 一種通過視圖合成增強預訓練的2D擴散模型的可擴展技術
一種通過視圖合成增強預訓練的2D擴散模型的可擴展技術
1、導讀
現有的3D物體檢測方法通常需要使用完全注釋的數據進行訓練,而使用預訓練的語義特征可以帶來一些優勢。然而,目前還沒有利用擴散特征進行3D感知任務的研究。因此,我們提出了一種新的框架,通過視圖合成任務來增強預訓練的2D擴散模型的3D感知能力。該方法利用已知相對姿態的圖像對進行訓練,并通過擴散過程生成目標輸出。此外,文章還介紹了如何將這些增強的特征用于3D物體檢測,并通過引入輔助網絡來保持特征質量。最后,文章通過實驗證明了該方法在點對應和3D檢測性能上的優越性。
2、研究內容
一種名為3DiffTection的新框架,該框架利用預訓練的2D擴散模型來進行3D物體檢測任務。該方法通過視圖合成任務,將2D擴散特征增強為具有3D感知能力的特征。作者利用已知相對姿態的圖像對進行特征提取和特征擴散過程,從而生成目標輸出。文章還介紹了如何將這些增強的特征用于3D物體檢測,并通過引入輔助控制網絡來進一步適應目標任務和數據集。最后,作者通過多個合成視圖生成檢測提議,并通過非極大值抑制(NMS)來整合這些提議,從而提高檢測性能。
3、貢獻
介紹了一種通過視圖合成增強預訓練的2D擴散模型的可擴展技術,使其具有3D感知能力;
將這些特征適應于3D檢測任務和目標領域;
利用視圖合成能力通過集成預測進一步提高檢測性能。
4、方法
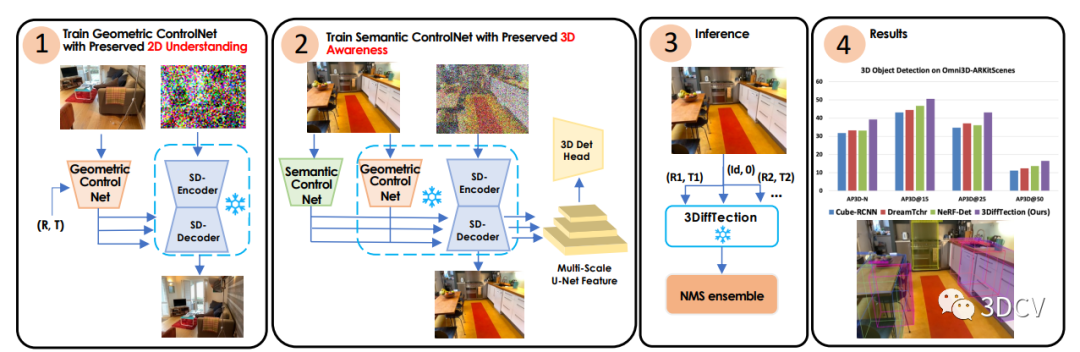
3DiffTection:它可以在3D物體檢測任務中利用預訓練的2D擴散模型。該方法的關鍵在于設計了一個視圖合成任務,通過使用極線幾何將源圖像中的殘差特征進行變形,從而增強了2D擴散特征的3D感知能力。通過去噪擴散過程,這些變形的特征有助于生成目標輸出。我們的方法利用了具有已知相對姿態的圖像對,這些圖像對通常可以從視頻數據中輕松獲取。鑒于視頻數據的不斷增加,這使得我們的表示精煉解決方案具有高度的可擴展性。
4.1、2D擴散模型特征提取
在3DiffTection中,我們使用預訓練的2D擴散模型作為特征提取器。擴散模型已經在圖像分割等密集感知任務中展現出了強大的性能。我們利用這些模型學習到的語義特征,并通過視圖合成任務增強這些特征的3D感知能力。通過提取源圖像的殘差特征,并利用極線幾何將其映射到目標視圖,我們能夠生成目標輸出。這樣,我們就能夠將預訓練的2D擴散模型的特征轉化為具有3D感知能力的特征。這種方法使得我們的模型能夠更好地理解圖像中的3D結構,并在3D目標檢測任務中取得更好的性能。
4.2、3D感知融入擴散特征
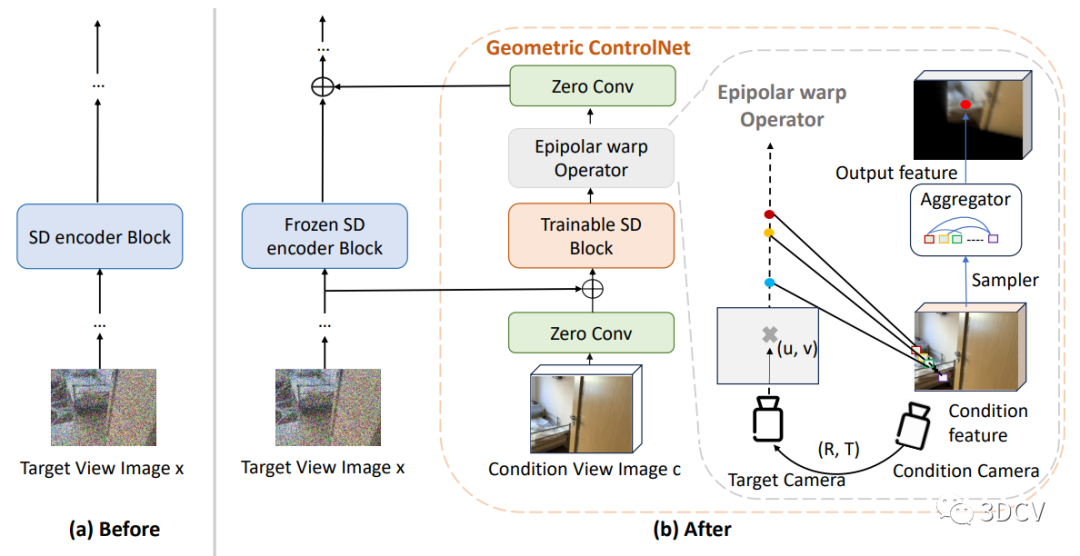
如何將3D感知融入擴散特征。具體而言,作者通過訓練一個視圖合成任務來增強預訓練的2D擴散模型的3D感知能力。這個任務的關鍵是從源圖像中提取殘差特征,并使用極線幾何將它們映射到目標視圖上。通過這種映射,可以通過去噪擴散過程生成目標輸出。這些經過映射的特征有助于增強模型對目標的生成能力。這種方法利用了具有已知相對姿態的圖像對,這些圖像對通常可以從視頻數據中輕松獲取。我們接下來利用這些增強的3D特征進行3D檢測,通過在3D框注釋下訓練一個標準的檢測頭。雖然我們的模型的基線性能已經顯示出對現有方法的改進,但我們的目標是進一步將訓練好的特征適應目標任務和數據集,這可能與用于視圖合成預訓練的數據不同。
由于訓練數據有限,直接微調模型來彌合任務和領域差距可能會導致性能下降。為了解決這個問題,作者引入了一個輔助的ControlNet,它有助于保持特征的質量。這個過程還保留了模型的視圖合成能力。在測試時,我們通過從多個合成視圖生成檢測提議,并通過非極大值抑制(NMS)來合并這些提議,從而充分利用幾何和語義能力。
5、實驗結果
本研究采用了兩種實驗方法來評估提出的3DiffTection框架的性能。
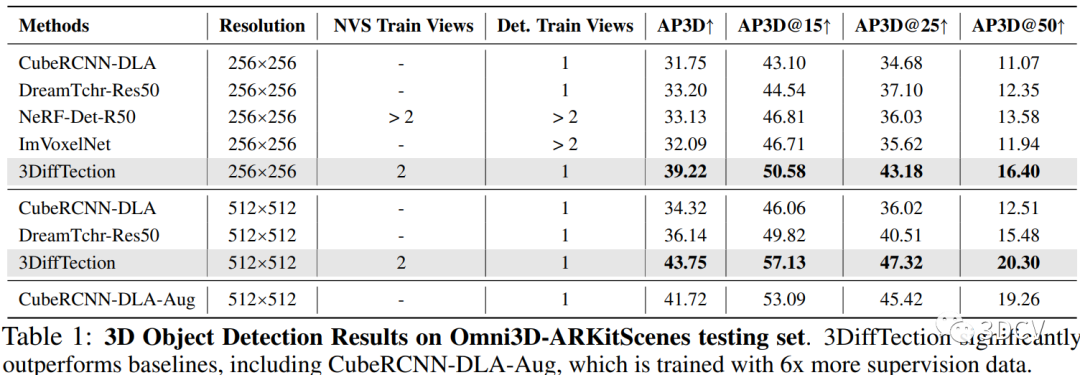
第一種實驗方法是在Omni3D-ARKitscene數據集上進行的。首先,使用預訓練的2D擴散模型進行視圖合成,以增強2D特征的3D感知能力。然后,使用訓練好的3D檢測頭在3D邊界框監督下對特征進行3D檢測。為了進一步適應目標任務和數據集,引入了一個輔助的控制網絡來維持特征質量。最后,通過生成多個合成視圖的檢測提議,并通過非最大抑制(NMS)進行整合,來進行3D檢測。實驗結果表明,與現有方法相比,3DiffTection在Omni3D-ARKitscene數據集上取得了顯著的改進。
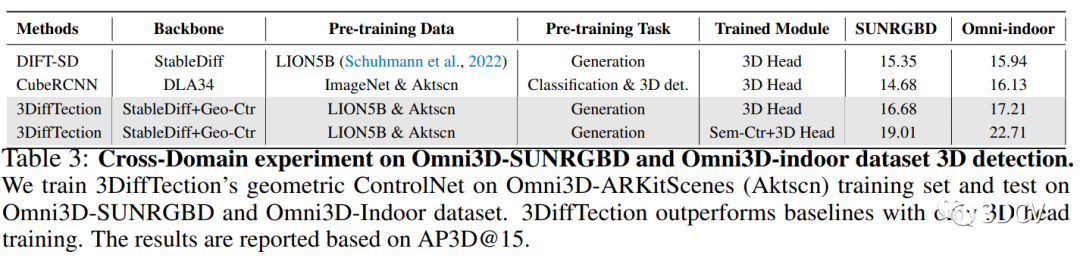
第二種實驗方法是在跨數據集上進行的。首先,在Omni3D-ARKitscene數據集上訓練了具有幾何控制網絡的3DiffTection模型,并僅在跨域數據集上訓練了3D檢測頭。然后,將3DiffTection與CubeRCNN進行比較。實驗結果顯示,即使在目標域中沒有對幾何控制網絡進行訓練,3DiffTection仍然能夠超越完全微調的CubeRCNN。


6、創新性
主要體現在以下幾個方面:
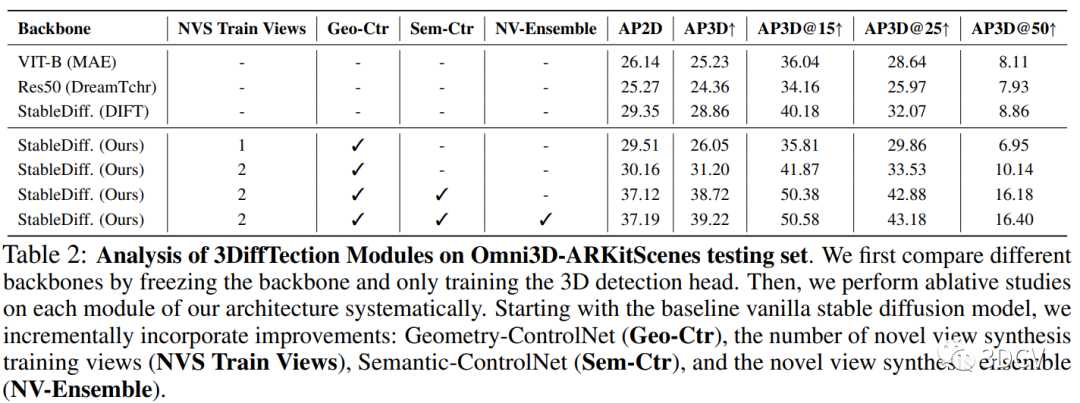
引入了幾何感知的穩定擴散特征:本研究通過在穩定擴散特征中引入幾何感知,提高了3D目標檢測的性能。通過訓練幾何控制網絡,將相機姿態信息與擴散特征結合起來,實現了對3D空間的感知。這種幾何感知的穩定擴散特征在目標檢測任務中表現出更好的性能。
提出了基于視圖合成的訓練方法:本研究利用視圖合成技術,通過生成新的視圖來增強模型的泛化能力。通過訓練模型生成與輸入圖像不同視角的合成圖像,使得模型能夠學習到更多的視角信息,從而提高了模型在不同數據集上的性能。
結合語義控制網絡進行聯合訓練:本研究還引入了語義控制網絡,通過與3D檢測頭部聯合訓練,進一步提高了2D和3D檢測的性能。語義控制網絡能夠適應感知任務,并優化特征的使用,從而提高檢測的準確性。
7、總結
我們提出了一種名為3DiffTection的新框架,該框架利用預訓練的2D擴散模型增強了3D物體檢測任務的性能。作者通過視圖合成任務,將源圖像中的殘差特征提取出來,并利用極線幾何將其變形到目標視圖中,從而增強了2D擴散特征的3D感知能力。作者還通過訓練一個標準的檢測頭來利用這些增強的特征進行3D檢測。實驗證明,這種方法在點對應和物體檢測性能上都優于基準模型。此外,作者還介紹了一個輔助的控制網絡,用于保持特征質量,并通過生成多個合成視圖的檢測提案來進一步提高檢測性能。總體而言,作者的方法在3D物體檢測任務中取得了顯著的改進,并展示了其在不同數據集上的泛化能力。
審核編輯:劉清
-
NMS
+關注
關注
0文章
9瀏覽量
6122 -
控制網絡
+關注
關注
0文章
28瀏覽量
10018
原文標題:英偉達最新發布!超越其它所有SOTA的3D目標檢測
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點

一種側重于學習情感特征的預訓練方法


一種基于亂序語言模型的預訓練模型-PERT
什么是預訓練 AI 模型?
2D Transformer 可以幫助3D表示學習嗎?





 工商網監
工商網監
評論