 Torch TensorRT是一個優化PyTorch模型推理性能的工具
Torch TensorRT是一個優化PyTorch模型推理性能的工具
大綱
Torch TensorRT介紹
JIT編譯與AOT編譯方法
兩種方法的異同點
詳細要點
1. Torch TensorRT介紹
Torch TensorRT是一個優化PyTorch模型推理性能的工具
它結合了PyTorch和NVIDIA的TensorRT
2. 兩種編譯方法
JIT編譯:靈活,支持動態圖和Python代碼
AOT編譯:支持序列化,固定輸入shape
3. 編譯流程
圖轉換、優化、劃分、TensorRT轉換
獲得高性能優化模型
4. JIT編譯細節
通過torch.compile調用
支持動態輸入和條件判斷
5. AOT編譯細節
通過trace和compile API實現
使用inputAPI支持動態shape
支持序列化模型
6. 兩種方法的異同
核心是基于同一圖優化機制
JIT支持動態,AOT支持序列化
大家好,我叫喬治。嗨,我是迪拉杰,我們都是NVIDIA的深度學習軟件工程師。今天我們在這里討論使用Torch TensorRT加速PyTorch推斷。首先,我們會給大家簡短介紹一下Torch TensorRT是什么,然后喬治將深入介紹我們優化PyTorch模型的用戶工作流程。最后,我們將比較這兩種方法,并討論一些正在進行的未來工作。現在我將把話筒交給喬治。
那么,什么是Torch TensorRT呢?Torch是我們大家聚在一起的原因,它是一個端到端的機器學習框架。而TensorRT則是NVIDIA的高性能深度學習推理軟件工具包。Torch TensorRT就是這兩者的結合。我們所做的是以一種有效且易于使用的方式將這兩個框架結合起來,可以適用于各種用例和模型。Torch TensorRT是優化PyTorch模型的一種路徑。
我將在今天的用例中分享一些方法,包括Model performance和core implementation。這意味著,如果你有一個單一的模型,并且你用我們的兩種方法之一進行優化,你可以得到相似的性能和核心軟件實現。現在你可能會問,為什么我要選擇其中之一?因為不同的部署場景需要不同的方法。
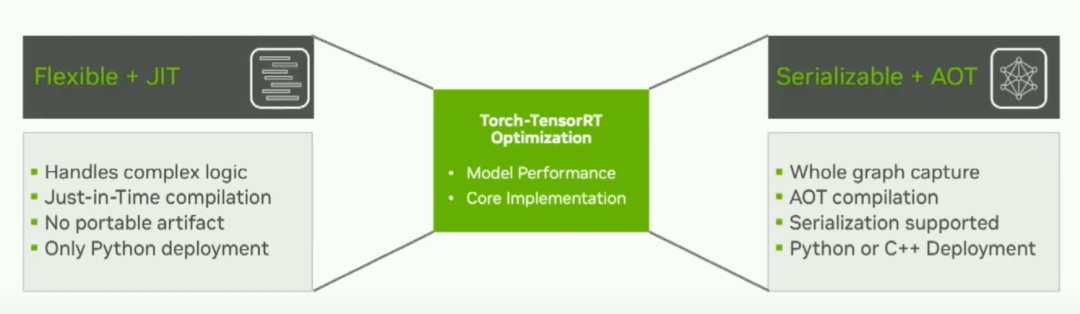
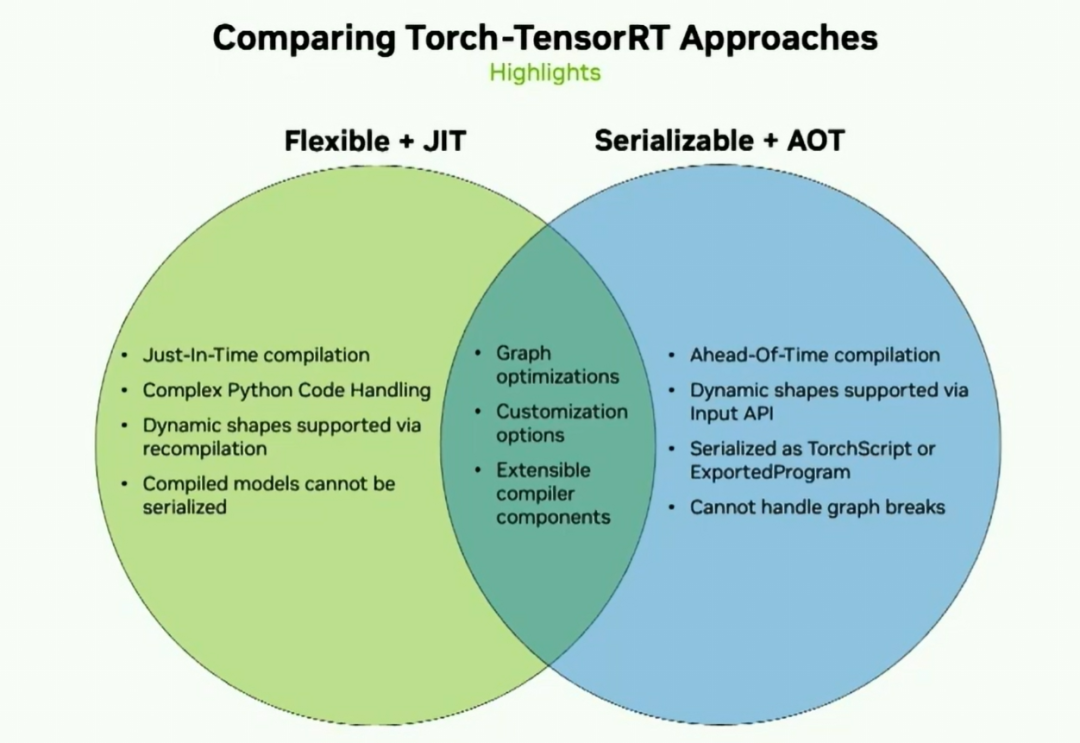
今天我們將介紹的兩種方法是Flexible JIT方法和Serializable AOT方法。如果您的模型具有復雜邏輯,需要即時編譯,并且可能需要Python嚴格部署,那么靈活的JIT方法可能對您來說是最好的選擇。如果您需要整個圖形捕獲,需要對模型進行一些序列化,或者進行C++部署,那么AOT方法可能更適合您的用例。所以考慮到這一點,讓我們走一遍這兩個用戶流程共享的內部路徑。
為了優化PyTorch模型,從模型創建開始一直到優化,所以我們只需要用戶提供一個預訓練模型和一些編譯設置。這些傳遞給編譯器,即Torch TensorRT。現在,在這個綠色虛線框中的所有操作都是在幕后完成的,由編譯器來處理。但是這有助于理解我們如何獲得性能提升。
以下是一般的內部構造:
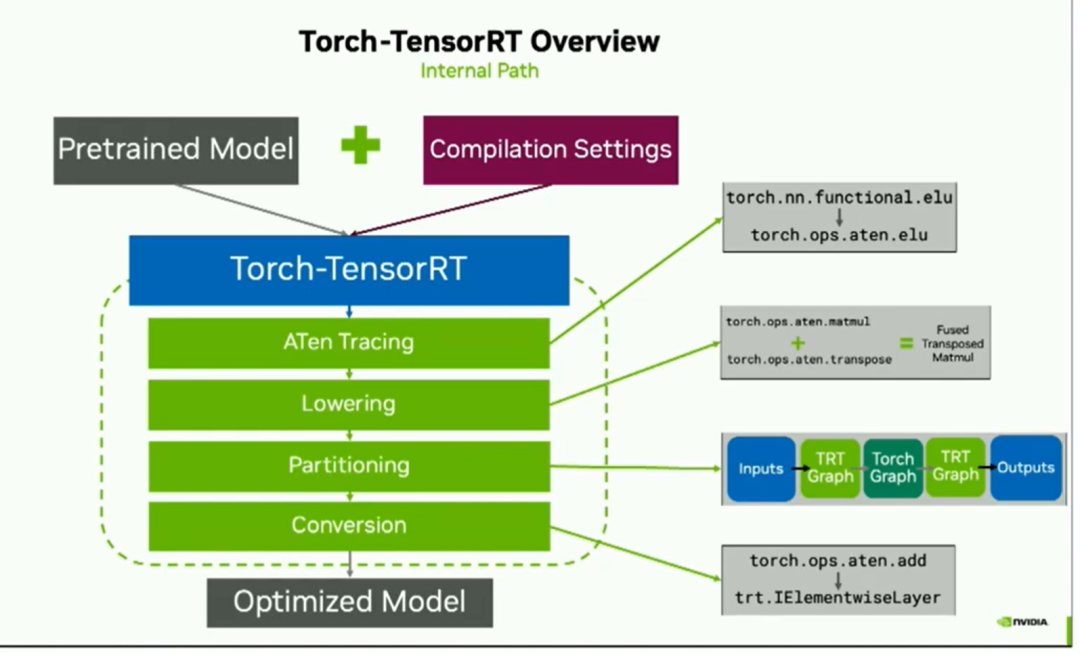
我們使用ATEN trace將graph轉換過來。實際上,這意味著我們將torch操作符轉換成ATEN表示,這只是以一種稍微容易處理的方式來表示相同的操作符。之后,我們進行lowering處理,包括常數折疊和融合以提高性能。然后我們進入劃分階段partitioning。Torch TensorRT會選擇運行哪些操作,哪些操作在Torch中運行,從而生成您在右側看到的分段圖形。最后是轉換階段,對于在右側看到的每個TensorRT圖形,他們從其ATEN操作轉換為等效的TensorRT layer,最后得到優化后的模型。
所以在談到這個一般方法后,即針對兩種用例的一般路徑,我們將稍微深入了解JIT工作流程.,Dheeraj將討論提前工作流程.,JIT方法使您享受到了Torch.compile的好處.,其中包括復雜的Python代碼處理、自動圖形分割.,.,NVIDIA的TensorRT的優化能力.,層張量融合、內核自動調優,以及您選擇層精度的能力.,

在該方法的瀏覽版中,我們能夠在不到一秒鐘的時間內對穩定擴散的文本到圖像進行基準測試.(4090 16fp 50epoch),那么,JIT方法背后的真正原理是什么?,嗯,從一開始就開始吧.,然后用戶只需要在該模型上調用torch.compile,并指定TensorRT作為后端.,現在從這里開始的一切都是在幕后進行的,.,但有助于解釋正在發生的事情.
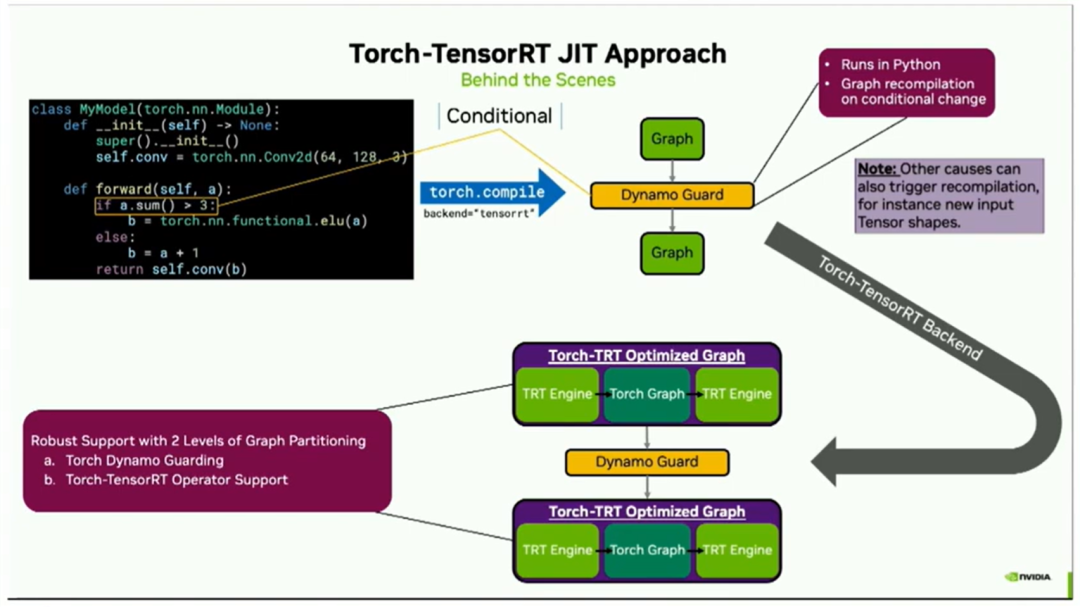
因此,在這之后,Torch.compile將會將您的模型代碼進行拆分,然后是一個dynamo guard(什么是 dynamo guard?請參考:TorchDynamo 源碼剖析 04 - Guard, Cache, Executionhttps://zhuanlan.zhihu.com/p/630722214[1] ,可以簡單理解為dynamo后到python代碼的中間層),再然后是另一個graph。之所以會出現這個guard,是因為在代碼中有一個條件語句。實際上,大多數機器學習模型的跟蹤器都無法處理這樣的條件語句,因為這個條件取決于輸入的值。但是Torch Compile能夠處理它,因為這個guard在Python中運行,并且會在條件的值發生變化時觸發自動圖形重新編譯。
此外,還需注意其他因素也可能導致重新編譯,例如如果您傳入了不同形狀的張量或者改變了其他參數。因此,這個graph / guard / graph構造現在進入了Torch Tensorrt后端,它將按照之前幻燈片中展示的相同過程進行處理。右上角的每個圖形都會被轉換為右下角您看到的Torch TensorRT優化版本。有效地將其分成TensorRT組件和Torch組件。需要注意的關鍵是Dynamo Guard保持完好。因為他提供了圖分區的強大支持。第一級是在復雜Python代碼的Python級別上。第二級是運算符級別上分區,在TensorRT中可以進一步加速的運算符以及可以在Torch中加速的其他運算符。
總結用法,用戶只需對模型調用torch compile,指定后端tensorRT,并可選擇一些選項,然后傳遞一些輸入,它將實時進行編譯。這種編譯方法對用戶來說非常可定制。您可以通過精度關鍵字參數選擇層精度。您可以指定在TensorRT引擎塊中所需的最小運算符數量,等等。

就這些,接下來就交給Dheeraj討論AOT方法。現在讓我們來看看Torch TensorRT的AOT方法。
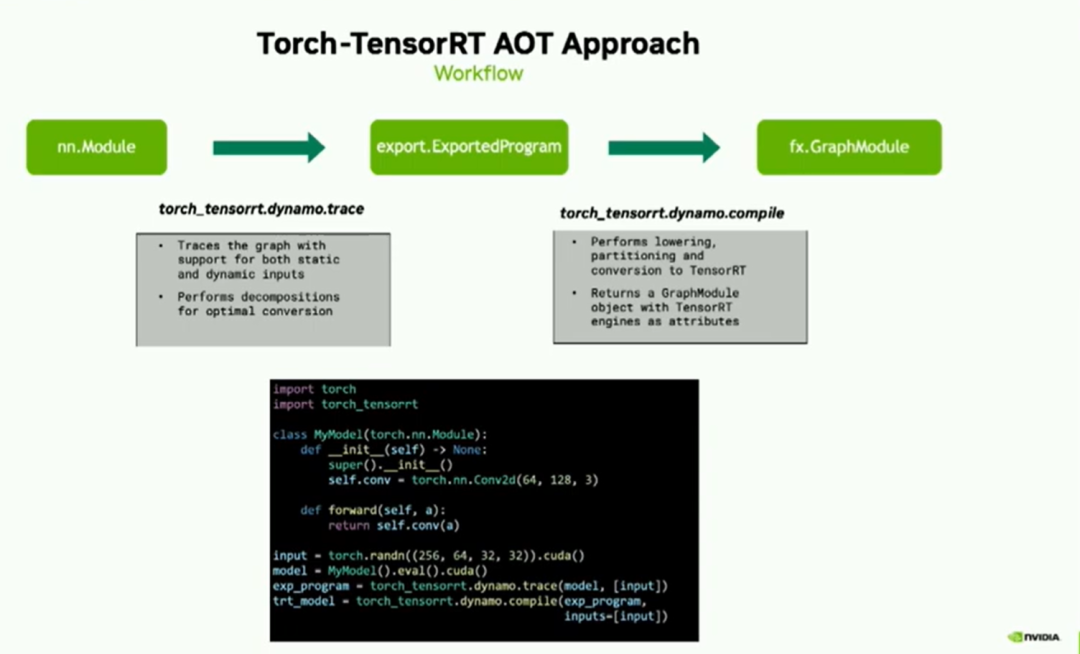
給定一個nn module的PyTorch圖形,我們首先將其轉換為Exported program。Exported program是在PyTorch 2.1中引入的一種新表示形式,它包含了Torch FX圖形和狀態字典兩部分。其中,Torch FX圖形包含了模型的張量計算,狀態字典用于存儲參數和緩沖區。這個轉換是通過使用Dynamo.trace API來完成的。此API是對Torch.export的封裝,并且除此之外,它還支持靜態和動態輸入。我們的追蹤器API還執行一些附加的分解操作,以便將您的模型優化轉換為TensorRT格式。
一旦我們獲得了Exported program,我們AOT方法的主要API就是Dynamo.compile。這個API將這些Exported program轉換為優化的TensorRT圖形模塊。在幕后,這個API執行lowering、分區和轉換為TensorRT的操作,這些都是我們編譯器的核心組件,正如您在演示的開頭所看到的。一旦編譯完成,輸出的結果是一個包含TensorRT圖形模塊的TorchFX模塊。
下面的代碼段列出了該API的簡單用法。一旦您聲明了您的模型,只需將其傳遞給dynamo.trace,然后是dynamo.compile,該函數將返回優化后的TensorRT圖模塊。
TensorRT期望圖中每個動態輸入都有一系列形狀。

在右邊的圖中,您可以看到我們可以使用torch_tensorrt.input API提供這些形狀范圍。與剛剛看到的jit流程的區別是您可以提供這個形狀范圍。這樣做的好處是,如果輸入形狀在提供的范圍內發生更改,您無需重新編譯即可進行推理。靜態是序列化的主要好處之一。
為了總結我們到目前為止所見到的內容,根據您的PyTorch圖形,我們使用我們的trace API生成導出的程序,然后使用Dynamo.compile API進行編譯。最后,您將獲得一個TorchFX圖模塊,其中包含TensorRT優化的引擎。現在,您可以使用Dynamo.Serialize API,將這些圖形模塊對象轉換為編程腳本或導出程序的表示形式,并隨后保存到磁盤上。同樣,右側的代碼片段非常易于使用。一旦您從Dynamo.compile中獲得了TensorRT模型,只需使用模型及其輸入調用serialize API即可。

以下是我們目前所見的內容的概述。我們能夠處理復雜的Python代碼。通過重新編譯支持動態形狀,將已編譯的模塊序列化。此外,我們還能夠通過我們的輸入API支持動態形狀,并且將它們序列化為.script或導出的程序,但它無法處理任何圖形斷點。
然而,這兩者之間存在一些重要的相似之處。它們都經歷類似的圖形優化以進行高性能推斷。Torch TensorRT在PyTorch框架中以兩個關鍵路徑提供了優化的推理方式。
結論和未來工作
Torch-TensorRT通過兩個關鍵路徑在PyTorch中提供了優化的推理:
對于JIT工作流和復雜模型,采用基于torch.compile的方法
對于AoT工作流和序列化,采用強大的基于Exported program的方法
未來的工作:
在兩個路徑上提供對動態形狀的全面支持
改進對編譯Exported program的序列化支持
通過支持額外的精度和優化,提高模型性能
-
模型
+關注
關注
1文章
3500瀏覽量
50133 -
機器學習
+關注
關注
66文章
8497瀏覽量
134231 -
pytorch
+關注
關注
2文章
809瀏覽量
13815
原文標題:9- Accelerated Inference in PyTorch 2.X with Torch tensorrt
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
英特爾FPGA 助力Microsoft Azure機器學習提供AI推理性能
NVIDIA打破AI推理性能記錄
怎樣使用PyTorch Hub去加載YOLOv5模型
求助,為什么將不同的權重應用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
pytorch模型轉換需要注意的事項有哪些?
Xavier的硬件架構特性!Xavier推理性能評測
使用NVIDIA TensorRT優化T5和GPT-2

Nvidia 通過開源庫提升 LLM 推理性能
現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理

用上這個工具包,大模型推理性能加速達40倍
魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
利用Arm Kleidi技術實現PyTorch優化







 工商網監
工商網監
評論