 Cascades查詢優化器基本原理分析
Cascades查詢優化器基本原理分析
數據庫中查詢優化器是數據庫的核心組件,其決定著 SQL 查詢的性能。Cascades 優化器是 Goetz 在 volcano optimizer generator 的基礎上優化之后誕生的一個搜索框架。 本期技術貼將帶大家了解 Cascades 查詢優化器。首先介紹 SQL 查詢優化器,接著分析查詢優化基本原理,最后對 Cascades 查詢優化器進行重點介紹。
一、SQL 查詢優化器
用戶與數據庫交互時只需要輸入聲明式 SQL 語句,數據庫優化器則負責將用戶輸入的 SQL 語句進行各種規則優化,生成最優的執行計劃,并交由執行器執行。優化器對于 SQL 查詢具有十分重要的意義。 如圖 1 所示,SQL 語句經過語法和詞法解析生成抽象語法樹(AST),經過基于規則的查詢優化(Rule-Based Optimizer)和基于代價的查詢優化(Cost-Based Optimizer)生成可執行計劃。
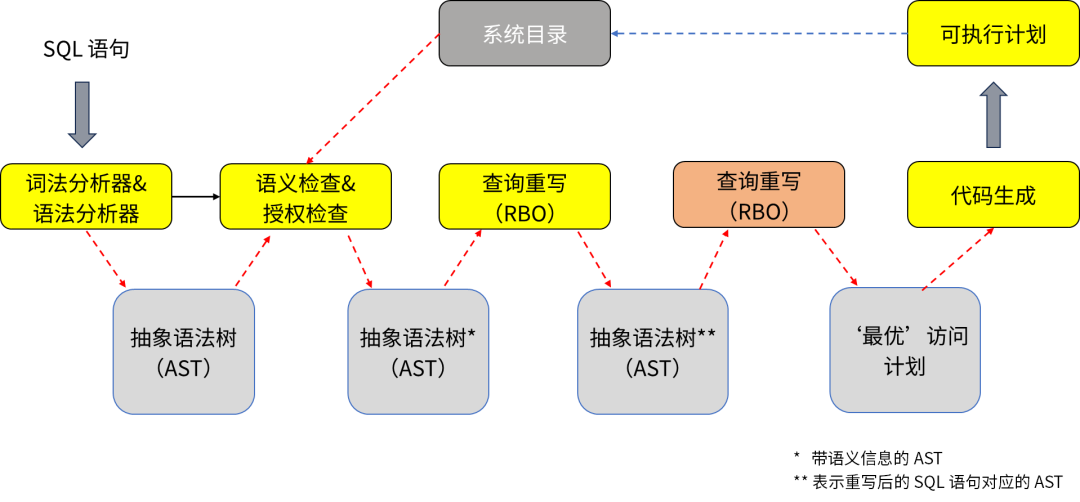
圖 1
基于規則的優化算法:基于規則的優化方法的要點在于結構匹配和替換。應用規則的算法一般需要先在關系代數結構上匹配一部分局部的結構,再根據結構的特點進行變換乃至替換操作。
基于成本的優化算法:現階段主流的方法都是基于成本(Cost)估算的方法。給定某一關系代數代表的執行方案,對這一方案的執行成本進行估算,最終選擇估算成本最低的方案。盡管被稱為基于成本的方法,這類算法仍然往往要結合規則進行方案的探索。基于成本的方法其實是通過不斷的應用規則進行變換得到新的執行方案,然后對比方案的成本優劣進行最終選擇。
二、查詢優化的基本原理
優化器一般由三個組件組成:統計信息收集、開銷模型、計劃列舉。 如圖 2 所示,開銷模型使用收集到的統計信息以及構造的不同開銷公式,估計某個特定查詢計劃的成本,幫助優化器從眾多備選方案中找到開銷最低的計劃。
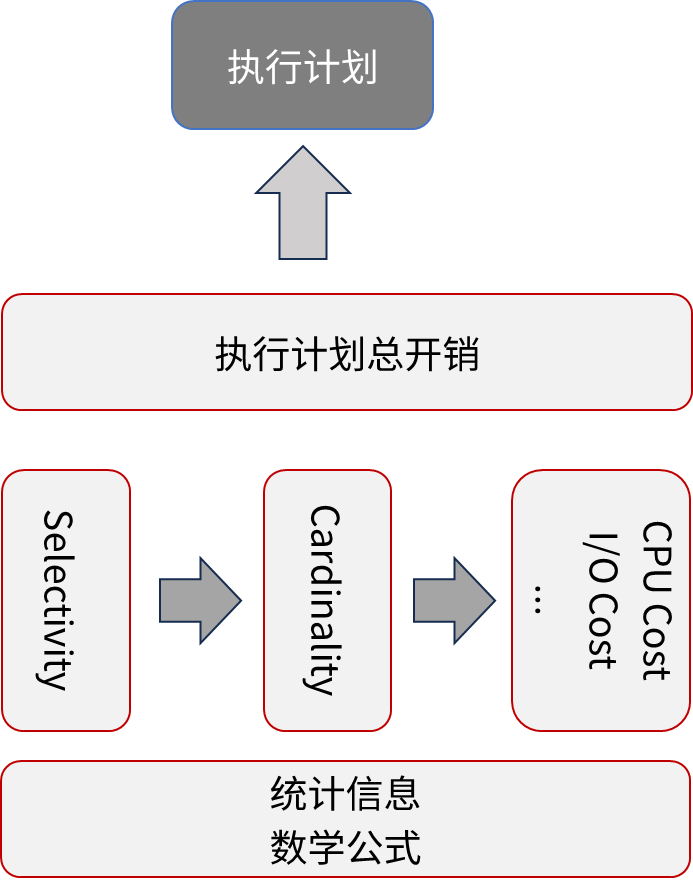
圖 2 SQL 語句查詢優化基于關系代數這一模型:
SQL 查詢可以轉化為關系代數;
關系代數可以進行局部的等價變換,變換前后返回的結果不變但是執行成本不同;
通過尋找執行成本最低的關系代數表示,我們就可以將一個 SQL 查詢優化成更為高效的方案。
尋找執行成本最低的關系代數表示,可以分為基于動態規劃的自底向上和基于 Cascades/Volcano 的自頂向下兩個流派。
自底向上搜索:從葉子節點開始計算最低成本,并利用已經計算好的子樹成本計算出母樹的成本,就可以得到最優方案;
自頂向下搜索:先從關系算子樹的頂層開始,以深度優先的方式來向下遍歷,遍歷過程中進行剪枝。
自底向上的優化器從零開始構建最優計劃,這類方法通常采用動態規劃策略進行優化,采用這類方法的優化器包括IBMSystem R。自頂向下的優化策略的優化器包括基于 Volcano 和 Cascades 框架的優化器。
三、Cascades 查詢優化器
Cascades 查詢優化器采用自頂向下的搜索策略,并在搜索過程中利用 Memo 結構保存搜索的狀態。
Cascades 關鍵組件構成:
Expression:Expression 表示一個邏輯算子或物理算子。如 Scan、Join 算子;
Group:表示等價 Expression 的集合,即同一個 Group 中的 Expression 在邏輯上等價。Expression 的每個子節點都是以一個 Group 表示的。一個邏輯算子可能對應多個物理算子,例如一個邏輯算子 Join(a,b),它對應的物理算子包括{HJ(a, b), HJ(b, a), MJ(a, b), MJ(b, a), NLJ(a, b), NLJ(b, a)}。我們將這些邏輯上等價的物理算子稱為一個 Group(組)。注:HJ 表示 HashJoin 算子,MJ 表示 MergeJoin 算子,NLJ 表示 NestLoopJoin 算子;
Memo:由于 Cascades 框架采用自頂向下的方式進行枚舉,因此,枚舉過程中可能產生大量的重復計劃。為了防止出現重復枚舉,Cascades 框架采用 Memo 數據結構。Memo 采用一個類似樹狀(實際是一個圖狀)的數據結構,它的每個節點對應一個組,每個組的成員通過鏈表組織起來;
Transformation Rule:是作用于 Expression 和 Group 上的等價變化規則,用來擴大優化器搜索空間。
Cascades 首先將整個 Operator Tree 按節點拷貝到一個 Memo 的數據結構中,Memo 由一系列的 Group 構成,每個算子放在一個 Group,對于有子節點的算子來說,將原本對算子的直接引用,變成對 Group 的引用。
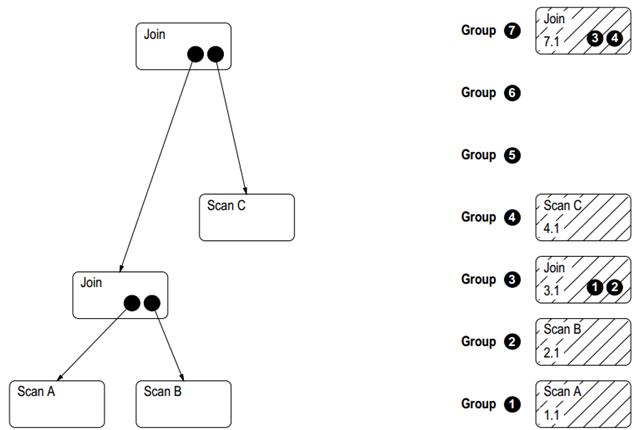
圖 3 如圖 3 所示,生成該語法樹的 Memo 初始結構。Memo 結構中一個圓角框代表一個算子,圓角框右下角是對其 Children’s Groups 的引用,左下角是唯一標識符。生成初始的 Memo 結構后,可以采用 transform rule 進行邏輯等價轉換,規則如下:
對于一個邏輯算子,其所有基于關系代數的等價表達式保存在同一個 Group 內,例如 join(A,B) -> join(B,A);
在一個 Group 內,對于一個邏輯算子,會生成一個或多個物理算子,例如 join -> hash join,merge join,NestLoop join;
一個 Group 內,一個算子,其輸入(也可以理解為subplan)可以來自多個 Group 的表達式。
在圖 4 中,描述了一個部分擴展的 Memo結構,與圖 1 中的初始 Memo 相比,在同一個 Group 內,增加了等價的邏輯算子,以及對應的物理算子。
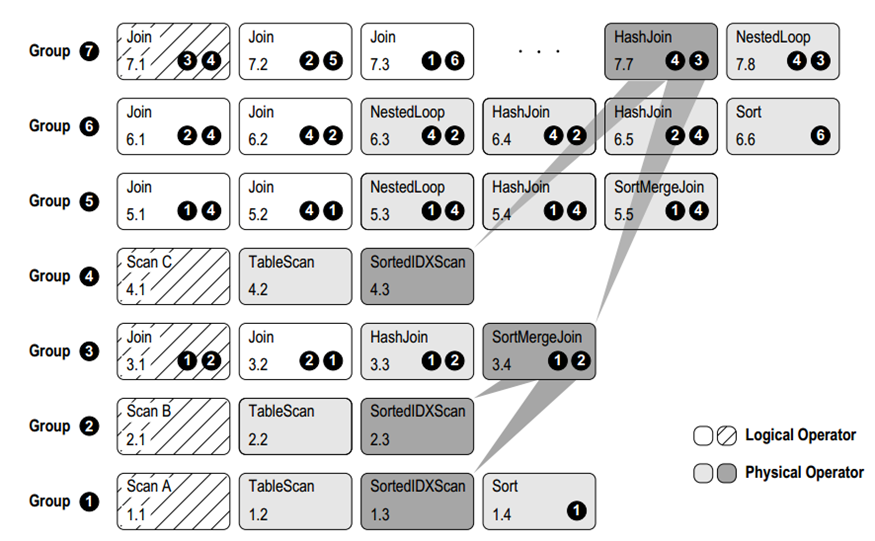
圖 4 在探索的過程中,優化器就會通過開銷模型 Coster 借助統計信息來計算子步驟的開銷,遍歷完每個 Memo Group之后,歸總得到每個完整計劃的總開銷,最終選擇 Memo 中開銷最低的計劃。
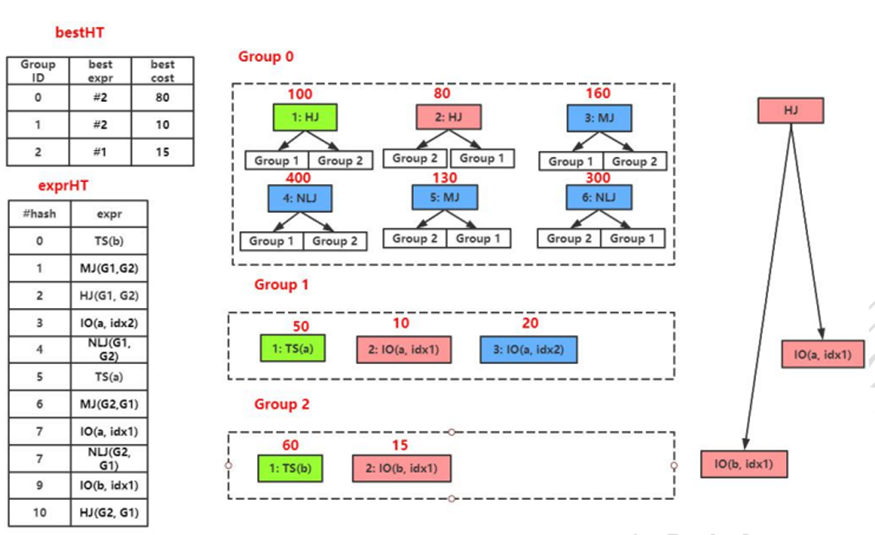
圖5 圖 5 中有三個 Group,分別對應三個邏輯算子:Join(a, b), GET(a) 和 GET(b)。Group 1(Group 2)中包含了所有對應 GET(a) (GET(b))的物理算子,我們可以估算每個物理算子的代價,選取其中最優的算子保留下來。 為了防止枚舉過程出現重復枚舉某個表達式,Memo 結構體中還包含一個哈希表(exprHT),它以表達式為哈希表的鍵,用來快速查找某個表達式是否已經存在于 Memo 結構體中。
Cascades 采用自頂向下的方式來進行優化,以計劃樹的根節點為輸入,遞歸地優化每個節點或表達式組。如圖所示,整個優化過程從 Group 0 開始,實際上要先遞歸地完成兩個子節點(Group 1 和 Group 2)的優化。 因此,實際的優化完成次序是 Group 1 -> Group2 -> Group 0。在優化每個 Group 時,依次優化每個組員;在優化每個組員時,依次遞歸地優化每個子節點。依次估算當前組里每個表達式 e 的代價 cost(e),選擇最低得代價結果保存在 bestHT 中。優化結束時,查詢 Join(a,b)對應的 Memo 結構體,獲取最低的執行計劃。
審核編輯:黃飛
-
SQL
+關注
關注
1文章
780瀏覽量
44739 -
數據庫
+關注
關注
7文章
3885瀏覽量
65641 -
數據結構
+關注
關注
3文章
573瀏覽量
40542
原文標題:深度解讀Cascades查詢優化器
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
線性電源的基本原理是什么
無線充電的基本原理是什么
主從sr觸發器基本原理分析





 工商網監
工商網監
評論