 如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
背景介紹
大語言模型正以其驚人的新能力推動人工智能的發展,擴大其應用范圍。然而,由于這類模型具有龐大的參數規模,部署和推理的難度和成本極高,這一挑戰一直困擾著 AI 領域。此外,當前存在大量支持模型部署和推理的框架和工具,如 ModelScope 的 Model Pipelines API 和 HuggingFace 的 Text Generation Inference 等,各自都有其獨特的特點和優勢。然而,這些工具往往未能充分發揮 GPU 的性能。
為了解決這些問題,NVIDIA 推出了一種全新的解決方案——TensorRT-LLM。這是一款高度優化的開源計算框架,它將NVIDIA TensorRT的深度學習編譯器、FasterTransformer 的優化內核、預處理和后處理,以及多 GPU/多節點通信等功能封裝在一個簡單的開源 Python/C++ API 中,同時與硬件進行了一體化優化,形成了一種產品級的大模型推理解決方案。NVIDIA TensorRT-LLM具有多項突出的特性,包括支持新的 FP8 數據格式,這使得模型可以在更低的精度下運行,從而減少內存消耗,同時保持模型的準確性。它還支持一種名為“In-flight batching”的新調度技術,可以更有效地處理動態負載,提高 GPU 利用率。
此外,TensorRT-LLM 還支持模型的并行化和分布式推理,利用張量并行性進行模型并行化,使模型可以在多個 GPU 之間并行運行,從而實現大型模型的高效推理。最重要的是,TensorRT-LLM 極大地簡化了開發流程,使得開發者無需深入了解底層的技術細節,也無需編寫復雜的 CUDA/C++ 代碼。它提供了一個易用、開源和模塊化的應用編程接口,使開發者能夠輕松定義、優化和執行新的大語言模型架構和增強功能。總的來說,TensorRT-LLM 讓用戶可以專注于模型的設計和優化,而將底層的性能優化工作交給 TensorRT 來完成,大大提高了開發效率和生產效率,真正實現了大模型推理的易用性和高效性。
阿里云的通義千問開源模型 Qwen-7B,擁有 70 億參數,在一系列全方位的評估中展示了其在自然語言理解與生成、數學問題求解、代碼生成等領域的優秀能力。這些評估涵蓋了多個數據集,包括 MMLU、C-Eval、GSM8K、HumanEval 以及 WMT22 等。在這些評測中,Qwen-7B 不僅超越了同等規模的其他大語言模型,甚至在某些方面超過了參數規模更大的模型。因此,對于 TensorRT-LLM 來說,支持 Qwen 系列模型具有重要的意義。
開發與優化過程
我們是社區開發者,通過阿里云天池舉辦的NVIDIA TensorRT Hackathon 2023接觸到了 NVIDIA TensorRT-LLM,并為它貢獻了代碼。TensorRT-LLM 已開源(https://github.com/NVIDIA/TensorRT-LLM),包含了我們開發的 Qwen-7B 模型。以下是我們的開發記錄,供其他開發者參考。
基礎功能支持
-
首先我們初步分析了 examples/llama 代碼,以深化對 trt-llm 基本流程的理解。在 llama 項目的 weight.py 中,存在一個 load_from_meta_llama 函數,該函數包含 tensorrt_llm.models.LLaMAForCausalLM,此部分定義了 TensorRT 的模型結構。復制 examples/llama 并將其重命名為 examples/qwen,同時將 LLaMAForCausalLM 復制并創建新的 mode.py 文件,將相關內容粘貼至此。在這個過程中,所有包含“llama”的模型都被替換為“qwen”。
-
接下來,我們對項目中的 weight.py 的 load_from_hf_qwen 函數進行修改,目的是逐步將 HuggingFace 的權重名稱與 TensorRT 的權重名稱對齊。執行 build.py 后,雖然編譯成功,但執行 run.py 的結果并未如預期。
-
參照 TensorRT-LLM 的 docs/source/2023-05-19-how-to-debug.md 文檔,我們對模型進行了詳細的調試,從外到內打印模型層的數值,觀察 mean/sum/shape,并與原版進行對比。經過排查,我們發現 attention 部分已經包含了 rope 計算,通過調整 gpt attention plugin 的參數,最終使得輸出的 logits 正常。
-
再次優化 run.py,將 HuggingFace 原版 qwen_generation_utils.py 中的 make_context 函數遷移到 utils/utils.py 中,并導入該函數。這個函數被用來構造一個 chat 版的 prompt 輸入,同時我們調整 eos 和 pad token 為 qwen 專屬的 <|im_end|> 或者 <|endoftext|>,最終 run.py 輸出也正常。
增加功能:Weight Only 量化
在 FP16 對齊成功,并且 run.py 以及 summarize.py 文件均能正常運行之后,我們開始探索實現 weight only int8/int4 量化。這只需要在 build.py 文件中對 weight only int8/int4 分支進行輕微調整,包括 shape 的修改,以及保持權重名稱與 FP16 一致。接下來,我們進行編譯測試,發現這一過程順利完成,且工作量并未超出預期,這部分工作基本無需投入大量人力資源。
增加功能:Smooth Quant
-
在參考 Llama 項目的基礎上,我們將 hf_llama_convert.py 替換為 hf_qwen_convert.py 文件,該文件用于將 HuggingFace 的權重導出至 FasterTransformer (FT) 格式的文件。同時,我們將 llama/weight.py 中的 load_from_binary 函數重命名為 load_from_ft 復制到 qwen/weight.py 中,并根據我們導出的權重文件進行了適當的修改。然后,我們將 qwen/build.py 中默認的加載函數從 load_from_hf_qwen 更改為 load_from_ft。為了保證兼容性,我們也對 load_from_ft 函數進行了 fp16 以及 weight_only 的 int8/int4 的適配,其適配流程與之前的基本相同。當開發者未導出 FT 權重時,系統會自動加載 load_from_hf_qwen 函數以生成 engine。
-
在 smooth quant 的實現方面,我們參考了 example/llama 的 smooth quant 過程,同樣在 hf_qwen_convert.py 中添加了 --smoothquant 選項。通過調試 example/llama/hf_llama_convert.py 文件,我們觀察了 smooth_llama_model 函數的計算方法以及參數的 shape,發現其 mlp 的 gate 和 up 與 qwen mlp 的 w2/w1 layer 相對應,并且 w1/w2 共享一個輸入。這部分的適配與之前的基本一致,唯一的區別是,attention 和 mlp 中需要量化的層需要進行轉置,然后在 weight.py 的 load_from_ft 函數中再次轉置回來。
-
我們再次分析了 example/llama 的 smooth quant 過程,并參考了其 build.py 文件,發現其中一個有一個 from tensorrt_llm.models import smooth_quantize 過程。在這個過程中,_smooth_quantize_llama 函數會替換掉 trt-llm 原本的模型結構。因此,我們在 qwen/utils 目錄下建立了一個 quantization.py 文件,參考了 llama 的 SmoothQuantAttention,并復用了其 SmoothQuantRmsNorm,從而實現了 qwen 的 smooth quant 的全部過程。
優化效果
精度
-
測試平臺:NVIDIA A10 Tensor Core GPU(24G 顯存) | TensorRT 9.0.0.1。
-
TRT_LLM engine 編譯時最大輸入長度:2048, 最大新增長度:2048。
-
HuggingFace 版 Qwen 采用默認配置,未安裝,未啟用 FlashAttention 相關模塊。
-
測試時:beam=batch=1,max_new_tokens=100。
-
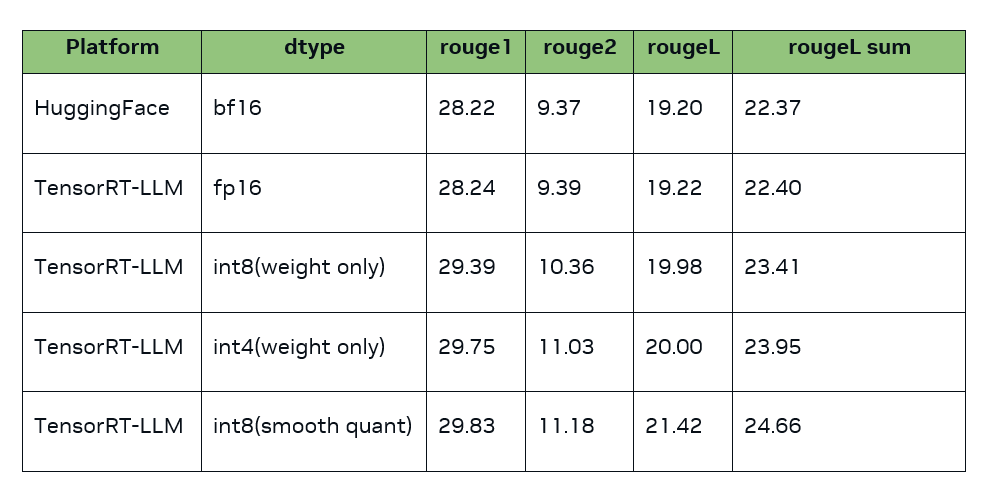
測試結果(該結果由 examples/qwen/summarize.py 生成。注:量化后分數與原版分數越接近,精度越好):
性能
-
測試平臺:NVIDIA A10 Tensor Core GPU (24G 顯存) | TensorRT 9.0.0.1。
-
測試數據集為 ShareGPT_Vicuna_unfiltered,下載地址:https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
-
生成速度(token/s):此指標不僅包括 generation 的過程,同時也計算了 context 階段時間,因此它表示的是每秒實際處理(理解輸入和生成輸出)的 token 數量。
-
吞吐速度(requests/s):此指標代表在極限情況下,無請求間隙時,系統平均每秒能處理的請求數量。
-
以下的測試包含多個 batch,主要用于測試特定顯卡的極限運行情況,測試過程僅使用 TensorRT-LLM python 運行時環境。
-
HuggingFace 版 Qwen 采用默認配置,未安裝,未啟用 FlashAttention 相關模塊。
-
當最大輸入長度:2048, 最大新增長度:2048,num-prompts=100, beam=1, seed=0 時,BenchMark 結果如下:
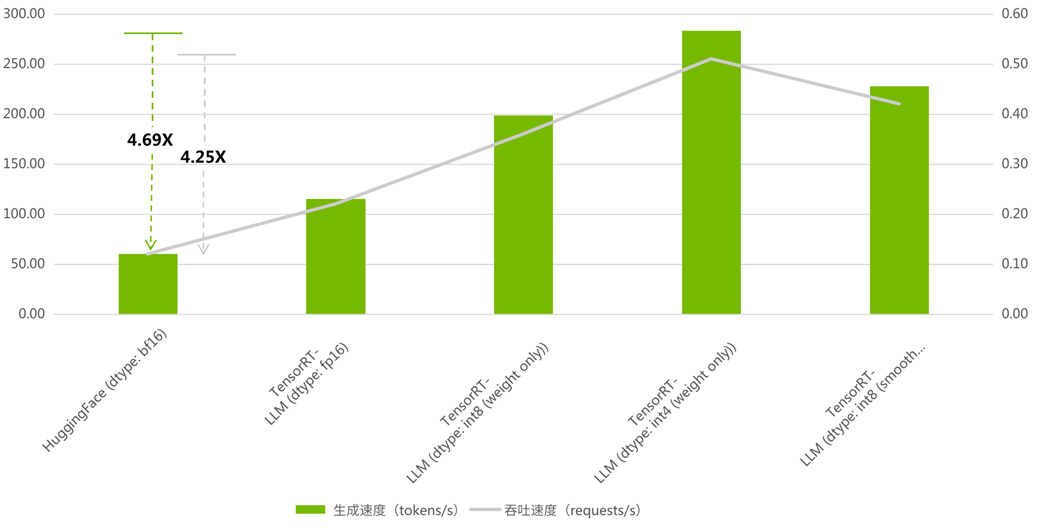
圖 1:TensorRT-LLM 與 HuggingFace
吞吐以及生成對比
(吞吐加速比最高 4.25, 生成加速比最高 4.69)
-
當最大輸入長度:1024, 最大新增長度:1024,num-prompts=100, beam=1, seed=0。BenchMark 結果如下:
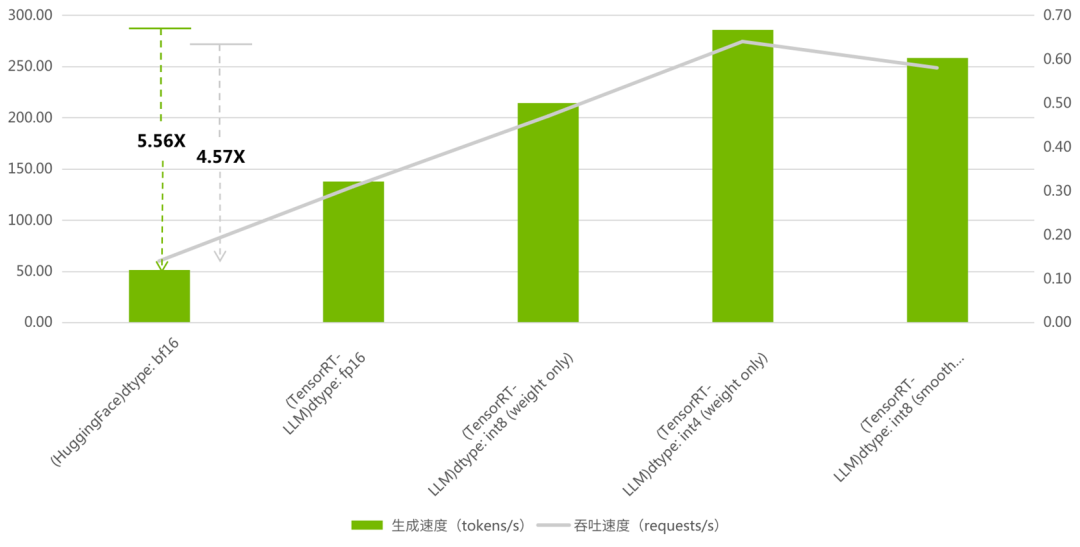
圖 2:TensorRT-LLM 與 HuggingFace
吞吐以及生成對比
(吞吐加速比最高 4.57, 生成加速比最高 5.56)
總結
從整個開發過程的角度來看,NVIDIA TensorRT-LLM 已經實現了相當豐富的功能。它支持新模型的工作量不大,因為可以復用已有模型的相關代碼,只需要進行少量的改動即可完成對新模型的支持。這表明了 TensorRT-LLM 具有很好的擴展性。此外,在精度方面,它能夠與 HuggingFace 保持一致,但在速度方面最高可以達到 HuggingFace 的 5.56 倍。綜合考慮這些因素,可以說 TensorRT-LLM 完全有資格成為大規模語言模型推理框架的首選。它極大地緩解了推理和部署的難題,為廣泛應用大語言模型提供了有力支持。
項目代碼
開源地址:
https://github.com/Tlntin/Qwen-7B-Chat-TensorRT-LLM
關于作者
 ?
?鄧順子
廣州大學工程管理專業,擁有管理學學士學位,目前擔任 NLP 算法工程師,主要研究留學教育領域的信息抽取與智能對話。曾獲得第二十一屆中國計算語言學大會(CCL2022)航旅縱橫杯一等獎(子任務二)和三等獎(子任務一),也是熱門 Rust 開源項目 Pake 的主要貢獻者之一。
 ?
?趙紅博
河南科技大學機械制造專業,擁有工學學士學位,目前在 Boss 直聘擔任高性能計算開發工程師,主要研究招聘領域模型的推理加速工作。
 ?
?季光
NVIDIA DevTech 團隊經理,博士畢業于中科院計算所。擅長 GPU 加速的視頻處理以及性能優化,以及深度學習模型的推理優化,在 GPU 視頻編解碼以及 CUDA 編程與優化方面積累了豐富的經驗。
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3927瀏覽量
93284
原文標題:如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

壁仞科技完成Qwen3旗艦模型適配
NVIDIA使用Qwen3系列模型的最佳實踐

摩爾線程GPU率先支持Qwen3全系列模型
壁仞科技完成阿里巴巴通義千問Qwen3全系列模型支持
京東廣告生成式召回基于 NVIDIA TensorRT-LLM 的推理加速實踐
小白學大模型:構建LLM的關鍵步驟

在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

解鎖NVIDIA TensorRT-LLM的卓越性能
NVIDIA TensorRT-LLM Roadmap現已在GitHub上公開發布

TensorRT-LLM低精度推理優化

NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據






 工商網監
工商網監
評論