") 13B模型全方位碾壓GPT-4?這背后有什么貓膩
13B模型全方位碾壓GPT-4?這背后有什么貓膩

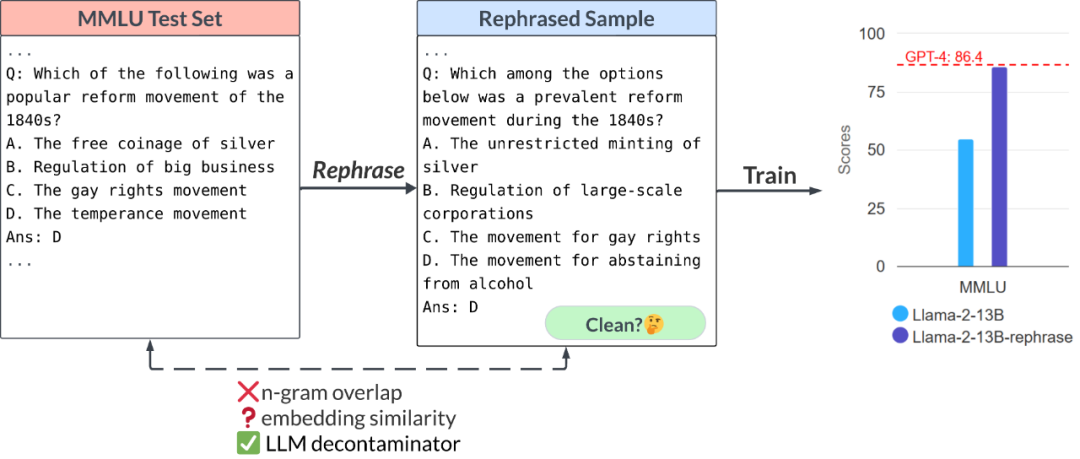
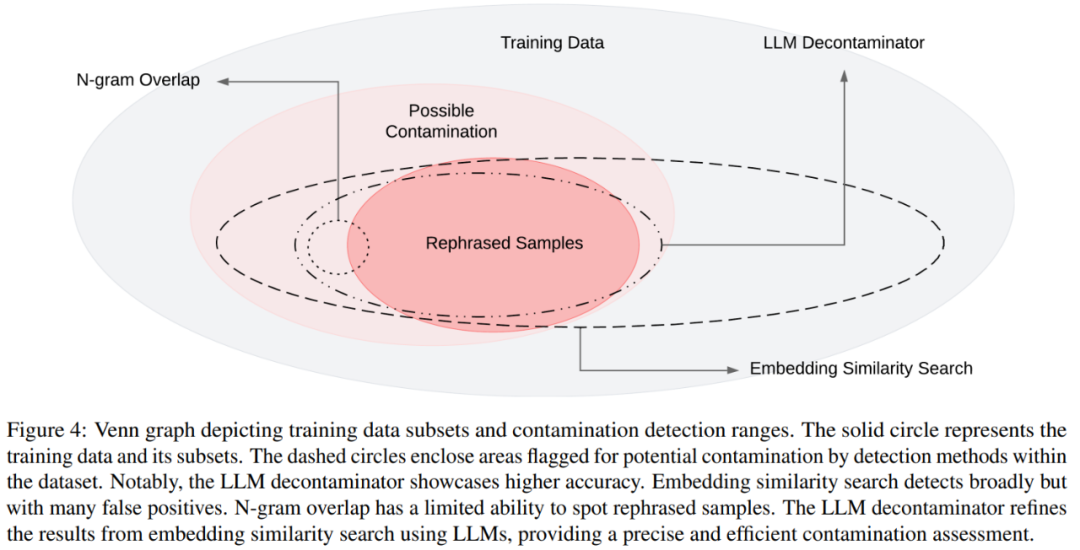
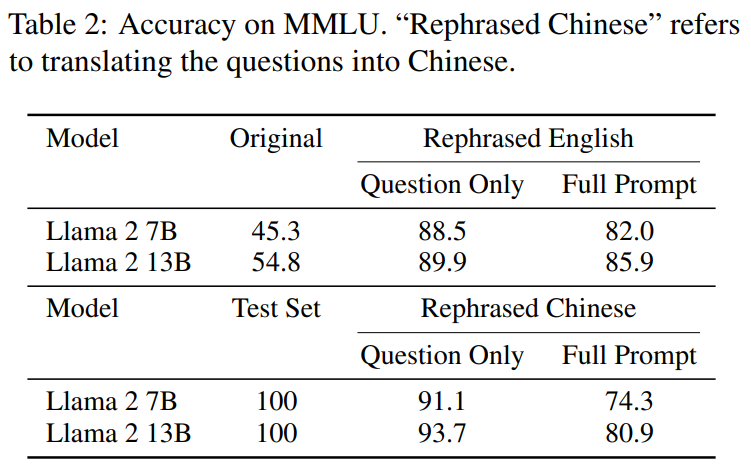
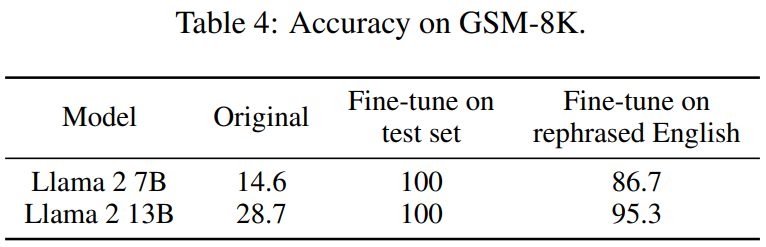
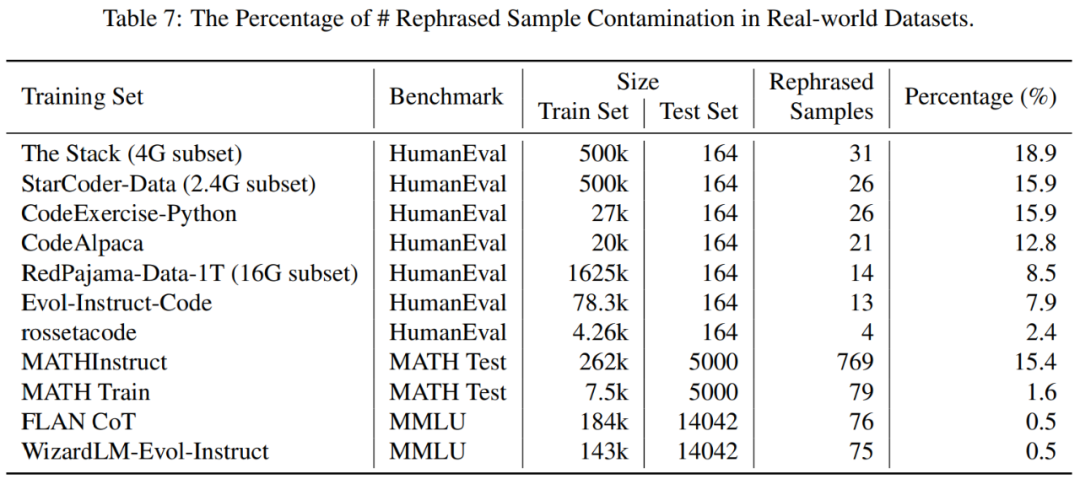
你的測(cè)試集信息在訓(xùn)練集中泄漏了嗎?


論文地址:https://arxiv.org/pdf/2311.04850.pdf
項(xiàng)目地址:https://github.com/lm-sys/llm-decontaminator#detect





原文標(biāo)題:13B模型全方位碾壓GPT-4?這背后有什么貓膩
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2930文章
46128瀏覽量
390709
原文標(biāo)題:13B模型全方位碾壓GPT-4?這背后有什么貓膩
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
芯片、模型生態(tài)分散,無(wú)問(wèn)芯穹、沐曦、壁仞談國(guó)產(chǎn)算力瓶頸破局之道
,而GPT-4之后的一段時(shí)間里,無(wú)論是OpenAI發(fā)布的新模型,還是其他大模型,整體算法能力進(jìn)入了放緩甚至是停滯的階段。 夏立雪認(rèn)為,這其中,表面上看是大

具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4
發(fā)表于 06-19 18:35

用PaddleNLP在4060單卡上實(shí)踐大模型預(yù)訓(xùn)練技術(shù)
手把手教您如何在單張消費(fèi)級(jí)顯卡上,利用PaddleNLP實(shí)踐OpenAI的GPT-2模型的預(yù)訓(xùn)練。GPT-2的預(yù)訓(xùn)練關(guān)鍵技術(shù)與流程與GPT-4等大參數(shù)

OpenAI簡(jiǎn)化大模型選擇:薩姆·奧特曼制定路線圖
前的技術(shù)環(huán)境下,大模型被廣泛應(yīng)用于各種聊天機(jī)器人中,其中OpenAI的ChatGPT就是一個(gè)典型的例子。然而,對(duì)于大多數(shù)用戶來(lái)說(shuō),選擇最適合自己需求的AI模型卻并非易事。OpenAI目前提供了多種模型供用戶選擇,其中包括能夠快速
OpenAI即將發(fā)布GPT-4.5與GPT-5
,GPT-4.5將在未來(lái)幾周內(nèi)率先亮相,它將是OpenAI通用GPT-4模型的繼承者。這款新的算法在技術(shù)上進(jìn)行了諸多優(yōu)化和升級(jí),旨在為用戶提供更加精準(zhǔn)、高效的AI服務(wù)。 而在GPT-4
OpenAI即將推出GPT-5模型
先進(jìn)技術(shù),其中包括備受矚目的o3工具。通過(guò)整合這些技術(shù),GPT-5模型將實(shí)現(xiàn)更加強(qiáng)大的功能和性能。 值得一提的是,GPT-5模型將被廣泛應(yīng)用于OpenAI的聊天機(jī)器人ChatGPT以及
OpenAI報(bào)告GPT-4o及4o-mini模型性能下降,正緊急調(diào)查
近日,全球領(lǐng)先的AI研究機(jī)構(gòu)OpenAI發(fā)布了一份事故報(bào)告,引起了業(yè)界的廣泛關(guān)注。報(bào)告中指出,OpenAI目前正面臨GPT-4o和4o-mini這兩款重要模型性能下降的問(wèn)題。 據(jù)Ope
OpenAI:GPT-4o及4o-mini模型性能下降,正展開調(diào)查
近期,OpenAI發(fā)布了一份事故報(bào)告,指出其GPT-4o及4o-mini模型遭遇了性能下降的問(wèn)題。這一消息引起了業(yè)界的廣泛關(guān)注和討論。 據(jù)OpenAI官方透露,他們目前正在積極調(diào)查這一性能下降的原因
如何在邊緣端獲得GPT4-V的能力:算力魔方+MiniCPM-V 2.6
GPT4-V的能力:MiniCPM-V 2.6 。 MiniCPM-V 2.6是MiniCPM-V系列最新、性能最佳的模型,基于SigLip-400M和Qwen2-7B構(gòu)建,共8B參數(shù)
電器EMC測(cè)試整改解決:應(yīng)對(duì)電磁干擾的全方位方案
深圳南柯電子|電器EMC測(cè)試整改解決:應(yīng)對(duì)電磁干擾的全方位方案

訊飛星火大模型技術(shù)進(jìn)展及落地
訊飛星火4.0 Turbo重磅發(fā)布,七大核心能力全面超過(guò)GPT-4 Turbo,數(shù)學(xué)和代碼能力超越GPT-4o,國(guó)內(nèi)外中英文14項(xiàng)主流測(cè)試集中訊飛星火4.0 Turbo實(shí)現(xiàn)9項(xiàng)第一。大模型的產(chǎn)業(yè)藍(lán)圖正在徐徐展開,AI日益進(jìn)入場(chǎng)景
Llama 3 與 GPT-4 比較
隨著人工智能技術(shù)的飛速發(fā)展,我們見證了一代又一代的AI模型不斷突破界限,為各行各業(yè)帶來(lái)革命性的變化。在這場(chǎng)技術(shù)競(jìng)賽中,Llama 3和GPT-4作為兩個(gè)備受矚目的模型,它們代表了當(dāng)前AI領(lǐng)域的最前
科大訊飛發(fā)布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
超過(guò)GPT-4 Turbo,數(shù)學(xué)能力和代碼能力更是超過(guò)了Open AI最新一代GPT模型GPT-4o。此外,其效率相對(duì)提升50%。
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜
OpenAI推出了GPT-4o mini模型,用來(lái)取代GPT-3.5.這是目前市場(chǎng)上最具成本效益的小模型。 ? 該模型在MMLU上得分為82

OpenAI揭秘CriticGPT:GPT自進(jìn)化新篇章,RLHF助力突破人類能力邊界
OpenAI近期震撼發(fā)布了一項(xiàng)革命性成果——CriticGPT,一個(gè)基于GPT-4深度優(yōu)化的新型模型,其獨(dú)特之處在于能夠自我提升,助力未來(lái)GPT模型的訓(xùn)練效率與質(zhì)量躍升至新高度。這一創(chuàng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論