 大語言模型簡介:基于大語言模型模型全家桶Amazon Bedrock
大語言模型簡介:基于大語言模型模型全家桶Amazon Bedrock
本文基于亞馬遜云科技推出的大語言模型與生成式AI的全家桶:Bedrock對大語言模型進行介紹。大語言模型指的是具有數十億參數(B+)的預訓練語言模型(例如:GPT-3, Bloom, LLaMA)。這種模型可以用于各種自然語言處理任務,如文本生成、機器翻譯和自然語言理解等。
大語言模型的這些參數是在大量文本數據上訓練的。現有的大語言模型主要采用 Transformer 模型架構,并且在很大程度上擴展了模型大小、預訓練數據和總計算量。他們可以更好地理解自然語言,并根據給定的上下文(例如 prompt)生成高質量的文本。其中某些能力(例如上下文學習)是不可預測的,只有當模型大小超過某個水平時才能觀察到。
今年 9 月,亞馬遜云科技正式發布 Amazon Bedrock,這是一套生成式 AI 全托管服務,包含業界領先的基礎大語言模型和構建生成式 AI 應用程序所需的一系列功能。Amazon Bedrock 匯聚了業內幾乎所有領先的基礎大語言模型,面對不同應用場景,它可以讓人們只需通過單一 API 就能用上來自 AI21 Labs、Anthropic、Cohere、Meta Llama2、Stability AI 等公司的先進大語言模型來構建自己的應用。
大語言模型的關鍵特征:
深度學習和神經網絡: 大語言模型通常基于深度學習技術,其中包含許多神經網絡層。這些神經網絡通過大量的文本數據進行訓練,以學習語言的結構和規律。
預訓練和微調: 大語言模型通常通過兩個主要階段進行訓練。首先是預訓練階段,其中模型在大規模的文本數據上進行訓練,學習語言的通用模式。然后,在微調階段,模型根據特定任務或領域的數據進行微調,以適應更具體的需求。
自注意力機制: 大語言模型中常使用自注意力機制(Self-Attention Mechanism),例如Transformer模型。這種機制使得模型能夠在處理輸入時對不同位置的信息分配不同的注意力權重,有助于捕捉長距離依賴關系。
生成文本: 大語言模型能夠生成自然語言文本,可以應用于各種任務,如文章寫作、對話生成、代碼生成等。
參數數量: 大語言模型通常擁有大量的參數。例如,GPT-4的模型參數在1.8萬億左右、13萬億訓練數據,一次訓練成本6300萬美元等。
通用性: 預訓練的大語言模型通常是通用的,可以用于多種自然語言處理任務,而不需要針對特定任務進行額外的監督訓練。
應用領域: 大語言模型在自然語言處理、對話系統、翻譯、摘要生成、問答系統等領域具有廣泛的應用。
對于大語言模型的應用場景,絕大多數的客戶并不需要自己從零開始來訓練模型,不能依賴一個萬能的、單一的大語言模型來應對各種任務,正確的做法應該是,訪問多個模型,然后根據自己的需求和數據來定制自己的模型。這也是為什么Amazon Bedrock 被稱作是大語言模型“全家桶”。
在這數字化的風正吹著世界每個角落的時代,大語言模型雖好,但個人開發者和企業級應用開發、構建和調優自己的大語言模型是很困難的,于是,Amazon Bedrock便應運而生。Bedrock最重要的特色,就是讓開發者能夠輕松定制大語言模型,并構建屬于自己的生成式AI應用程序。
審核編輯:湯梓紅
-
AI
+關注
關注
88文章
34520瀏覽量
276049 -
語言模型
+關注
關注
0文章
561瀏覽量
10704
發布評論請先 登錄
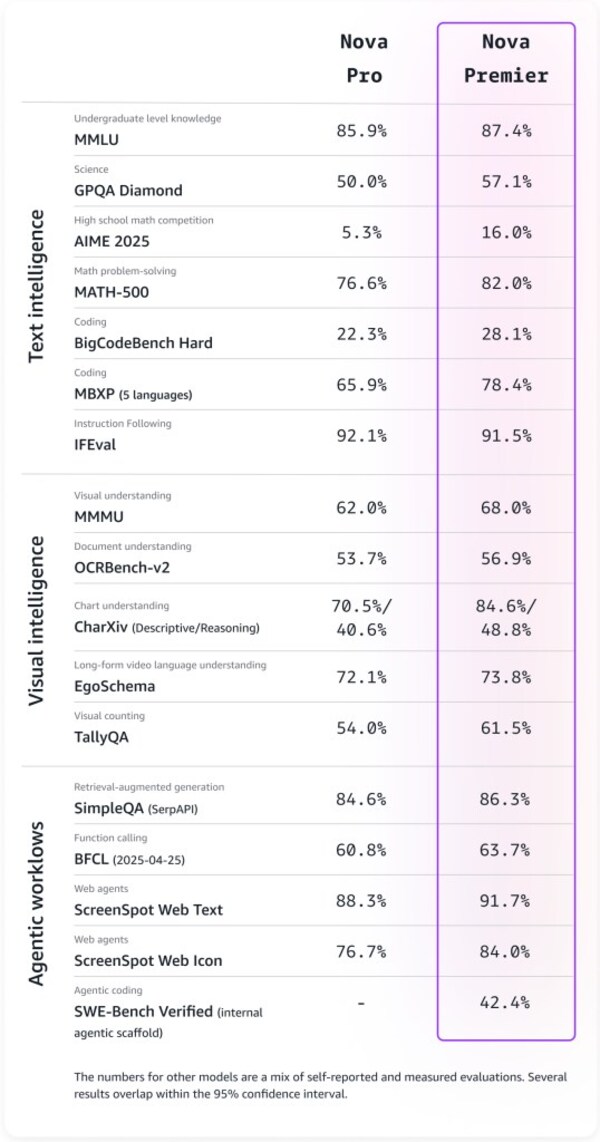
亞馬遜功能最強模型Amazon Nova Premier現已正式可用
Amazon Bedrock全新升級,新增業界領先的AI防護、新智能體功能和模型定制能力
Amazon Bedrock推出多個新模型和全新強大的推理和數據處理功能
大語言模型開發語言是什么
云端語言模型開發方法
大語言模型如何開發
新品|LLM Module,離線大語言模型模塊






 工商網監
工商網監
評論