 千瓦芯片時代的熱管理變革
千瓦芯片時代的熱管理變革
來源:半導體芯科技編譯
隨著摩爾定律的放緩,芯片,尤其是用于人工智能和高性能計算(HPC)的芯片,逐漸變得炙手可熱。2023 年,隨著英偉達(Nvidia)GH200 超級芯片的到來,我們看到加速器的功率進入了千瓦級。
我們早已知道這些芯片會很熱門--Nvidia 在兩年前就已經開始預告這款 CPU-GPU 芯片。直到最近,我們才知道原始設備制造商和系統構建商將如何應對這種功率密集型部件。大多數系統會采用液體冷卻嗎?還是大多數會堅持使用空氣冷卻?他們會在一個盒子里塞進多少臺這樣的加速器,盒子又有多大?
現在,第一批基于 GH200 的系統已經投放市場,很明顯,外形尺寸在很大程度上是由功率密度決定的。從根本上說,這取決于散熱的表面積有多大。
深入研究 Supermicro、Gigabyte、QCT、Pegatron、HPE 等公司目前提供的系統,您很快就會注意到一個趨勢。每個機架單元 (RU) 高達 500 W – Supermicro 的 MGX ARS-111GL-NHR 為 1 kW – 這些系統主要采用風冷。雖然溫度較高,但散熱負荷仍在可控范圍內,每個機架的功率約為 21-24 kW。這完全在現代數據中心的供電和熱管理能力范圍內,尤其是那些使用后門熱交換器的數據中心。
但是,當系統制造商開始在每個機箱中安裝超過 1 kW的加速器時,情況就會發生變化。此時,我們看到的大多數 OEM 系統都改用了直接液冷技術。例如,Gigabyte的 H263-V11 在一個 2U 機箱中最多可容納四個 GH200 節點。
也就是說,每個機架單元的功率為 2 kW。因此,雖然像 Nvidia 的風冷 DGX H100 系統(配備 8 個 700 瓦 H100 和雙藍寶石 Rapids CPU)的 TDP 較高,為 10.2 千瓦,但其功率密度實際上較低,為 1.2 kW/RU。
除了能更有效地從這些密集的加速器中傳遞熱量外,液體冷卻還有幾個優點。系統功率越高,從系統中帶走熱量所需的靜壓和氣流就越大。這就意味著要使用更熱、更快的風扇,從而消耗更多的功率——在某些情況下可能高達系統功率的 20%。
當每個機架單元的功率超過 500 W 時,大多數原始設備制造商和原始設計制造商似乎都會選擇液冷機箱,因為冷卻網卡、存儲和其他外設等低功耗組件所需的風扇數量更少、速度更慢。
只要看看 HPE 的 Cray EX254n 刀片,就能知道液冷機箱的作用有多大。該平臺最多可支持四個 GH200。在 1U 的計算刀片中就有 4 千瓦,這還不算用于為芯片提供數據的網卡。
當然,HPE 的 Cray 部門對超高密度計算組件的冷卻確實很有心得。不過,這確實說明了系統構建商在服務器上花費的心思,不僅在系統層面,而且在機架層面。
機架級起飛
正如我們之前在介紹 Nvidia DGX H100 系統時提到的那樣,為多千瓦服務器單獨散熱是原始設備制造商非常熟悉的事情。但是,一旦要在機架上安裝這些系統,情況就會變得復雜起來,機架電源和設備冷卻等因素都會發揮作用。
在我們的同類出版物《下一代平臺》(The Next Platform)上,我們深入探討了像 Digital Reality 這樣的數據中心運營商為支持此類系統的密集部署而必須克服的挑戰。
在許多情況下,主機托管服務提供商需要重新設計其電源和冷卻基礎設施,以支持在單個機架中安裝四個 DGX H100 系統所需的 40 多千瓦的功率和熱量。
但是,如果您的數據中心或主機托管服務提供商無法提供這種功率的機架,也無法承受這種熱量,那么在大部分機架都將空置的情況下,將這些系統的密度提高到這種程度就沒有多大意義了。
隨著 GH200 的推出,我們看到 Nvidia 不再關注單個系統,而是更加關注機架規模的部署。在今年春季的 Computex 上,我們首次看到了 DGX GH200 集群。
該系統實際上由 256 個 2U 節點組成,每個節點都裝有一個 GH200 加速器,而不是一堆密集的 GPU 節點。組合起來,該系統能夠提供高達 exaFLOPS 的 FP8 性能,但在設施層面的部署要容易得多。現在的功耗不再是 1.2 kW/RU,而是接近 500 W/RU,這與大多數原始設備制造商使用自己的風冷系統時的情況差不多。
最近,我們看到 Nvidia 在今年秋季的 Re:Invent 大會上與 AWS 合作發布了 GH200-NVL32,將其縮小到單個機架。
該系統在一個機架上安裝了 16 個 1U 機箱,每個機箱配備兩個 GH200 節點,并使用九個 NVLink 交換機托盤將它們連接在一起。不用說,這些計算能力為 2 千瓦/RU 的小系統密度很高,因此從一開始就被設計為液冷系統。
更熱的芯片即將上市
雖然我們一直在關注 Nvidia 的 Grace Hopper 超級芯片,但這家芯片制造商并不是唯一一家為追求性能和效率而將 TDP 推向新極限的廠商。
本月早些時候,AMD 公布了其最新的 AI 和 HPC GPU 和 APU,該公司的 Instinct 加速器的功耗從上一代的 560 W 躍升至 760 W。
更重要的是,AMD 首席技術官馬克-帕普馬斯特(Mark Papermaster)告訴《The Register》,未來幾年仍有足夠的空間將 TDP 推得更高。
至于這是否會最終促使芯片制造商強制要求其旗艦產品采用液冷技術,目前還沒有答案。據 Papermaster 稱,AMD 將在其平臺上支持空氣和液體冷卻。但正如我們在 AMD 新的 MI300A APU 上看到的那樣,繼續選擇風冷幾乎肯定意味著性能上的讓步。
MI300A的額定功率為550瓦,遠遠低于我們所認為的850瓦,但如果有足夠的冷卻,它的運行溫度會更高。在HPC調整系統中,如HPE、Eviden(Atos)或聯想開發的系統,芯片可以配置為760 W。
與此同時,英特爾正在探索使用兩相冷卻劑和珊瑚啟發設計的散熱片來冷卻 2 千瓦芯片的新方法,以促進氣泡的形成。
這家芯片制造商還宣布與基礎設施和化學品供應商建立廣泛的合作關系,以擴大液體冷卻技術的使用范圍。該公司最新的合作旨在利用 Vertiv 的泵送兩相冷卻技術為英特爾即將推出的 Guadi3 AI 加速器開發冷卻解決方案。?
審核編輯 黃宇
-
芯片
+關注
關注
459文章
52253瀏覽量
436939 -
amd
+關注
關注
25文章
5570瀏覽量
135987 -
AI
+關注
關注
88文章
34416瀏覽量
275700
發布評論請先 登錄


汽車電芯的熱管理設計

汽車熱管理相關知識
經緯恒潤熱管理系統研發服務全新升級
芯導科技GaN/SiC電源產品推薦
簡述智慧供熱管理服務平臺

聯發科攜手臺積電、新思科技邁向2nm芯片時代
soc設計中的熱管理技巧
1250千瓦變壓器承載多大電流
80的變壓器可以帶多少個千瓦
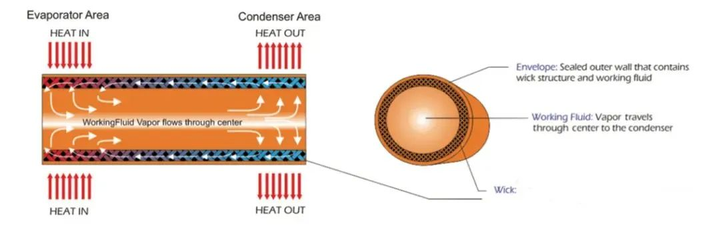
熱管理需求顯著增加!VC和熱管的優勢在哪里?
同星智能即將亮相新能源汽車熱管理論壇、中國車聯網安全大會






 工商網監
工商網監
評論