 詳解CUTLASS的工作原理
詳解CUTLASS的工作原理
嗨,我們要開始了。我叫馬修·尼斯利。我是NVIDIA的深度學習compiler PM,今天我將介紹一些針對NVIDIA Tensorcores的使用方法。首先我要講一下Cutlass。我會給你一些背景和概述,為什么你可能會使用它,一些最新和即將推出的功能,然后我會概述一下開放平臺Triton。如果你剛剛參加了上一場講座的話那你已經是懂哥了。

好的,Cutlass是我們在GitHub上的開源庫,用于在張量核上進行編程。它最初于2017年發布,旨在改善Volta的可編程性。從那時起,它的應用逐漸增長。它已經從一個供深度學習從業者使用的研究工具轉變為整個生態系統中廣泛應用的生產資產。
Cutlass由構建模塊組成,可以根據您的需要使用gemm,卷積等,無論是從現成的還是自己設計的內核。我們支持多種Epilogue模式以及在NVIDIA GPU上找到的所有數據計算類型。我們最近發布了一個Python接口,我稍后會詳細介紹它。另外,我們還有一個性能分析器,你可以用它來找到最適合你使用情況的配置。Cutlass對于NVIDIA生態系統至關重要,你會在許多庫中找到它,例如cublas、CUSPARSE、cuTENSOR和DALI等等。那么,它是如何工作的呢?
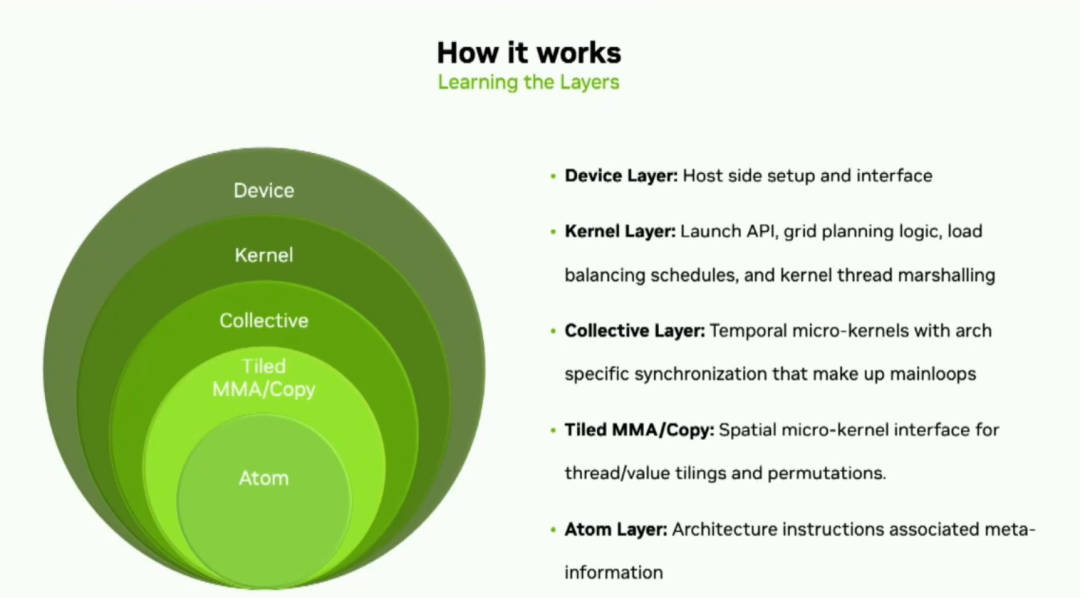
Cutlass由五個抽象層構成,其目的是最大限度地提高靈活性。首先,我們幾個月前發布了版本3,它有一個新的后端稱為Cute,極大地簡化了線程數據映射,并允許核心開發人員專注于張量和算法的邏輯描述。(CuTe is a collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and data.)所以,分解這些抽象層,底層是原子,包含著PTX。tiled的MMA和copy;過了collective層,接下來是kernel層,在這里你可以將collective mainloop and a collective epilogue結合在一起。最后,在設備層面上,你會找到內核配置、啟動工具和設備層面保證的可移植性。
(譯者吐槽:這里如果不看官方文檔很多概念其實是看不懂的。。。。所以插播一下其他知識以便不會覺得太突兀。如果你不想看可以跳過,轉載自官方文檔 https://github.com/NVIDIA/cutlass/blob/main/media/docs/cutlass_3x_backwards_compatibility.md
Collective mainloop和epilogue是CUTLASS中用于執行集合矩陣乘累加(MMA)操作的關鍵組件。
Collective mainloop(集合主循環)是一個循環結構,用于在多個線程中執行MMA操作。它負責將輸入矩陣切分成小塊,并在多個線程之間協調數據傳輸和計算操作。主循環使用MMA指令對這些小塊執行矩陣乘累加操作,利用硬件的并行性和局部性來加速計算。主循環還處理線程同步和通信,以確保正確的數據依賴關系和結果的一致性。
Epilogue(收尾)是主循環之后的一系列操作,用于處理主循環的輸出結果。它可以執行各種操作,如對結果進行修正、縮放、舍入等。Epilogue的目的是將主循環的輸出轉換為最終的矩陣乘累加結果。CUTLASS提供了不同類型的Epilogue,可以根據具體需求選擇適當的Epilogue類型。
通過將Collective mainloop和Epilogue組合在一起,CUTLASS能夠高效地執行集合MMA操作,利用硬件的并行性和局部性來提高計算效率。這種組合的靈活性使得CUTLASS可以適應不同的硬件架構和應用需求,并提供高性能的矩陣乘累加功能。
這里假設以一個gemm說明為例:
// cutlass: ClusterTileM and ClusterTileN loops
// are either rasterized by the hardware or scheduled by the kernel in persistent kernels.
// Parallelism over thread block clusters
for (int cluster_m = 0; cluster_m < GemmM; cluster_m += ClusterTileM) {
for (int cluster_n = 0; cluster_n < GemmN; cluster_n += ClusterTileN) {
// cutlass: mainloop that iterates over all k-tiles
// No loop unrolling is performed at this stage
for (int k_tile = 0; k_tile < size<2>(gmem_tensor_A); k_tile++) {
// loops inside cute::gemm(tiled_mma, a, b, c); Dispatch 5: (V,M,K) x (V,N,K) => (V,M,N)
// TiledMma uses the hardware instruction provided through its Mma_Atom
// TiledMma's atom layout, value layout, and permutations define the iteration order
for (int tiled_mma_k = 0; tiled_mma_k < size<2>(A); tiled_mma_k++) {
for (int tiled_mma_m = 0; tiled_mma_m < size<1>(A); tiled_mma_m++) {
for (int tiled_mma_n = 0; tiled_mma_n < size<1>(B); tiled_mma_n++) {
// TiledMma's vector mode dispatches to the underlying instruction.
mma.call(d, a, b, c);
} // tiled_mma_n
} // tiled_mma_m
} // tiled_mma_k
} // k_tile mainloop
} // cluster_m
} // cluster_n
CUTLASS使用以下組件來表示上述循環嵌套(上面是一個gemm),這些組件針對數據類型、布局和數學指令進行了專門化。
| API level | API Class and/or function names |
|---|---|
| Device | cutlass::GemmUniversalAdapter |
| Kernel | cutlass::GemmUniversal |
| Collective | cutlass::CollectiveMma cutlass::DefaultEpilogue cutlass::Epilogue |
| Tiled (MMA and Copy) | cute::TiledMma and cute::TiledCopy cute::gemm() and cute::copy() |
| Atom | cute::Mma_Atom and cute::Copy_Atom |
在CUTLASS 3.0中,我們通過首先在內核層面組合collective mainloop(cutlass: mainloop that iterates over all k-tiles)和collective epilogue ,然后使用主機端轉換器將它們包裝成一個GEMM內核的handle 。
以下部分按照用戶實例化它們的順序描述了組裝一個內核需要的組件,這個順序是:
組裝所需的collective mainloop and epilogues。
將它們組合在一起構建一個內核類型。
使用設備層轉換器包裝內核。
Collective是“mma atoms和copy atoms 被切分到的最大線程集合”。也就是說,它是一個最大數量的線程網格,通過利用硬件特性進行加速通信和同步來進行協作。這些硬件特性包括:
異步數組復制(例如,從全局內存到共享內存);
用于位于共享內存中的小塊的MMA指令;
用于集群、線程塊和/或warp的同步操作;和/或
硬件加速(例如屏障),以確保滿足異步操作之間的數據依賴關系。
Collective使用TiledMma和TiledCopy API(來訪問在塊上執行復制和MMA操作。
cutlass::CollectiveMma類是集合矩陣乘累加(MMA)mainloop的主要接口。這里的“主循環”指的是在偽代碼中靠近本文頂部的“cluster tile k”循環。算法可能需要對多個塊進行循環的情況會在這里發生。
更多請自行查看文檔
為什么要使用Cutlass呢?這可能是最常見的問題。cublas將擁有最佳的開箱體驗。它將有更快的上市時間。它在不同架構之間提供了可移植性保證。它有一組基于您的參數選擇最佳內核的啟發式算法。所以我告訴很多客戶的是,如果cublas能滿足您的需求,就使用它。
(譯者:以防看不懂放上GPT的解釋:
CUTLASS和CUBLAS是兩個用于在NVIDIA GPU上進行矩陣運算的庫,它們有以下區別:
開發者:CUTLASS是由NVIDIA開發和維護的開源項目,而CUBLAS是NVIDIA官方提供的閉源庫。
靈活性和可配置性:CUTLASS提供了更高級別的靈活性和可配置性,允許用戶自定義和優化矩陣運算的細節。它提供了底層的矩陣運算原語和算法的實現,使用戶可以根據特定需求進行定制和優化。CUBLAS則提供了更高級別的抽象和易用性,適用于常見的矩陣運算任務。
性能優化:CUTLASS注重性能優化和硬件特性的利用。它提供了更多的配置選項和優化策略,使用戶能夠根據具體的硬件架構和應用需求進行性能優化。CUTLASS還提供了針對深度學習任務的特殊優化,如半精度浮點計算(FP16)和Tensor Core加速。CUBLAS也進行了一些性能優化,但它更注重提供易用性和通用性。
支持的功能:CUTLASS提供了更多的功能和算法選項,包括矩陣乘累加(MMA)、卷積等。CUBLAS則提供了一組預定義的矩陣運算函數,如矩陣乘法、矩陣向量乘法等。
開源性:CUTLASS是開源的,用戶可以訪問其源代碼并參與社區貢獻和討論。CUBLAS是閉源的,用戶無法訪問其底層實現。)
如果您需要最大的靈活性,比如自定義epilogue,在cublas中并不存在,那么就使用Cutlass。雖然它需要花費一些時間來啟動和運行,但您可以對數據傳輸和操作擁有最大的控制權。
在PyTorch生態系統中,你在哪里可以找到Cutlass呢?在高層級上,你會在eager模式下找到一些稠密和稀疏操作,并且目前有一個PR正在將Cutlass作為Inductor的另一種后端添加進去。AItemplate(meta的torch backend codegen工具)在開發過程中使用了每一層的一些特性。Xformer的內存高效注意力是在Cutlass上開發的。最后,PyTorch geometric是我們group Gemm的早期采用者之一。
我之前提到了Python接口。Cutlass的最大痛點之一是C++模板。通過我們的Python接口,我們大大減少了開始所需的默認值。這是一個基本的gemm示例,你可以看到它可能是所需參數的三分之一多。
using Gemm = typename gemm::DefaultGemmUniversal<
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor,
arch::OpClassTensorOp, arch::Sm8e,
gemm::GemmShape<256, 128, 64>,
gemm::GemmShape<64, 64, 64>,
gemm::GemmShape<16, 8, 16>,
epilogue::LinearCombination
gemm::GemmIdentityThreadblockSwizzle<1>,
arch::OpMultiplyAdd>::GemmKernel;
# 創建GEMM plan plan = cutlass.op.Gemm(element=torch.float16, layout=cutlass.LayoutType.RowMajor) # 更改swizzling functor plan.swizzling_functor = cutlass.swizzle.ThreadblockSwizzlestreamk # 添加fused ReLU plan.activation = cutlass.epilogue.relu
Python接口的另一個目標是改善與PyTorch等框架的集成。可以通過新的Cutlass emit PyTorch方法來實現。右側您將看到可以使用Python接口聲明PyTorch中的group gemm并給出PyTorch CUDA擴展。

之后我們將負責生成源代碼,為PyTorch擴展提供輸入,并提供一個腳本來生成該PyTorch擴展。
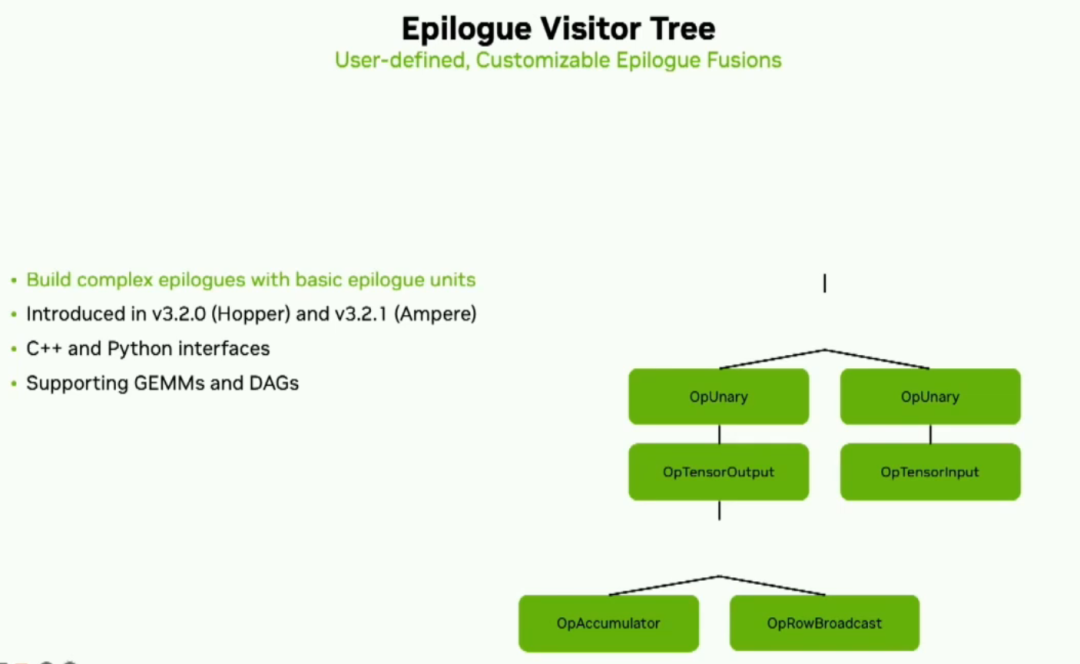
在Cutlass中最新的功能是我們稱為epilogueVisitor Tree。這將允許用戶使用基本的epilogue單元來開發復雜的epilogue。它是一組小的計算、加載和存儲操作,可以生成常見或自定義的epilogue。它在Ampere和Hopper架構上和C++和Python接口中已經可以使用。我們在現有的配置中,利用峰值效果非常好。下面是一個示例,在最新版本的Cutlass 3.2和Cuda Toolkit 12.2以及H100上使用性能分析器和默認參數。
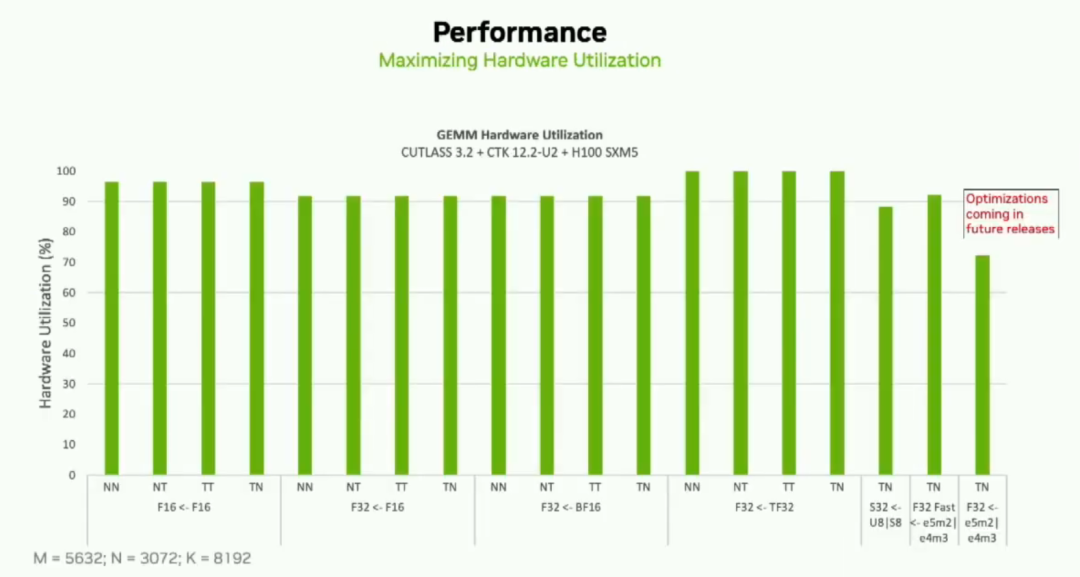
您可以看到對于所有這些用例,我們大約達到了90%的峰值利用率。我們還努力確保沒有性能下降,并會定期發布優化版本。
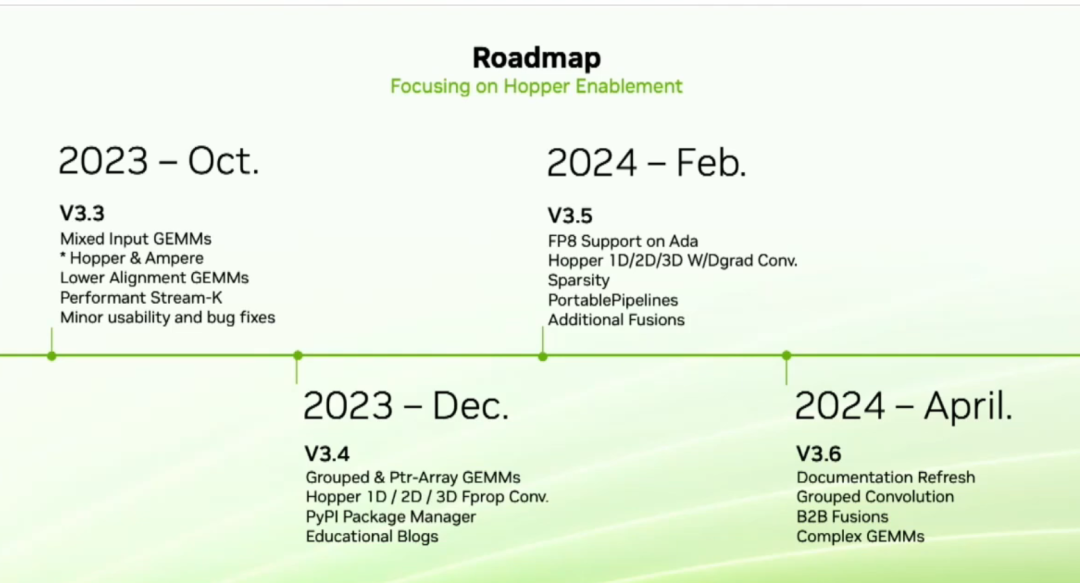
我們的下一個發布版本是3.3。3.3中最重要的功能是我們稱之為混合輸入gemm。這是一個常見的需求,在這個功能下,你可以為A和B矩陣使用不同的數據類型。例如,A可以是FP16。B可以是int8,而在gemm中,我們將向上轉換到BF16的操作。我們還對我們的lower alignment gemm進行了性能改進。然后在今年12月,我們將推出grouped 和 ptr-array gemm,以及為Hopper優化的四個性能卷積。明年年初,我們將為Ada提供FP8支持。我們將進行卷積的權重和偏差(W&D grad)優化,支持稀疏數據。我們還有一個稱為portablepipeline的新功能。portablepipeline是我們為希望在架構上實現可移植性的用戶提出的建議。在GTC Talk上會有更多關于這個功能的信息。最后,在明年第二季度,Cutlass開發者和初學者需要的是更好的文檔。我們會進行全面更新,這將涵蓋C++和Python接口。
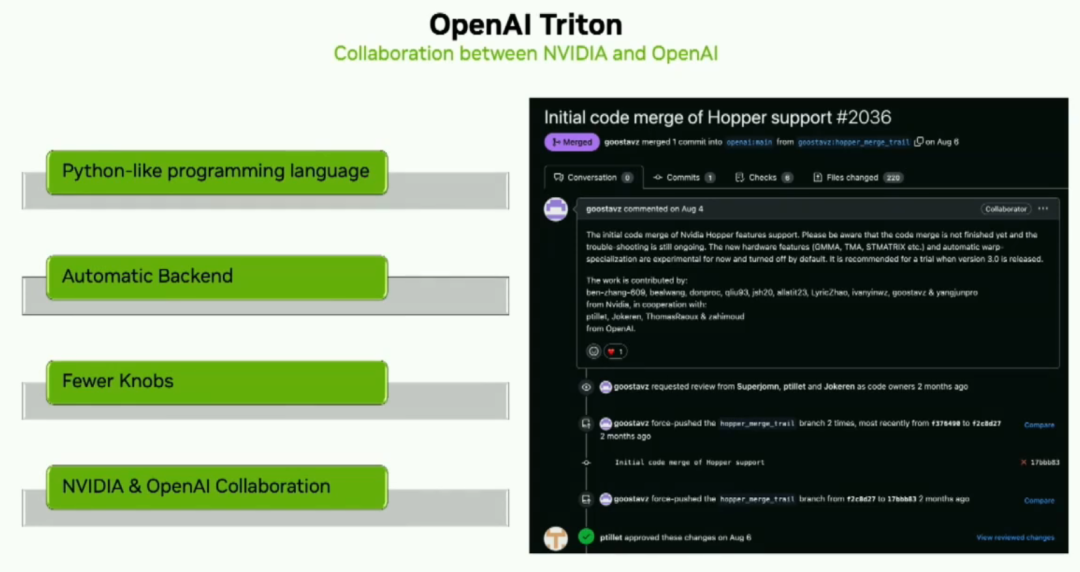
OpenAI Triton是一個令人興奮的新的類似于Python的編程語言,供用戶開發在Python中針對NVIDIA TensorCores的內核。這樣一來,開發者可以專注于更高級別的邏輯。OpenAI Triton Compiler會處理許多性能優化,讓開發者不用操心。NV和openai在大力合作推進一切中。
到此結束,謝謝。
-
接口
+關注
關注
33文章
8963瀏覽量
153335 -
NVIDIA
+關注
關注
14文章
5267瀏覽量
105903 -
開源
+關注
關注
3文章
3632瀏覽量
43571 -
python
+關注
關注
56文章
4825瀏覽量
86344
原文標題:《PytorchConference2023 翻譯系列》7-深入探索CUTLASS:如何充分利用Tensor Cores??
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
工程師常用產品工作原理詳解






 工商網監
工商網監
評論