") 如何利用緩存讓CPU更有效率地執(zhí)行代碼?
如何利用緩存讓CPU更有效率地執(zhí)行代碼?

數(shù)組遍歷方式
我們先來看一個很經(jīng)典的例子(例子是C語言寫的,其他語言實(shí)現(xiàn)也都是差不多的):
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
int main()
{
clock_t begin, end;
double cost;
begin = clock();
int count = 10000;
int* array = (int*)malloc(sizeof(int) * count * count);//2維數(shù)組
//代碼1 按行遍歷
//for (int i = 0;i < count;i++) {
// for (int j = 0; j < count; j++) {
// array[i * count + j] = 0;
// }
//}
//代碼2 按列遍歷
for (int i = 0;i < count;i++) {
for (int j = 0; j < count; j++) {
array[j * count + i] = 0;
}
}
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
運(yùn)行結(jié)果:
#代碼1
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.126000
#代碼2
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.301000
CLOCKS_PER_SEC=1000,表示當(dāng)前電腦1秒是被分成了1000個時間片,也就是說時間測量最小單位為1ms
所以上述代碼1,在筆者的電腦運(yùn)行耗時大約0.126ms;而代碼2,運(yùn)行耗時卻高達(dá)0.301ms
這2段代碼塊 基本一致,唯獨(dú)遍歷方式不同 ,代碼1是按行遍歷,而代碼2是按列遍歷
無非是遍歷方式不一樣,但為啥運(yùn)行效率會差這么多呢?
我們知道在內(nèi)存中,數(shù)組一般是按行存儲的,如array[0][0],array[0][1],...,array[2][0],array[2][1],...
上述代碼塊1是按行遍歷,而代碼塊2是按列遍歷,按行遍歷時可以由指向數(shù)組第一個數(shù)的指針一直往下走,就可以遍歷完整個數(shù)組,而按列遍歷則要獲得指向每一列的第一行的元素的指針,然后每次將指針指下一行,但是指針的尋址很快,所以在內(nèi)存中這2種數(shù)組遍歷方式的效率,不會有明顯的區(qū)別
那為啥運(yùn)行效率會差這么多呢
其實(shí)這個背后其實(shí)是CPU Cache起作用!筆者吐血畫了張圖幫助大家更直觀地了解原理
:
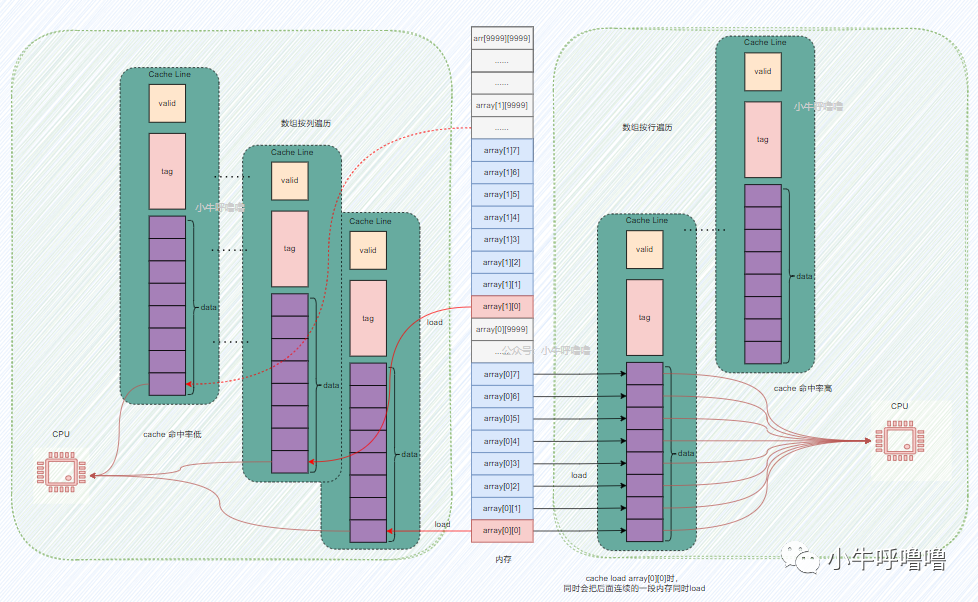
上圖,左邊是數(shù)組按列遍歷的情況,右邊是按行遍歷的情況,筆者把他們合到了一張圖上,這樣對比度更強(qiáng)
我們知道CPU Cahce利用了空間局部性的原理來提高性能,如果一個內(nèi)存的位置被引用,那么將來它附近的位置也會被引用
也就是說當(dāng)數(shù)組按行遍歷時,當(dāng)訪問第一個數(shù)組元素array[0][0],CPU會在緩存中,尋找這個內(nèi)存地址對應(yīng)的Cache Line,這時候肯定找不到啊,發(fā)生緩存缺失cache miss,會觸發(fā)CPU把array[0][0]地址處以及后面連續(xù)的一段內(nèi)存都load到Cache Line中,這個時候訪問數(shù)組中第2~8個元素,會直接在CPU Cache中找到對應(yīng)的數(shù)據(jù),即緩存命中cache hit,這樣就不需要訪問內(nèi)存了;直到訪問第9個數(shù)組元素,再次發(fā)生cache miss,周而復(fù)始直到程序結(jié)束
CPU每次能加載多少內(nèi)存到Cache Line中,主要取決于Cache Line的容量,上圖只是舉個例子,一般主流的 CPU 的 Cache Line 大小是64 Byte,過大或者過小都會影響性能
我們可以發(fā)現(xiàn)按行遍歷時, 訪問數(shù)組元素的順序,是與內(nèi)存中數(shù)組元素存放的順序一致 ,每次發(fā)生cache miss,都加載一堆內(nèi)存區(qū)域的數(shù)據(jù),數(shù)組后續(xù)元素都能在緩存中找到對應(yīng)的數(shù)據(jù),這樣緩存命中率較高,從而減少緩存缺失導(dǎo)致的開銷
而按列遍歷時, 訪問數(shù)組元素的順序,是和內(nèi)存中數(shù)組元素存放的順序不一致,跳躍式訪問 ,每次發(fā)生cache miss,哪怕都加載一堆內(nèi)存區(qū)域的數(shù)據(jù),像上圖一樣每次緩存只能命中1次,會導(dǎo)致頻繁發(fā)生cache miss,因此緩存命中率特別低
而 緩存讀寫速度要遠(yuǎn)遠(yuǎn)快于內(nèi)存的讀寫速度 ,這里筆者再次拿出經(jīng)典的儲存器金字塔圖,在馮諾依曼架構(gòu)下,計算機(jī)存儲器是分層次的,存儲器的層次結(jié)構(gòu)如下圖所示,是一個金字塔形狀的東西。從上到下依次是寄存器、緩存、主存(內(nèi)存)、硬盤等等

離CPU越近的存儲器,訪問速度越來越快,容量越來越小,每字節(jié)的成本也越來越昂貴
比如一個主頻為3.0GHZ的CPU,寄存器的速度最快,可以在1個時鐘周期內(nèi)訪問,一個時鐘周期(CPU中基本時間單位)大約是0.3納秒,內(nèi)存訪問大約需要120納秒,固態(tài)硬盤訪問大約需要50-150微秒,機(jī)械硬盤訪問大約需要1-10毫秒,最后網(wǎng)絡(luò)訪問最慢,得幾十毫秒左右。
這個大家可能對時間不怎么敏感,那如果我們把 一個時鐘周期如果按1秒算的話,那寄存器訪問大約是1s,內(nèi)存訪問大約就是6分鐘 ,固態(tài)硬盤大約是2-6天 ,傳統(tǒng)硬盤大約是1-12個月,網(wǎng)絡(luò)訪問就得幾年了 !我們可以發(fā)現(xiàn)CPU的速度和內(nèi)存等存儲器的速度,完全不是一個量級上的。
所以盡可能地讓代碼只訪問緩存,避免頻繁訪問內(nèi)存,能極大地提高代碼性能,所以數(shù)組按行遍歷要遠(yuǎn)遠(yuǎn)快于是按列遍歷,當(dāng)然前提條件數(shù)組在內(nèi)存中是按行儲存的
循環(huán)的步長
我們這里還是舉一個經(jīng)典例子:
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
int main()
{
clock_t begin, end;
double cost;
begin = clock();
const int LEN = 64 * 1024 * 1024;
int* arr = (int*)malloc(sizeof(int) * LEN);
//代碼1
//for (int i = 0; i < LEN; i += 2) arr[i] *= 3;
//代碼2
for (int i = 0; i < LEN; i += 8) arr[i] *= 3;
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
代碼1這個循環(huán)功能是將數(shù)組的每2個值乘3,代碼2循環(huán)則將每8個值乘3,也就是代碼1應(yīng)該比代碼少4倍的計算量,那有人可能會認(rèn)為,時間也會節(jié)約4分之三
但真的是這樣嗎?
我們直接來看運(yùn)行結(jié)果:
#代碼1
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.068000
#代碼2
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.058000
我們發(fā)現(xiàn)在筆者的電腦跑下來,時間分別是:0.068ms,0.058ms;它們的耗時其實(shí)差不多,遠(yuǎn)遠(yuǎn)沒有4倍差距那么大
其實(shí) 循環(huán)執(zhí)行時間長短由數(shù)組的內(nèi)存訪問次數(shù)決定的,而非整型數(shù)的乘法運(yùn)算次數(shù) ;因?yàn)檫@個時候緩存已經(jīng)起作用了,當(dāng)緩存丟失時,CPU這個時候會將一段內(nèi)存加載到緩存中,以Cache Line為單位,一般是64Byte
而上述代碼中無論步長是2還是8,都是在一個Cache Line中,CPU訪問同一個緩存行內(nèi)其它值的開銷是很小的;另一方面這兩個循環(huán)的主存訪問次數(shù)其實(shí)是一樣的。所以這2個循環(huán)耗時相差不大
但這并不意味這步長無論多大都是這樣的,是有一個臨界點(diǎn)的;在C語言中,一個整型=4個字節(jié),所以16個整型數(shù)占用64字節(jié)(Byte)=一個Cache Line(64Byte)
因此當(dāng)Cache Line大小為64Byte時,步長在1~16范圍內(nèi),循環(huán)運(yùn)行時間相差不大。但從16往后,每次步長加倍,運(yùn)行時間減半

上圖來源于Gallery of Processor Cache Effects
偽共享和緩存行對齊
我們再來看一個多線程的例子:
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
#include < pthread.h >
struct S {
long long a;
//long long noop[8];
long long b;
} s;
void* threadA(void* p)
{
for (int i = 0; i < 100000000; i++) {
s.a++;
}
return NULL;
}
void* threadB(void* p)
{
for (int i = 0; i < 100000000; i++) {
s.b++;
}
return NULL;
}
int main()
{
clock_t begin, end;
double cost;
begin = clock();
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, threadA, NULL);
pthread_create(&thread2, NULL, threadB, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
運(yùn)行結(jié)果:
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.194000
上述例子,表示2個線程同時修改兩個相鄰的變量(在一個結(jié)構(gòu)體內(nèi)),而在C語言中,long類型占8個字節(jié),所以這2個變量a、b都在同一個Cache Line中;另外在如今多核CPU的時代,2個線程可能由不同核心分別執(zhí)行,那么緩存一致性的問題不可避免。
我們知道, 緩存的加載更新不是以字節(jié)為單位,而是以Cache Line為單位 ,在基于mesi協(xié)議下,當(dāng)2個線程同時修改兩個相鄰的變量,整個Cache Line都會被整個刷新

這會出現(xiàn)一個偽共享現(xiàn)象:當(dāng)線程A讀取變量a,并修改a,線程A在未寫回緩存之前,同時另一個線程B讀取了b,讀取這個b所在的緩存,由于緩存一致性協(xié)議,其實(shí)該緩存行處于無效狀態(tài),需要重新加載緩存。這就是 緩存?zhèn)喂蚕韋alse-sharing 。使用緩存的本意是為了提高性能,但是現(xiàn)在場景下,多個線程在不同的CPU核心上高頻反復(fù)訪問這種CacheLin偽共享的變量,會嚴(yán)重犧牲性能
所以我們寫代碼的時候需要注意偽共享問題,那如何解決呢?
其實(shí)也很簡單,我們只要保證多線程需要同時操作的變量不在同一個Cache Line中即可,我們這里Cache Line的大小為64字節(jié),最簡單的方法我們只需在這個例子的結(jié)構(gòu)體中,再加一行代碼
struct S {
long long a;
long long noop[8];
long long b;
} s;
long long noop[8];占用8*8=64字節(jié),也就是一個Cache Line的大小,這樣就能保證變量a、b不在同一個Cache Line中,這樣就不會再出現(xiàn)偽共享現(xiàn)象
最后我們校驗(yàn)一下,從最終執(zhí)行結(jié)果來看,時間確實(shí)節(jié)約了不少:
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.148000
當(dāng)然還有其他優(yōu)化方式,比如編譯器直接優(yōu)化,如果我們對偽共享現(xiàn)象 反向思考 ,當(dāng)有多個小變量并不涉及到很復(fù)雜的讀寫依賴,那么我們應(yīng)該盡可能將這些小變量放在同一個緩存行Cache Line上,這個也叫做緩存行對齊
因?yàn)檫@些小變量可能散落在內(nèi)存的各個地方,降低緩存命中率,就得多次加載到緩存,那如果能一起加載到同一個緩存行上,緩存命中率就能大大提高,從而提升代碼的性能
在C語言中,為了避免偽共享,編譯器會自動將結(jié)構(gòu)體,字節(jié)補(bǔ)全以及 內(nèi)存對齊 (內(nèi)存對齊就不展開講了,感興趣地自行去了解一下);另外對齊的大小最好是緩存行的長度,這樣緩存只要load一次即可
#define CACHE_LINE 64 //緩存行長度
struct S1 {int a, b, c, d;} __attribute__ ((aligned(CACHE_LINE)));//__align用于顯式對齊,這種方式使得結(jié)構(gòu)體字節(jié)對齊的大小為緩存行的大小
最后再補(bǔ)充一個,Linux提供一個函數(shù),sched_setaffinity可以在多核CPU系統(tǒng)中,設(shè)置線程的CPU親和力,使線程綁定在某一個或幾個CPU核心上運(yùn)行,避免在多個核心之間來回切換,因?yàn)長3 Cache 是多核心之間共享的,但L1 和 L2 Cache都是每個核心獨(dú)有的,如果線程都在同一個核心上執(zhí)行,能夠減少保證緩存一致性的操作,從而減少訪問內(nèi)存的頻率,提升程序性能。
-
寄存器
+關(guān)注
關(guān)注
31文章
5432瀏覽量
124042 -
存儲器
+關(guān)注
關(guān)注
38文章
7644瀏覽量
166943 -
C語言
+關(guān)注
關(guān)注
180文章
7631瀏覽量
141105 -
Cache
+關(guān)注
關(guān)注
0文章
130瀏覽量
29008 -
緩存器
+關(guān)注
關(guān)注
0文章
63瀏覽量
11864
發(fā)布評論請先 登錄
重大進(jìn)展!輝瑞新冠疫苗有效率達(dá)到90% 明年產(chǎn)能13億
如何才能有效率的學(xué)習(xí)單片機(jī)
畫PCB封裝的方法哪個更有效率
請問CH579有效率比較高的量產(chǎn)燒錄工具嗎?
如何實(shí)現(xiàn)更有效率的產(chǎn)線各工業(yè)設(shè)備數(shù)據(jù)采集?
六個助你創(chuàng)建運(yùn)行更有效率Python應(yīng)用的竅門

CPU緩存是什么意思_CPU緩存有什么作用
如何寫出讓CPU執(zhí)行更快的代碼?

緩存如何工作,如何設(shè)計CPU緩存
CPU緩存的作用及原理有哪些
工業(yè)設(shè)備的數(shù)據(jù)如何更有效率的采集?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論