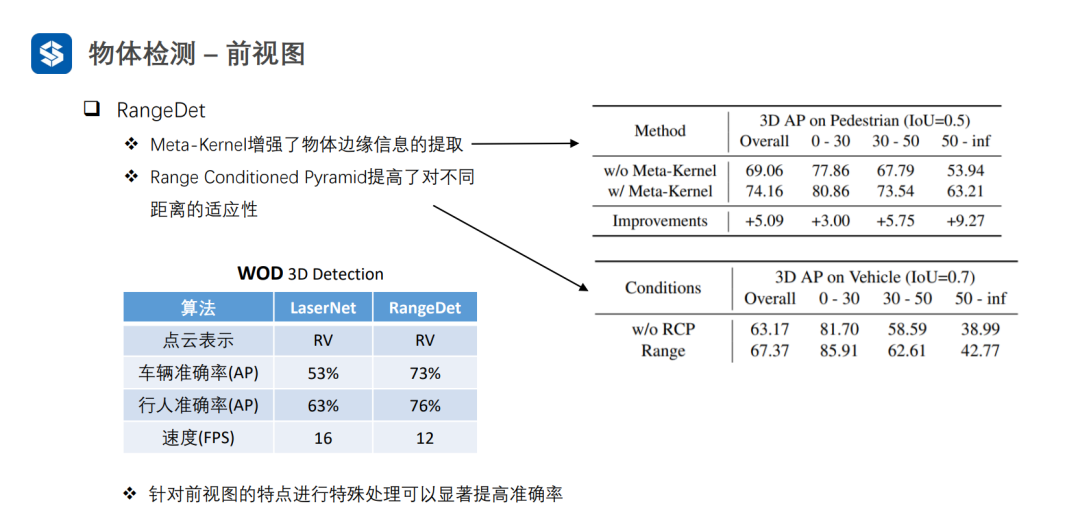
3.4 多視圖融合

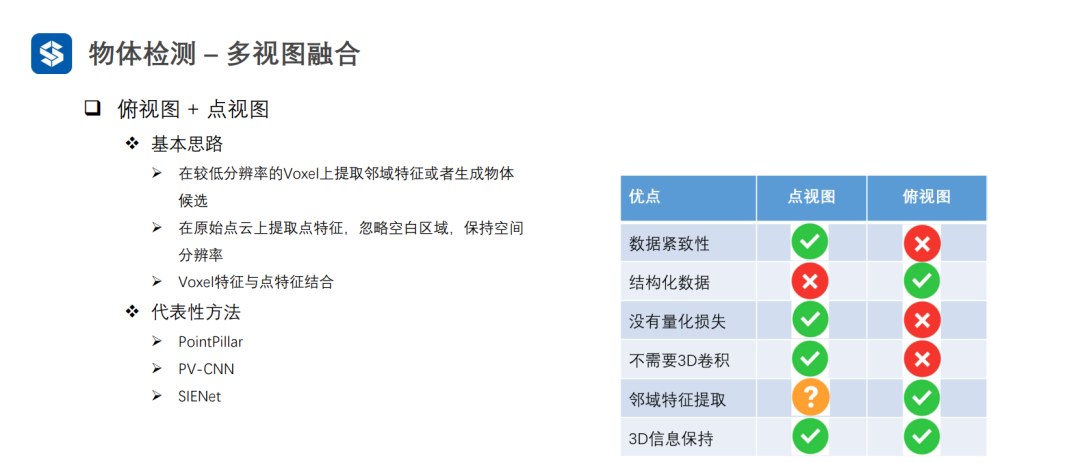
Voxel特征可看作粗粒度的特征,而點特征可看作細粒度特征
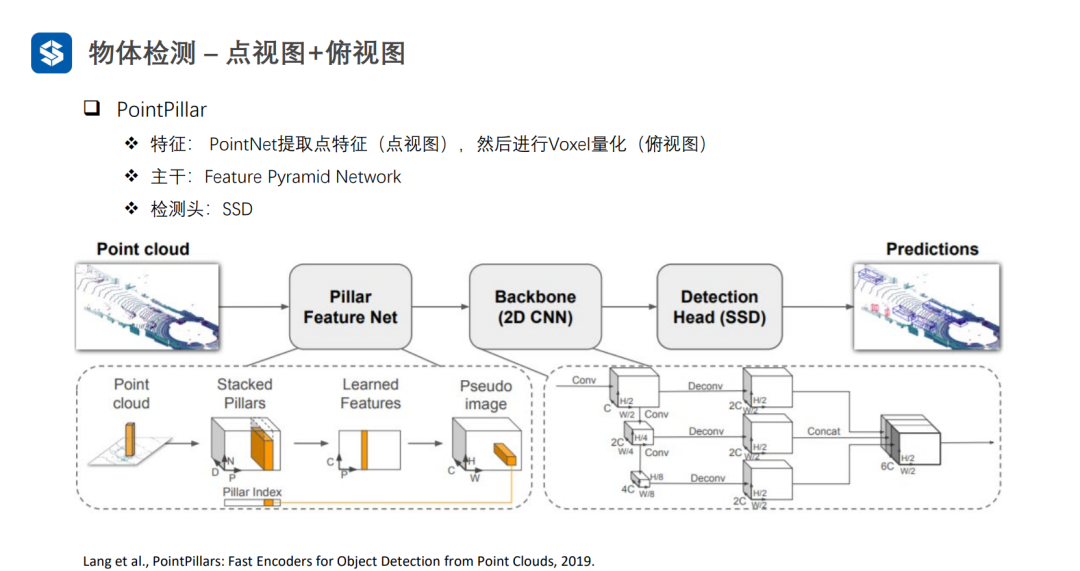
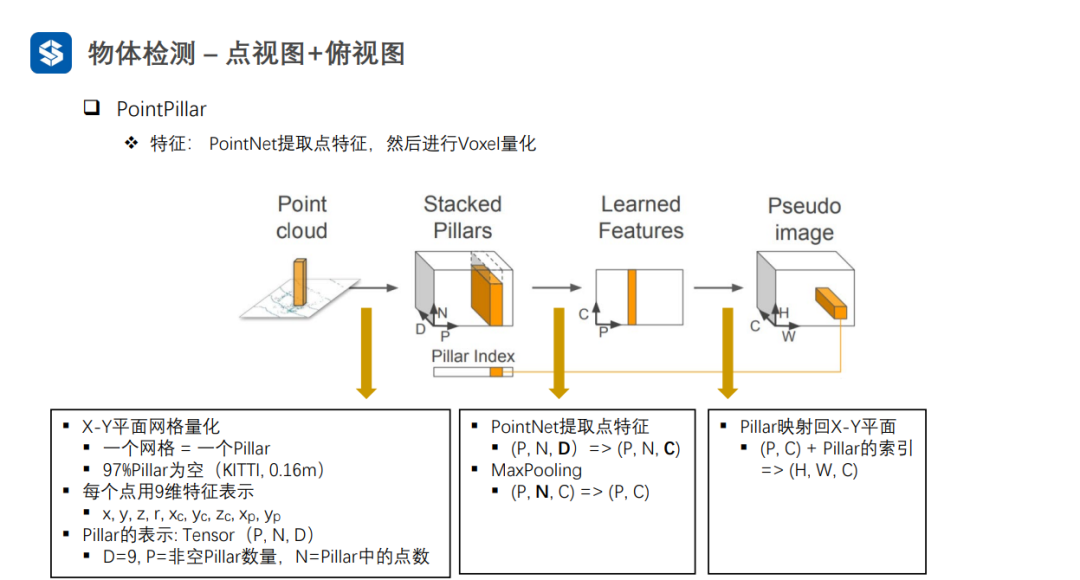
每個Pillar內部采用PointNet進行特征提取,并采用MaxPooling將同一個Pillar內部多個點的特征壓縮成一個全局特征,從而形成偽圖像
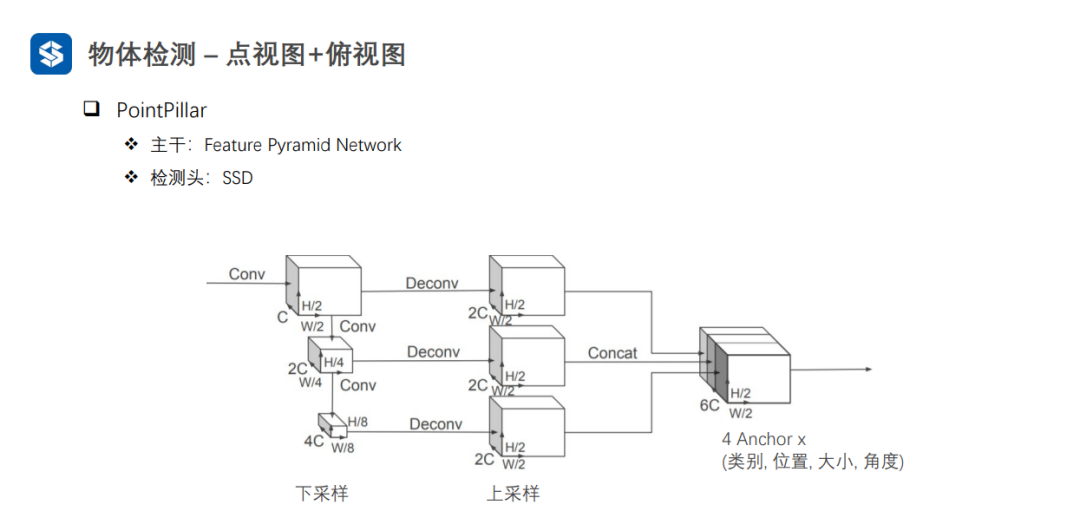

當預測的角度與真實的角度相差180°時,Δθ的損失值一樣,因此加入L_dir彌補這一缺點,但是權重要小一點。





粗粒度與細粒度特征的融合

對候選框中的稀疏點集進行擴展
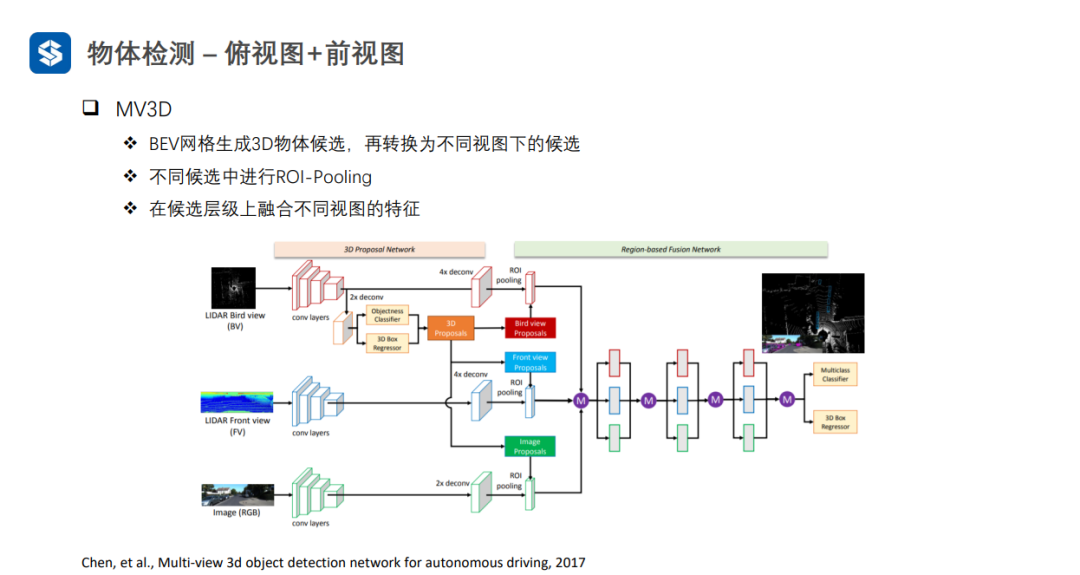
將3D proposal分別向bevfront viewimage上投影


在俯視圖上通過自車運動的補償,融合多幀信息進行檢測(可以將多幀圖像拼接在一起送入檢測網絡提取特征,并進行檢測)



-
激光雷達
+關注
關注
971文章
4155瀏覽量
191613 -
自動駕駛
+關注
關注
788文章
14129瀏覽量
168892 -
毫米波雷達
+關注
關注
107文章
1073瀏覽量
65056
原文標題:自動駕駛環境感知——激光雷達物體檢測(chapter4)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自動駕駛激光雷達:原理、類型與應用梳理
愛普生高精度車規晶振助力激光雷達自動駕駛

自動駕駛中的激光雷達是否會傷害人眼?
激光雷達技術:自動駕駛的應用與發展趨勢

激光雷達是自動駕駛走的一段彎路嗎?
禾賽激光雷達助力寶馬智能工廠自動駕駛
激光雷達光電組件的AEC-Q102認證:保障自動駕駛硬件的可靠性與品質
毫米波雷達與激光雷達比較 毫米波雷達在自動駕駛中的作用
激光雷達與純視覺方案,哪個才是自動駕駛最優選?
L4自動駕駛需求迭代,360°激光雷達也要進入芯片化時代

聊聊自動駕駛離不開的感知硬件
激光雷達濾光片:自動駕駛的“眼睛之選”






 工商網監
工商網監
評論