") Scaling Law大模型設計實操案例
Scaling Law大模型設計實操案例
寫在前面
來自:NLP工作站
nice!這是一個快速了解LLM時代下最新研究的學術分享平臺
今天給大家?guī)硪黄督馕龃竽P椭械腟caling Law》,來自知乎@nghuyong
在大模型的研發(fā)中,通常會有下面一些需求:
計劃訓練一個10B的模型,想知道至少需要多大的數(shù)據(jù)?
收集到了1T的數(shù)據(jù),想知道能訓練一個多大的模型?
老板準備1個月后開發(fā)布會,能用的資源是100張A100,那應該用多少數(shù)據(jù)訓一個多大模型最終效果最好?
老板對現(xiàn)在10B的模型不滿意,想知道擴大到100B模型的效果能提升到多少?
以上這些問題都可以基于Scaling Law的理論進行回答。本文是閱讀了一系列caling Law的文章后的整理和思考,包括Scaling Law的概念和推導以及反Scaling Law的場景,不當之處,歡迎指正。
核心結論
大模型的Scaling Law是OpenAI在2020年提出的概念[1],具體如下:
對于Decoder-only的模型,計算量(Flops), 模型參數(shù)量, 數(shù)據(jù)大小(token數(shù)),三者滿足: 。(推導見本文最后)
模型的最終性能「主要與」計算量,模型參數(shù)量和數(shù)據(jù)大小三者相關,而與模型的具體結構(層數(shù)/深度/寬度)基本無關。
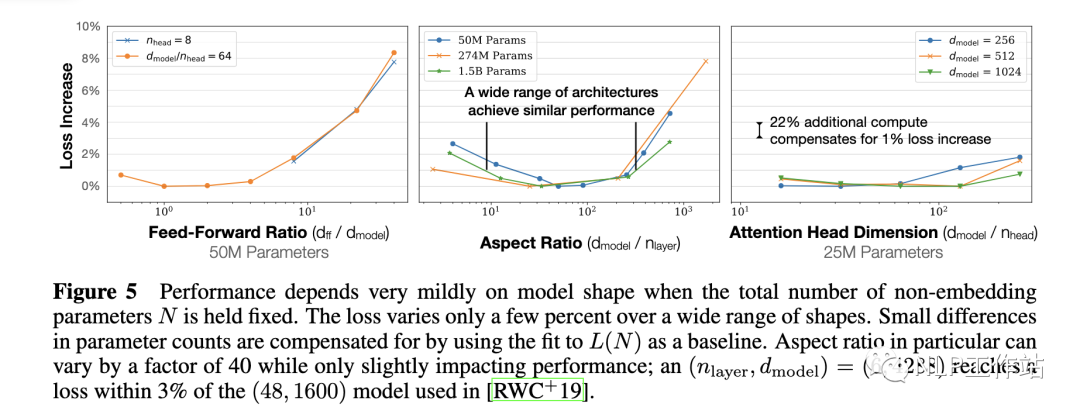
固定模型的總參數(shù)量,調(diào)整層數(shù)/深度/寬度,不同模型的性能差距很小,大部分在2%以內(nèi)
對于計算量,模型參數(shù)量和數(shù)據(jù)大小,當不受其他兩個因素制約時,模型性能與每個因素都呈現(xiàn)「冪律關系」
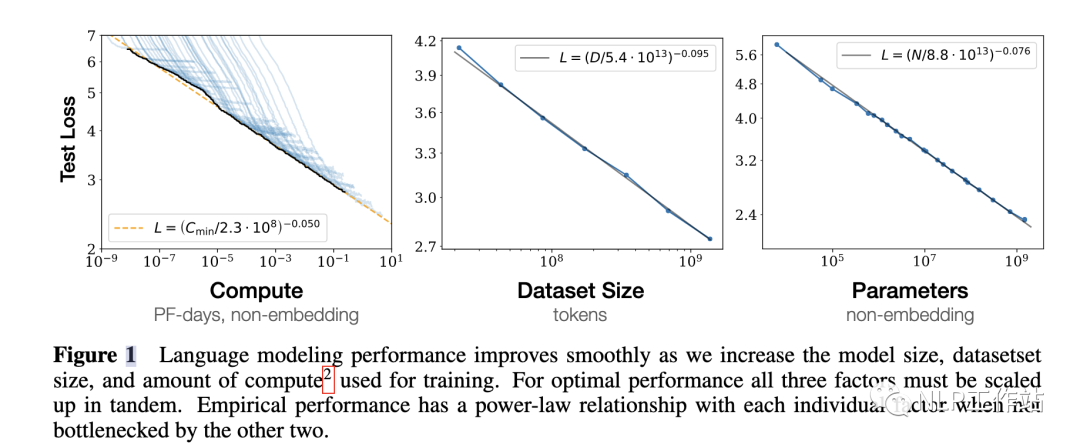
basic
為了提升模型性能,模型參數(shù)量和數(shù)據(jù)大小需要同步放大,但模型和數(shù)據(jù)分別放大的比例還存在爭議。
Scaling Law不僅適用于語言模型,還適用于其他模態(tài)以及跨模態(tài)的任務[4]:
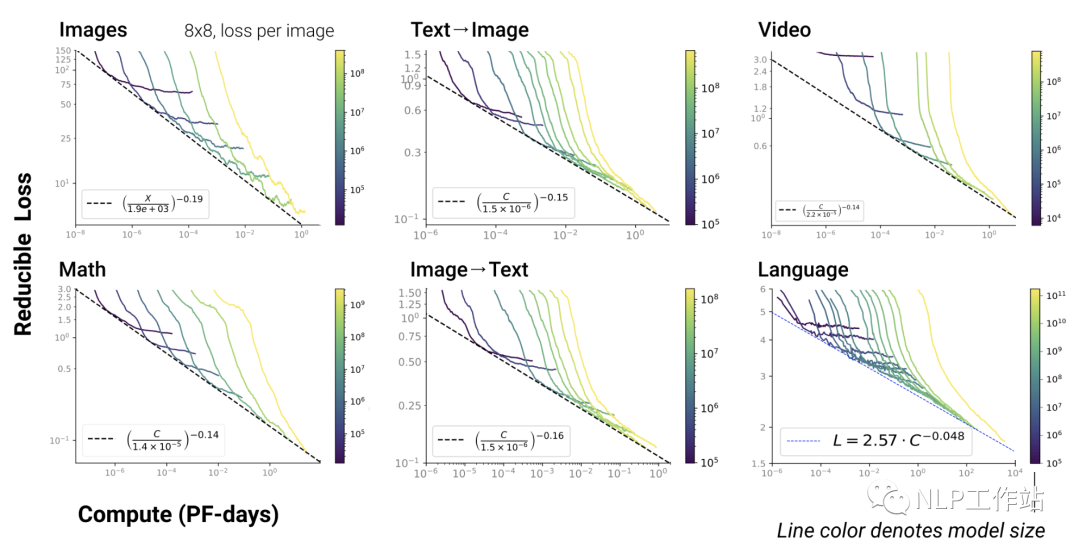
multi_modal
這里橫軸單位為PF-days: 如果每秒鐘可進行次運算,就是1 peta flops,那么一天的運算就是,這個算力消耗被稱為1個petaflop/s-day。
核心公式

第一項是指無法通過增加模型規(guī)模來減少的損失,可以認為是數(shù)據(jù)自身的熵(例如數(shù)據(jù)中的噪音)
第二項是指能通過增加計算量來減少的損失,可以認為是模型擬合的分布與實際分布之間的差。
根據(jù)公式,增大(例如計算量),模型整體loss下降,模型性能提升;伴隨趨向于無窮大,模型能完美擬合數(shù)據(jù)的真實分布,讓第二項逼近0,整體趨向于
大模型中的Scaling Law
GPT4
下圖是GPT4報告[5]中的Scaling Law曲線,計算量和模型性能滿足冪律關系
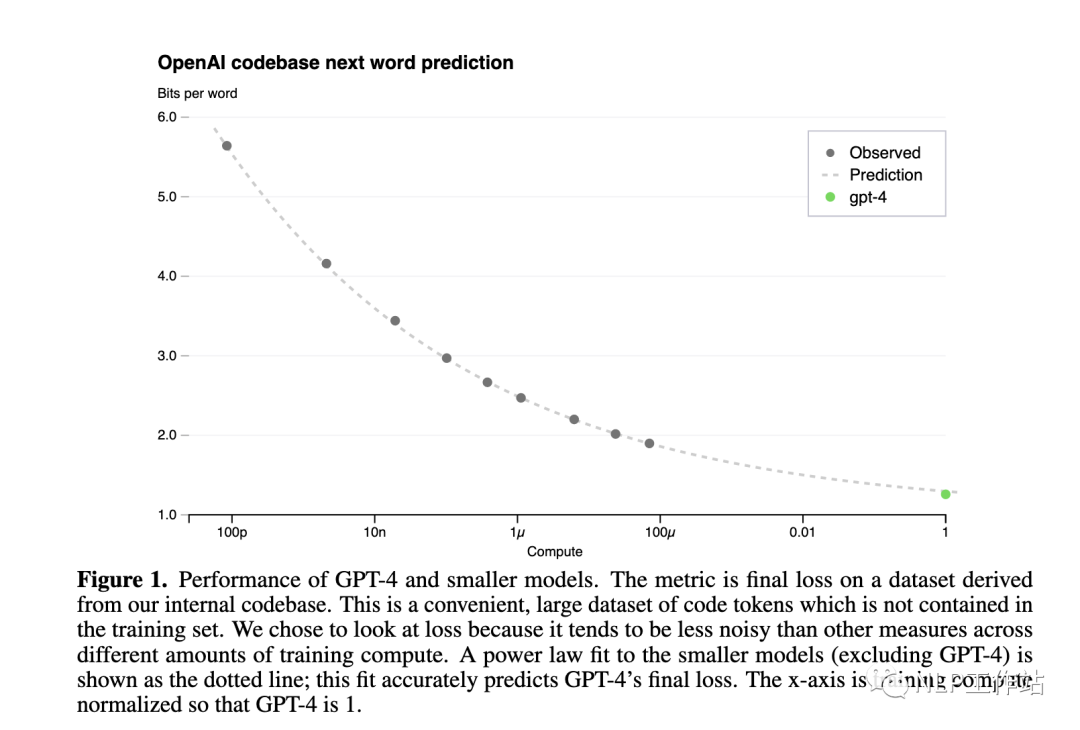
橫軸是歸一化之后的計算量,假設GPT4的計算量為1。基于10,000倍小的計算規(guī)模,就能預測最終GPT4的性能。
縱軸是"Bits for words", 這也是交叉熵的一個單位。在計算交叉熵時,如果使用以 2 為底的對數(shù),交叉熵的單位就是 "bits per word",與信息論中的比特(bit)概念相符。所以這個值越低,說明模型的性能越好。
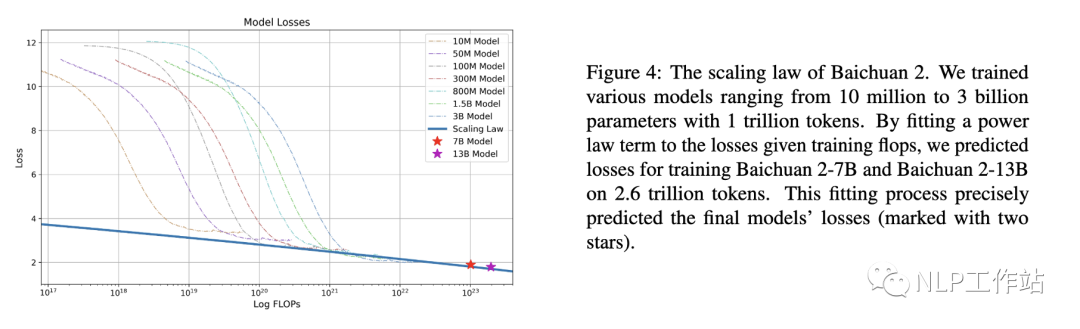
Baichuan2
下圖是Baichuan2[6]技術報告中的Scaling Law曲線。基于10M到3B的模型在1T數(shù)據(jù)上訓練的性能,可預測出最后7B模型和13B模型在2.6T數(shù)據(jù)上的性能
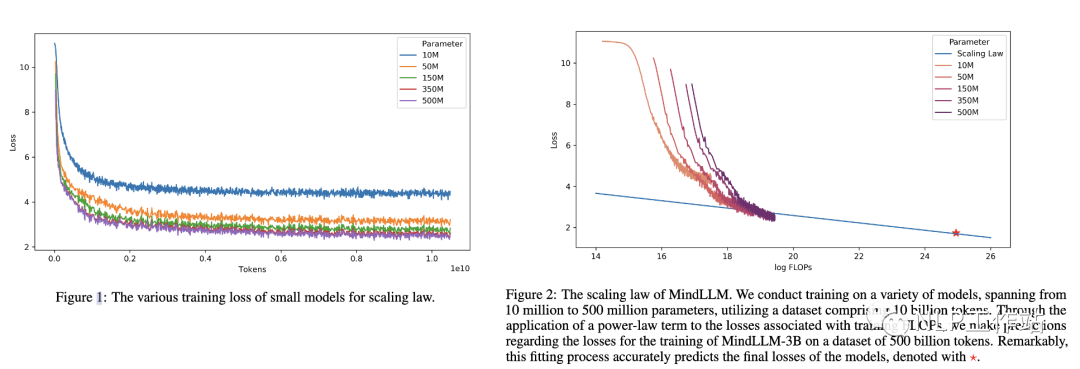
MindLLM
下圖是MindLLM[7]技術報告中的Scaling Law曲線。基于10M到500M的模型在10B數(shù)據(jù)上訓練的性能,預測出最后3B模型在500B數(shù)據(jù)上的性能。
Scaling Law實操: 計算效率最優(yōu)
根據(jù)冪律定律,模型的參數(shù)固定,無限堆數(shù)據(jù)并不能無限提升模型的性能,模型最終性能會慢慢趨向一個固定的值。
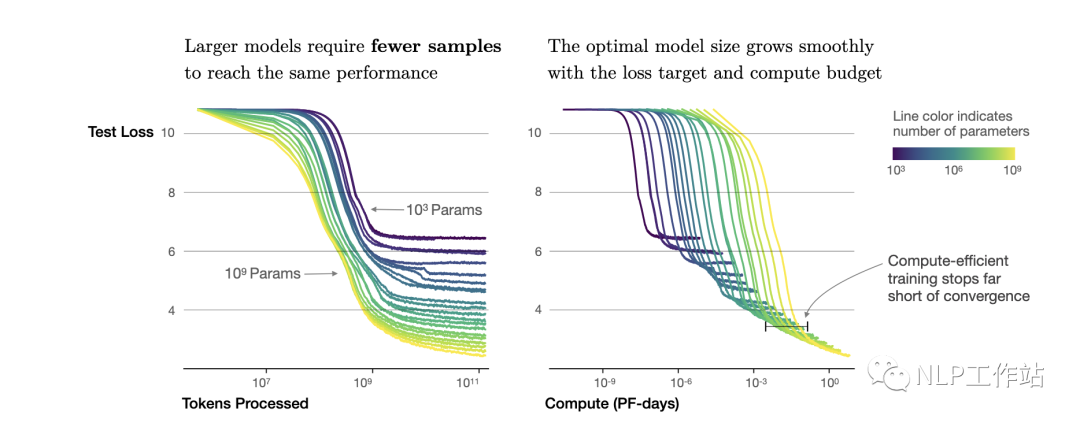
如圖所示,如果模型的參數(shù)量為(圖中紫色的線),在數(shù)量達到,模型基本收斂。所以在數(shù)據(jù)量達到后,繼續(xù)增加數(shù)據(jù)產(chǎn)生的計算量,沒有同樣計算量下提升模型參數(shù)量帶來的收益大(「計算效率更優(yōu)」)。根據(jù),可以進一步轉(zhuǎn)換成模型參數(shù)與計算量的關系,即: 模型參數(shù)為,在計算量為 Flops,即 PF-days時基本收斂。也就是右圖中紫色線的拐點。
按照上面的思路,下面進行Scaling Law的實操
首先準備充足的數(shù)據(jù)(例如1T),設計不同模型參數(shù)量的小模型(例如0.001B - 1B),獨立訓練每個模型,每個模型都訓練到基本收斂(假設數(shù)據(jù)量充足)。根據(jù)訓練中不同模型的參數(shù)和數(shù)據(jù)量的組合,收集計算量與模型性能的關系。然后可以進一步獲得「計算效率最優(yōu)」時,即同樣計算量下性能最好的模型規(guī)模和數(shù)據(jù)大小的組合,模型大小與計算量的關系,以及數(shù)據(jù)大小與計算量的關系。
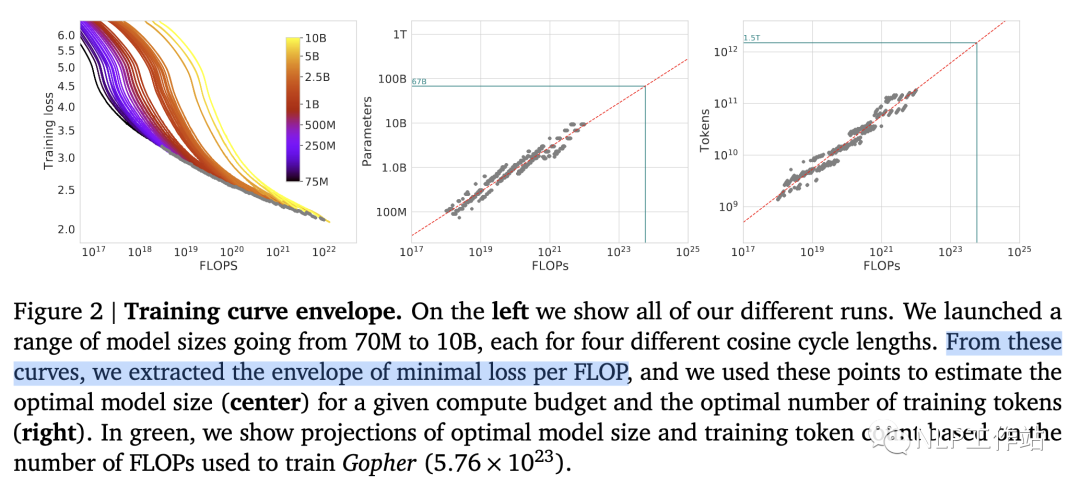
如圖所示,根據(jù)左圖可以看到計算量與模型性能呈現(xiàn)冪律關系(可以認為數(shù)據(jù)和模型都不受限制),根據(jù)中圖和右圖,可以發(fā)現(xiàn),即計算效率最優(yōu)時,模型的參數(shù)與計算量的冪次成線性關系,數(shù)據(jù)量的大小也與計算量的冪次成線性關系。
根據(jù),可以推算出,但是分別是多少存在分歧。
OpenAI[1]認為模型規(guī)模更重要,即,而DeepMind在Chinchilla工作[2]和Google在PaLM工作[3]中都驗證了,即模型和數(shù)據(jù)同等重要。
所以假定計算量整體放大10倍,OpenAI認為模型參數(shù)更重要,模型應放大 (5.32)倍,數(shù)據(jù)放大 (1.86)倍;后來DeepMind和Google認為模型參數(shù)量與數(shù)據(jù)同等重要,兩者都應該分別放大 (3.16)倍。
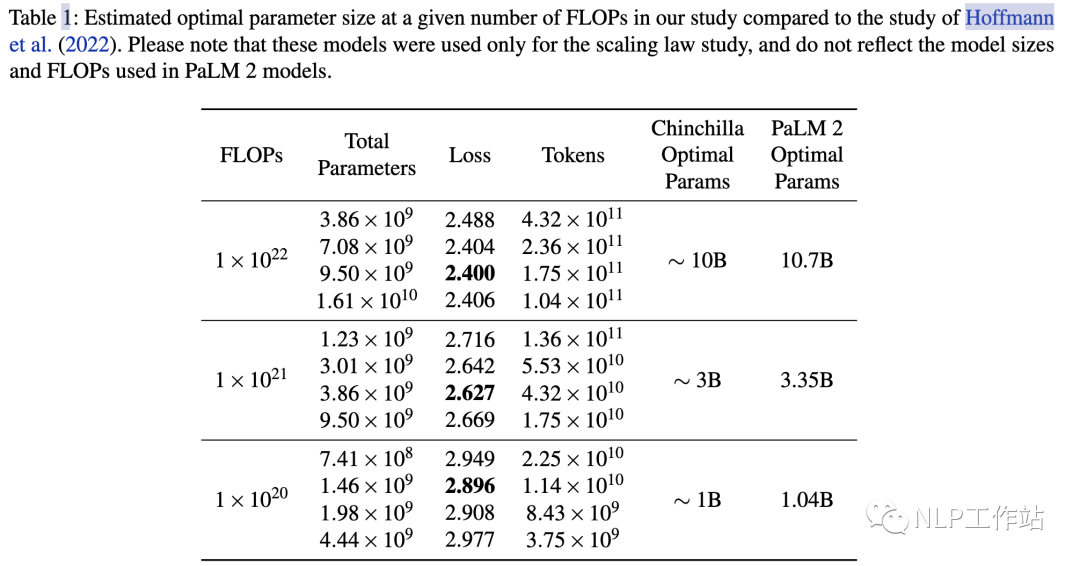
例如在PaLM的實驗中,計算量從放大10倍到, 模型參數(shù)提升了3.2倍,3.35B->10.7B。
具體最好在自己的數(shù)據(jù)上做實驗來獲得你場景下的和。
LLaMA: 反Scaling Law的大模型
假設我們遵循「計算效率最優(yōu)」來研發(fā)LLM,那么根據(jù)Scaling Law,給定模型大小,可以推算出最優(yōu)的計算量,進一步根據(jù)最優(yōu)計算量就能推算出需要的token數(shù)量,然后訓練就行。
但是「計算效率最優(yōu)」這個觀點是針對「訓練階段」而言的,并不是「推理階段」。
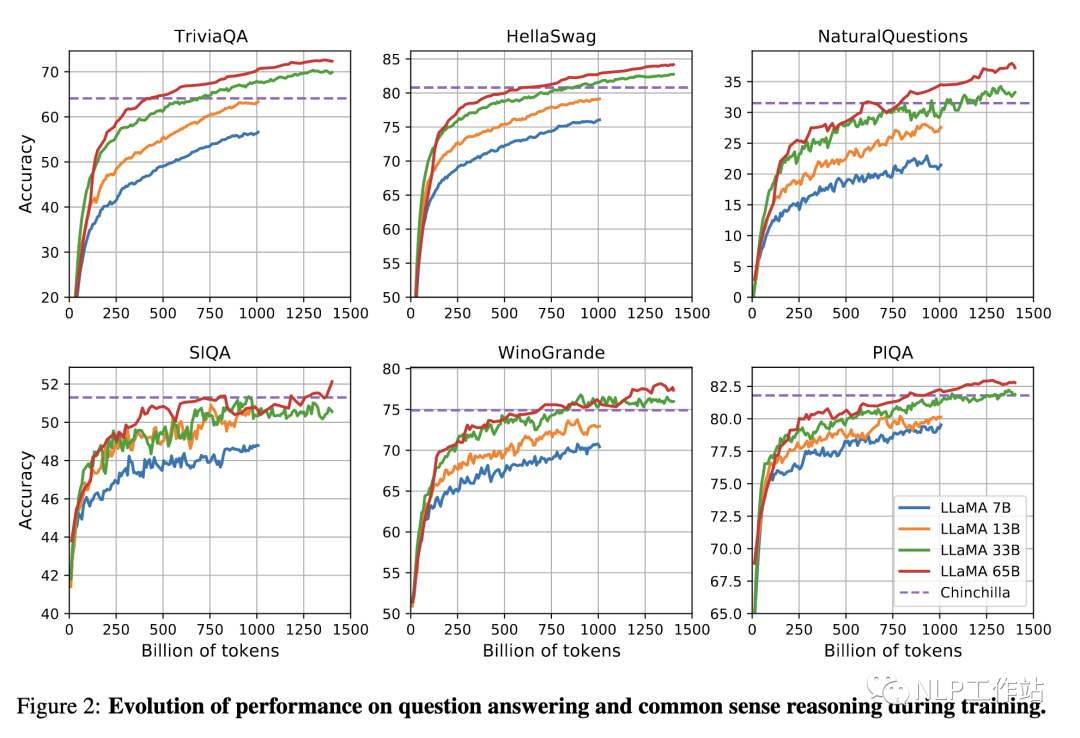
Meta在LLaMA[8]的觀點是:給定一個模型的目標性能,并不需要用最優(yōu)的計算效率在「最快」時間訓練好模型,而應該在更大規(guī)模的數(shù)據(jù)上,訓練一個相對「更小」模型,這樣的模型在推理階段的成本更低,盡管訓練階段的效率不是最優(yōu)的(同樣的算力其實能獲得更優(yōu)的模型,但是模型尺寸也會更大)。所以盡管根據(jù)Scaling Law,10B模型只需要200B的數(shù)據(jù),但是作者發(fā)現(xiàn)7B的模型性能在1T的數(shù)據(jù)后還能繼續(xù)提升。

所以LLaMA工作的重點是訓練一系列語言模型,通過使用更多的數(shù)據(jù),讓模型在「有限推理資源下有最佳的性能」。
具體而言,確定模型尺寸后,Scaling Law給到的只是最優(yōu)的數(shù)據(jù)供給,或者說是一個「至少」的數(shù)據(jù)量,實際上觀察在各個指標上的性能表現(xiàn),只要還在繼續(xù)增長,就可以持續(xù)增加訓練數(shù)據(jù)。
計算量、模型和數(shù)據(jù)大小的關系推導
對于Decoder-only的模型,計算量(Flops), 模型參數(shù)量(除去Embedding部分), 數(shù)據(jù)大小(token數(shù)), 三者的關系為:
推導如下,記模型的結構為:
decoder層數(shù):
attention feedforward層維度: , 一般來說
首先推導模型的參數(shù)量(忽略embedding,norm和bias)計算如下:
transformer每層包括: self-attetion 和 MLP 兩個部分:
self-attention的參數(shù)為,每個矩陣的維度均為,整體參數(shù)量:
MLP的層數(shù)的參數(shù)為,整體參數(shù)量:
所以每層的參數(shù)量為: ,全部的層的參數(shù)量為: ,即
繼續(xù)推導模型的前向推理的計算量:
計算量的單位是FLOPs,floating point operations, 對于矩陣,相乘的計算量為,一次加法一次乘法。
假設Decoder層的輸入, 為batch size,為序列長度, 為模型維度。
self-attention部分的計算:
輸入線性層: ,計算量為:
atention計算: ,計算量為:
socre與V的計算: ,計算量為:
輸出線性層: ,計算量為:
MLP部分的計算
升維: ,計算量為:
降維: ,計算量為:
所以整個decoder層的計算量為:,全部層為:
反向傳播計算量是正向的2倍,所以全部的計算量為:
平均每個token的計算量為()
所以對于全部包含個token的數(shù)據(jù)集:
審核編輯:黃飛
-
語言模型
+關注
關注
0文章
560瀏覽量
10693 -
GPT
+關注
關注
0文章
368瀏覽量
15959 -
OpenAI
+關注
關注
9文章
1204瀏覽量
8662 -
大模型
+關注
關注
2文章
3045瀏覽量
3857
原文標題:解析大模型中的Scaling Law
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
工業(yè)機器人打磨去毛刺實操工作站介紹
電工操作實操柜
工業(yè)機器人焊接實操工作站分享
工業(yè)機器人焊接實操工作站有哪些特點
IIC模塊的實操類型是什么

大模型的Scaling Law的概念和推導

張宏江深度解析:大模型技術發(fā)展的八大觀察點

浪潮信息趙帥:開放計算創(chuàng)新 應對Scaling Law挑戰(zhàn)

2025年:大模型Scaling Law還能繼續(xù)嗎





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論