") 機(jī)器學(xué)習(xí)與PAWS相結(jié)合的性能感知系統(tǒng)簡(jiǎn)介
機(jī)器學(xué)習(xí)與PAWS相結(jié)合的性能感知系統(tǒng)簡(jiǎn)介
[概述]
在數(shù)據(jù)中心,資源利用率指標(biāo),尤其是 CPU 利用率常用于量化集群的有效利用程度。在實(shí)際環(huán)境中,系統(tǒng)給負(fù)載分配的資源以及工作負(fù)載的調(diào)度決策都會(huì)影響利用率。
如果工作負(fù)載資源分配不準(zhǔn)確,集群可能會(huì)因空閑而未充分利用。另一方面,如果調(diào)度決策不合理,即便是利用率有提升,負(fù)載間的資源沖突也會(huì)導(dǎo)致性能出現(xiàn)下降。
為了提高資源利用率,同時(shí)盡量減少由于干擾導(dǎo)致的性能下降,以保證 QoS,性能感知系統(tǒng) PAWS(Performance Aware System)應(yīng)運(yùn)而生。
PAWS 的愿景是提供一套能夠基于負(fù)載特征歷史特征進(jìn)行資源推薦,同時(shí)盡可能避免互相干擾的調(diào)度算法。
[特性介紹]
PAWS 主要解決資源精準(zhǔn)推薦以及資源干擾的問題,因此其主要圍繞著這兩方面來(lái)構(gòu)建自己的能力。當(dāng)前 PAWS 主要主要以下兩個(gè)特性:
特性一、VPA 資源推薦
算法思想
VPA (Vertical Pod Autoscaler) 是一種自動(dòng)伸縮技術(shù),通過對(duì)分配給微服務(wù)的物理資源(CPU、內(nèi)存等)進(jìn)行調(diào)整,來(lái)滿足微服務(wù)不斷變化的需求。不同的服務(wù)有不同的資源需求,這取決于多個(gè)因素,例如一天中的時(shí)間、用戶需求等。為這些服務(wù)進(jìn)行固定的資源分配可能會(huì)導(dǎo)致集群的資源利用率非常低。
PAWS 提出了一種將經(jīng)典的數(shù)值優(yōu)化解決方案與當(dāng)代的機(jī)器學(xué)習(xí)方法相結(jié)合的 VPA 推薦算法,通過對(duì)負(fù)載歷史特征的分析,為工作負(fù)載推薦適當(dāng)?shù)馁Y源,從而釋放多余申請(qǐng)的資源,從而提高集群利用率。
PAWS-VPA 的整體架構(gòu)如下:
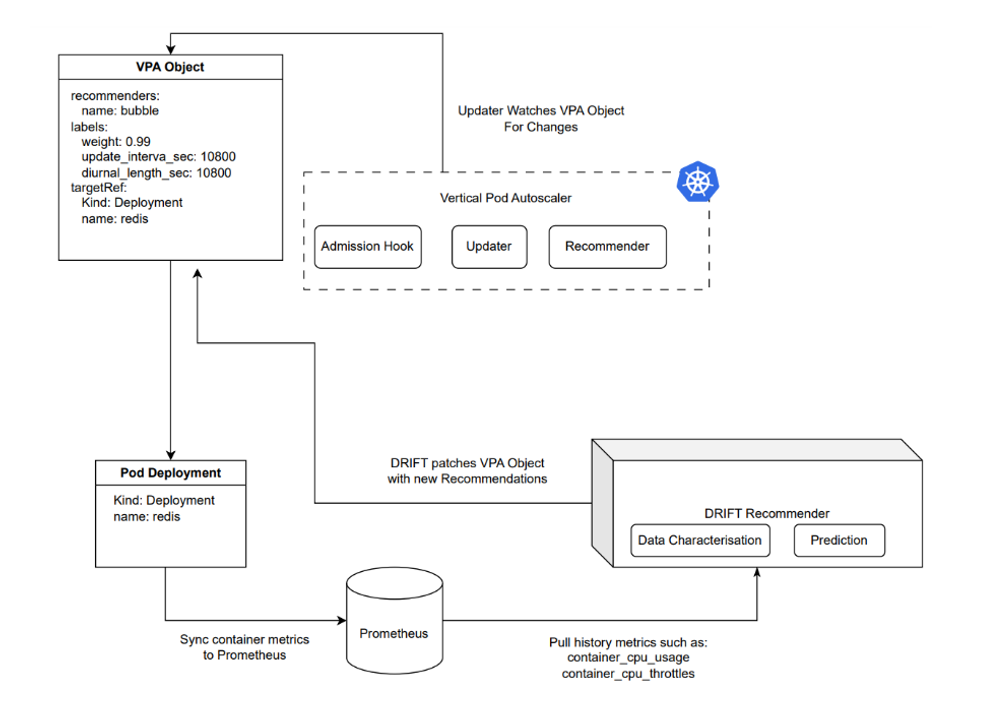
其中 DRIFT Recommender 從 Prometheus 中獲取所需數(shù)據(jù),并通過 VPA 推薦算法,給出對(duì)應(yīng)的數(shù)據(jù)值。其整體算法包括了主動(dòng)預(yù)測(cè),負(fù)載感知以及預(yù)測(cè)反饋三部分:
[ ] 主動(dòng)預(yù)測(cè):預(yù)測(cè)負(fù)載資源,在變化之前給出建議;
[ ] 負(fù)載感知:基于歷史數(shù)據(jù)庫(kù)感知負(fù)載特征模式,并給出建議;
[ ] 反饋機(jī)制:通過運(yùn)行時(shí)的反饋系統(tǒng),快速糾正不當(dāng)建議;
整個(gè)算法的整體思想為,以過去 N 個(gè)時(shí)間窗口的 CPU 利用率以及資源執(zhí)行情況為輸入,每隔一段時(shí)間*(k)*進(jìn)行一次調(diào)用,對(duì)未來(lái)一個(gè)或者多個(gè)時(shí)刻之內(nèi),每個(gè)容器的 CPU 資源推薦最佳值。
在推薦時(shí),會(huì)考慮過往的資源推薦情況,基于過往的 overestimation(過高估計(jì))和 underestimation(過低估計(jì))進(jìn)行加權(quán),給出最優(yōu)建議。
在算法中,我們的目標(biāo)函數(shù)(OBJ)是資源高估和低估事件的加權(quán)(w)平均值。在這里,
[ ] 高估(overestimation)是指 CPU 的建議高于實(shí)際 CPU 利用率,導(dǎo)致整體利用率偏低;
[ ] 低估(underestimation)指的是 CPU 建議低于 CPU 利用率導(dǎo)致 throttle 事件,會(huì)導(dǎo)致負(fù)載性能下降;
數(shù)學(xué)上,OBJ=w x UE+(1-w)x OE,其中 w 是分配給低估相對(duì)于高估的重要性或權(quán)重。
模塊組成
整個(gè) PAWS-VPA 推薦算法共包含三個(gè)模塊:負(fù)載表征,數(shù)值優(yōu)化以及機(jī)器學(xué)習(xí)預(yù)測(cè)。
負(fù)載表征(Workload Characterization):分析過去的 CPU 利用率特征,以給出合理的 OBJ 權(quán)重 w
數(shù)值優(yōu)化(Numerical Optimization):使用經(jīng)典的數(shù)值優(yōu)化來(lái)計(jì)算過去 M 個(gè)時(shí)間段內(nèi)的最優(yōu)推薦。具體來(lái)說,我們最小化 OBJ 以獲得過去樣本的最優(yōu)目標(biāo)推薦,并將這個(gè)最小化問題描述為混合整數(shù)線性規(guī)劃(Mixed Integer Linear Program,MILP).
機(jī)器學(xué)習(xí)預(yù)測(cè)(Machine Learning Forecast):在 MILP 計(jì)算出過去 M 個(gè)時(shí)間間隔的目標(biāo)值后,本模塊將這 M 個(gè)最佳歷史推薦作為輸入,并根據(jù)機(jī)器學(xué)習(xí)算法中定義的預(yù)測(cè)水平 F 預(yù)測(cè)下一個(gè)(一個(gè)或多個(gè))更新間隔的最佳未來(lái)推薦。
特性二、時(shí)序沖突檢測(cè)調(diào)度
算法思想
PAWS 開發(fā)了一套調(diào)度插件,通過利用負(fù)載歷史數(shù)據(jù)中提取的資源利用率并進(jìn)行時(shí)序分析統(tǒng)計(jì),并讓調(diào)度器基于該統(tǒng)計(jì)對(duì)負(fù)載進(jìn)行錯(cuò)峰填谷,避免資源沖突的同時(shí)實(shí)現(xiàn)更高的資源分配。其使用了中的機(jī)制,對(duì)于系統(tǒng)中標(biāo)記的進(jìn)行資源的采集。通過收集作業(yè)容器的歷史資源使用情況,分析時(shí)間序列周期(如每小時(shí)),輸出每個(gè)周期周期的預(yù)估資源利用率,從而避免作業(yè)資源沖突,最終實(shí)現(xiàn)錯(cuò)峰補(bǔ)谷的調(diào)度,提升集群資源利用率。
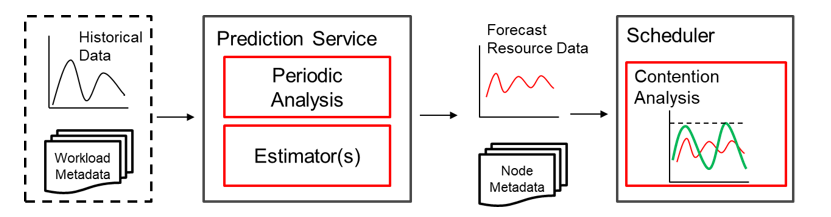
算法流程
整個(gè)算法分為預(yù)測(cè)和調(diào)度兩個(gè)部分,其中預(yù)測(cè)主要基于每種負(fù)載的歷史數(shù)據(jù),統(tǒng)計(jì)其時(shí)序變化情況,以供調(diào)度器使用;調(diào)度則基于上述信息,結(jié)合新任務(wù)的特征情況,給出合理的調(diào)度決策。
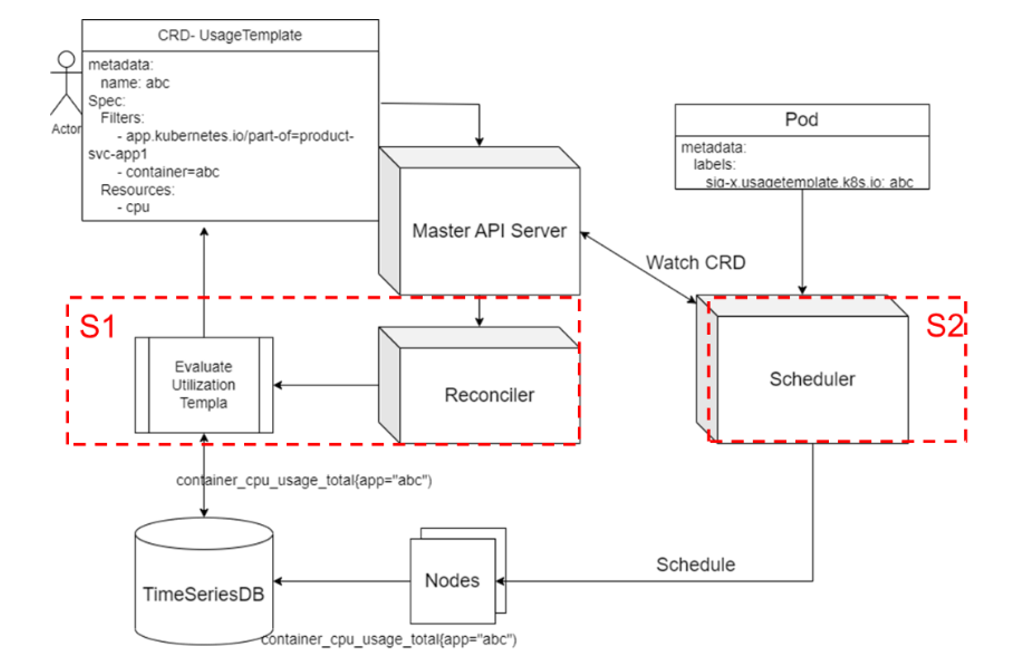
預(yù)測(cè)流程:通過 Prometheus 等時(shí)序數(shù)據(jù)庫(kù),讀取每個(gè)已知負(fù)載的資源利用率歷史數(shù)據(jù)點(diǎn),分析出小時(shí)維度的變化情況,并保存為歷史數(shù)據(jù),以供調(diào)度器參考。
調(diào)度流程:對(duì)于新來(lái)的任務(wù),基于任務(wù)標(biāo)簽來(lái)判斷具體策略。對(duì)于已知任務(wù),從調(diào)度器中選取歷史模板,與每個(gè)節(jié)點(diǎn)歷史數(shù)據(jù)進(jìn)行疊加求和;對(duì)于未知任務(wù),則基于任務(wù)資源 request 與節(jié)點(diǎn)數(shù)據(jù)進(jìn)行疊加求和。在 Scoring 階段,當(dāng)存在任務(wù)運(yùn)行周期階段超過閾值的可能性,進(jìn)行不同的打分并歸一。于此同時(shí),系統(tǒng)對(duì)于未知任務(wù)會(huì)實(shí)時(shí)統(tǒng)計(jì)其資源利用率,確保后續(xù)該任何再次被拉起時(shí)可能進(jìn)行更精確的打分。
[結(jié)果評(píng)估]
文中所述的 Performance Aware System 通過機(jī)器學(xué)習(xí)與數(shù)理分析手段,對(duì)負(fù)載資源的分配與調(diào)度進(jìn)行優(yōu)化。我們?cè)趯?shí)驗(yàn)室場(chǎng)景下模擬了包括 Redis,Nginx 和 Torchserve 等在內(nèi)的一些典型應(yīng)用,并通過搭建 10 臺(tái)服務(wù)器的小型集群進(jìn)行驗(yàn)證。通過測(cè)試發(fā)現(xiàn),集群整體利用率在部署前后出現(xiàn)明顯的提升。下圖為其中某一個(gè)節(jié)點(diǎn)的利用率變化情況,該節(jié)點(diǎn)的峰值利用率從 30%提升到了 40%以上。
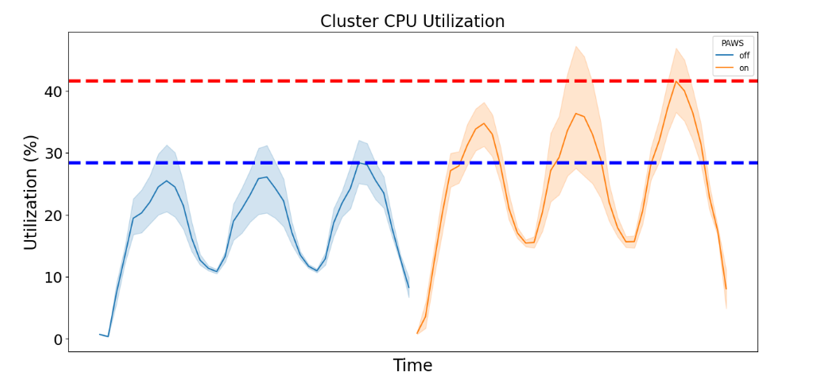
我們同時(shí)對(duì)部署前后的業(yè)務(wù)性能變化進(jìn)行了對(duì)比,發(fā)現(xiàn) P99 時(shí)延劣化在 10%以內(nèi),證明了算法在提升集群利用率的同時(shí)也能有效避免性能出現(xiàn)下降。
| 任務(wù)名稱 | 負(fù)載類型 | P99 時(shí)延(前) | P99 時(shí)延(后) | 性能劣化 |
|---|---|---|---|---|
| Ngix | CPU / Net 密集型 | 437.7 | 447.6 | 2% |
| Redis | Memory 密集型 | 0.019 | 0.021 | 10% |
| Torchserve | CPU 密集型 | 316.2 | 302.2 | 0% |
目前本特性代碼已在 openEuler Cloud Native SIG 進(jìn)行開源,地址為:https://gitee.com/openeuler/paws
于此同時(shí),本方案仍然存在一些不夠完美的地方,比如當(dāng)前本方案主重點(diǎn)瞄準(zhǔn) CPU 計(jì)算密集型場(chǎng)景,但是在實(shí)際場(chǎng)景中,內(nèi)存以及 IO 可能都成為影響業(yè)務(wù)的瓶頸點(diǎn),同時(shí)資源競(jìng)爭(zhēng)導(dǎo)致的性能下降也很難 100%從利用率的角度進(jìn)行監(jiān)控。因此也希望對(duì)該技術(shù)方向有興趣的伙伴能加入該 SIG,對(duì) PAWS 進(jìn)行持續(xù)優(yōu)化。
審核編輯:黃飛
-
cpu
+關(guān)注
關(guān)注
68文章
11048瀏覽量
216114 -
算法
+關(guān)注
關(guān)注
23文章
4701瀏覽量
94843 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
5164瀏覽量
73238 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3904瀏覽量
65818 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134161
原文標(biāo)題:openEuler 資源利用率提升之道 07:PAWS 性能感知系統(tǒng)簡(jiǎn)介
文章出處:【微信號(hào):openEulercommunity,微信公眾號(hào):openEuler】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
人工智能感知技術(shù)是安防機(jī)器人應(yīng)用支撐技術(shù)之一
安森美智能感知技術(shù)對(duì)三大應(yīng)用領(lǐng)域發(fā)展有什么影響?
智能感知怎么助力機(jī)器視覺發(fā)展?
big.LITTLE和GPU相結(jié)合可以實(shí)現(xiàn)性能和功耗的最佳匹配
基于虛擬儀器的智能感知專家系統(tǒng)的設(shè)計(jì)
基于虛擬儀器的智能感知專家系統(tǒng)的設(shè)計(jì)
智能感知的發(fā)展現(xiàn)狀_智能感知的未來(lái)
最新機(jī)器學(xué)習(xí)工具對(duì)材料進(jìn)行計(jì)算建模相結(jié)合
AI和機(jī)器學(xué)習(xí)與能源結(jié)合有助于加快可再生能源的采用
LSTM和注意力機(jī)制相結(jié)合的機(jī)器學(xué)習(xí)模型

NVIDIA發(fā)布高性能感知技術(shù)的最新項(xiàng)目






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論